爬虫项目实战(二)

(一)爬虫实战之Xpath数据解析
1)、XPath介绍
XPath,全称XML Path Language,即XML路径语言,它是一门在XML文档中查找信息的语言。最初是用来搜寻XML文档的,但同样适用于HTML文档的搜索。所以在做爬虫时完全可以使用XPath做相应的信息抽取。
2)、XPath的常用规则:
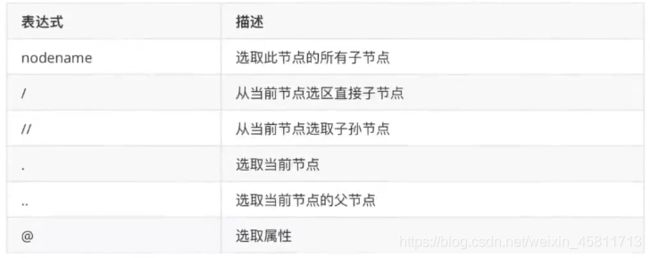
这里列出了XPath的常用匹配规则,示例如下: .//title[@lang='eng‘],这是一个XPath规则,代表的是选择所有名称为title,同时属性lang的值为eng的节点,后面会通过Python的lxml库,利用XPath进行HTML的解析。
3)、安装
windows-> python3环境下: pip install lxml
linux环境下: pip3 install lxml

4)、实例
注意:Chrome中的源代码无法直接复制,
小插曲:如何复制Chrome浏览器中的源代码
现在很多网页直接查看源代码是看不到完整的源代码的,有些网页往下翻会不停的加载新内容,就算最终全部加载完了,源代码中也不会显示网页的全部内容。只有按F12或ctrl+shift+i才能看到所有元素的源代码。
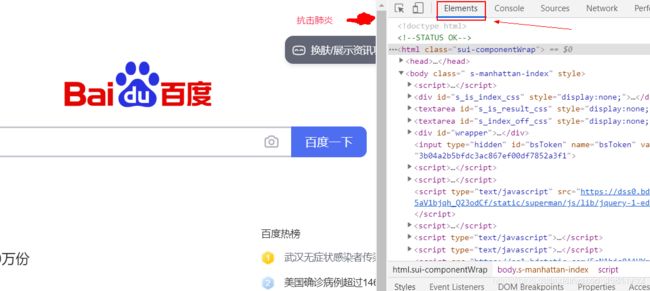
从上图可以看出来,这些元素的源代码默认是无法选中进行一次性复制的,只能一个一个元素复制。下面就分享一下复制整个页面的源代码的方法。
a、如下图,找到顶部的html标签,然后点击鼠标右键后选择Edit as HTML
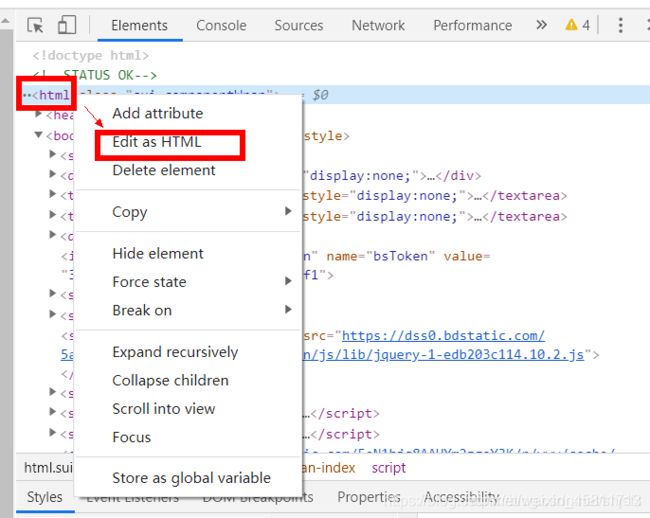 b、现在按ctrl+a全部选中就可以复制到剪贴板了。
b、现在按ctrl+a全部选中就可以复制到剪贴板了。
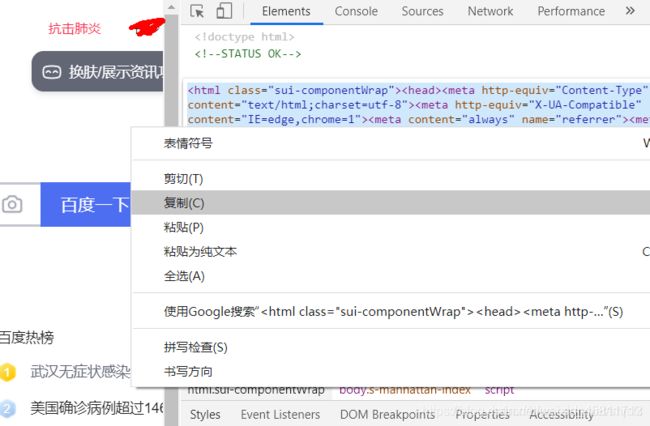
c、如果觉得格式有些乱,可通过网上的在线html工具进行在线格式化
https://tool.oschina.net/codeformat/html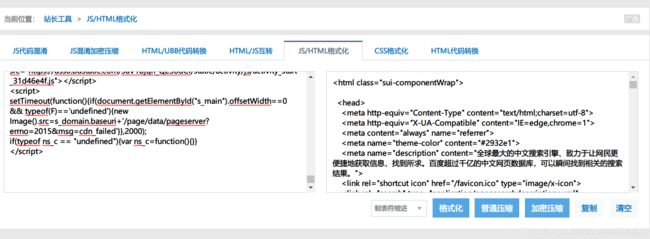
问题解决!!!
