Reinforcement Learning with Competitive Ensembles of Information-Constrained Primitives
利用信息约束基元的竞争集合强化学习
- Anirudh Goyal1, Shagun Sodhani1, Jonathan Binas1, Xue Bin Peng2
- Sergey Levine2, Yoshua Bengio1y
- 1Mila, Université de Montréal
- 2University of California, Berkeley yCIFAR Senior Fellow.
Abstract
Reinforcement learning agents that operate in diverse and complex environments can benefit from the structured decomposition of their behavior. Often, this is addressed in the context of hierarchical reinforcement learning, where the aim is to decompose a policy into lower-level primitives or options, and a higher-level meta-policy that triggers the appropriate behaviors for a given situation. However, the meta-policy must still produce appropriate decisions in all states. In this work, we propose a policy design that decomposes into primitives, similarly to hierarchical reinforcement learning, but without a high-level meta-policy. Instead, each primitive can decide for themselves whether they wish to act in the current state. We use an information-theoretic mechanism for enabling this decentralized decision: each primitive chooses how much information it needs about the current state to make a decision and the primitive that requests the most information about the current state acts in the world. The primitives are regularized to use as little information as possible, which leads to natural competition and specialization. We experimentally demonstrate that this policy architecture improves over both flat and hierarchical policies in terms of generalization.
在各种复杂环境中运行的强化学习代理可以从其行为的结构化分解中受益。通常,这是在分层强化学习的背景下解决的,其中目标是将策略分解为较低级别的原语或选项,以及触发针对给定情况的适当行为的较高级别元策略。但是,元政策仍必须在所有州制定适当的决策。在这项工作中,我们提出了一种分解为原语的策略设计,类似于分层强化学习,但没有高级元策略。相反,每个原语可以自己决定他们是否希望在当前状态下行动。我们使用信息理论机制来实现这种分散的决策:每个原语选择它需要多少关于当前状态的信息来做出决定,以及请求关于当前状态的最多信息的原语在世界中起作用。原语被规范化以尽可能少地使用信息,这导致自然竞争和专业化。我们通过实验证明,这种策略体系结构在泛化方面优于扁平化和分层策略。
Introduction
Learning policies that generalize to new environments or tasks is a fundamental challenge in rein-forcement learning. While deep reinforcement learning has enabled training powerful policies, which outperform humans on specific, well-defined tasks [24], their performance often diminishes when the properties of the environment or the task change to regimes not encountered during training.
This is in stark contrast to how humans learn, plan, and act: humans can seamlessly switch between different aspects of a task, transfer knowledge to new tasks from remotely related but essentially distinct prior experience, and combine primitives (or skills) used for distinct aspects of different tasks in meaningful ways to solve new problems. A hypothesis hinting at the reasons for this discrepancy is that the world is inherently compositional, such that its features can be described by compositions of small sets of primitive mechanisms [26]. Since humans seem to benefit from learning skills and learning to combine skills, it might be a useful inductive bias for the learning models as well.
学习可以推广到新环境或任务的政策是加强学习的基本挑战。虽然深度强化学习已经使培训能够在特定的,明确定义的任务中胜过人类[24],但是当环境属性或任务改变为培训期间未遇到的制度时,他们的表现往往会减弱。
这与人类学习,计划和行动的方式形成鲜明对比:人类可以在任务的不同方面之间无缝切换,将知识从远程相关但基本上不同的先前经验转移到新任务,并结合用于区分的原始(或技能)以有意义的方式解决新问题的不同任务的各个方面。暗示这种差异的原因的一个假设是世界本质上是成分的,因此它的特征可以通过一小组原始机制的组合来描述[26]。由于人类似乎从学习技能和学习结合技能中受益,因此它也可能是学习模型的有用归纳偏见。
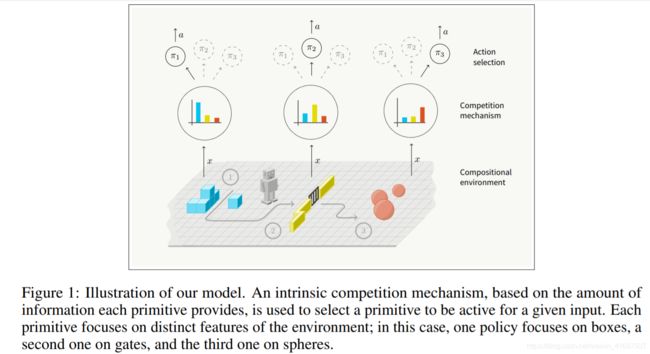
图1:我们模型的图示。 基于每个基元提供的信息量的内在竞争机制用于选择对于给定输入有效的基元。 每个原语都侧重于环境的不同特征; 在这种情况下,一个政策侧重于箱子,第二个政策侧重于大门,第三个政策侧重于球体。
This is addressed to some extent by the hierarchical reinforcement learning (HRL) methods, which focus on learning representations at multiple spatial and temporal scales, thus enabling better explo-ration strategies and improved generalization performance [9, 36, 10, 19]. However, hierarchical approaches rely on some form of learned high-level controller, which decides when to activate different components in the hierarchy. While low-level sub-policies can specialize to smaller portions of the state space, the top-level controller (or master policy) needs to know how to deal with any given state. That is, it should provide optimal behavior for the entire accessible state space. As the master policy is trained on a particular state distribution, learning it in a way that generalizes to new environments effectively can, therefore, become the bottleneck for such approaches [31, 3].
We argue, and empirically show, that in order to achieve better generalization, the interaction between the low-level primitives and the selection thereof should itself be performed without requiring a single centralized network that understands the entire state space. We, therefore, propose a fully decentralized approach as an alternative to standard HRL, where we only learn a set of low-level primitives without learning a high-level controller. We construct a factorized representation of the policy by learning simple “primitive” policies, which focus on distinct regions of the state space. Rather than being gated by a single meta-policy, the primitives directly compete with one another to determine which one should be active at any given time, based on the degree to which their state encoders “recognize” the current state input.
We frame the problem as one of information transfer between the current state and a dynamically selected primitive policy. Each policy can by itself decide to request information about the current state, and the amount of information requested is used to determine which primitive acts in the current state. Since the amount of state information that a single primitive can access is limited, each primitive is encouraged to use its resources wisely. Constraining the amount of accessible information in this way naturally leads to a decentralized competition and decision mechanism where individual primitives specialize in smaller regions of the state space. We formalize this information-driven objective based on the variational information bottleneck. The resulting set of competing primitives achieves both a meaningful factorization of the policy and an effective decision mechanism for which primitives to use. Importantly, not relying on a centralized meta-policy means that individual primitive mechanisms can be recombined in a “plug-and-play” fashion, and can be transferred seamlessly to new environments.
这在一定程度上通过分层强化学习(HRL)方法得到解决,该方法侧重于在多个空间和时间尺度上学习表示,从而实现更好的探索策略和改进的泛化性能[9,36,10,19]。但是,分层方法依赖于某种形式的学习型高级控制器,它决定何时激活层次结构中的不同组件。虽然低级子策略可以专注于状态空间的较小部分,但顶级控制器(或主策略)需要知道如何处理任何给定状态。也就是说,它应该为整个可访问状态空间提供最佳行为。由于主要政策是针对特定的州分布进行培训的,因此以有效推广到新环境的方式进行学习可能会成为这种方法的瓶颈[31,3]。
我们争论并且凭经验证明,为了实现更好的泛化,低级原语与其选择之间的交互本身应该在不需要理解整个状态空间的单个集中式网络的情况下执行。因此,我们提出了一种完全分散的方法作为标准HRL的替代方法,我们只学习一组低级原语而无需学习高级控制器。我们通过学习简单的“原始”策略来构建策略的分解表示,该策略关注于状态空间的不同区域。基于状态编码器“识别”当前状态输入的程度,基元不是由单个元策略门控而是直接相互竞争以确定在任何给定时间哪个应该是活动的。
我们将问题框定为当前状态和动态选择的原始策略之间的信息传递之一。每个策略可以自己决定请求有关当前状态的信息,并且所请求的信息量用于确定哪个原语在当前状态中起作用。由于单个基元可以访问的状态信息量是有限的,因此鼓励每个基元明智地使用其资源。以这种方式约束可访问信息量自然会导致分散的竞争和决策机制,其中各个原语专注于状态空间的较小区域。我们基于变化的信息瓶颈正式化了这个信息驱动的目标。由此产生的竞争原语集实现了策略的有意义的分解和用于原语的有效决策机制。重要的是,不依赖于集中式元策略意味着可以以“即插即用”的方式重新组合各个原始机制,并且可以无缝地转移到新环境。
Contributions:
In summary, the contributions of our work are as follows: (1) We propose a method for learning and operating a set of functional primitives in a fully decentralized way, without requiring a high-level meta-controller to select active primitives (see Figure 1 for illustration). (2) We introduce an information-theoretic objective, the effects of which are twofold: a) it leads to the specialization of individual primitives to distinct regions of the state space, and b) it enables a competition mechanism, which is used to select active primitives in a decentralized manner. (3) We demonstrate the superior transfer learning performance of our model, which is due to the flexibility of the proposed framework regarding the dynamic addition, removal, and recombination of primitives. Decentralized primitives can be successfully transferred to larger or previously unseen environments, and outperform models with an explicit meta-controller for primitive selection.
总之,我们的工作贡献如下:(1)我们提出了一种以完全分散的方式学习和操作一组功能原语的方法,而不需要高级元控制器来选择活动原语(参见图 1用于说明)。 (2)我们引入了一个信息理论目标,其效果是双重的:a)它导致个体原语专门化到状态空间的不同区域,和b)它使竞争机制,用于选择 活跃的原语以分散的方式。 (3)我们证明了我们模型的优越的转移学习性能,这是由于所提出的框架在原语的动态添加,删除和重组方面的灵活性。 分散的基元可以成功地转移到更大或以前看不见的环境,并且优于具有用于基元选择的显式元控制器的模型。
Preliminaries

