后端存储课程笔记(大量实战经验)
课程内容: 极客时间-后端存储
第一章:
电商系统:
幂等性,工作中也多次见到其实现了。一个幂等操作的特点是,其任意多次执行所产生的影响均与一次执行的影响相同
- 在电商系统中,防止重复下单如何解决: 因此提供一个接口返回给前端订单id, 然后下订单的时候把此id当成主键id或者uniqueId就能防止重复下单(不管是重复请求还是网络超时重试都不影响mysql的主键唯一性)
- ABA问题如何解决: 提供的答案是加一个版本号version,然后每次操作都校验版本号。
思考:版本号 和 加锁 两种方法哪个更好呢。
总结: 幂等性应当成为自己一个习惯性思考:自己写的服务、接口等是否应当具备幂等性、是否已经具备幂等性。
第二章:
先抛出两个问题:
- 商品详情页的高并发怎么解决?
- 商品数据怎么存储的问题
先说第二个:最简单的方法就是存在一个大表里。 在量级上来后我们可以把商品系统需要存储的数据按照特点,分成商品基本信息、商品参数、图片视频和商品介绍几个部分来分别存储。然后添加缓存(nosql), 对图像视频啥的用cdn、
第一个就是 商品详情页静态化用cdn加速。
第三章
介绍了购物车系统的大概设计。
第四章:
介绍了mysql的ACID,以及做账户余额的一些注意事项。
第五章:
现在微服务应用越多,系统被拆分,我们的业务系统微服务化之后,不可避免地要面对跨系统的数据一致性问题。
做MySql事务不需要知道 MySQL 是如何实现 ACID 的。因为数据库已经把事务封装的非常好了,我们只需要掌握如何使用就可以很好地解决问题。
但分布式事务不是这样的,并没有一种分布式事务的服务或者组件,能帮我们很简单地就解决分布式系统下的数据一致性问题。
连事务都不可能完美的解决ACID,所以才有多种隔离级别,分布式事务也是如此,其分为几个级别:
- 2PC(二阶段提交):
假设一种场景:淘宝购物的优惠券使用,涉及到至少两个系统:
a 在订单系统中成功下单
b 在优惠券系统中成功消耗此优惠券
2pc会引入一个“事务协调者” 来提供完成的使用优惠券下单服务。其实现方法分为两个阶段:首先准备阶段会给两个系统发送“准备”指令,让他们把除了提交事务之外的其他所有工作都做完,然后返回准备成功的讯号。 之后第二阶段会发送提交指令,让他们分别commit事务。
比如说订单系统在准备阶段需要完成:在订单库开启一个数据库事务;
在“订单优惠券表”写入这条订单的优惠券记录;
在“订单表”中写入订单数据。
注意,到这里我们没有提交订单数据库的事务,最后给事务协调者返回“准备成功”。类似的,促销服务在准备阶段,需要在促销库开启一个数据库事务,更新优惠券状态,但是暂时不要提交这个数据库事务,给协调者返回“准备成功”。协调者在收到两个系统“准备成功”的响应之后,开始进入第二阶段。
如果准备阶段失败了,这时候回滚即可,因为什么都还没做
但如果进入第二阶段提交了,那么整个分布式事务只能成功,不能失败。
如果发生网络传输失败的情况,需要反复重试,直到提交成功为止。
如果发生什么参与者提交失败、宕机等等原因,2pc没办法处理,只能打下日志让人工介入。
这里可以认为既然已经在准备阶段把资源锁下来了,那么不出意外的话,应该会能够成功的。
然后关于协调者没必要新启动一个服务做,直接从A或者B中选一个来做就好了。
2PC 也有很明显的缺陷,整个事务的执行过程需要阻塞服务端的线程和数据库的会话,所以,2PC
在并发场景下的性能不会很高。
并且,协调者是一个单点,一旦过程中协调者宕机,就会导致订单库或者促销库的事务会话一直卡在等待提交阶段,直到事务超时自动回滚。卡住的这段时间内,数据库有可能会锁住一些数据,服务中会卡住一个数据库连接和线程,这些都会造成系统性能严重下降,甚至整个服务被卡住。
总结:可以认为2PC是一个经典的中心化,强一致性的原子操作。
2PC的缺陷和3PC的改进:https://zhuanlan.zhihu.com/p/35298019
- 分布式队列消息:
主要目的:消息生产者和消息消费者的数据最终一致性问题。
举个例子。比如用户在电商 APP 上购物时,先把商品加到购物车里,
然后几件商品一起下单,
最后支付,完成购物流程。
这个过程中 订单系统创建订单后,发消息给购物车系统,将已下单的商品从购物车中删除。因为从购物车删除已下单商品这个步骤,并不是用户下单支付这个主要流程中必需的步骤,使用消息队列来异步清理购物车是更加合理的设计。
这里值得思考的地方是:对于订单系统: 创建订单和发送系统应在同一个事务内,要么都成功要么都失败,不能出现订单创建失败但消息发出去了。 所以发消息就必须要引入事务消息。
所以会有事务队列消息也分成两个阶段:
1.半消息,给队列发送半消息:完整的消息但是对消费者来说是不可见的。
2.和下单放在一个事务里面一起提交。
这里有个问题是,如果订单创建成功,但是事务消息提交失败怎么办? 此时一般认为不会撤销
订单,而是对事务消息进行处理。
最简单的处理方式参照kafka:
Kafka 的解决方案比较简单粗暴,直接抛出异常,让用户自行处理。我们可以在业务代码中反复重试提交,直到提交成功,或者删除之前创建的订单进行补偿。
而rmq处理比较复杂,引入了事务反查的机制:其实就是在生产者(订单系统)中提供一个接口,让rmq的broker判断订单事务是否执行成功,来判断要不要发送事务消息。即做一个不完全依赖producer的服务,自己也可以发送消息。
总结流程:
实现订单下单场景:
- 首先发送一个半消息给MQ.