第一种方式:
from lxml import etree
text = '''
学习猿地 - IT培训|Java培训|Python培训|ui设计培训|web前端培训|GO培训|PHP培训|成就自己的只需一套精品
'''
#使用etree解析html字符串
html = etree.HTML(text)
#print(html)
#提取数据
# r = html.xpath("/html/body/ul/li/a/text()")
# 执行结果:['java工程师', 'Python工程师', 'AI工程师']
# print(r)
# r = html.xpath("/html/body/ul/li[1]/a/text()")
# print(r)
# ['java工程师']注意:下标从1开始,不是从0开始
第二种方式:
from lxml import etree
# 第二种方式,读取一个html文件并解析
html = etree.parse('./text.html', etree.HTMLParser())
# print(html)
# 提取数据
# r = html.xpath("/html/body/ul/li/a/text()")
# print(r)
#执行结果 ['java工程师', 'Python工程师', 'AI工程师']
#范围更广,获取页面中所有li里面的数据
# r = html.xpath("//li/a/text()")
# print(r)
#执行结果 ['java工程师', 'Python工程师', 'AI工程师', '猿叔', '猿婶', '猿姐']
#提取指定标签中的数据
h = html.xpath('//div[@class="teacher"]/ul/li/a/text()')
print(h)
#执行结果['猿叔', '猿婶', '猿姐']
#获取指定标签的属性
r = html.xpath('//div[@class="teacher"]//li/a/@href')
print(r)
#执行结果['/1/', '/2/', '/3/']
res = list(zip(h,r))
print(res)
#执行结果[('猿叔', '/1/'), ('猿婶', '/2/'), ('猿姐', '/3/')]
import requests
from lxml import etree
#封装类,进行学习猿地的登录和订单的获取
class LMonkey():
#登陆请求地址
loginurl = 'https://www.lmonkey.com/login'
# 帐户中心地址
orderurl = 'https://www.lmonkey.com/my/order'
# 请求头header
headers = {
'User - agent': 'Mozilla / 5.0(Linux; Android 6.0;Nexus5Build / MRA58N) AppleWebKit / 537.36(KHTML, like Gecko) Chrome / 83.0.4103.116Mobile Safari / 537.36'
}
# 请求对象
req = None
#token口令
token = ''
#订单号
ordercode = 0
# 初始化方法
def __init__(self):
#请求对象的初始化
self.req = requests.session()
if self.getlogin():
if self.postlogin():
self.getorder()
# get登陆页面,获取_token
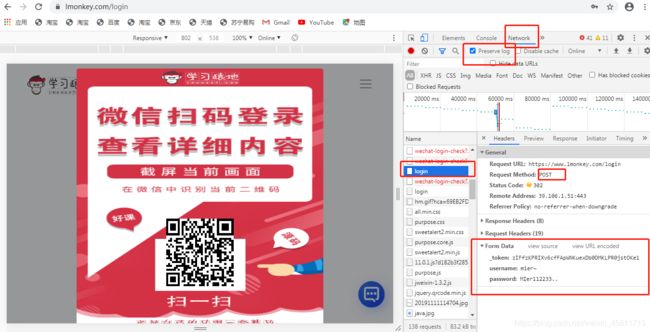
def getlogin(self):
# 1、get请求login页面,设置cookie获取_token
res = self.req.get(url=self.loginurl,headers=self.headers)
if res.status_code == 200:
print('get登录页面请求成功')
html = etree.HTML(res.text)
self.token = html.xpath('//input[@name="_token"]/@value')[0]
print('token获取成功')
return True
else:
print('请求错误')
#post请求登录,设置cookie
def postlogin(self):
uname = input('手机号:')
passw = input('密码:')
data = {
'_token':self.token,
'username':uname,
'password':passw
}
#发起post请求
res = self.req.post(url=self.loginurl,headers=self.headers,data=self.data)
if res.status_code == 200 or res.status_code == 302:
print('登陆成功')
#请求订单数据
#get请求帐户中心,获取默认订单号
def getorder(self):
# 3、get请求帐户中心,获取默认订单号
res = self.req.get(url=self.orderurl,headers=self.headers,)
if res.status_code == 200:
print("帐户中心请求成功,正在解析数据")
html = etree.HTML(res.text)
r = html.xpath('//div[@class="avatar-content"]//small/text()')
print(r)
self.ordercode = r
obj = LMonkey()
# obj.getlogin()
# obj.postlogin()
#1、get请求login页面,设置cookie获取_token
#2、post请求,提交登陆数据,进行登陆,并设置cookie
#3、get请求帐户中心,获取默认订单号
import requests,json
from lxml import etree
class Yq():
#请求的地址 猿著
url = 'https://www.lmonkey.com/essence'
#定义请求头信息
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.97 Safari/537.36'
}
#爬取的数据
data = ''
#存储数据
filepath = './yq.json'
#初始化
def __init__(self):
#发送请求
res = requests.get(url=self.url,headers=self.headers)
if res.status_code == 200:
#请求的内容写入文件
with open('./yq.html','w',encoding='utf-8') as fp:
fp.write(res.text)
if self.pasedata():
self.writedata()
#解析数据
def pasedata(self):
#解析数据
html = etree.parse('./yq.html',etree.HTMLParser())
#提取数据 作者 文章标题 文章地址url
author = html.xpath('//div[contains(@class,"old_content")]//div[contains(@class,"list-group-item-action")]//strong/a/text()')
