HBase集群平滑迁移步骤
HBase集群平滑迁移步骤
测试环境
| CDH版本 | HBASE版本 | |
|---|---|---|
| 测试源集群 | 5.15.1 | 1.2.0 |
| 测试目标集群 | 6.2.0 | 2.1.0 |
线上迁移环境
| CDH版本 | HBASE版本 | |
|---|---|---|
| 线上源集群 | 5.9.3 | 1.2.0 |
| 线上目标集群 | 6.2.0 | 2.1.0 |
迁移前准备
源集群配置
snapshot配置(已配置忽略)
#修改配置
hbase.snapshot.enabled=true
replication配置(已配置忽略)
#设置
hbase.replication=true
源集群表信息统计:
查看namespace:
#查看是否有用户namespace
hbase(main):001:0> list_namespace
NAMESPACE
default
hbase
2 row(s) in 0.3830 seconds
查看各namespace下表
#查看namespace:hbase下是否有需要迁移的表
hbase(main):002:0> list_namespace_tables 'hbase'
TABLE
meta
namespace
2 row(s) in 0.0260 seconds
#namespace:hbase表不需要迁移
确定待迁移表
#确定待迁移表为:namespace:default下表,总共183张表
hbase(main):003:0> list_namespace_tables 'default'
TABLE
air_message_record
ali_upload_records
ali_upload_records_sec
alibaba_records
alipay_records
alitaobao_records
attachments
audit_logs
audit_message
.................................
zhima_feedbacks
zhima_history_feedbacks
183 row(s) in 0.2350 seconds
在目标集群创建与源集群相同的表
方式一:
参考地址:
https://www.cloudera.com/documentation/enterprise/latest/topics/cdh_bdr_hbase_replication.html#concept_xjp_2tt_nw
/**If the table to be replicated does not yet exist on the destination cluster, you must create it. The easiest way to do this is to extract the schema using HBase Shell.
/**On the source cluster, describe the table using HBase Shell. The output below has been reformatted for readability.
hbase> describe acme_users
Table acme_users is ENABLED
acme_users
COLUMN FAMILIES DESCRIPTION
{NAME => 'user', DATA_BLOCK_ENCODING => 'NONE', BLOOMFILTER => 'NONE',
REPLICATION_SCOPE => '0', VERSIONS => '3', COMPRESSION => 'NONE',
MIN_VERSIONS => '0', TTL => 'FOREVER', KEEP_DELETED_CELLS => 'FALSE',
BLOCKSIZE => '65536', IN_MEMORY => 'false', BLOCKCACHE => 'false'}
/**Copy the output and make the following changes:
/**For the TTL, change FOREVER to org.apache.hadoop.hbase.HConstants::FOREVER.
/**Add the word CREATE before the table name.
/**Remove the line COLUMN FAMILIES DESCRIPTION and everything above the table name.
/**The result is a command like the following:
"CREATE 'cme_users' ,
{NAME => 'user', DATA_BLOCK_ENCODING => 'NONE', BLOOMFILTER => 'NONE',
REPLICATION_SCOPE => '0', VERSIONS => '3', COMPRESSION => 'NONE',
MIN_VERSIONS => '0', TTL => org.apache.hadoop.hbase.HConstants::FOREVER, KEEP_DELETED_CELLS => 'FALSE',
BLOCKSIZE => '65536', IN_MEMORY => 'false', BLOCKCACHE => 'false'}
/**On the destination cluster, paste the command from the previous step into HBase Shell to create the table.
方式二:Hbase-ui界面,复制表信息,然后创建:
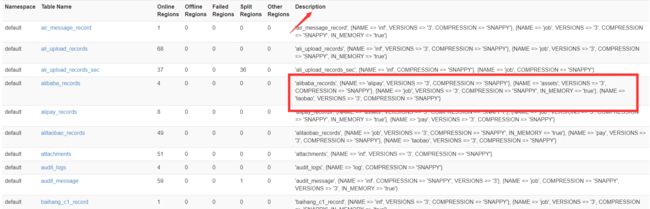
image.png
线上所有Table创建快捷脚本:
省略。。。
在源集群添加目标集群作为peer(增量配置)
#add_peer 'ID', 'CLUSTER_KEY',其中后者参数值为:
hbase.zookeeper.quorum:hbase.zookeeper.property.clientPort:zookeeper.znode.parent
#如下
add_peer '1', CLUSTER_KEY => "10.10.15.56,10.10.15.18,10.10.15.79,10.10.15.84,10.10.15.88:2181:/hbase"
#NAMESPACES => ["default"], SERIAL => true**新版本才支持****
为什么新版本中需要串行Replication
参考:https://hbase.apache.org/book.html#_serial_replication
- 先put然后delete到源集群
- 由于region移动/ RS故障,它们被不同的复制源线程推送到对等群集。
- 如果在put之前将delete删除操作推入对等群集,并且在将put放置到对等群集之前在同等群集中发生flush和major-compact,则将收集删除并将该put放在对等群集中,但是在源群集中,该put操作将被delete,因此源群集和目标群集之间的数据不一致。
逐个表依次迁移步骤(增量)
开启表级replication,开始双写
#列族cf1..
hbase> alter 'tableName', {NAME => 'cf1', REPLICATION_SCOPE => '1'},{NAME => 'cf2', REPLICATION_SCOPE => '1'}...