Information-Theoretic Decentralized Learning of Distinct Primitives
Our goal is to learn a policy, composed of multiple primitive sub-policies, to maximize average returns over T -step interactions for a distribution of tasks. Simple primitives which focus on solving a part of the given task (and not the complete task) should generalize more effectively, as they can be applied to similar aspects of different tasks (subtasks) even if the overall objective of the tasks are drastically different. Learning primitives in this way can also be viewed as learning a factorized representation of a policy, which is composed of several independent policies.
Our proposed approach consists of three components: 1) a mechanism for restricting a particular primitive to a subset of the state space; 2) a competition mechanism between primitives to select the most effective primitive for a given state; 3) a regularization mechanism to improve the generalization performance of the policy as a whole. We consider experiments with both fixed and variable sets of primitives and show that our method allows for primitives to be added or removed during training, or recombined in new ways. Each primitive is represented by a differentiable, parameterized function approximator, such as a neural network.
我们的目标是学习由多个原始子策略组成的策略,以最大化T -step交互的平均回报以分配任务。专注于解决给定任务的一部分(而不是完整任务)的简单原语应该更有效地概括,因为它们可以应用于不同任务(子任务)的类似方面,即使任务的总体目标是截然不同的。以这种方式学习原语也可以被视为学习策略的分解表示,该策略由若干独立策略组成。
我们提出的方法包括三个部分:1)用于将特定基元限制到状态空间的子集的机制; 2)基元之间的竞争机制,为给定状态选择最有效的原语; 3)正规化机制,以提高整个政策的泛化绩效。我们考虑使用固定和可变原语集进行实验,并表明我们的方法允许在训练期间添加或删除基元,或以新方式重新组合。每个基元由可微分的参数化函数逼近器表示,例如神经网络。
Primitives with an Information Bottleneck
To encourage each primitive to encode information from a particular part of state space, we limit the amount of informa-tion each primitive can access from the state. In particular, each primitive has an information bottleneck with respect to the input state, preventing it from using all the information from the state.
为了鼓励每个原语对来自状态空间的特定部分的信息进行编码,我们限制每个原语可以从状态访问的信息量。 特别地,每个原语具有关于输入状态的信息瓶颈,从而阻止它使用来自该状态的所有信息。

The encoder output Z is meant to represent the information
about the current state S that an individual primitive believes
is important to access in order to perform well. The decoder
takes this encoded information and produces a distribution
over the actions A. Following the variational information bottleneck objective [2], we penalize the
KL divergence of Z and the prior
编码器输出Z用于表示信息
关于个体原始人认为的当前状态S.
访问是很重要的,以便表现良好。 解码器
获取此编码信息并生成分布
行动A.遵循变化的信息瓶颈目标[2],我们惩罚了
Z和先前的KL分歧
![]()
In other words, a primitive pays an “information cost” proportional to Lk for accessing the information
about the current state.
In the experiments below, we fix the prior to be a unit Gaussian. In the general case, we can learn the
prior as well and include its parameters in θ. The information bottleneck encourages each primitive to
limit its knowledge about the current state, but it will not prevent multiple primitives from specializing
to similar parts of the state space. To mitigate this redundancy, and to make individual primitives focus
on different regions of the state space, we introduce an information-based competition mechanism to
encourage diversity among the primitives, as described in the next section.
换句话说,基元支付与Lk成比例的“信息成本”以访问信息
关于目前的状况。
在下面的实验中,我们将之前的单位修正为高斯。 在一般情况下,我们可以学习
先前也将其参数包含在θ中。 信息瓶颈鼓励每个原语
限制它对当前状态的了解,但它不会阻止多个原语专门化
到州空间的类似部分。 减轻这种冗余,并使各个原语集中
在国家空间的不同区域,我们引入了一种基于信息的竞争机制
鼓励原语之间的多样性,如下一节所述。
Competing Information-Constrained Primitives
We can use the information measure from equation 1 to define a selection mechanism for the primitives
without having to learn a centralized meta-policy. The idea is that the information content of an
individual primitive encodes its effectiveness in a given state s such that the primitive with the highest
我们可以使用等式1中的信息度量来定义基元的选择机制
无需学习集中式元策略。 这个想法是一个信息的内容
个体原语在给定状态s中编码其有效性,使得具有最高的原语

The resulting weights αk can be treated as a probability distribution that can be used in different ways:
form a mixture of primitives, sample a primitive using from the distribution, or simply select the
primitive with the maximum weight. The selected primitive is then allowed to act in the environment.
Trading Reward and Information: To make the different primitives compete for competence in
the different regions of the state space, the environment reward is distributed according to their
得到的权重αk可以被视为可以以不同方式使用的概率分布:
形成基元的混合,从分布中使用原始样本,或者只是选择
最大权重的原始。 然后允许所选原语在环境中起作用。
交易奖励和信息:使不同的原始人竞争能力
在国家空间的不同区域,环境奖励是根据他们分配的
![]()
reward for accessing more information about the current state, but that primitive also pays the price
(equal to information cost) for accessing the state information. Hence, a primitive that does not
access any state information is not going to get any reward. The information bottleneck and the
competition mechanism, when combined with the overall reward maximization objective, should lead
to specialization of individual primitives to distinct regions in the state space.
That is, each primitive should specialize in a part of the state space that it can reliably associate
rewards with. Since the entire ensemble still needs to understand all of the state space for the given
task, different primitives need to encode and focus on different parts of the state space.
获取有关当前状态的更多信息的奖励,但该原语也支付了价格
(等于信息成本)用于访问状态信息。 因此,一个原始的没有
访问任何州的信息都不会得到任何奖励。 信息瓶颈和
竞争机制,当与整体奖励最大化目标相结合时,应该引领
将各个原语专门化到状态空间中的不同区域。
也就是说,每个原语应该专注于它可以可靠地关联的状态空间的一部分
奖励。 由于整个集合仍然需要了解给定的所有状态空间
任务,不同的原语需要编码并专注于状态空间的不同部分。
Regularization of the Combined Representation
To encourage a diverse set of primitive configurations and to make sure that the model does not collapse to a single primitive (which remains active at all times), we introduce an additional regularization
term,
为了鼓励各种原始配置并确保模型不会崩溃到单个原语(始终保持活动状态),我们引入了一个额外的正则化
术语,

Objective and Algorithm Summary
Our overall objective function consists of 3 terms,
我们的总体目标函数包括3个术语,