titles = html.xpath('//div[contains(@class,"old_content")]//div[contains(@class,"flex-fill")]//div/text()')
titleurl = html.xpath('//div[contains(@class,"old_content")]//div[contains(@class,"flex-fill")]//a/@href')
#print(*zip(author,titles,titleurl))
#运行结果('xxyd_h5x', 'JetBrains开发工具正版授权领取', 'https://www.lmonkey.com/t/lpLmQeKLg') ('IT头条', '面向回家编程!GitHub标星两万的”Python抢票教程”,我们先帮你跑了一遍', 'https://www.lmonkey.com/t/lpLmQeKLg') ('duke', 'Python教程-一文读懂运算和运算符', 'https://www.lmonkey.com/t/lpLmQeKLg') ('dragonsz', 'CentOS7 下使用 rsync+sersync 配置文件自动同步', 'https://www.lmonkey.com/t/user/15') ('qingqi', 'Python 教程-代码测试', 'https://www.lmonkey.com/t/2zLAPzMyW') ('jhxspy', 'Python教程-强制数据类型转换', 'https://www.lmonkey.com/t/2zLAPzMyW') ('xxyd_python', 'Python 教程-从变量开始', 'https://www.lmonkey.com/t/2zLAPzMyW') ('IT头条', 'Python 教程-Python 安装', 'https://www.lmonkey.com/t/2zLAPzMyW') ('IT头条', 'Python 教程-了解Python', 'https://www.lmonkey.com/t/2zLAPzMyW') ('GaiJoon', '喊话 JavaScript 开发者:玩 DOM 也要专业范儿', 'https://www.lmonkey.com/t/2zLAPzMyW') ('IT头条', '1000 行 Python 代码脚本 bug,或影响上百篇学术论文', 'https://www.lmonkey.com/t/2zLAPzMyW') ('IT头条', '生产环境下的LAMP环境搭建', 'https://www.lmonkey.com/t/user/168547') ('王炸', 'Golang语言的主要特性与发展的环境和影响因素', 'https://www.lmonkey.com/t/G5yvRWXyp') ('王炸', '分享 10 个有用的 Laravel 5.8 集合辅助方法', 'https://www.lmonkey.com/t/G5yvRWXyp')
# 整理数据
data = []
for i in range(0,len(author)):
res = {'author':author[i],'title':titles[i],'url':titleurl[i]}
data.append(res)
# print(data)
#运行结果[{'author': 'xxyd_h5x', 'title': 'JetBrains开发工具正版授权领取', 'url': 'https://www.lmonkey.com/t/lpLmQeKLg'}, {'author': 'IT头条', 'title': '面向回家编程!GitHub标星两万的”Python抢票教程”,我们先帮你跑了一遍', 'url': 'https://www.lmonkey.com/t/lpLmQeKLg'}, {'author': 'duke', 'title': 'Python教程-一文读懂运算和运算符', 'url': 'https://www.lmonkey.com/t/lpLmQeKLg'}, {'author': 'dragonsz', 'title': 'CentOS7 下使用 rsync+sersync 配置文件自动同步', 'url': 'https://www.lmonkey.com/t/user/15'}, {'author': 'qingqi', 'title': 'Python 教程-代码测试', 'url': 'https://www.lmonkey.com/t/2zLAPzMyW'}, {'author': 'jhxspy', 'title': 'Python教程-强制数据类型转换', 'url': 'https://www.lmonkey.com/t/2zLAPzMyW'}, {'author': 'xxyd_python', 'title': 'Python 教程-从变量开始', 'url': 'https://www.lmonkey.com/t/2zLAPzMyW'}, {'author': 'IT头条', 'title': 'Python 教程-Python 安装', 'url': 'https://www.lmonkey.com/t/2zLAPzMyW'}, {'author': 'IT头条', 'title': 'Python 教程-了解Python', 'url': 'https://www.lmonkey.com/t/2zLAPzMyW'}, {'author': 'GaiJoon', 'title': '喊话 JavaScript 开发者:玩 DOM 也要专业范儿', 'url': 'https://www.lmonkey.com/t/2zLAPzMyW'}, {'author': 'IT头条', 'title': '1000 行 Python 代码脚本 bug,或影响上百篇学术论文', 'url': 'https://www.lmonkey.com/t/2zLAPzMyW'}, {'author': 'IT头条', 'title': '生产环境下的LAMP环境搭建', 'url': 'https://www.lmonkey.com/t/user/168547'}, {'author': '王炸', 'title': 'Golang语言的主要特性与发展的环境和影响因素', 'url': 'https://www.lmonkey.com/t/G5yvRWXyp'}, {'author': '王炸', 'title': '分享 10 个有用的 Laravel 5.8 集合辅助方法', 'url': 'https://www.lmonkey.com/t/G5yvRWXyp'}]
self.data = data
return True
#写入数据
def writedata(self):
#写入数据
with open('self.filepath','w')as fp:
json.dump(self.data,fp)
#实例化对象
Yq()
(二)爬虫实战BeautifulSoup数据解析
1)、bs4的安装与三种使用方式
BeautifulSoup是一个可以从HTML或XML文件中提取数据的python库,它能够通过你喜欢的转换器实现惯用的文档,导航、查找、修改文档的方式,BeautifulSoup可节省大量的时间。
官方文档:https://www.crummy.com/software/BeautifulSoup/bs4/doc
a、安装
命令:pip install BeautifulSoup4
插曲一:解决bug—You should consider upgrading via the ‘python -m pip install --upgrade pip’ command.