- 此时会阻塞,然后在这个方法里面进行订单创建并提交本地事务,如果commit成功,则返回COMMIT状态,否则是ROLLBACK状态,如果正常返回COMMIT或者ROLLBACK的话,不会存在第3步的反查情况。
- 如果上面的本地事务提交成功以后,此节点突然断电,那么反查方法就会在某个时候被MQ调用,此方法会根据消息中的订单号去数据库确认订单是否存在,存在就返回COMMIT状态,否则是ROLLBACK状态。
- 购物车在另外一个项目中,反正只要收到MQ的消息就将本次订单的商品从购物车中删除即可。
关于消息队列,这个还是挺复杂的,这里只是做一个简单的分析。
- TCC:
一文读懂tcc:https://www.cnblogs.com/jajian/p/10014145.html
第六章:
介绍了ES
第七章:
介绍了mysql的备份策略。主从集群的一些同步策略。
第八章
介绍了一个mysql慢查的例子。
第一,在编写 SQL 的时候,一定要小心谨慎地仔细评估。先问自己几个问题:你的 SQL 涉及到的表,它的数据规模是多少?你的 SQL 可能会遍历的数据量是多少?尽量地避免写出慢 SQL。
第二,能不能利用缓存减少数据库查询次数?在使用缓存的时候,还需要特别注意的就是缓存命中率,要尽量避免请求命中不了缓存,穿透到数据库上。
最好再做一层localcache,防止不会因为缓存在同一个时间点过期而引发缓存穿透。
第九章
如何避免写出mysql慢查:
- 认识mysql的上限:
一台 MySQL 数据库,大致处理能力的极限是,每秒一万条左右的简单 SQL,这里的“简单 SQL”,指的是类似于主键查询这种不需要遍历很多条记录的 SQL。根据服务器的配置高低,可能低端的服务器只能达到每秒几千条,高端的服务器可以达到每秒钟几万条,所以这里给出的一万 TPS 是中位数的经验值。考虑到正常的系统不可能只有简单 SQL,所以实际的 TPS 还要打很多折扣。
我的经验数据,一般一台 MySQL 服务器,平均每秒钟执行的 SQL 数量在几百左右,就已经是非常繁忙了,即使看起来 CPU 利用率和磁盘繁忙程度没那么高,你也需要考虑给数据库“减负”了。
- 表的大小和使用索引
遍历行数在千万左右,是 MySQL 查询的一个坎儿。MySQL 中单个表数据量,也要尽量控制在一千万条以下,最多不要超过二三千万这个量级。原因也很好理解,对一个千万级别的表执行查询,加上几个 WHERE 条件过滤一下,符合条件的数据最多可能在几十万或者百万量级,这还可以接受。但如果再和其他的表做一个联合查询,遍历的数据量很可能就超过千万级别了。所以,每个表的数据量最好小于千万级别。
增加适量的索引,以及用explain看sql执行命令, 注意是否用到了索引等等
第十章
SQL 是如何在执行器中执行的?