Related Work
There are a wide variety of hierarchical reinforcement learning approaches[34, 9, 10]. One of the
most widely applied HRL framework is the Options framework ([36]). An option can be thought of
as an action that extends over multiple timesteps thus providing the notion of temporal abstraction or
subroutines in an MDP. Each option has its own policy (which is followed if the option is selected)
and the termination condition (to stop the execution of that option). Many strategies are proposed for
discovering options using task-specific hierarchies, such as pre-defined sub-goals [16], hand-designed
features [12], or diversity-promoting priors [8, 11]. These approaches do not generalize well to new
tasks. [4] proposed an approach to learn options in an end-to-end manner by parameterizing the
intra-option policy as well as the policy and termination condition for all the options. Eigen-options
[21] use the eigenvalues of the Laplacian (for the transition graph induced by the MDP) to derive an
intrinsic reward for discovering options as well as learning an intra-option policy.
In this work, we consider sparse reward setup with high dimensional action spaces. In such a scenario,
performing unsupervised pretraining or using auxiliary rewards leads to much better performance
[13, 12, 16]. Auxiliary tasks such as motion imitation have been applied to learn motor primitives
that are capable of performing a variety of sophisticated skills [20, 28, 23, 22].
Our work is also related to the Neural Module Network family of architectures [3, 17, 30] where
the idea is to learn modules that can perform some useful computation like solving a subtask and
a controller that can learn to combine these modules for solving novel tasks. The key difference
between our approach and all the works mentioned above is that we learn functional primitives in a
fully decentralized way without requiring any high-level meta-controller or master policy.
有各种各样的等级强化学习方法[34,9,10]。其中一个
最广泛应用的HRL框架是Options框架([36])。可以考虑一个选项
作为一个延伸多个时间步长的动作,从而提供时间抽象或概念
MDP中的子程序。每个选项都有自己的策略(如果选择了该选项,则会遵循该策略)
和终止条件(停止执行该选项)。提出了许多策略
使用任务特定的层次结构发现选项,例如手工设计的预定义子目标[16]
特征[12],或促进多样性的先验[8,11]。这些方法并没有很好地概括为新的
任务。 [4]提出了一种通过参数化方法以端到端的方式学习选项的方法
内部期权政策以及所有期权的政策和终止条件。本征选项
[21]使用拉普拉斯算子的特征值(对于由MDP引起的转移图)来推导出
发现期权以及学习期权内政策的内在回报。
在这项工作中,我们考虑使用高维动作空间的稀疏奖励设置。在这种情况下,
执行无人监督的预训练或使用辅助奖励可以获得更好的性能
[13,12,16]。已经应用诸如运动模仿之类的辅助任务来学习运动原语
能够执行各种复杂技能[20,28,23,22]。
我们的工作还涉及神经模块网络系列架构[3,17,30]
我的想法是学习可以执行一些有用计算的模块,比如解决子任务和
一个控制器,可以学习组合这些模块来解决新任务。关键的区别
我们的方法和上面提到的所有工作之间的关系是我们在a中学习函数原语
完全分散的方式,无需任何高级元控制器或主策略。
Experimental Results
In this section, we briefly outline the tasks that we used to evaluate our proposed method and direct
the reader to the appendix for the complete details of each task along with the hyperparameters used
for the model. The code is provided with the supplementary material. We designed experiments to
address the following questions:a) Learning primitives – Can an ensemble of primitives be learned
over a distribution of tasks? b) Transfer Learning using primitives – Can the learned primitives
be transferred to unseen/unsolvable sparse environments? c) Comparison to centralized methods
– How does our method compare to approaches where the primitives are trained using an explicit
meta-controller, in a centralized way?
Baselines. We compare our proposed method to the following baselines:
a) Option Critic [4] – We extended the author’s implementation 2 of the Option Critic architecture
and experimented with multiple variations in the terms of hyperparameters and state/goal encoding.
None of these yielded reasonable performance in partially observed tasks, so we omit it from the
results.
b) MLSH (Meta-Learning Shared Hierarchy) [13] – This method uses meta-learning to learn subpolicies that are shared across tasks along with learning a task-specific high-level master. It also
requires a phase-wise training schedule between the master and the sub-policies to stabilize training.
We use the MLSH implementation provided by the authors 3
.
c) Transfer A2C: In this method, we first learn a single policy on the one task and then transfer the
policy to another task, followed by fine-tuning in the second task.
在本节中,我们将简要概述用于评估我们提出的方法和指导的任务
读者到附录中了解每项任务的完整细节以及所使用的超参数
对于模型。代码提供补充材料。我们设计了实验
解决以下问题:a)学习原语 - 可以学习原始集合
在分配任务? b)使用原语传递学习 - 学习原语
转移到看不见/无法解决的稀疏环境? c)与集中方法的比较
- 我们的方法如何与使用显式训练基元的方法进行比较
元控制器,以集中的方式?
基线。我们将我们提出的方法与以下基线进行比较:
a)期权评论 [4] - 我们扩展了作者对Option Critic架构的实现2
并且在超参数和状态/目标编码方面进行了多种变化的实验。
这些都没有在部分观察到的任务中产生合理的性能,所以我们从中省略了它
结果。
b)MLSH(元学习共享层次结构)[13] - 该方法使用元学习来学习跨任务共享的子策略以及学习任务特定的高级主控。它也是
需要在主人和子政策之间采用逐步培训计划来稳定培训。
我们使用作者提供的MLSH实现3
。
c)转移A2C:在这种方法中,我们首先学习一项任务的单一政策,然后转移
策略到另一个任务,然后在第二个任务中微调。
5.1 Multi-Task Training
We evaluate our model in a partially-observable 2D multi-task environment called Minigrid, similar to
the one introduced in [6]. The environment is a two-dimensional grid with a single agent, impassable
walls, and many objects scattered in the environment. The agent is provided with a natural language
string that specifies the task that the agent needs to complete. The setup is partially observable
and the agent only gets the small, egocentric view of the grid (along with the natural language task
description). We consider three tasks here: the Pickup task (A), where the agent is required to pick up
an object specified by the goal string, the Unlock task (B) where the agent needs to unlock the door
(there could be multiple keys in the environment and the agent needs to use the key which matches
the color of the door) and the UnlockPickup task ©, where the agent first needs to unlock a door
that leads to another room. In this room, the agent needs to find and pick up the object specified by
the goal string. Additional implementation details of the environment are provided in appendix D.
Details on the agent model can be found in appendix D.3.
We train agents with varying numbers of primitives on various tasks – concurrently, as well as in
transfer settings. The different experiments are summarized in Figs. 3 and 5. An advantage of the
multi-task setting is that it allows for quantitative interpretability as to when and which primitives are
being used. The results indicate that a system composed of multiple primitives generalizes more easily
to a new task, as compared to a single policy. We further demonstrate that several primitives can be
combined dynamically and that the individual primitives respond to stimuli from new environments
when trained on related environments.
我们在名为Minigrid的部分可观察的2D多任务环境中评估我们的模型,类似于
[6]中介绍的那个。环境是一个二维网格,只有一个代理,无法通过
墙壁和许多散落在环境中的物体。代理商提供自然语言
string,指定代理程序需要完成的任务。该设置是部分可观察的
并且代理只获得网格的小型,以自我为中心的视图(以及自然语言任务)
描述)。我们在这里考虑三个任务:提货任务(A),代理需要在那里提取
由目标字符串指定的对象,解锁任务(B),代理需要解锁门
(环境中可能有多个密钥,代理需要使用匹配的密钥
门的颜色)和UnlockPickup任务(C),代理首先需要解锁门
通往另一个房间。在这个房间里,代理需要查找并获取指定的对象
目标字符串。附录D中提供了有关环境的其他实施细节。
有关代理模型的详细信息,请参见附录D.3。
我们在各种任务上训练具有不同数量原语的代理 - 同时以及同时
转移设置。不同的实验总结在图1和2中。 3和5.的一个优点
多任务设置是它允许对何时和哪些基元进行定量解释
正在使用。结果表明,由多个原语组成的系统更容易概括
与单一政策相比,新任务。我们进一步证明了几个原语可以
动态组合并且各个基元响应来自新环境的刺激
在相关环境中接受培训。
Do Learned Primitives Help in Transfer Learning?
We now evaluate our approach in the settings where the adaptation to the changes in the task is vital.
The argument in the favor of modularity is that it enables better knowledge transfer between related
task. This transfer is more effective when the tasks are closely related as the model would only have
to learn how to compose the already learned primitives. In general, it is difficult to determine how
“closely” related two tasks are and the inductive bias of modularity could be harmful if the two tasks
are quite different. In such cases, we could add new primitives (which would have to be learned) and
still obtain a sample-efficient transfer as some part of the task structure would already have been
captured by the pretrained primitives. This approach can be extended by adding primitives during
training which provides a seamless way to combine knowledge about different tasks to solve more
complex tasks. We investigate here the transfer properties of a primitive trained in one environment
and transferred to a different one.
Continuous control for ant maze We evaluate the transfer performance of pretrained primitives
on the cross maze environment [15]. Here, a quadrupedal robot must walk to the different goals along
the different paths (see Appendix G for details). The goal is randomly chosen from a set of available
goals at the start of each episode. We pretrain a policy (see model details in Appendix G.1) with a
motion reward in an environment which does not have any walls (similar to [15]), and then transfer
the policy to the second task where the ant has to navigate to a random goal chosen from one of the 3
(or 10) available goal options. For our model, we make four copies of the pretrained policies and
then finetune the model using the pretrained policies as primitives. We compare to both MLSH [13]
and option-critic [4]. All these baselines have been pretrained in the same manner. As evident from
Figure 5, our method outperforms the other approaches. The fact that the initial policies successfully
adapt to the transfer environment underlines the flexibility of our approach.
我们现在在适应任务变化至关重要的环境中评估我们的方法。
支持模块化的论点是,它可以在相关之间实现更好的知识转移
任务。当任务与模型只有密切相关时,这种转移更有效
学习如何撰写已经学过的原语。一般来说,很难确定如何
“紧密”相关的两个任务是,如果这两个任务,模块化的归纳偏差可能是有害的
是完全不同的。在这种情况下,我们可以添加新的原语(必须学习)和
因为任务结构的某些部分已经存在,所以仍然可以获得样本有效的转移
由预训练的原语捕获。可以通过在期间添加基元来扩展此方法
培训提供了一种无缝的方式来结合不同任务的知识来解决更多问题
复杂的任务。我们在这里研究在一个环境中训练的基元的传递属性
并转移到另一个。
对蚂蚁迷宫的连续控制我们评估预训练基元的传递性能
在十字迷宫环境[15]。在这里,四足机器人必须走向不同的目标
不同的路径(详见附录G)。目标是从一组可用的中随机选择的
每集开头的目标。我们预先制定了一项政策(见附录G.1中的模型详情)
在没有任何墙壁的环境中运动奖励(类似于[15]),然后转移
第二项任务的策略,其中蚂蚁必须导航到从3中选择的一个中选择的随机目标
(或10)可用的目标选项。对于我们的模型,我们制作了四份预训练政策和
然后使用预训练的策略作为基元来微调模型。我们比较MLSH [13]
和期权评论家[4]。所有这些基线都以相同的方式进行了预训练。从中可以看出
图5,我们的方法优于其他方法。初始政策成功的事实
适应转移环境强调了我们方法的灵活性。
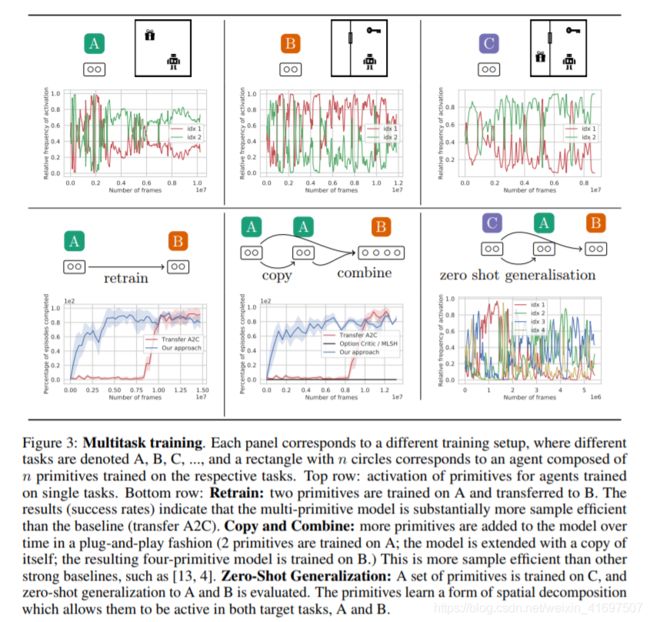
Figure 3: Multitask training. Each panel corresponds to a different training setup, where different
tasks are denoted A, B, C, …, and a rectangle with n circles corresponds to an agent composed of
n primitives trained on the respective tasks. Top row: activation of primitives for agents trained
on single tasks. Bottom row: Retrain: two primitives are trained on A and transferred to B. The
results (success rates) indicate that the multi-primitive model is substantially more sample efficient
than the baseline (transfer A2C). Copy and Combine: more primitives are added to the model over
time in a plug-and-play fashion (2 primitives are trained on A; the model is extended with a copy of
itself; the resulting four-primitive model is trained on B.) This is more sample efficient than other
strong baselines, such as [13, 4]. Zero-Shot Generalization: A set of primitives is trained on C, and
zero-shot generalization to A and B is evaluated. The primitives learn a form of spatial decomposition
which allows them to be active in both target tasks, A and B.
图3:多任务培训。每个面板对应不同的训练设置,其中不同
任务表示为A,B,C,…,并且具有n个圆圈的矩形对应于由…组成的代理
n个原始人训练各自的任务。第一行:为受过训练的代理激活原语
单一任务。底行:重写:在A上训练两个原语并转移到B.
结果(成功率)表明多原始模型实际上更具样本效率
比基线(转移A2C)。 复制和组合:更多基元被添加到模型中
时间以即插即用的方式(2个原语在A上训练;模型扩展了一个副本
本身;得到的四原始模型在B上训练。)这比其他模型更有效
强大的基线,如[13,4]。 零射击泛化:在C上训练一组原语,和
评估对A和B的零射击泛化。原语学习一种空间分解的形式
这允许它们在目标任务A和B中都是活动的。
Learning Ensembles of Functional Primitives
We evaluate our approach on a number of RL environments to show that we can indeed learn sets of
primitive policies focusing on different aspects of a task and collectively solving it.
Motion Imitation. To test the scalability of the proposed method, we present a series of tasks from
the motion imitation domain. In these tasks, we train a simulated 2D biped character to perform
a variety of highly dynamic skills by imitating motion capture clips recorded from human actors.
我们在许多RL环境中评估我们的方法,以表明我们确实可以学习一些
原始政策侧重于任务的不同方面并集体解决它。
运动模仿为了测试所提方法的可扩展性,我们提出了一系列任务
动作模仿领域。 在这些任务中,我们训练模拟的2D Biped角色来执行
通过模仿从人类演员录制的动作捕捉剪辑,各种高度动态的技能。

