爬取图片并保存到本地
爬取图片保存到本地
- 网址
- 代码
- 结果
- python爬取百度图片
- 完整代码
网址
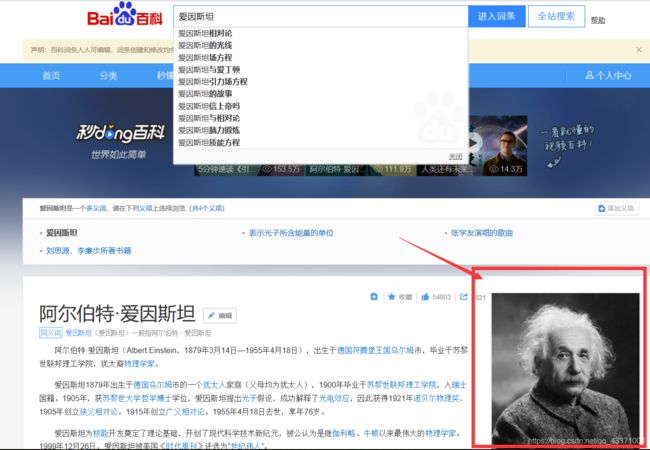
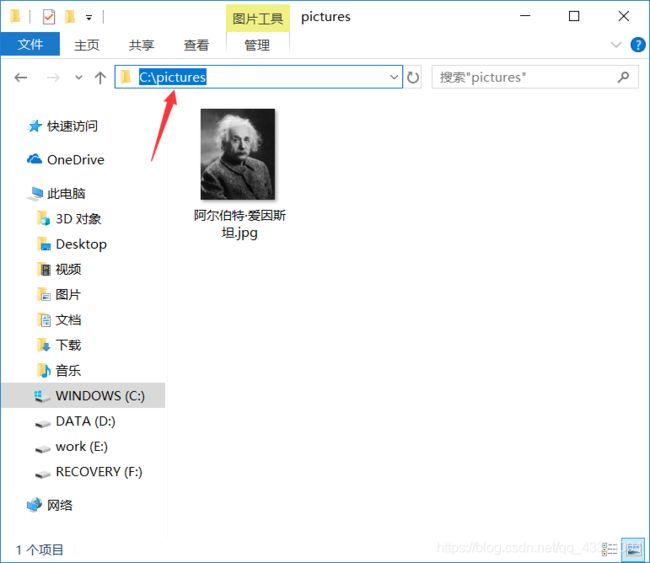
爬取百度百科爱因斯坦图片,并保存到 C:\pictures\ 下
https://baike.baidu.com/item/阿尔伯特·爱因斯坦/127535?fromtitle=爱因斯坦&fromid=122624&fr=aladdin
代码
import requests
from bs4 import BeautifulSoup
import os
url = 'https://baike.baidu.com/item/阿尔伯特·爱因斯坦/127535?fromtitle=%E7%88%B1%E5%9B%A0%E6%96%AF%E5%9D%A6&fromid=122624'
#url='http://baike.baidu.com/subview/6593456/6713831.htm'
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36'}
wb_data = requests.get(url, headers=headers)
#print(wb_data)
soup = BeautifulSoup(wb_data.content, 'lxml')
#print(soup)
def Saving(url,name):
#root = r"C:\Users\JF\Desktop\pictures\\"
root = r'C:\pictures\\'
path = root + name + '.jpg'
try:
if not os.path.exists(root):
os.mkdir(root)
if not os.path.exists(path):
print(url)
r = requests.get(url)
print(r)
with open(path, 'wb') as f:
f.write(r.content)
#f = r.replace(r, "1.jpg")
f.close()
print("文件保存成功")
else:
print("文件已存在")
except:
print("爬去失败")
def GetPicture():
PictureList = soup.select('div.summary-pic > a > img')
Picture =PictureList[0].get('src')
NameList = soup.select('dd.lemmaWgt-lemmaTitle-title > h1')
Name = NameList[0].text
LinkList = soup.select('a.link-inner')
#print(Name)
#print(Picture)
Saving(Picture, Name)
GetPicture()
结果
python爬取百度图片
这个【犀利了我的哥】大佬写的,python爬取百度苍老师的图片,很吊。
https://blog.csdn.net/xiligey1/article/details/73321152
我修改了路径,在C盘下新建一个pictures的文件夹,用来存放图片
string = 'C:\\pictures\\'+str(i + 1) + '.jpg'
完整代码
# -*- coding: utf-8 -*-
"""根据搜索词下载百度图片"""
import re
import sys
import urllib
import requests
def get_onepage_urls(onepageurl):