- 先把命令转换成结构化数据,名字叫抽象语法树(AST)

然后根据AST生成一个逻辑执行计划(原则上把过滤和投影尽可能的早做以减少扫描行数 - 具体执行从磁盘中get数据就是我们熟悉的B+树那一套东西了。
第十一章
如何更好的使用缓存:
1 更新mysql -> 更新缓存。不如直接删除缓存。这样可以有效的避免并发写产生脏数据的问题。但在高并发下仍然存在不一致问题。
线程1读取缓存未命中,查询当前数据库数据
线程2更新当前数据库数据,删除缓存(不存在)
线程1讲老数据更新至缓存,导致当前数据库数据与缓存不一致
如果一定要保证百分百的数据一致,还是用锁比较好,写的时候上锁,更新、释放锁。
2 为了防止缓存穿透的问题: 在系统上线之前先灰度预热redis,把经常访问的数据先放进redis。如果没有灰度就最好手动预热。
3 注意另外一种穿透
当发生缓存穿透时,如果从数据库中读取数据的时间比较长,也容易引起数据库雪崩。
比如说,我们缓存的数据是一个复杂的数据库联查结果,如果在数据库执行这个查询需要 10 秒钟,那当缓存中这条数据过期之后,最少 10 秒内,缓存中都不会有数据。
如果这 10 秒内有大量的请求都需要读取这个缓存数据,这些请求都会穿透缓存,打到数据库上,这样很容易导致数据库繁忙,当请求量比较大的时候就会引起雪崩。
所以,如果说构建缓存数据需要的查询时间太长,或者并发量特别大的时候,Cache Aside 或者是 Read/Write Through 这两种缓存模式都可能出现大量缓存穿透。对于这种情况,并没有一种方法能应对所有的场景,你需要针对业务场景来选择合适解决方案。
比如说,可以牺牲缓存的时效性和利用率,缓存所有的数据,放弃 Read Through 策略所有的请求,只读缓存不读数据库,用后台线程来定时更新缓存数据。
第十二章
mysql如何应对高并发:
当缓存以用户为维度的时候,缓存无法有效的阻隔请求。mysql扛不住
1.读写分离。(主从同步延迟带来数据不一致问题,增加和用户交互的页面、时间。或者合理使用事务。
2.kafka错峰
第十三章
主从同步是如何实现的:
同步复制、半同步复制、和异步复制。
复制状态机:
在 MySQL 中,无论是复制还是备份恢复,依赖的都是全量备份和 Binlog,全量备份相当于备份那一时刻的一个数据快照,Binlog 则记录了每次数据更新的变化,也就是操作日志。我们这节课讲主从同步,也就是数据复制,虽然讲的都是 MySQL,但是你要知道,这种基于“快照 + 操作日志”的方法,不是 MySQL 特有的。比如说,Redis Cluster 中,它的全量备份称为 Snapshot,操作日志叫 backlog,它的主从复制方式几乎和 MySQL 是一模一样的。我再给你举个例子,之前我们讲过的 Elasticsearch,它是一个内存数据库,读写都在内存中,那它是怎么保证数据可靠性的呢?对,它用的是 translog,它备份和恢复数据的原理和实现方式也是完全一样的。这些什么什么 log,都是不同的马甲儿而已。
几乎所有的存储系统和数据库,都是用这一套方法来解决备份恢复和数据复制问题的。
第十四章
当mysql-table中的数据越来越多,速度越来越慢怎么解决?
---- 数据归档:
当单表的订单数据太多,多到影响性能的时候,首选的方案是,归档历史订单。
简单地说,就是把大量的历史订单移到另外一张历史订单表中。为什么这么做呢?因为像订单这类具有时间属性的数据,都存在热尾效应。大多数情况下访问的都是最近的数据,但订单表里面大量的数据都是不怎么常用的老数据(老数据理论上来说可以允许慢一点)
ps:注意前提
这样拆分的另外一个好处是,拆分订单时,需要改动的代码非常少。
几乎只需要修改查询历史订单这一个模块里面的代码。
然后就到了我们熟悉的一套流程:
1 创建新的历史表
2 代码兼容新表,双查
3 校验代码是否正确
4 迁移数据
5 再校验代码
6 正确无误之后删除已经迁移的数据。(迁移之前一定做好备份,这样如果不小心误操作了,也能用备份来恢复。)
如何批量删除大量数据?
select max(id) from orderswhere timestamp < SUBDATE(CURDATE(),INTERVAL 3 month);
delete from orderswhere id <= ?order by id limit 1000;为什么在删除语句中非得加一个排序呢?因为按 ID 排序后,我们每批删除的记录,基本都是 ID 连续的一批记录,由于 B+ 树的有序性,这些 ID 相近的记录,在磁盘的物理文件上,大致也是放在一起的,这样删除效率会比较高,也便于 MySQL 回收页。
插入一个经典的设计思路:
大量的历史订单数据删除完成之后,如果你检查一下 MySQL 占用的磁盘空间,你会发现它占用的磁盘空间并没有变小,这是什么原因呢?
