
5G元年正式开启
和4G相比,5G到底有何不同?比如10G视频,4G下载需15分钟,5G仅9秒
十年前4G到来,谁能想到他巨大的改变了我们的生活方式和缔造了无数企业,5G让我们拭目以待吧!
5G的到来让人工智能,工业互联,智慧城市更是加快了步伐,而大数据正是基础。
大数据框架Hadoop发展到今天家族产品已经非常丰富,能够满足不同场景的大数据处理需求。作为目前主流的大数据处理技术,市场上很多公司的大数据业务都是基于Hadoop开展,而且对很多场景已经具有非常成熟的解决方案。
作为开发人员掌握Hadoop及其生态内框架的开发技术,就是进入大数据领域的必经之路。
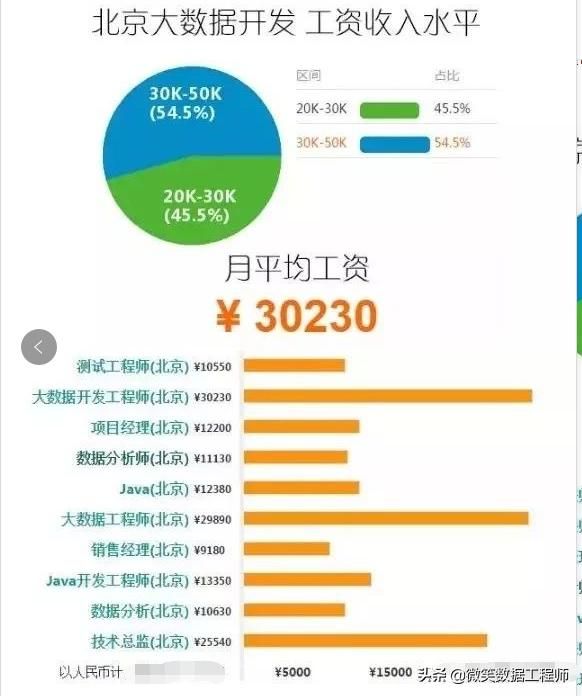
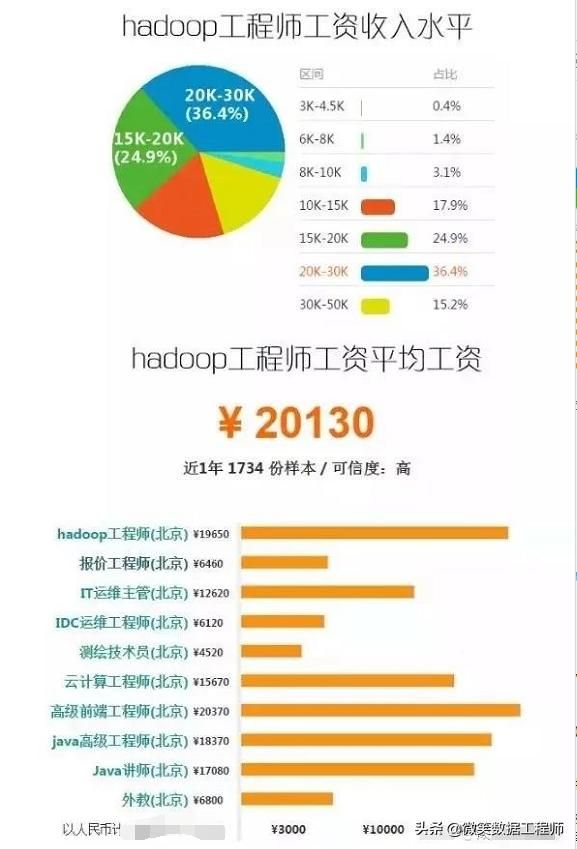
下面详细介绍一下,学习Hadoop开发技术的路线图。
第一阶段:Hadoop生态架构技术
语言基础
1 Java:掌握javase知识,多理解和实践在Java虚拟机的内存管理、以及多线程、线程池、设计模式、并行化就可以,不需要深入掌握。
2.Linux:系统安装(命令行界面和图形界面)、基本命令、网络配置、Vim编辑器、进程管理、Shell脚本、虚拟机的菜单熟悉等等。
3.Python:基础语法,数据结构,函数,条件判断,循环等基础知识。
4.Scala:是一门现代的多范式编程语言,设计初衷是要集成面向对象编程和函数式编程的各种特性。Scala允许用户使用命令和函数范式编写代码。Scala运行在Java虚拟机之上,可以直接调用Java类库。
函数编程范式更适合用于Map/Reduce和大数据模型,它摒弃了数据与状态的计算模型,着眼于函数本身,而非执行的过程的数据和状态的处理
5.Mysql:Hive的元数据都放在mysql上,Hive和Hbase的语法与Sql类似
环境准备
这里介绍在windows电脑搭建完全分布式,1主3从。
VMware虚拟机、Linux系统(Centos6.5)、Hadoop安装包,这里准备好Hadoop完全分布式集群环境。
6.MapReduce
MapReduce分布式离线计算框架,是Hadoop核心编程模型。主要适用于大批量的集群任务,由于是批量执行,故时效性偏低。
7.HDFS
Hadoop分布式文件系统(HDFS)是一个高度容错性的系统,适合部署在廉价的机器上。HDFS能提供高吞吐量的数据访问,非常适合大规模数据集上的应用。
8.Yarn
前期了解即可,Yarn是一个资源调度平台,主要负责给任务分配资源。Yarn是一个公共的资源调度平台,所有满足条件的框架都可以使用Yarn来进行资源调度。
9.Hive