"""获取单个翻页的所有图片的urls+当前翻页的下一翻页的url"""
if not onepageurl:
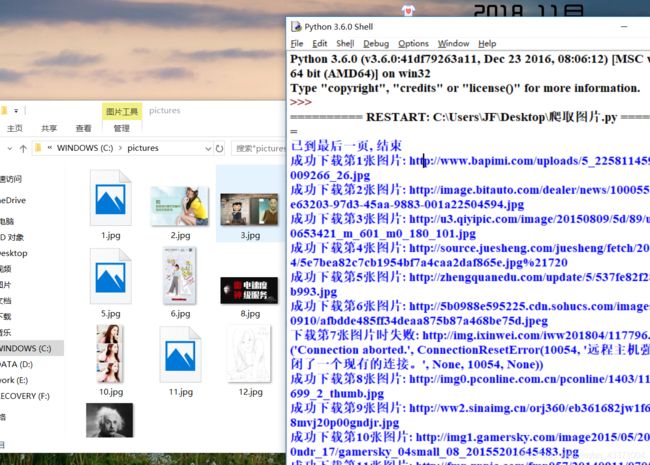
print('已到最后一页, 结束')
return [], ''
try:
html = requests.get(onepageurl)
html.encoding = 'utf-8'
html = html.text
except Exception as e:
print(e)
pic_urls = []
fanye_url = ''
return pic_urls, fanye_url
pic_urls = re.findall('"objURL":"(.*?)",', html, re.S)
fanye_urls = re.findall(re.compile(r'下一页'), html, flags=0)
fanye_url = 'http://image.baidu.com' + fanye_urls[0] if fanye_urls else ''
return pic_urls, fanye_url
def down_pic(pic_urls):
"""给出图片链接列表, 下载所有图片"""
for i, pic_url in enumerate(pic_urls):
try:
pic = requests.get(pic_url, timeout=15)
string = 'C:\\pictures\\'+str(i + 1) + '.jpg'
with open(string, 'wb') as f:
f.write(pic.content)
print('成功下载第%s张图片: %s' % (str(i + 1), str(pic_url)))
except Exception as e:
print('下载第%s张图片时失败: %s' % (str(i + 1), str(pic_url)))
print(e)
continue
if __name__ == '__main__':
keyword = '苍老师' # 关键词, 改为你想输入的词即可, 相当于在百度图片里搜索一样
url_init_first = r'http://image.baidu.com/search/flip?tn=baiduimage&ipn=r&ct=201326592&cl=2&lm=-1&st=-1&fm=result&fr=&sf=1&fmq=1497491098685_R&pv=&ic=0&nc=1&z=&se=1&showtab=0&fb=0&width=&height=&face=0&istype=2&ie=utf-8&ctd=1497491098685%5E00_1519X735&word='
url_init = url_init_first + urllib.parse.quote(keyword, safe='/')
all_pic_urls = []
onepage_urls, fanye_url = get_onepage_urls(url_init)
all_pic_urls.extend(onepage_urls)
fanye_count = 0 # 累计翻页数
while 1:
onepage_urls, fanye_url = get_onepage_urls(fanye_url)
fanye_count += 1
# print('第页' % str(fanye_count))
if fanye_url == '' and onepage_urls == []:
break
all_pic_urls.extend(onepage_urls)
down_pic(list(set(all_pic_urls)))
结果
谢谢支持。