这也是和 InnoDB 的物理存储结构有关系。虽然逻辑上每个表是一颗 B+ 树,但是物理上,每条记录都是存放在磁盘文件中的,这些记录通过一些位置指针来组织成一颗 B+ 树。当 MySQL 删除一条记录的时候,只能是找到记录所在的文件中位置,然后把文件的这块区域标记为空闲,然后再修改 B+ 树中相关的一些指针,完成删除。
其实那条被删除的记录还是躺在那个文件的那个位置,所以并不会释放磁盘空间。
这么做也是没有办法的办法,因为文件就是一段连续的二进制字节,类似于数组,它不支持从文件中间删除一部分数据。
如果非要这么删除,只能是把这个位置之后的所有数据往前挪,这样等于是要移动大量数据,非常非常慢。所以,删除的时候,只能是标记一下,并不真正删除,后续写入新数据的时候再重用这块儿空间。
理解了这个原理,你就很容易知道,不仅是 MySQL,很多其他的数据库都会有类似的问题。这个问题也没什么特别好的办法解决,磁盘空间足够的话,就这样吧,至少数据删了,查询速度也快了,基本上是达到了目的。
第十五章
mysql海量数据最后的处理方法:分库分表
为什么mysql不可舍弃:
只有 MySQL 这类关系型数据库,才能提供金融级的事务保证
原则:
能不拆就不拆,能少拆不多拆。原因也很简单,你把数据拆分得越散,开发和维护起来就越麻烦,系统出问题的概率就越大。
意义(解决什么问题?
1 慢查询问题:解决查询慢,只要减少每次查询的数据总量就可以了,也就是说,分表就可以解决问题。
2 并发太高,顶不住:一个数据库实例撑不住,就把并发请求分散到多个实例中去,所以,解决高并发的问题是需要分库的。(这里可以想打redis-key分桶的机制,其实也是一样的。
这里需要理解一下mysql 集群、实例等概念, 假设我们mysql集群是一主三从。

这里我们可以理解的是:
1 一个client对应一个某一个实例的数据库。但这个机器上可能有其他的数据库实例也在,所以可能存在相互影响的关系
2 mysql的瓶颈在一主多从的主实例上,一是他只有一个执行器,资源是有限的。多个并发打过来的时候肯定是扛不住的(连接池上限)
3 读从库的时候这里既有缓存又有从实例(资源翻倍)一般不会成为瓶颈。
现在我们来讨论分库分表
1 分表:
首先分表还是在同一个database下面分,也就是同一个机器上,资源并没有变多(所以写磁盘等等操作并不会优化),对并发数来讲没有任何影响。影响的地方在 一是写的时候 :由于B+数的特性,我们分多个表意味着树的高度降低了,意味着磁盘操作变少了,且写完之后的维护时间变少了,还有就是锁一个表变成锁多个表,锁力度变小。 二是读的时候,其扫描的行数变少。 总结:分表提升的是读写速度。
2 分库:
分库意味着 在不同的database下, 且是在不同的实例上(不同的机器)。 这其实就是N倍资源=直接提高并发数上限,但其带来的问题就是跨节点查询、join、数据一致性等等问题。
参考文档:
https://www.cnblogs.com/qdhxhz/p/11608222.html
https://zhuanlan.zhihu.com/p/84224499
继续讨论在业务上分表分库的难点:
1 以什么来做切分列呢?Sharding Key
比如我们把订单 ID 作为 Sharding Key 来拆分订单表,那拆分之后,如果我们按照订单 ID 来查订单,就需要先根据订单 ID 和分片算法计算出,我要查的这个订单它在哪个分片上,也就是哪个库哪张表中,然后再去那个分片执行查询就可以了。
但是,当我打开“我的订单”这个页面的时候,它的查询条件是用户 ID,这里没有订单 ID,那就没法知道我们要查的订单在哪个分片上,就没法查了。当然你要强行查的话,那就只能把所有分片都查一遍,再合并查询结果,这个就很麻烦,而且性能很差,还不能分页。
那要是把用户 ID 作为 Sharding Key 呢?也会面临同样的问题,使用订单 ID 作为查询条件来查订单的时候,就没办法找到订单在哪个分片了。
这个问题的解决办法是,在生成订单 ID 的时候,把用户 ID 的后几位作为订单 ID 的一部分,比如说,可以规定,18 位订单号中,第 10-14 位是用户 ID 的后四位,这样按订单 ID 查询的时候,就可以根据订单 ID 中的用户 ID 找到分片。
解决方法:
一般的做法是,把订单数据同步到其他的存储系统中去,在其他的存储系统里面解决问题。比如说,我们可以再构建一个以店铺 ID 作为 Sharding Key 的只读订单库,专门供商家来使用。或者,把订单数据同步到 HDFS 中,然后用一些大数据技术来生成订单相关的报表。