删除下列文件夹D:\softwaredownload\anaconda\Lib\site-packages\pip-20.0.2.dist-info
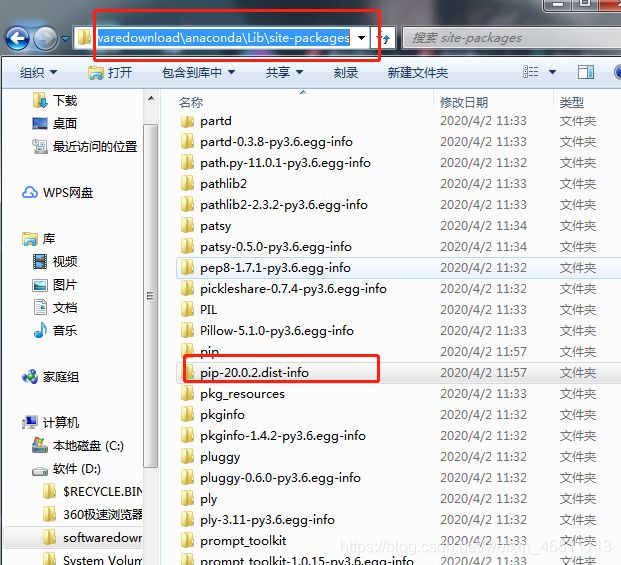
再次运行python -m pip install --upgrade pip 后升级成功,之前不能安装的包也能安装了!

问题解决
 b、三种使用方式
b、三种使用方式
(1)使用Tag对象按照文档结构获取数据

#安装后需要在bs4中导入使用
from bs4 import BeautifulSoup
#定义html文档内容
html_doc = """
The Dormouse's story
The Dormouse's story
Once upon a time there were three little sisters; and their names were
Elsie,
Lacie and
Tillie;
and they lived at the bottom of a well.
...
"""
#创建一个BeautifulSoup对象,建议手动指定解析器:soup = BeautifulSoup(html_doc,'lxml)
soup = BeautifulSoup(html_doc,'lxml')
#通过tag标签对象获取文档数据
r = soup.title
r = soup.title['abc']
# r = soup.p
# r = soup.p['class']
# r = soup.title.text
print(r)
(2)使用find和find_all方法进行查找

(3)、使用CSS选择器
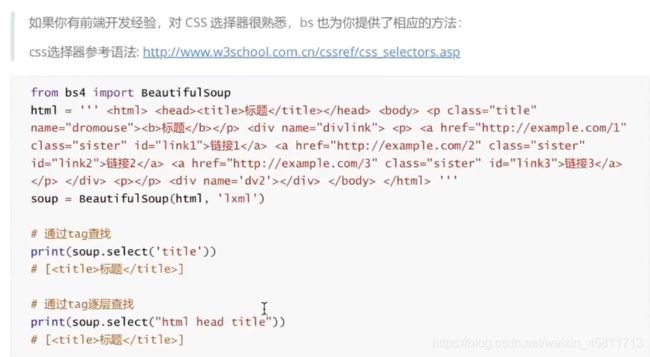


#安装后需要在bs4中导入使用
from bs4 import BeautifulSoup
#定义html文档内容
html_doc = """
The Dormouse's story
The Dormouse's story
Once upon a time there were three little sisters; and their names were
Elsie,
Lacie and
Tillie;
and they lived at the bottom of a well.
...