Snapshots of some of the learned motions are shown in Figure 6.4 To analyze the specialization of the
various primitives, we computed 2D embeddings of states and goals which each primitive is active in,
and the actions proposed by the primitives. Figure 7 illustrates the embeddings computed with t-SNE
[41]. The embeddings show distinct clusters for the primitives, suggesting a degree of specialization
of each primitive to certain states, goals, and actions.
图6.4显示了一些学习动作的快照。分析了该动作的特殊性
各种基元,我们计算了每个基元活跃的状态和目标的二维嵌入,
以及原始人提出的行动。 图7说明了用t-SNE计算的嵌入
[41]。 嵌入显示了基元的不同聚类,表明了一定程度的专业化
每个原语对某些状态,目标和行为的影响。

图4:持续学习场景:我们考虑我们培训的持续学习场景
两个目标位置的2个原语,然后在4个目标位置上转移(和微调)然后转移(和
微调)8个进球位置。 左侧的图显示基元保持激活状态。 坚实的
绿线显示任务之间的边界,右侧的图显示样本数
由我们的模型和跨不同任务的转移基线模型。 我们观察到了
建议的模型比基线采用更少的步骤(以类似方式训练的A2C政策)和
随着任务变得越来越困难,样本数量方面的差距不断增大。

图5:左:多任务设置,我们在训练中表明我们能够训练8个基元
混合了4项任务。 右:不同Ant Maze任务的成功率。 测量成功率
作为蚂蚁能够达到目标的次数(基于500个采样轨迹)。
6 Summary and Discussion
We present a framework for learning an ensemble of primitive policies which can collectively solve
tasks in a decentralized fashion. Rather than relying on a centralized, learned meta-controller, the
selection of active primitives is implemented through an information-theoretic mechanism. The
learned primitives can be flexibly recombined to solve more complex tasks. Our experiments show
that, on a partially observed “Minigrid” task and a continuous control “ant maze” walking task, our
method can enable better transfer than flat policies and hierarchical RL baselines, including the
Meta-learning Shared Hierarchies model and the Option-Critic framework. On Minigrid, we show
how primitives trained with our method can transfer much more successfully to new tasks and on the
ant maze, we show that primitives initialized from a pretrained walking control can learn to walk to
different goals in a stochastic, multi-modal environment with nearly double the success rate of a more
conventional hierarchical RL approach, which uses the same pretraining but a centralized high-level
policy.
The proposed framework could be very attractive for continual learning settings, where one could
add more primitive policies over time. Thereby, the already learned primitives would keep their focus
on particular aspects of the task, and newly added ones could specialize on novel aspects.
我们提出了一个框架,用于学习可以集体解决的原始政策集合
以分散的方式完成任务。而不是依赖于集中的,学习过的元控制器
通过信息理论机制实现活动基元的选择。该
学习的原语可以灵活地重新组合以解决更复杂的任务。我们的实验显示
在部分观察到的“Minigrid”任务和连续控制“蚂蚁迷宫”步行任务中,我们的
方法可以实现比平坦策略和分层RL基线更好的传输,包括
元学习共享层次结构模型和Option-Critic框架。在Minigrid上,我们展示
如何用我们的方法训练的原语可以更成功地转移到新的任务和
蚂蚁迷宫,我们表明从预训练的步行控制初始化的原始可以学会走路
随机,多模态环境中的不同目标,几乎是成功率的两倍
传统的分层RL方法,它使用相同的预训练但集中的高级别
政策。
拟议的框架对于持续学习环境非常有吸引力
随着时间的推移添加更原始的政因此,已经学过的原语将保持其焦点
关于任务的特定方面,新增的可以专注于新颖的方面。