所以你看,一旦做了分库分表,就会极大地限制数据库的查询能力,之前很简单的查询,分库分表之后,可能就没法实现了。所以我们在之前的课程中,先讲了各种各样的方法,来缓解数据多、并发高的问题,而一直没讲分库分表。分库分表一定是,数据量和并发大到所有招数都不好使了,我们才拿出来的最后一招。
第十六章
介绍了redis-cluster,
集群的切片分布:16384个槽,CPR(key)%16384. 然后再去映射到相对应的group执行。
分片可以解决 Redis 保存海量数据的问题,并且客观上提升了 Redis 的并发能力和查询性能。但是并不能解决高可用的问题,每个节点都保存了整个集群数据的一个子集,任何一个节点宕机,都会导致这个宕机节点上的那部分数据无法访问。
解决方法: 主从机制
集群的主从同步策略、选主策略这部分没怎么介绍,可以自己去看。
优点:
Redis Cluster 的优点是易于使用。分片、主从复制、弹性扩容这些功能都可以做到自动化,通过简单的部署就可以获得一个大容量、高可靠、高可用的 Redis 集群,并且对于应用来说,近乎于是透明的。
redis-cluster 缺点:
但是 Redis Cluster 不太适合构建超大规模集群,主要原因是,它采用了去中心化的设计。刚刚我们讲了,Redis 的每个节点上,都保存了所有槽和节点的映射关系表,客户端可以访问任意一个节点,再通过重定向命令,找到数据所在的那个节点。那你有没有想过一个问题,这个映射关系表,它是如何更新的呢?比如说,集群加入了新节点,或者某个主节点宕机了,新的主节点被选举出来,这些情况下,都需要更新集群每一个节点上的映射关系表。
去中心化就只能节点传播至节点,节点一多就会变得很慢,在集群规模太大的情况下,数据不同步的问题会被明显放大,还有一定的不确定性,如果出现问题很难排查。
所以出现了codis 等中心化的架构,在这些节点上加一个proxy, 维护映射表等关系。

缺点:
不过,这个架构的缺点也很突出,增加了一层代理转发,每次数据访问的链路更长了,必然会带来一定的性能损失。而且,代理服务本身又是集群的一个单点,当然,我们可以把代理服务也做成一个集群来解决单点问题,那样集群就更复杂了。
另一种方法:
另外一种方式是,不用这个代理服务,把代理服务的寻址功能前移到客户端中去。客户端在发起请求之前,先去查询元数据,就可以知道要访问的是哪个分片和哪个节点,然后直连对应的 Redis 节点访问数据。当然,客户端不用每次都去查询元数据,因为这个元数据是不怎么变化的,客户端可以自己缓存元数据,这样访问性能基本上和单机版的 Redis 是一样的。如果某个分片的主节点宕机了,新的主节点被选举出来之后,更新元数据里面的信息。对集群的扩容操作也比较简单,除了迁移数据的工作必须要做以外,更新一下元数据就可以了。
第十七章
大厂如何mysql和redis的同步。 在海量的数据和并发下,mysql根本扛不住一般都会redis缓存,但此时有缓存穿透的问题,在峰值流量下, 哪怕是一个很小比例的缓存穿透也可能打挂mysql,所以一般都会把所有的数据全量放在redis,此时就会有一个问题如果做redis和mysql的数据一致性呢?
1 分布式事务来解决数据一致性
分布式事务,对数据更新服务有很强的侵入性。我们拿下单服务来说,
如果为了更新缓存增加一个分布式事务,无论我们用哪种分布式事务,或多或少都会影响下单服务的性能。
还有一个问题是,如果 Redis 本身出现故障,写入数据失败,还会导致下单失败,等于是降低了下单服务性能和可用性,这样肯定不行。
2 增加一个更新订单缓存的服务,接收订单变更的 MQ 消息,然后更新 Redis 中缓存的订单数据。
这类核心的业务数据,使用方非常多,本来就需要发消息,增加一个消费订阅基本没什么成本,订单服务本身也不需要做任何更改。
用kafka等成熟的MQ保证消息不丢失,
3 利用mysql的binlog更新缓存
负责更新缓存的服务,把自己伪装成一个 MySQL 的从节点,从 MySQL 接收 Binlog,解析 Binlog 之后,可以得到实时的数据变更信息,然后根据这个变更信息去更新 Redis 缓存。
其实它们的实现思路是一样的,都是异步订阅实时数据变更信息,去更新 Redis。只不过,直接读取 Binlog 这种方式,它的通用性更强。不要求订单服务再发订单消息了,订单更新服务也不用费劲去解决“发消息失败怎么办?”这种数据一致性问题了。