"""
#1、创建一个BeautifulSoup对象,建议手动指定解析器:soup = BeautifulSoup(html_doc,'lxml)
soup = BeautifulSoup(html_doc,'lxml')
#通过tag标签对象获取文档数据
# r = soup.title
# r = soup.title['abc']
# r = soup.p
# r = soup.p['class']
# r = soup.title.text
# print(r)
#2、通过搜索获取页面中的元素 find,find_all
# r = soup.find('a')
#运行结果Elsie
# r = soup.find_all('a')
#运行结果[Elsie, Lacie, Tillie]
# r = soup.find('title')
# print(r.text)
# print(r.get_text())
# print(r.get_text)
# print(r)
'''运行结果The Dormouse's story
The Dormouse's story
The Dormouse's story>
The Dormouse's story '''
# 3、.css选择器
#通过标签选择元素
# r = soup.select('title')
#通过class类名获取元素
# r = soup.select('.title')
#通过ID名获取元素
# r = soup.select('#link2')
#通过空格,层级关系获取元素
# r = soup.select('html body p')
#通过逗号,并列关系获取元素
r = soup.select('p,.title')
print(r)
2)bs4-学习猿地-猿圈
'''
分析爬取的数据
数据源地址:https://www.lmonkey.com/t
数据内容:文章标题、文章的链接、作者、发布时间
工具:
python,requests,bs4
'''
import requests,json
from bs4 import BeautifulSoup
#1.定义请求的URL和请求头
url = 'https://www.lmonkey.com/t'
#定义请求头信息
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.97 Safari/537.36'
}
#2.发送请求
res = requests.get(url,headers=headers)
#3.判断请求是否成功,并获取请求的源代码
if res.status_code == 200:
pass
#4.解析数据
soup = BeautifulSoup(res.text,'lxml')
#获取页面中所有的文章
divs = soup.find_all('div',class_="list-group-item list-group-item-action p-06")
varlist= []
for i in divs:
r = i.find('div',class_="topic_title mb-0 lh-180")
if r:
# print(i.a['href'])
# print(i.strong.a.text)
# print(i.span['title'])
vardict = {
'title':r.text.split('\n')[0],
'url':i.a['href'],
'author':i.strong.a.text,
'time':i.span['title']
}#将文本切分,只要第一个内容
varlist.append(vardict)
print(varlist)
#运行结果'''[{'title': '图层操作'}, {'title': 'ps_行业介绍笔记'}, {'title': 'DIV+CSS页面布局笔记'}, {'title': '认识网站笔记'}, {'title': 'ps_行业介绍笔记'}, {'title': 'DIV+CSS页面布局笔记'}, {'title': '认识网站笔记'}, {'title': 'requests笔记'}, {'title': 'Java的各种数据类型对象库的处理应用笔记'}, {'title': 'Java语言的基本语法格式笔记'}, {'title': 'Java程序开发入门笔记'}, {'title': 'Java程序开发入门笔记'}, {'title': 'Java编译过程'}, {'title': '常用快捷键'}, {'title': 'Java程序开发入门笔记'}]'''
#5.写入数据
with open ('./yq.json','w') as fp:
json.dump(varlist,fp)
#运行结果
[{'title': '图层操作', 'url': 'https://www.lmonkey.com/t/oREQ9lXE1', 'author': '?_xQfer4', 'time': '2020-06-17 17:50:37'}, {'title': 'ps_行业介绍笔记', 'url': 'https://www.lmonkey.com/t/1NLXY8jBV', 'author': '?_xQfer4', 'time': '2020-06-17 17:33:43'}, {'title': 'DIV+CSS页面布局笔记', 'url': 'https://www.lmonkey.com/t/GRLbK8zBz', 'author': '~~~七~~~', 'time': '2020-06-13 17:54:32'}, {'title': '认识网站笔记', 'url': 'https://www.lmonkey.com/t/oZBde7OEp', 'author': 'coding_dog', 'time': '2020-06-09 19:43:36'}, {'title': 'ps_行业介绍笔记', 'url': 'https://www.lmonkey.com/t/qpBarN3EJ', 'author': '?_xQfer4', 'time': '2020-06-07 22:15:14'}, {'title': 'DIV+CSS页面布局笔记', 'url': 'https://www.lmonkey.com/t/dvy91vbyK', 'author': '樱桃大嘴猴.', 'time': '2020-06-04 11:30:36'}, {'title': '认识网站笔记', 'url': 'https://www.lmonkey.com/t/kNB0opeLe', 'author': '徐枭雄老师-英子', 'time': '2020-05-31 21:30:56'}, {'title': 'requests笔记', 'url': 'https://www.lmonkey.com/t/WMLDKw5yY', 'author': '温水泡青蛙', 'time': '2020-05-31 16:00:54'}, {'title': 'Java的各种数据类型对象库的处理应用笔记', 'url': 'https://www.lmonkey.com/t/QOLMxNmyd', 'author': '明明就晴天', 'time': '2020-05-29 13:23:38'}, {'title': 'Java语言的基本语法格式笔记', 'url': 