图6:政策学习动作的快照。 上:参考动画片段。 中间:模拟人物模仿参考运动。 底部:选择每个原语的概率。

图7:嵌入可视化每个基元活动的状态(S)和目标(G),以及原始人为动作模仿任务提出的动作(A)。 共有四个原语 训练有素。 基元产生不同的簇。
Acknowledgements
The authors acknowledge the important role played by their colleagues at Mila throughout the
duration of this work. The authors would like to thank Greg Wayne, Mike Mozer, Matthew Botvnick
for very useful discussions. The authors would also like to thank Nasim Rahaman, Samarth Sinha,
Nithin Vasisth, Hugo Larochelle, Jordan Hoffman, Ankesh Anand for feedback on the draft. The
authors are grateful to NSERC, CIFAR, Google, Samsung, Nuance, IBM, Canada Research Chairs,
Canada Graduate Scholarship Program, Nvidia for funding, and Compute Canada for computing
resources. We are very grateful to Google for giving Google Cloud credits used in this project.
作者承认他们在Mila的同事所扮演的重要角色这项工作的持续时间。 作者要感谢Greg Wayne,Mike Mozer,Matthew Botvnick非常有用的讨论。 作者还要感谢Nasim Rahaman,Samarth Sinha,
Nithin Vasisth,Hugo Larochelle,Jordan Hoffman,Ankesh Anand对选秀的反馈意见。该
作者感谢NSERC,CIFAR,谷歌,三星,Nuance,IBM,加拿大研究主席,
加拿大研究生奖学金计划,Nvidia资助计划,以及Compute Canada计算机
资源。 我们非常感谢Google提供此项目中使用的Google Cloud积分。
References
[1]Alessandro Achille and Stefano Soatto. Information dropout: learning optimal representations through noise. CoRR, abs/1611.01353, 2016. URL http://arxiv.org/abs/1611.01353.
[2]Alexander A. Alemi, Ian Fischer, Joshua V. Dillon, and Kevin Murphy. Deep variational information bottleneck. CoRR, abs/1612.00410, 2016. URL http://arxiv.org/abs/1612. 00410.
[3]Jacob Andreas, Dan Klein, and Sergey Levine. Modular multitask reinforcement learning with policy sketches. In Proceedings of the 34th International Conference on Machine Learning-Volume 70, pages 166–175. JMLR. org, 2017.
[4]Pierre-Luc Bacon, Jean Harb, and Doina Precup. The option-critic architecture. In AAAI, pages 1726–1734, 2017.
[5]Greg Brockman, Vicki Cheung, Ludwig Pettersson, Jonas Schneider, John Schulman, Jie Tang, and Wojciech Zaremba. Openai gym, 2016.
[6]Maxime Chevalier-Boisvert, Lucas Willems, and Suman Pal. Minimalistic gridworld environ-ment for openai gym. https://github.com/maximecb/gym-minigrid, 2018.
[7]Kyunghyun Cho, Bart Van Merriënboer, Caglar Gulcehre, Dzmitry Bahdanau, Fethi Bougares, Holger Schwenk, and Yoshua Bengio. Learning phrase representations using rnn encoder-decoder for statistical machine translation. arXiv preprint arXiv:1406.1078, 2014.
[8]Christian Daniel, Gerhard Neumann, and Jan Peters. Hierarchical relative entropy policy search. In Artificial Intelligence and Statistics, pages 273–281, 2012.
[9]Peter Dayan and Geoffrey E Hinton. Feudal reinforcement learning. In Advances in neural information processing systems, pages 271–278, 1993.
[10]Thomas G Dietterich. Hierarchical reinforcement learning with the maxq value function decomposition. Journal of Artificial Intelligence Research, 13:227–303, 2000.
[11]Benjamin Eysenbach, Abhishek Gupta, Julian Ibarz, and Sergey Levine. Diversity is all you need: Learning skills without a reward function. arXiv preprint arXiv:1802.06070, 2018.
[12]Carlos Florensa, Yan Duan, and Pieter Abbeel. Stochastic neural networks for hierarchical reinforcement learning. arXiv preprint arXiv:1704.03012, 2017.
[13]K. Frans, J. Ho, X. Chen, P. Abbeel, and J. Schulman. Meta Learning Shared Hierarchies. arXiv e-prints, October 2017.
[14]Kevin Frans, Jonathan Ho, Xi Chen, Pieter Abbeel, and John Schulman. Meta learning shared hierarchies. arXiv preprint arXiv:1710.09767, 2017.
[15]Tuomas Haarnoja, Kristian Hartikainen, Pieter Abbeel, and Sergey Levine. Latent space policies for hierarchical reinforcement learning. arXiv preprint arXiv:1804.02808, 2018.
[16]Nicolas Heess, Srinivasan Sriram, Jay Lemmon, Josh Merel, Greg Wayne, Yuval Tassa, Tom Erez, Ziyu Wang, Ali Eslami, Martin Riedmiller, et al. Emergence of locomotion behaviours in rich environments. arXiv preprint arXiv:1707.02286, 2017.
[17]Justin Johnson, Bharath Hariharan, Laurens van der Maaten, Judy Hoffman, Li Fei-Fei, C Lawrence Zitnick, and Ross Girshick. Inferring and executing programs for visual rea-soning. In Proceedings of the IEEE International Conference on Computer Vision, pages 2989–2998, 2017.
[18]Diederik P Kingma and Jimmy Ba. Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980, 2014.
[19]Tejas D Kulkarni, Karthik Narasimhan, Ardavan Saeedi, and Josh Tenenbaum. Hierarchical deep reinforcement learning: Integrating temporal abstraction and intrinsic motivation. In Advances in neural information processing systems, pages 3675–3683, 2016.
[20]Libin Liu and Jessica Hodgins. Learning to schedule control fragments for physics-based characters using deep q-learning. ACM Transactions on Graphics, 36(3), 2017.
[21]Marlos C Machado, Marc G Bellemare, and Michael Bowling. A laplacian framework for option discovery in reinforcement learning. arXiv preprint arXiv:1703.00956, 2017.
[22]Josh Merel, Arun Ahuja, Vu Pham, Saran Tunyasuvunakool, Siqi Liu, Dhruva Tirumala, Nicolas Heess, and Greg Wayne. Hierarchical visuomotor control of humanoids. In International Conference on Learning Representations, 2019. URL https://openreview.net/forum? id=BJfYvo09Y7.
[23]Josh Merel, Leonard Hasenclever, Alexandre Galashov, Arun Ahuja, Vu Pham, Greg Wayne, Yee Whye Teh, and Nicolas Heess. Neural probabilistic motor primitives for humanoid control. In International Conference on Learning Representations, 2019. URL https://openreview. net/forum?id=BJl6TjRcY7.
[24]Volodymyr Mnih, Koray Kavukcuoglu, David Silver, Andrei A Rusu, Joel Veness, Marc G Bellemare, Alex Graves, Martin Riedmiller, Andreas K Fidjeland, Georg Ostrovski, et al. Human-level control through deep reinforcement learning. Nature, 518(7540):529, 2015.
[25]Volodymyr Mnih, Adria Puigdomenech Badia, Mehdi Mirza, Alex Graves, Timothy Lilli-crap, Tim Harley, David Silver, and Koray Kavukcuoglu. Asynchronous methods for deep reinforcement learning. In International conference on machine learning, pages 1928–1937, 2016.
[26]Giambattista Parascandolo, Niki Kilbertus, Mateo Rojas-Carulla, and Bernhard Schölkopf. Learning independent causal mechanisms. arXiv preprint arXiv:1712.00961, 2017.
[27]Adam Paszke, Sam Gross, Soumith Chintala, Gregory Chanan, Edward Yang, Zachary DeVito, Zeming Lin, Alban Desmaison, Luca Antiga, and Adam Lerer. Automatic differentiation in PyTorch. In NIPS Autodiff Workshop, 2017.
[28]Xue Bin Peng, Glen Berseth, Kangkang Yin, and Michiel Van De Panne. Deeploco: Dynamic locomotion skills using hierarchical deep reinforcement learning. ACM Trans. Graph., 36
(4):41:1–41:13, July 2017. ISSN 0730-0301. doi: 10.1145/3072959.3073602. URL http: //doi.acm.org/10.1145/3072959.3073602.
[29]Xue Bin Peng, Pieter Abbeel, Sergey Levine, and Michiel van de Panne. Deepmimic: Example-guided deep reinforcement learning of physics-based character skills. ACM Trans. Graph., 37(4):143:1–143:14, July 2018. ISSN 0730-0301. doi: 10.1145/3197517.3201311. URL http://doi.acm.org/10.1145/3197517.3201311.
[30]Clemens Rosenbaum, Ignacio Cases, Matthew Riemer, and Tim Klinger. Routing networks and the challenges of modular and compositional computation. arXiv preprint arXiv:1904.12774, 2019.
[31]Alexander Sasha Vezhnevets, Simon Osindero, Tom Schaul, Nicolas Heess, Max Jaderberg, David Silver, and Koray Kavukcuoglu. Feudal networks for hierarchical reinforcement learning. arXiv preprint arXiv:1703.01161, 2017.
[32]John Schulman, Philipp Moritz, Sergey Levine, Michael Jordan, and Pieter Abbeel. High-dimensional continuous control using generalized advantage estimation. arXiv preprint arXiv:1506.02438, 2015.
[33]John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms. arXiv preprint arXiv:1707.06347, 2017.
[34]Richard S Sutton, Andrew G Barto, et al. Reinforcement learning: An introduction. MIT press, 1998.
[35]Richard S. Sutton, David McAllester, Satinder Singh, and Yishay Mansour. Policy gradient methods for reinforcement learning with function approximation. In Proceedings of the 12th International Conference on Neural Information Processing Systems, NIPS’99, pages 1057– 1063, Cambridge, MA, USA, 1999. MIT Press. URL http://dl.acm.org/citation.cfm? id=3009657.3009806.
[36]Richard S Sutton, Doina Precup, and Satinder Singh. Between mdps and semi-mdps: A framework for temporal abstraction in reinforcement learning. Artificial intelligence, 112(1-2): 181–211, 1999.
[37]Richard S Sutton, Doina Precup, and Satinder Singh. Between mdps and semi-mdps: A framework for temporal abstraction in reinforcement learning. Artificial intelligence, 112(1-2): 181–211, 1999.
[38]Tijmen Tieleman and Geoffrey Hinton. Lecture 6.5-rmsprop, coursera: Neural networks for machine learning. University of Toronto, Technical Report, 2012.
[39]Naftali Tishby, Fernando C. N. Pereira, and William Bialek. The information bottleneck method. CoRR, physics/0004057, 2000. URL http://arxiv.org/abs/physics/0004057.
[40]Emanuel Todorov, Tom Erez, and Yuval Tassa. Mujoco: A physics engine for model-based control. In 2012 IEEE/RSJ International Conference on Intelligent Robots and Systems, pages 5026–5033. IEEE, 2012.
[41]Laurens van der Maaten and Geoffrey Hinton. Visualizing data using t-SNE. Journal of Machine Learning Research, 9:2579–2605, 2008. URL http://www.jmlr.org/papers/v9/ vandermaaten08a.html.
[42]Ronald J. Williams. Simple Statistical Gradient-Following Algorithms for Connectionist Reinforcement Learning. Machine Learning, 8(3-4):229–256, 1992. ISSN 0885-6125. doi: 10.1007/BF00992696. URL https://doi.org/10.1007/BF00992696.
[43]Yuhuai Wu, Elman Mansimov, Roger B Grosse, Shun Liao, and Jimmy Ba. Scalable trust-region method for deep reinforcement learning using kronecker-factored approximation. In Advances in neural information processing systems, pages 5279–5288, 2017.
Interpretation of the regularization term
The regularization term is given by