Hive是一个数据仓库,所有的数据都是存储在HDFS上的。使用Hive主要是写Hql,非常类似于Mysql数据库的Sql。其实Hive在执行Hql,底层在执行的时候还是执行的MapRedce程序。
10.Spark
在这里相信有许多想要学习大数据的同学,大家可以+下大数据学习裙:957205962,即可免费领取套系统的大数据学习教程
Spark 是专为大规模数据处理而设计的快速通用的计算引擎,其是基于内存的迭代式计算。Spark 保留了MapReduce 的优点,而且在时效性上有了很大提高。
11.Spark Streaming
Spark Streaming是实时处理框架,数据是一批一批的处理。
12.Storm
Storm是一个实时计算框架,和MR的区别就是,MR是对离线的海量数据进行处理,而Storm是对实时新增的每一条数据进行处理,是一条一条的处理,可以保证数据处理的时效性。
13.Zookeeper
Zookeeper是很多大数据框架的基础,它是集群的管理者。监视着集群中各个节点的状态根据节点提交的反馈进行下一步合理操作。
最终,将简单易用的接口和性能高效、功能稳定的系统提供给用户
14.Hbase
Hbase是一个Nosql 数据库,是一个Key-Value类型的数据库,是高可靠、面向列的、可伸缩的、分布式的数据库。
适用于非结构化的数据存储,底层的数据存储在HDFS上。
15.Kafka
kafka是一个消息中间件,在工作中常用于实时处理的场景中,作为一个中间缓冲层。
16.Flume
Flume是一个日志采集工具,常见的就是采集应用产生的日志文件中的数据,一般有两个流程。
一个是Flume采集数据存储到Kafka中,方便Storm或者SparkStreaming进行实时处理。
另一个流程是Flume采集的数据存储到HDFS上,为了后期使用hadoop或者spark进行离线处理。
17.Flink
Flink是一个面向数据流处理和批量数据处理的可分布式的开源计算框架,它基于同一个Flink流式执行模型(streaming execution model),能够支持流处理和批处理两种应用类型。
Flink在实现流处理和批处理时,与传统的一些方案完全不同,它从另一个视角看待流处理和批处理,将二者统一起来:Flink是完全支持流处理,也就是说作为流处理看待时输入数据流是无界的;批处理被作为一种特殊的流处理,只是它的输入数据流被定义为有界的。大有取代spark之势!
18.Sqoop
Sqoop是一款开源的工具,主要用于在Hadoop(Hive)与传统的数据库(mysql、postgresql...)间进行数据的传递,可以将一个关系型数据库(例如 : MySQL ,Oracle ,PostgreSQL等)中的数据导进到Hadoop的HDFS中,也可以将HDFS的数据导进到关系型数据库中。
第一阶段学完基本就可以找到一份初级大数据工作了!!