缺点:实现订单缓存更新服务有点儿复杂,毕竟不像收消息,拿到的直接就是订单数据,解析 Binlog 还是挺麻烦的。

具体操作:可以学习一下阿里的开源项目:Canal
后文介绍并演示了canal的下载、安装等具体操作。此处不做赘述。可以看这个:实例
需要特别注意的是,无论是用 MQ 还是 Canal 来异步更新缓存,对整个更新服务的数据可靠性和实时性要求都比较高,数据丢失或者更新慢了,都会造成 Redis 中的数据与 MySQL 中数据不同步。在把这套方案应用到生产环境中去的时候,需要考虑一旦出现不同步问题时的降级或补偿方案。比如:
设置一个合理的缓存过期时间,这样即使出现缓存不同步,等缓存过期后就会自动恢复。再比如,识别用户手动刷新操作,强制重新加载缓存数据(但要注意防止大量缓存穿透)。还可以在管理员的后台系统中,预留一个手动清除缓存的功能,必要的时候人工干预。
第十八章
对象存储
象存储是原生的分布式存储系统。
近乎无限的存储容量;
超高的读写性能;
数据高可靠:
节点磁盘损毁不会丢数据;
实现服务高可用:节点宕机不会影响集群对外提供服务。
其实现并不复杂,反而是最简单的分布式系统:
1 节点:
对象存储对外提供的服务,其实就是一个近乎无限容量的大文件 KV 存储,所以对象存储和分布式文件系统之间,没有那么明确的界限。
对象存储的内部,有很多的存储节点,用于保存这些大文件,这个就是数据节点的集群。
2 元数据管理中心:
我们为了管理这些数据节点和节点中的文件,还需要一个存储系统保存集群的节点信息、文件信息和它们的映射关系。这些为了管理集群而存储的数据,叫做元数据 (Metadata)。
元数据对于一个存储集群来说是非常重要的,所以保存元数据的存储系统必须也是一个集群。但是元数据集群存储的数据量比较少,数据的变动不是很频繁,加之客户端或者网关都会缓存一部分元数据,所以元数据集群对并发要求也不高。一般使用类似ZooKeeper或者etcd这类分布式存储就可以满足要求。
3 代理:
另外,存储集群为了对外提供访问服务,还需要一个网关集群,对外接收外部请求,对内访问元数据和数据节点。网关集群中的每个节点不需要保存任何数据,都是无状态的节点。有些对象存储没有网关,取而代之的是客户端,它们的功能和作用都是一样的。

流程大概就是这样,但是还是有很多细节在里面,比如集群的主从同步、选主机制等等。
数据如何拆分:
在对象存储中,每一个大文件都会被拆成多个大小相等的块儿(Block),拆分的方法很简单,就是把文件从头到尾按照固定的块儿大小,切成一块儿一块儿,最后一块儿长度有可能不足一个块儿的大小,也按一块儿来处理。块儿的大小一般配置为几十 KB 到几个 MB 左右。
(对象被拆成块儿之后,还是太过于碎片化了,如果直接管理这些块儿,会导致元数据的数据量会非常大,也没必要管理到这么细的粒度。所以一般都会再把块儿聚合一下,放到块儿的容器里面。这里的“容器”就是存放一组块儿的逻辑单元。容器这个名词,没有统一的叫法,比如在ceph中称为 Data Placement,你理解这个含义就行。容器内的块儿数大多是固定的,所以容器的大小也是固定的。
这个容器类似 redis 的集群分片机制。容器也会有主从副本、复制同步等。但对象存储主从复制的时候,复制的不是日志,而是整块儿的数据。
第一个原因是基于性能的考虑。我们知道操作日志里面,实际上就包含着数据。在更新数据的时候,先记录操作日志,再更新存储引擎中的数据,相当于在磁盘上串行写了 2 次数据。对于像数据库这种,每次更新的数据都很少的存储系统,这个开销是可以接受的。但是对于对象存储来说,它每次写入的块儿很大,两次磁盘 IO 的开销就有些不太值得了。
第二个原因是它的存储结构简单,即使没有日志,只要按照顺序,整块儿的复制数据,仍然可以保证主从副本的数据一致性。
为什么拆分:
第一是为了提升读写性能,这些块儿可以分散到不同的数据节点上,这样就可以并行读写。
第二是把文件分成大小相等块儿,便于维护管理。
第十九章
多系统数据一致性的另一种实现方法
同样一份订单数据,除了在订单库保存一份用于在线交易以外,还会在各种数据库中,以各种各样的组织方式存储,用于满足不同业务系统的查询需求。像 BAT 这种大厂,它的核心业务数据,存个几十上百份是非常正常的。那么问题来了,如何能够做到让这么多份数据实时地保持同步呢?