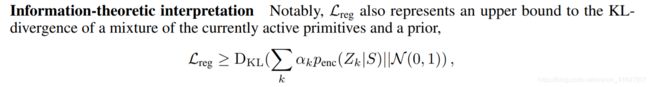
and thus can be regarded as a term limiting the information content of the mixture of all active
primitives. This arises from the convexity properties of the KL divergence, which directly lead to

Additional Results
B.1 2D Bandits Environment
In order to test if our approach can learn distinct primitives, we used the 2D moving bandits tasks
(introduced in [14]). In this task, the agent is placed in a 2D world and is shown the position of two
randomly placed points. One of these points is the goal point but the agent does not know which. We
use the sparse reward setup where the agent receives the reward of 1 if it is within a certain distance
of the goal point and 0 at all other times. Each episode lasts for 50 steps and to get the reward, the
learning agent must reach near the goal point in those 50 steps. The agent’s action space consists of 5
actions - moving in one of the four cardinal directions (top, down, left, right) and staying still.
为了测试我们的方法是否可以学习不同的原语,我们使用了2D移动强盗任务
(在[14]中介绍)。 在此任务中,代理程序放置在2D世界中,并显示为两个位置
随机放置点。 其中一个点是目标点,但代理人不知道哪个。 我们
使用稀疏奖励设置,如果代理在一定距离内,则获得1的奖励
目标点和其他所有时间的0。 每集都要持续50步并获得奖励
学习代理必须达到这50个步骤中的目标点附近。 代理人的行动空间由5组成
行动 - 沿四个主要方向之一(上,下,左,右)移动并保持静止。
B.1.1 Results for 2D Bandits
We want to answer the following questions:
-
- Can our proposed approach learn primitives which remain active throughout training?
-
- Can our proposed approach learn primitives which can solve the task?
We train two primitives on the 2D Bandits tasks and evaluate the relative frequency of activation of
the primitives throughout the training. It is important that both the primitives remain active. If only 1
primitive is acting most of the time, its effect would be the same as training a flat policy. We evaluate
the effectiveness of our model by comparing the success rate with a flat A2C baseline. Figure 8 shows
that not only do both the primitives remain active throughout training, our approach also outperforms
the baseline approach.
我们想回答以下问题:
- 1.我们提出的方法能否学习在整个培训过程中保持活跃的原语?
- 2.我们提出的方法可以学习可以解决任务的原语吗?
我们在2D Bandits任务上训练两个原语并评估激活的相对频率整个训练过程中的基元。 重要的是两个基元保持活动状态。 如果只有1原始人大部分时间都在行动,其效果与培训单一政策相同。 我们评估通过将成功率与平坦的A2C基线进行比较,我们的模型的有效性。 图8显示这两个基元不仅在训练中保持活跃,我们的方法也表现优异
基线方法。

图8:2D强盗任务的表现。 左:我们的模型比较(蓝色曲线 - 分散政策)与基线(红色曲线 - 扁平政策)的成功率表明了我们提出的方法的有效性。 右:基元激活的相对频率(归一化总计为1)。 在整个训练过程中都使用这两种原语。
B.2 Four-rooms Environment
We consider the Four-rooms gridworld environment [37] where the agent has to navigate its way
through a grid of four interconnected rooms to reach a goal position within the grid. The agent
can perform one of the following four actions: move up, move down, move left, move right. The
environment is stochastic and with 1/3 probability, the agent’s chosen action is ignored and a new
action (randomly selected from the remaining 3 actions) is executed ie the agent’s selected action
is executed with a probability of only 2/3 and the agent takes any of the 3 remaining actions with a
probability of 1/9 each.
我们考虑代理人必须导航的四房网格世界环境[37]通过四个互连房间的网格到达网格内的目标位置。代理
可以执行以下四个操作之一:向上移动,向下移动,向左移动,向右移动。该环境是随机的,以1/3的概率,代理人选择的行为被忽略而且是新的执行动作(从剩余的3个动作中随机选择),即代理的选定动作
以2/3的概率执行,并且代理使用a执行剩余的3个动作中的任何一个每个概率为1/9。
B.2.1 Task distribution for the Four-room Environment
In the Four-room environment, the agent has to navigate to a goal position which is randomly selected
from a set of goal positions. We can use the size of this set of goal positions to define a curriculum
of task distributions. Since the environment does not provide any information about the goal state,
the larger the goal set, harder is the task as the now goal could be any element from a larger set.
The choice of the set of goal states and the choice of curriculum does not affect the environment
dynamics. Specifically, we consider three tasks - Fourroom-v0, Fourroom-v1 and Fourroom-v2 with
the set of 2, 4 and 8 goal positions respectively. The set of goal positions for each task is fixed but not
known to the learning agent. We expect, and empirically verify, that the Fourroom-v0 environment
requires the least number of samples to be learned, followed by the Fourroom-v1 and the Fourroom-v2
environment (figure 6 in the paper).
在四室环境中,代理必须导航到随机选择的目标位置从一组目标位置。 我们可以使用这组目标位置的大小来定义课程任务分配。 由于环境不提供有关目标状态的任何信息,目标设定越大,任务就越难,因为现在的目标可能是来自更大集合的任何元素。目标状态集的选择和课程的选择不会影响环境动力学。 具体来说,我们考虑三个任务 - Fourroom-v0,Fourroom-v1和Fourroom-v2
分别为2个,4个和8个目标位置的集合。 每项任务的目标位置集是固定的,但不是
学习代理人都知道。 我们期望并凭经验验证Fourroom-v0环境
需要学习最少数量的样本,然后是Fourroom-v1和Fourroom-v2
环境(论文中的图6)。
B.2.2 Results for Four-rooms environment
We want to answer the following questions:
- Can our proposed approach learn primitives that remain active when training the agent over
a sequence of tasks? - Can our proposed approach be used to improve the sample efficiency of the agent over a
sequence of tasks?
To answer these questions, we consider two setups. In the baseline setup, we train a flat A2C policy
on Fourrooms-v0 till it achieves a 100 % success rate during evaluation. Then we transfer this policy
to Fourrooms-v1 and continue to train till it achieves a 100 % success rate during the evaluation
on Fourrooms-v1. We transfer the policy one more time to Fourrooms-v2 and continue to train the
policy until it reaches a 60% success rate. In the last task(Fourrooms-v2), we do not use 100% as the
threshold as the models do not achieve 100% for training even after training for 10M frames. We use
60% as the baseline models generally converge around this value.
In the second setup, we repeat this exercise of training on one task and transferring to the next task
with our proposed model. Note that even though our proposed model converges to a higher value
than 60% in the last task(Fourrooms-v2), we compare the number of samples required to reach 60%
success rate to provide a fair comparison with the baseline.
我们想回答以下问题:
1.我们提出的方法可以学习在训练代理时保持活跃的原语一系列任务?
2.我们提出的方法是否可用于提高代理的样本效率
任务顺序?
要回答这些问题,我们会考虑两种设置。在基线设置中,我们训练平坦的A2C策略在Fourrooms-v0上,直到它在评估期间达到100%的成功率。然后我们转移这个政策到Fourrooms-v1并继续训练,直到评估期间达到100%的成功率在Fourrooms-v1。我们将政策再次转移到Fourrooms-v2并继续训练策略直到达到60%的成功率。在上一个任务(Fourrooms-v2)中,我们不使用100%作为即使在训练10M帧之后,模型也未达到100%的训练阈值。我们用60%作为基线模型通常会收敛于此值。在第二个设置中,我们重复这项关于一项任务的培训并转移到下一个任务用我们提出的模型。请注意,即使我们提出的模型收敛到更高的值在上一个任务(Fourrooms-v2)中超过60%,我们比较了达到60%所需的样本数量成功率提供与基线的公平比较。
C Implementation Details
In this section, we describe the implementation details which are common for all the models. Other
task-specific details are covered in the respective task sections.
3. All the models (proposed as well as the baselines) are implemented in Pytorch 1.1 unless
stated otherwise. [27].
4. For Meta-Learning Shared Hierarchies [14] and Option-Critic [4], we adapted the author’s
implementations 5
for our environments.
5. During the evaluation, we use 10 processes in parallel to run 500 episodes and compute the
percentage of times the agent solves the task within the prescribed time limit. This metric is
referred to as the “success rate”.
6. The default time limit is 500 steps for all the tasks unless specified otherwise.
7. All the feedforward networks are initialized with the orthogonal initialization where the
input tensor is filled with a (semi) orthogonal matrix.
8. For all the embedding layers, the weights are initialized using the unit-Gaussian distribution.
9. The weights and biases for all the GRU model are initialized using the uniform distribution
在本节中,我们将描述所有模型通用的实现细节。其他任务特定的详细信息将在相应的任务部分中介绍。
3.所有模型(建议以及基线)都在Pytorch 1.1中实现,除非另有说明。 [27]。
4.对于元学习共享层次结构[14]和选项批评[4]
5对于我们的环境。在评估期间,我们并行使用10个进程来运行500集并计算代理在规定时限内解决任务的次数百分比。该指标是被称为“成功率”。
6.除非另有说明,否则所有任务的默认时间限制为500步。
7.使用正交初始化初始化所有前馈网络输入张量用(半)正交矩阵填充。
8.对于所有嵌入层,使用单位 - 高斯分布初始化权重。
9.使用均匀分布初始化所有GRU模型的权重和偏差