'https://www.lmonkey.com/t/wDEx3zZBK', 'author': '明明就晴天', 'time': '2020-05-28 23:20:57'}, {'title': 'Java程序开发入门笔记', 'url': 'https://www.lmonkey.com/t/XkyJ48eBe', 'author': '明明就晴天', 'time': '2020-05-28 22:16:28'}, {'title': 'Java程序开发入门笔记', 'url': 'https://www.lmonkey.com/t/OxLP07qLe', 'author': '明明就晴天', 'time': '2020-05-28 22:12:38'}, {'title': 'Java编译过程', 'url': 'https://www.lmonkey.com/t/2QL7pvmBk', 'author': 'ℳℓ牛', 'time': '2020-05-18 13:07:53'}, {'title': '常用快捷键', 'url': 'https://www.lmonkey.com/t/7VEZYdoB3', 'author': 'ℳℓ牛', 'time': '2020-05-18 13:01:41'}, {'title': 'Java程序开发入门笔记', 'url': 'https://www.lmonkey.com/t/VDLeZlNBX', 'author': 'ℳℓ牛', 'time': '2020-05-18 12:57:07'}]
3)bs4-实战猿圈-代码优化
'''
分析爬取的数据
数据源地址:https://www.lmonkey.com/t
数据内容:文章标题、文章的链接、作者、发布时间
工具:
python,requests,bs4
'''
import requests,json
from bs4 import BeautifulSoup
#封装类
class Bs4Yq():
#定义属性
#请求得url
url = 'https://www.lmonkey.com/t'
#请求头
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.97 Safari/537.36'
}
#响应源代码的存放位置
res = None
#存储解析后的json数据
varlist = []
#初始化方法
def __init__(self):
#发起一个请求
res = requests.get(self.url,headers=self.headers)
if res.status_code == 200:
self.res_html = res.text
if self.ParseData():
self.WriteJson()
print('请求成功,数据写入文件')
else:
print("请求失败")
#解析html数据
def ParseData(self):
soup = BeautifulSoup(self.res_html, 'lxml')
try:
# 获取页面中所有的文章
divs = soup.find_all('div', class_="list-group-item list-group-item-action p-06")
for i in divs:
r = i.find('div', class_="topic_title mb-0 lh-180")
if r:
# print(i.a['href'])
# print(i.strong.a.text)
# print(i.span['title'])
vardict = {
'title': r.text.split('\n')[0],
'url': i.a['href'],
'author': i.strong.a.text,
'time': i.span['title']
} # 将文本切分,只要第一个内容
self.varlist.append(vardict)
# print(varlist)
return True
except:
return False
#写入json文件
def WriteJson(self):
if self.varlist != []:
try:
with open('./yq.json','w') as fp:
json.dump(self.varlist,fp)
return True
except:
return False
else:
print('无法获取当前解析的数据')
Bs4Yq()
(三)爬虫实战之re正则表达式数据解析
1)re正则模块的介绍
#正则表达式 re
'''
正则表达式,就是使用字符,转义字符和特殊字符组成的一个规则.
使用这个规则对文本的内容完成一个搜索或匹配或替换的功能
正则表达式的组成:
普通字符:大小写字母,数字,符号...
转义字符:\w \W \d \D \s \S ...
特殊字符:.* ? + ^ $ [] {} ()
匹配模式:I U ....
'''
#使用正则表达式进行匹配的基本语法
import re
#定义字符串
vars = 'iloveyou521tosimda'
#定义正则表达式
reg = '\d'
#调用正则函数方法
res = re.findall(reg,vars)
print(res)
#运行结果:['5', '2', '1']
'''
方式二:
#定义字符串
vars = 'iloveyou521tosimda'
#定义正则表达式
reg = '521'
#调用正则函数方法
res = re.finditer(reg,vars)
print(next(res))
#运行结果:<_sre.SRE_Match object; span=(8, 11), match='521'>
方式三:
#定义字符串
vars = 'iloveyou521tosimda'
#定义正则表达式
reg = '521'
#调用正则函数方法
res = re.findall(reg,vars)
print(res)
#运行结果:['521']
'''
2)re模块的相关函数–match与search
如果string的开始位置能够找到这个正则样式的任意个匹配,就返回一个相应的匹配对象。如果不匹配,
就返回None ;注意它与零长度匹配是不同的。
#re模块的相关函数其他函数--match与search
'''
re.match()函数
+从头开始匹配
+要么第一个就符合要求,要么不符合
+匹配成功则返回match对象,否则返回None
+可以使用group()方法获取返回的数据
+可以使用span()获取
re.search()函数
+从字符串开头到结尾进行搜索式的匹配
+匹配成功则返回search对象,否则返回None
+可以使用group()方法获取返回的数据
+可以使用span()获取
search()与match()方法的区别:
match()方法是从字符串的开头进行匹配,如果开始就不符合正则的要求,则匹配失败,返回None
search()方法是从字符串的开始位置一直搜索到字符串的最后,如果整个字符串中都没有匹配到,则失败,返回None
re.findall()
re.finditer()
re.sub()
'''
import re
#定义字符串
vars = 'iloveyou521tosimda'
'''
#调用正则match函数方法
#定义正则表达式
reg = 'ilove' #若输入love则返回None