第二阶段:数据挖掘算法
1.中文分词
2.开源分词库的离线和在线应用
3.自然语言处理
4.文本相关性算法
5.推荐算法
6.基于CB、CF,归一法,Mahout应用。
7.分类算法
8.NB、SVM
9.回归算法
10.LR、Decision Tree
11.聚类算法
12.层次聚类、Kmeans
13.神经网络与深度学习
14.人工智能
大数据开发高薪必备全套资源【免费获取】
Oracle高级技术总监多年精心创作一套完整课程体系【大数据、人工智能开发必看】,全面助力大数据开发零基础+入门+提升+项目=高薪!
「大数据零基础入门」
「大数据架构系统组件」
「大数据全套系统工具安装包」
Java必备工具
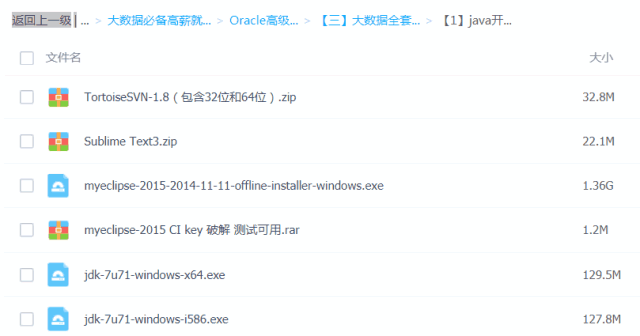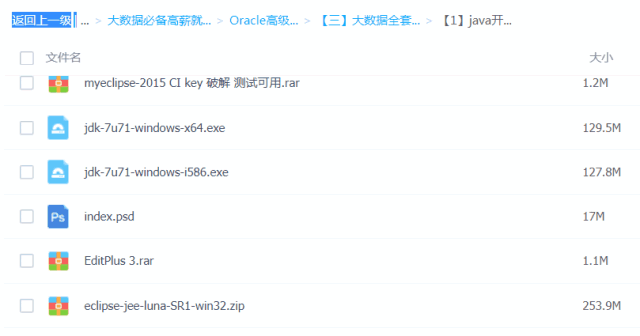