In section D.4.2, we explain all the components of the model architecture along with the implementation details in the context of the MiniGrid Environment. For the subsequent environments, we
describe only those components and implementation details which are different than their counterpart
in the MiniGrid setup and do not describe the components which work identically.
在D.4.2节中,我们将解释模型体系结构的所有组件以及MiniGrid环境上下文中的实现细节。 对于后续环境,我们
仅描述与其对应物不同的那些组件和实现细节
在MiniGrid设置中,并没有描述相同的组件。
D MiniGrid Environment
We use the MiniGrid environment [6] which is an open-source, grid-world environment package 6
.
It provides a family of customizable reinforcement learning environments that are compatible with
the OpenAI Gym framework [5]. Since the environments can be easily extended and modified, it is
straightforward to control the complexity of the task (eg controlling the size of the grid, the number
of rooms or the number of objects in the grid, etc). Such flexibility is very useful when experimenting
with curriculum learning or testing for generalization.
我们使用MiniGrid环境[6],它是一个开源的网格世界环境包6。它提供了一系列可定制的强化学习环境,与之兼容
OpenAI Gym框架[5]。 由于可以轻松扩展和修改环境,因此可以直接控制任务的复杂性(例如控制网格的大小,数量房间或网格中的对象数量等)。 这种灵活性在实验时非常有用课程学习或综合测试。
D.1 The World
In MiniGrid, the world (environment for the learning agent) is a rectangular grid of size say MxN.
Each tile in the grid contains either zero or one object. The possible object types are wall, floor, lava,
door, key, ball, box and goal. Each object has an associated string (which denote the object type) and
an associated discrete color (could be red, green, blue, purple, yellow and grey). By default, walls are
always grey and goal squares are always green. Certain objects have special effects. For example, a
key can unlock a door of the same color.
在MiniGrid中,世界(学习代理的环境)是一个大小为MxN的矩形网格。网格中的每个图块包含零个或一个对象。 可能的对象类型是墙,地板,熔岩,门,钥匙,球,框和目标。 每个对象都有一个关联的字符串(表示对象类型)和相关的离散颜色(可以是红色,绿色,蓝色,紫色,黄色和灰色)。 默认情况下,墙是总是灰色,目标方块总是绿色的。 某些物体具有特殊效果。 例如,a钥匙可以解锁相同颜色的门。
D.1.1 Reward Function
We consider the sparse reward setup where the agent gets a reward (of 1) only if it completes the task
and 0 at all other time steps. We also apply a time limit of 500 steps on all the tasks ie the agent must
complete the task in 500 steps. A task is terminated either when the agent solves the task or when the
time limit is reached - whichever happens first.
我们考虑稀疏奖励设置,其中代理仅在完成任务时才获得奖励(1)在所有其他时间步骤为0。 我们还对所有任务应用500步的时间限制,即代理必须以500步完成任务。 当代理解决任务或何时解决任务时,任务终止达到时间限制 - 以先发生者为准。
D.1.2 Action Space
The agent can perform one of the following seven actions per timestep: turn left, turn right, move
forward, pick up an object, drop the object being carried, toggle, done (optional action).
The agent can use the turn left and turn right actions to rotate around and face one of the 4 possible
directions (north, south, east, west). The move forward action makes the agent move from its current
tile onto the tile in the direction it is currently facing, provided there is nothing on that tile, or that the
tile contains an open door. The toggle actions enable the agent to interact with other objects in the
world. For example, the agent can use the toggle action to open the door if they are right in front of it
and have the key of matching color.
代理可以每个时间步执行以下七个操作之一:向左转,向右转,移动向前,拾取一个物体,放下被携带的物体,切换,完成(可选动作)。代理人可以使用左转和右转动作来围绕并面对4种可能的中的一种方向(北,南,东,西)。 前进行动使代理人从当前移动如果该瓷砖上没有任何东西,或者该瓷砖上有任何东西,则按照它当前所面向的方向拼贴到瓷砖上瓷砖包含一扇敞开的门。 切换操作使代理能够与其中的其他对象进行交互世界。 例如,代理可以使用切换操作来打开门,如果它们就在它前面并拥有匹配颜色的关键。
D.1.3 Observation Space
The MiniGrid environment provides partial and egocentric observations. For all our experiments, the
agent sees the view of a square of 4x4 tiles in the direction it is facing. The view includes the tile on
which the agent is standing. The observations are provided as a tensor of shape 4x4x3. However,
note that this tensor does not represent RGB images. The first two channels denote the view size and
the third channel encodes three integer values. The first integer value describes the type of the object,
the second value describes the color of the object and the third value describes if the doors are open
or closed. The benefit of using this encoding over the RGB encoding is that this encoding is more
space-efficient and enables faster training. For human viewing, the fully observable, RGB image
view of the environments is also provided and we use that view as an example in the paper.
Additionally, the environment also provides a natural language description of the goal. An example
of the goal description is: “Unlock the door and pick up the red ball”. The learning agent and the
environment use a shared vocabulary where different words are assigned numbers and the environment
provides a number-encoded goal description along with each observation. Since different instructions
can be of different lengths, the environment pads the goal description with tokens to ensure
that the sequence length is the same. When encoding the instruction, the agent ignores the padded
sub-sequence in the instruction.
MiniGrid环境提供部分和自我中心观察。对于我们所有的实验,代理在其面向的方向上看到正方形的4x4瓦片的视图。视图包含瓷砖代理商所站立的。观察结果以4x4x3的形状提供。然而,请注意,此张量不代表RGB图像。前两个通道表示视图大小和第三个通道编码三个整数值。第一个整数值描述对象的类型,第二个值描述对象的颜色,第三个值描述门是否打开或关闭。使用此编码而不是RGB编码的好处是这种编码更多节省空间,加快培训速度。对于人类观看,完全可观察的RGB图像还提供了环境视图,我们使用该视图作为本文的示例。此外,环境还提供了目标的自然语言描述。一个例子目标描述是:“解锁门并拿起红球”。学习代理人和环境使用共享词汇表,其中不同的单词被分配数字和环境提供数字编码的目标描述以及每个观察。由于不同的指示可以是不同长度的,环境焊盘与令牌来确保的目标描述序列长度是一样的。编码指令时,代理会忽略填充指令中的子序列。