res = re.match(reg,vars)
# print(res)
#运行结果<_sre.SRE_Match object; span=(0, 5), match='ilove'>
#若想从结果中直接获取字符串
print(res.group()) #获取返回的数据结果
#运行结果ilove
print(res.span()) #获取匹配结果的下标区间
#运行结果(0, 5)截取到5之前的数据
'''
#调用正则search函数方法
#定义正则表达式
reg = 'love'
res = re.search(reg,vars)
print(res)
print(res.group())
print(res.span())
#运行结果
# <_sre.SRE_Match object; span=(1, 5), match='love'>
# love
# (1, 5)
3)re模块相关函数
#re模块相关函数--其他函数
'''
re.findall()
+按照正则表达式的规则在字符串中匹配元素,结果返回一个列表,如果没有找到则返回空列表
re.finditer()
+按照正则表达式的规则在字符中匹配所有符合的元素,返回一个迭代器
re.sub()搜索替换
+按照正则表达式规则,在字符串中找到需要被替换的字符串,完成一个替换
参数:
pattern:正则表达式规则,匹配需要被替换的字符串
repl:替换后的字符串
string:被替换的原始字符串
compile()
可以直接将正则表达式定义为正则对象,使用正则对象直接操作
'''
import re
#定义字符串
varstr = 'iloveyou521tosimida511'
#正则表达式
reg ='\d{3}'
#函数调用
# res = re.findall(reg,varstr)
res = re.finditer(reg,varstr)
# print(list(res))
# print(res)
# '''运行结果[<_sre.SRE_Match object; span=(8, 11), match='521'>, <_sre.SRE_Match object; span=(19, 22), match='511'>]
# '''
'''
reg ='\d{3}'
运行结果['5', '2', '1', '5', '1', '1']
reg ='\d{4}'
运行结果['521', '511']
reg ='\d{3}'
res = re.finditer(reg,varstr)
运行结果
'''
#找到数字,替换成其它
# res = re.sub(reg,'AAA',varstr)
# print(res)
#直接定义正则表达式对象
reg = re.compile('\d{3}')
#直接使用创建的正则对象,去调用对应的方法或者函数
res = reg.findall(string=varstr)
# print(res)
lines = [
'i love 512 you',
'i love 521 you',
'i love 345 you',
'i love 543 you',
]
reg = re.compile('\d{3}')
for i in lines:
# reg = '\d{3}'
# res = re.search(reg,i)
# print(res.group())
res = reg.search(i).group()
print(res)
'''
运行结果:
512
521
345
543
'''
4)re模块–正则表达式的定义和规则
#re模块--正则表达式的定义和规则
import re
#普通字符
# vars = 'iloveyou'
# reg = 'love'
# res = re.search(reg,vars).group()
# print(res)
#运行结果:love
#转义字符\w \W \d \D \s \S..........
varstr = '2$_ilove5 21you'
reg = '\w'#代表 单个 字母、数字、下划线
reg = '\W'#代表 单个的 非字母、数字、下划线
reg = '\d'#代表 单个的 数字
reg = '\D'#代表 单个的 非数字
reg = '\s'#代表 单个的 空格符或制表符
reg = '\S'#代表 单个的 非 空格符或制表符
reg = '\w\w\w\w\d'#组合使用
#特殊字符 . * + ? {} () ^ $
varstr = 'hello WORLD 5211 iloveyou'
reg = '.' # . 点 代表 单个的 任意字符 除了换行符之外
reg = '.*' # * 星 代表匹配次数 任意次数
'''
*的特点:
如果使用*号,那么在匹配开始处如果符合要求,
则按照规则一直向后匹配,直道不符合匹配规则结束并把前面符合的数据返回
如果使用*号,那么在匹配开始处如果不符合要求,
则直接返回,匹配到的次数为0
'''
reg = '\w+' # + 代表匹配字数 至少要求匹配一次
reg = '\w+?'# ? 拒绝贪婪,就是前面的匹配规则只要达成则返回
reg = '\w+?'
reg = '\w{4}'#{}代表匹配数字,{4}一个数字时,表示必须匹配的次数
reg = '\w{2,5}'#{}代表匹配数字,{2,5}两个数字时,表示必须匹配的区间次数
reg = '[A-Z,a-z,0-9,]'#[]代表字符的范围[A-Z,a-z,0-9,] = \w
reg = '\w+(\d{4})' #()代表子组,括号中的表达式首先作为整个正则的一部分,另外会把符合小括号中的内容单独提取一份
varstr = '17610105211'
#定义一个匹配手机号的正则表达式
reg = '^1\d{11}$' # ^ 代表开头 $ 代表结尾
res = re.search(reg,varstr).group()
print(res,len(res))
#运行结果:i
#正则模式 re.I不区分大小写
vars = 'iLOVEyou'
reg = reg.search(reg,vars,re.I)
print(re)
#练习题
#定义一个正则表达式,来验证邮箱是否正确
#+规定qq号码必须是5~12位的数字,后面必须跟".com"
#完善手机号的正则表达式
#定义一个匹配 IP 的正则表达式 192.168.1.1 255.255.255.0
5)正则实战–猿来如此
'''
数据源地址:https://www.lmonkey.com/ask
数据字段:问题 时间 作者 url链接
'''
import requests,re,json
#定义请求的url和请求头信息
url = 'https://www.lmonkey.com/ask'
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.97 Safari/537.36'
}
#2.发起请求
res = requests.get(url,headers=headers)
#3.检测请求是否成功
if res.status_code == 200:
#4.获取返回的数据
res_html = res.text
# with open('./res.html','w',encoding='utf-8') as fp:
# fp.write(res_html)
#5.进行数据解析
#定义解析问题标题的正则
reg = '(.*?)