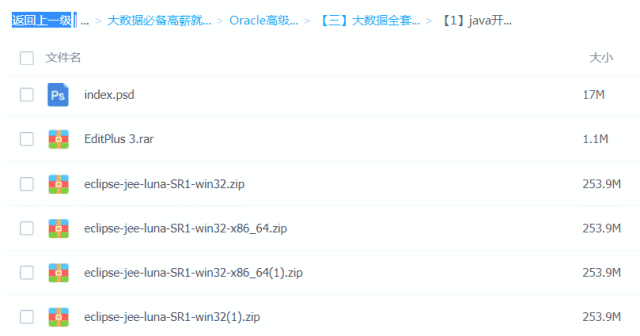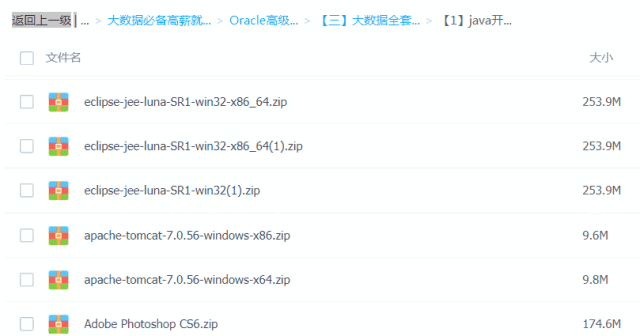
大数据必备工具
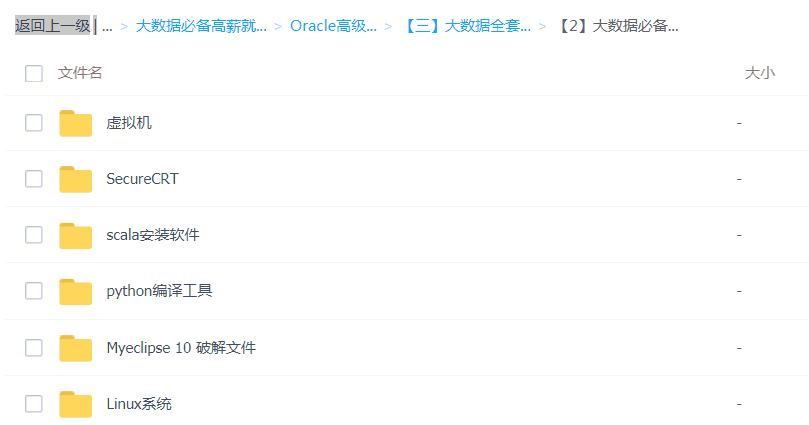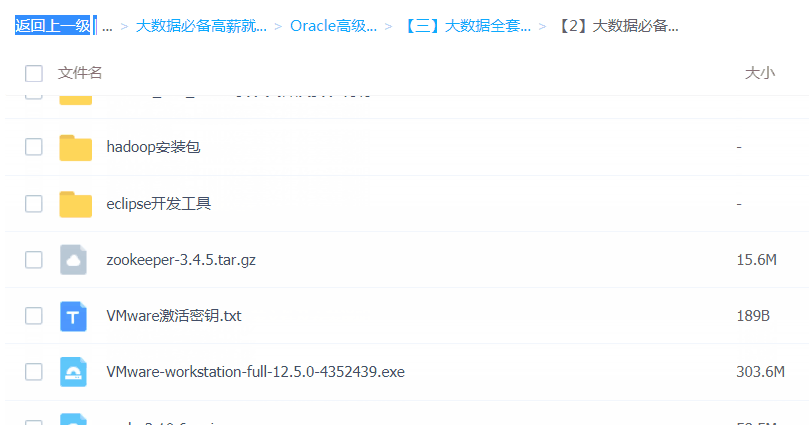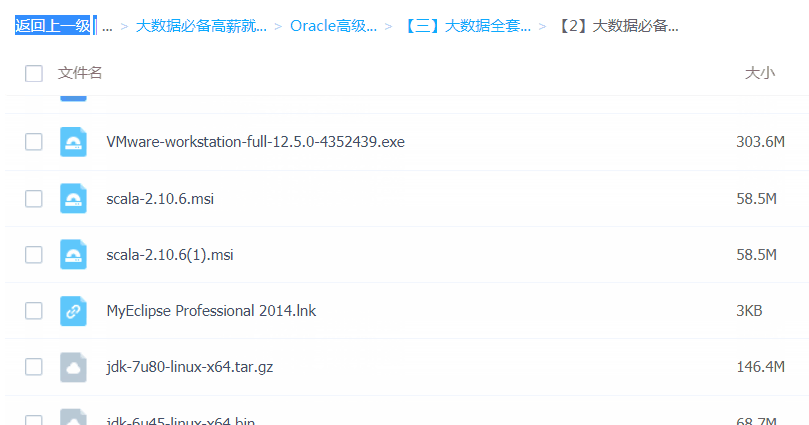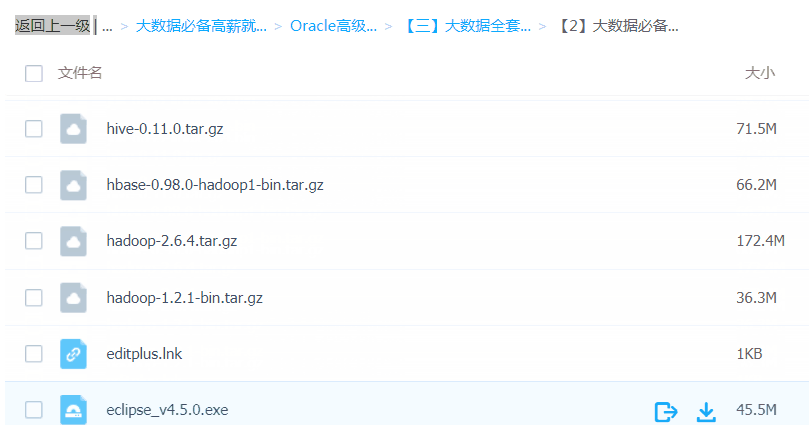
「大数据行业必备知资讯」
「大数据精品实战案例」
「大数据就业指导方案」
最后说一下的,也就是以上教程的获取方式!
领取方法:
还是那个万年不变的老规矩
1.评论文章,没字数限制,一个字都行!
2.成为小编成为的粉丝!
3.私信小编:“大数据开发教程”即可!
谢谢大家,祝大家学习愉快!(拿到教程后一定要好好学习,多练习哦!)