D.2 Tasks in MiniGrid Environment
We consider the following tasks in the MiniGrid environment:
- Fetch: In the Fetch task, the agent spawns at an arbitrary position in a 8 × 8 grid (figure 9 ).
It is provided with a natural language goal description of the form “go fetch a yellow box”.
The agent has to navigate to the object being referred to in the goal description and pick it
up.
2.Unlock: In the Unlock task, the agent spawns at an arbitrary position in a two-room grid
environment. Each room is 8 × 8 square (figure 10 ). It is provided with a natural language
我们在MiniGrid环境中考虑以下任务:
- 获取:在获取任务中,代理在8×8网格中的任意位置产生(图9)。
它提供了“go fetch a yellow box”形式的自然语言目标描述。代理必须导航到目标描述中引用的对象并选择它
起来。
2。解锁:在解锁任务中,代理会在两室网格中的任意位置生成环境。 每个房间都是8×8平方(图10)。 它提供自然语言

goal description of the form “open the door”. The agent has to find the key that corresponds
to the color of the door, navigate to that key and use that key to open the door.
3. UnlockPickup: This task is basically a union of the Unlock and the Fetch tasks. The agent
spawns at an arbitrary position in a two-room grid environment. Each room is 8 × 8 square
(figure 11 ). It is provided with a natural language goal description of the form “open the
door and pick up the yellow box”. The agent has to find the key that corresponds to the color
of the door, navigate to that key, use that key to open the door, enter the other room and pick
up the object mentioned in the goal description.
目标描述形式“打开门”。 代理必须找到对应的密钥根据门的颜色,导航到该键并使用该键打开门。
3. ** UnlockPickup **:此任务基本上是Unlock和Fetch任务的联合。 代理在两室网格环境中的任意位置产生。 每间客房均为8×8平方米(图11)。 它提供了一个自然的语言目标描述形式“打开门,拿起黄色的盒子“。 代理必须找到与颜色对应的键门,导航到那把钥匙,用那把钥匙打开门,进入另一个房间然后挑选目标描述中提到的对象。
D.3 Model Architecture
D.3.1 Training Setup
Consider an agent training on any task in the MiniGrid suite of environments. At the beginning
of an episode, the learning agent spawns at a random position. At each step, the environment
provides observations in two modalities - a 4 × 4 × 3 tensor xt (an egocentric view of the state of the
environment) and a variable length goal description g. We describe the design of the learning agent
in terms of an encoder-decoder architecture.
考虑对MiniGrid环境套件中的任何任务进行代理培训。 一开始在一集中,学习代理在随机位置产生。 在每一步,环境以两种方式提供观察 - 一个4×4×3张量xt(一个以自我为中心的状态观察环境)和可变长度目标描述g。 我们描述了学习代理的设计就编码器 - 解码器架构而言。
D.3.2 Encoder Architecture
The agent’s encoder network consists of two models - a CNN+GRU based observation encoder and
a GRU [7] based goal encoder
Observation Encoder:
It is a three layer CNN with the output channel sizes set to 16, 16 and 32 respectively (with ReLU
layers in between) and kernel size set to 2 × 2 for all the layers. The output of the CNN is flattened
and fed to a GRU model (referred to as the observation-rnn) with 128-dimensional hidden state. The
output from the observation-rnn represents the encoding of the observation.
Goal Encoder:
It comprises of an embedding layer followed by a unidirectional GRU model. The dimension of the
embedding layer and the hidden and the output layer of the GRU model are all set to 128.
The concatenated output of the observation encoder and the goal encoder represents the output of
the encoder.
D.3.3 Decoder
The decoder network comprises the action network and the critic network - both of which are
implemented as feedforward networks. We now describe the design of these networks.
D.3.4 Value Network
- Two-layer feedforward network with the tanh non-linearity.
- Input: Concatenation of z and the current hidden state of the observation-rnn.
- Size of the input to the first layer and the second layer of the policy network are 320 and 64
respectively. - Produces a scalar output.
D.4 Components specific to the proposed model
The components that we described so far are used by both the baselines as well as our proposed
model. We now describe the components that are specific to our proposed model. Our proposed
model consists of an ensemble of primitives and the components we describe apply to each of those
primitives.
D.4.1 Information Bottleneck
Given that we want to control and regularize the amount of information that the encoder encodes, we
compute the KL divergence between the output of the action-feature encoder network and a diagonal
unit Gaussian distribution. More is the KL divergence, more is the information that is being encoded
with respect to the Gaussian prior and vice-versa. Thus we regularize the primitives to minimize the
KL divergence.
D.4.2 Hyperparameters
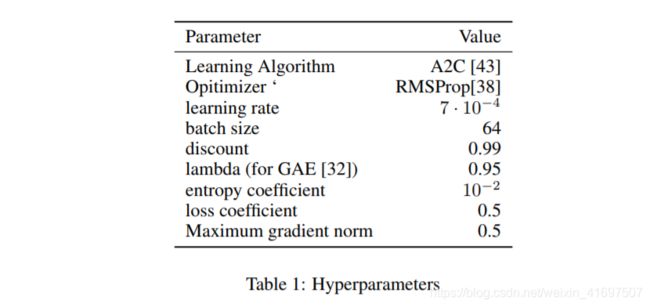
Table 1 lists the different hyperparameters for the MiniGrid tasks.
E 2D Bandits Environment
E.0.1 Observation Space
The 2D bandits task provides a 6-dimensional flat observation. The first two dimensions correspond
to the (x, y) coordinates of the current position of the agent and the remaining four dimensions
correspond to the (x, y) coordinates of the two randomly chosen points.
E.1 Model Architecture
E.1.1 Training Setup
Consider an agent training on the 2D bandits tasks. The learning agent spawns at a fixed position and
is randomly assigned two points. At each step, the environmental observation provides the current
position of the agent as well the position of the two points. We describe the design of the learning
agent in terms of an encoder-decoder architecture.
E.1.2 Encoder Architecture
The agent’s encoder network consists of a GRU-based recurrent model (referred as the observationrnn) with a hidden state size of 128. The 6-dimensional observation from the environment is the input
to the GRU model. The output from the observation-rnn represents the encoding of the observation.
E.2 Hyperparameters
The implementation details for the 2D Bandits environment are the same as that for MiniGrid
environment and are described in detail in section D.4.2. In the table below, we list the values of the
task-specific hyperparameters.

F Four-rooms Environment
F.1 The World
In the Four-rooms setup, the world (environment for the learning agent) is a square grid of say 11×11.
The grid is divided into 4 rooms such that each room is connected with two other rooms via hallways.
The layout of the rooms is shown in figure 12. The agent spawns at a random position and has to
navigate to a goal position within 500 steps.

F.1.1 Reward Function
We consider the sparse reward setup where the agent gets a reward (of 1) only if it completes the task
(and reaches the goal position) and 0 at all other time steps. We also apply a time limit of 300 steps
on all the tasks ie the agent must complete the task in 300 steps. A task is terminate either when the
agent solves the task or when the time limit is reached - whichever happens first.
F.1.2 Observation Space
The environment is a 11 × 11 grid divided into 4 interconnected rooms. As such, the environment has
a total of 104 states (or cells) that can be occupied. These states are mapped to integer identifiers. At
any time t, the environment observation is a one-hot representation of the identifier corresponding to
the state (or the cell) the agent is in right now. ie the environment returns a vectors of zeros with only
one entry being 1 and the index of this entry gives the current position of the agent. The environment
does not return any information about the goal state.
F.2 Model Architecture for Four-room Environment
F.2.1 Training Setup
Consider an agent training on any task in the Four-room suite of environments. At the beginning
of an episode, the learning agent spawns at a random position and the environment selects a goal
position for the agent. At each step, the environment provides a one-hot representation of the agent’s
current position (without including any information about the goal state). We describe the design of
the learning agent in terms of an encoder-decoder architecture.
F.3 Encoder Architecture
The agent’s encoder network consists of a GRU-based recurrent model (referred as the observationrnn with a hidden state size of 128. The 104-dimensional one-hot input from the environment is fed
to the GRU model. The output from the observation-rnn represents the encoding of the observation.
The implementation details for the Four-rooms environment are the same as that for MiniGrid
environment and are described in detail in section D.4.2.
G Ant Maze Environment
We use the Mujoco-based quadruple ant [40] to evaluate the transfer performance of our approach
on the cross maze environment [15]. The training happens in two phases. In the first phase, we
train the ant to walk on a surface using a motion reward and using just 1 primitive. In the second
phase, we make 4 copies of this trained policy and train the agent to navigate to a goal position in a
maze (Figure 13). The goal position is chosen from a set of 3 (or 10) goals. The environment is a
continuous control environment and the agent can directly manipulate the movement of joints and
limbs.

G.0.1 Observation Space
In the first phase (training the ant to walk), the observations from the environment correspond to the
state-space representation ie a real-valued vector that describes the state of the ant in mechanical
terms - position, velocity, acceleration, angle, etc of the joints and limbs. In the second phase (training
the ant to navigate the maze), the observation from the environment also contains the location of the
goal position along with the mechanical state of the ant.
G.1 Model Architecture for Ant Maze Environment
G.1.1 Training Setup
We describe the design of the learning agent in terms of an encoder-decoder architecture.
G.1.2 Encoder Architecture
The agent’s encoder network consists of a GRU-based recurrent model (referred as the observationrnn with a hidden state size of 128. The real-valued state vector from the environment is fed to the
GRU model. The output from the observation-rnn represents the encoding of the observation. Note that in the case of phase 1 vs phase 2, only the size of the input to the observation-rnn changes and
the encoder architecture remains the same.
G.1.3 Decoder
The decoder network comprises the action network and the critic network. All these networks are
implemented as feedforward networks. The design of these networks is very similar to that of the
decoder model for the MiniGrid environment as described in section D.3.3 with just one difference.
In this case, the action space is continuous so the action-feature decoder network produces the mean
and log-standard-deviation for a diagonal Gaussian policy. This is used to sample a real-valued action
to execute in the environment.