#调用正则方法去获取问题的标题
titlelist = re.findall(reg,res_html)
#定义解析作者的正则
reg = '(.*?)'
authorlist = re.findall(reg,res_html)
# 定义解析问题的时间
reg = ''
datatime = re.findall(reg,res_html)
#获取文章的连接地址
reg = ''
urllist = re.findall(reg,res_html)
#压缩数据
#常规方法处理数据[{},{},{}]
data = list(zip(titlelist,authorlist,datatime,urllist))
# datalist = []
# for i in data:
# res = {'title':i[0],'url':i[1],'author':i[2],'datatime':i[3]}
# datalist.append(res)
# print(datalist)
datalist = [{'title':i[0],'url':i[1],'author':i[2],'datatime':i[3]} for i in data]
print(datalist)
#数据入库
with open('./data.json','w',encoding='utf-8') as fp:
json.dump(datalist,fp)
输出的结果,用json在线解析及格式化验证工具对其格式进行处理,显示如下:
[
{
“title”:"【Java】You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version for the right syntax to use near ‘USER_ID=‘2’’ at line 1",
“url”:“轻风_N4zWcI”,
“author”:“2020-06-23 16:26:33”,
“datatime”:“https://www.lmonkey.com/ask/22985”
},
{
“title”:"【前端】为什么404代表找不到网址,404这个数字背后的逻辑是什么?",
“url”:“感觉_sp7aqM”,
“author”:“2020-06-20 21:29:36”,
“datatime”:“https://www.lmonkey.com/ask/22984”
},
{
“title”:"【PHP】使用User::create($input);进行添加数据,只有password字段添加成功了,而username是null。传输的有数据,不知道为什么,谢谢老师的解答。",
“url”:“雨季”,
“author”:“2020-05-25 15:12:05”,
“datatime”:“https://www.lmonkey.com/ask/22983”
},
{
“title”:"【前端】学习猿地的课程列表页,怎么我在官网找不到?有老师用到的图片素材吗?",
“url”:"? 月",
“author”:“2020-05-20 22:30:35”,
“datatime”:“https://www.lmonkey.com/ask/22982”
},
{
“title”:"【Java】打开的软件,是?",
“url”:“young先森”,
“author”:“2020-05-19 21:01:36”,
“datatime”:“https://www.lmonkey.com/ask/22981”
},
{
“title”:"【PHP】!DOCTYPE 标准是大写还是小写",
“url”:“ニック”,
“author”:“2020-05-18 23:04:01”,
“datatime”:“https://www.lmonkey.com/ask/22980”
},
{
“title”:"【PHP】什么时候会出thinkphp的内容?我看你们的课程介绍里面有才买的课程的",
“url”:“爱唯主机”,
“author”:“2020-05-10 10:44:40”,
“datatime”:“https://www.lmonkey.com/ask/22979”
},
{
“title”:"【Python】源码哪里有",
“url”:“孫小兜”,
“author”:“2020-05-08 16:36:02”,
“datatime”:“https://www.lmonkey.com/ask/22978”
},
{
“title”:"【前端】不需要封装函数去校验获取下一个兄弟节点的类型",
“url”:“Beyant”,
“author”:“2020-04-27 21:30:36”,
“datatime”:“https://www.lmonkey.com/ask/22977”
},
{
“title”:"【Java】课程一般吧",
“url”:“阳阳_sRAvEK”,
“author”:“2020-04-25 16:50:53”,
“datatime”:“https://www.lmonkey.com/ask/22976”
},
{
“title”:"【Java】课程一般吧",
“url”:“阳阳_sRAvEK”,
“author”:“2020-04-25 16:49:20”,
“datatime”:“https://www.lmonkey.com/ask/22975”
},
{
“title”:"【Java】Servlet.service() for servlet [com.shop.servlet.user.DoUserAdd] in context with path [/ShoppingProject] threw exception",
“url”:“pado”,
“author”:“2020-04-22 20:15:33”,
“datatime”:“https://www.lmonkey.com/ask/22974”
},
{
“title”:"【Java】根据老师步骤进行,最后跳转显示org.apache.catalina.connector.RequestFacade cannot be cast to javax.servlet.ServletResponse,这是什么原因呢?",
“url”:“顾你安稳”,
“author”:“2020-04-21 22:31:25”,
“datatime”:“https://www.lmonkey.com/ask/22973”
},
{
“title”:"【Java】老师的表单验证好像写错了吧,有bug。如果其他数据都对,但是验证码那一项写错,表单照样可以提交,并没有阻止。是不是Ajax的异步造成的bug。",
“url”:“喜欢悠哉独自在”,
“author”:“2020-04-20 18:41:47”,
“datatime”:“https://www.lmonkey.com/ask/22972”
},
{
“title”:"【Python】help,爬虫豆瓣电影TOP250爬取电影名称,导演,年份,链接–《初恋这件小事》的导演爬不下来,help",
“url”:“惠之吉”,
“author”:“2020-04-19 09:52:42”,
“datatime”:“https://www.lmonkey.com/ask/22971”
}
]