解决方法:
1 前面提到过分布式事务,但是这种侵入式过强,而且延时与备份数量成正相关。
2 使用 Binlog 和 MQ 构建实时数据同步系统
以前技术不先进的时候,异构数据库做的都是定时同步,使用 ETL 工具定时同步数据,在 T+1 时刻去同步上一个周期的数据,然后再做后续的计算和分析。定时 ETL 对于一些需要实时查询数据的业务需求就无能为力了。所以这种方式渐渐被淘汰。
上节课说过的,利用 Canal 把自己伪装成一个 MySQL 的从库,从 MySQL 实时接收 Binlog 然后写入 Redis 中。这个思路其实就很完成,稍微改进一下,就可以用来做异构数据库的同步了。
思路:
为了能够支撑下游众多的数据库,从 Canal 出来的 Binlog 数据肯定不能直接去写下游那么多数据库,一是写不过来,二是对于每个下游数据库,它可能还有一些数据转换和过滤的工作要做。所以需要增加一个 MQ 来解耦上下游。
问题:
这个方法看起来不难,但是非常容易出现性能问题。有些接收 Binlog 消息的下游业务,对数据的实时性要求比较高,不能容忍太高的同步时延。
瓶颈可能在的地方:
1 数据库本身的binlog 生产过慢。
2 Canal 和 MQ 这两个环节,由于没什么业务逻辑,性能都非常好。
3 消费 MQ 的同步程序: 因为这些同步程序里面一般都会有一些业务逻辑,而且如果下游的数据库写性能跟不上,表象也是这个同步程序处理性能上不来,消息积压在 MQ 里面。
而且这里不能扩展消费者实例,为了确保数据一致性,Binlog 的顺序很重要,是绝对不能乱序的。 严格来说,对于每一个 MySQL 实例,整个处理链条都必须是单线程串行执行,MQ 的主题也必须设置为只有 1 个分区(队列),这样才能保证数据同步过程中的 Binlog 是严格有序的,写到目标数据库的数据才能是正确的。
但这里也要根据具体的业务来分析,比如
订单库,其实我们并不需要对订单库所有的更新操作都严格有序地执行,比如说 A 和 B 两个订单号不同的订单,这两个订单谁先更新谁后更新并不影响数据的一致性,因为这两个订单完全没有任何关系。但是同一个订单,如果更新的 Binlog 执行顺序错了,那同步出来的订单数据真的就错了。也就是说,我们只要保证每个订单的更新操作日志的顺序别乱就可以了。这种一致性要求称为因果一致性(Causal Consistency),有因果关系的数据之间必须要严格地保证顺序,没有因果关系的数据之间的顺序是无所谓的。
所以,这个时候我们就可以对订单ID进行hash,把同一个id丢进同一个分区了,这样就保证了因果一致性。于是就可以水平拓展我们的下游消费者实例了。
思考:
在我们这种数据同步架构下,如果说下游的某个同步程序或数据库出了问题,需要把 Binlog 回退到某个时间点然后重新同步,这个问题该怎么解决?
这个问题的解决方案是这样的。如果说,下游只有一个同步程序,那直接按照时间重置Canal实例的位点就可以了。但是,如果MQ的下游有多个消费者,这个时候就不能重置Canal里的位点了,否则会影响到其它的消费者。正确的做法是,在MQ的消费订阅上按照时间重置位点,这样只影响出问题的那个订阅。所以,这种架构下,MQ中的消息,最好将保存时间设置得长一些,比如保留3天。
第二十章
不停机更换数据库
上线同步程序,从旧库中复制数据到新库中,并实时保持同步;
上线双写订单服务,只读写旧库;
开启双写,同时停止同步程序;
开启对比和补偿程序,确保新旧数据库数据完全一样;
逐步切量读请求到新库上;
下线对比补偿程序,关闭双写,读写都切换到新库上;
下线旧库和订单服务的双写功能。
思考:关键就是做到有记录、可回滚。具体操作可依照具体业务来定。
第二十一章
使用 Kafka 存储海量原始数据
现代的消息队列,本质上就是分布式的流数据存储系统。Kafka 官方给自己的定位也是“分布式流数据平台”,不只是一个 MQ。受制于单节点的存储容量,Kafka 实际能存储的数据容量并不是无限的。
HDPS+HIVE
内容太多,讲的太粗,有时间自己去了解。
第二十二章
介绍了不同数据用不同的数据库:比如搜索用ES等。
第二十三章
new sql = mysql + nosql
简单地说,New SQL 就是兼顾了 Old SQL 和 No SQL 的优点:
完整地支持 SQL 和 ACID,提供和 Old SQL 隔离级别相当的事务能力;
高性能、高可靠、高可用,支持水平扩容。
像 Google 的 Cloud Spanner、国产的 OceanBase 以及开源的CockroachDB都属于 New SQL 数据库。Cockroach 这个英文单词是蟑螂的意思,所以一般我们都把 CockroachDB 俗称为小强数据库。
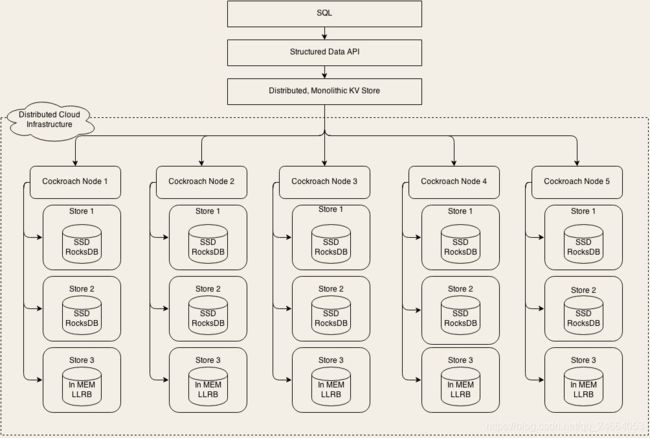
最上层是 SQL 层,SQL 层支持和关系型数据库类似的逻辑数据结构,比如说库、表、行和列这些逻辑概念。
SQL 层向下调用的是一个抽象的接口层 Structured Data API,实际实现这个 API 的是下面一层:Distributed, Monolithic KV Store,这就是一个分布式的 KV 存储系统。
我们先不深入进去看细节,从宏观层面上分析一下这个架构。
你可以看到,这个架构仍然是我们之间讲过的,大部分数据库都采用的二层架构:执行器和存储引擎。它的 SQL 层就是执行器,下面的分布式 KV 存储集群就是它的存储引擎。
那我们知道,MySQL 的存储引擎 InnoDB,实际上是基于文件系统的 B+ 树,
像 Hive 和 HBase,它们的存储引擎都是基于 HDFS 构建的。
那 CockroachDB 这种,使用分布式 KV 存储来作为存储引擎的设计,理论上也是可行的,并没有什么特别难以逾越的技术壁垒。
而且,使用分布式 KV 存储作为存储引擎,实现高性能、高可靠、高可用,以及支持水平扩容这些特性,就不是什么难事儿了,其中很多分布式 KV 存储系统已经做到了,这里面使用的一些技术和方法,大多我们在之前的课程中也都讲到过。
CockroachDB 在实现它的存储引擎这一层,就是大量地借鉴,甚至是直接使用了已有的一些成熟技术。
它的分片算法采用的是范围分片,我们之前也讲到过,范围分片对查询是最友好的,可以很好地支持范围扫描这一类的操作,这样有利于它支撑上层的 SQL 查询。
它采用Raft一致性协议来实现每个分片的高可靠、高可用和强一致。
这个 Raft 协议,它的一个理论基础,就是我们之前讲的复制状态机,并且在复制状态机的基础上,Raft 实现了集群自我监控和自我选举来解决高可用的问题。
Raft 也是一个被广泛采用的、非常成熟的一致性协议,比如 etcd 也是基于 Raft 来实现的。
CockroachDB 的元数据直接分布在所有的存储节点上,依靠流言协议来传播,这个流言协议,我们也讲到过,在 Redis Cluster 中也是用流言协议来传播元数据变化的。
CockroachDB 用上面这些成熟的技术解决了集群问题,在单机的存储引擎上,更是直接使用了 RocksDB 作为它的 KV 存储引擎。
RocksDB 也是值得大家关注的一个新的存储系统。你可以看到,CockroachDB 的存储引擎,也就是它的分布式 KV 存储集群,基本上没有什么大的创新,就是重用了已有的一些成熟的技术,这些技术在我们之前讲过的其他存储系统中,全部都见到过。我讲这些并没有贬低 CockroachDB 的意思,相反,站在巨人的肩膀上,才能看得更远,飞得更高,这是一种非常务实的做法
CockroachDB 能提供金融级的事务隔离性么?
CockroachDB 提供了另外两种隔离级别,分别是:Snapshot Isolation (SI) 和 Serializable Snapshot Isolation (SSI),其中 SSI 是 CockroachDB 默认的隔离级别。

SI 不会发生脏读、不可重复读,也不会发生幻读的情况,这个隔离级别似乎比 RR 还要好。
但是 SI 会有写倾斜问题。什么是写倾斜?
在 SI 级别下,由于采用快照的方式来实现事务的隔离,这个时候,如果并发地去更新主副卡余额,是有可能出现把主副卡余额之和扣减为负数的情况的。这种情况称为写倾斜。这里顺便提一句,写倾斜是普遍的译法,我个人觉得“倾斜”这个词翻译得并不准确,实际上它表达的,就是因为没有检测读写冲突,也没有加锁,导致数据写错了。
第二十四章
讲了rocksDB 这个讲的太粗略了,需要自己额外去学。