验证replication命令:(版本不一致,无法检查。略过)
#命令:
hbase org.apache.hadoop.hbase.mapreduce.replication.VerifyReplication [--starttime=timestamp1] [--stoptime=timestamp] [--families=comma separated list of families] peerId tableName
#命令参考:
bash-4.2$ ./bin/hbase org.apache.hadoop.hbase.mapreduce.replication.VerifyReplication
Usage: verifyrep [--starttime=X] [--endtime=Y] [--families=A] [--row-prefixes=B] [--delimiter=] [--recomparesleep=] [--batch=] [--verbose] [--sourceSnapshotName=P] [--sourceSnapshotTmpDir=Q] [--peerSnapshotName=R] [--peerSnapshotTmpDir=S] [--peerFSAddress=T] [--peerHBaseRootAddress=U]
Options:
starttime beginning of the time range
without endtime means from starttime to forever
endtime end of the time range
versions number of cell versions to verify
batch batch count for scan, note that result row counts will no longer be actual number of rows when you use this option
raw includes raw scan if given in options
families comma-separated list of families to copy
row-prefixes comma-separated list of row key prefixes to filter on
delimiter the delimiter used in display around rowkey
recomparesleep milliseconds to sleep before recompare row, default value is 0 which disables the recompare.
verbose logs row keys of good rows
sourceSnapshotName Source Snapshot Name
sourceSnapshotTmpDir Tmp location to restore source table snapshot
peerSnapshotName Peer Snapshot Name
peerSnapshotTmpDir Tmp location to restore peer table snapshot
peerFSAddress Peer cluster Hadoop FS address
peerHBaseRootAddress Peer cluster HBase root location
Args:
peerid Id of the peer used for verification, must match the one given for replication
tablename Name of the table to verify
Examples:
To verify the data replicated from TestTable for a 1 hour window with peer #5
$ hbase org.apache.hadoop.hbase.mapreduce.replication.VerifyReplication --starttime=1265875194289 --endtime=1265878794289 5 TestTable
验证结果参考:
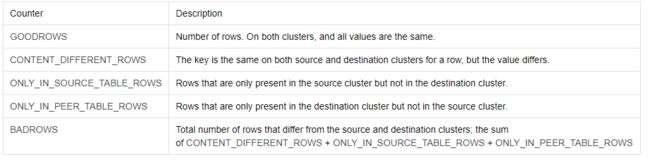
image.png
制作snapshot(全量数据迁移)
snapshot 'sourceTable', 'snapshotName'
导出snapshot到目标集群
#命令:
hbase org.apache.hadoop.hbase.snapshot.ExportSnapshot -snapshot xxx.snapshot -copy-to hdfs://xxx:8020/hbase -mappers XX -overwrite -bandwidth 5
#使用hdfs用户
eg:
hbase org.apache.hadoop.hbase.snapshot.ExportSnapshot -snapshot xinyan_black_records_sec.snapshot07021143 -copy-to hdfs://10.10.15.56:8020/hbase -chuser hbase -chgroup hbase -chmod 777 -overwrite -bandwidth 5
#命令参考;
Usage: bin/hbase org.apache.hadoop.hbase.snapshot.ExportSnapshot [options]
where [options] are:
-h|-help Show this help and exit.
-snapshot NAME Snapshot to restore.
-copy-to NAME Remote destination hdfs://
-copy-from NAME Input folder hdfs:// (default hbase.rootdir)
-no-checksum-verify Do not verify checksum, use name+length only.
-no-target-verify Do not verify the integrity of the \exported snapshot.
-overwrite Rewrite the snapshot manifest if already exists
-chuser USERNAME Change the owner of the files to the specified one.
-chgroup GROUP Change the group of the files to the specified one.
-chmod MODE Change the permission of the files to the specified one.
-mappers Number of mappers to use during the copy (mapreduce.job.maps).
-bandwidth Limit bandwidth to this value in MB/second.
Examples:
hbase org.apache.hadoop.hbase.snapshot.ExportSnapshot \
-snapshot MySnapshot -copy-to hdfs://srv2:8082/hbase \
-chuser MyUser -chgroup MyGroup -chmod 700 -mappers 16
hbase org.apache.hadoop.hbase.snapshot.ExportSnapshot \
-snapshot MySnapshot -copy-from hdfs://srv2:8082/hbase \
-copy-to hdfs://srv1:50070/hbase \
** bandwidth单位为MB/s,大B,限制的是单个Region Server的流量,若有n个Region Server,总流量为nbandwidth*
目标集群bulkload导入snapshot
bulkload位置
Snapshot metadata is stored in the .hbase_snapshot directory under the hbase root directory (/hbase/.hbase-snapshot). Each snapshot has its own directory that includes all the references to the hfiles, logs, and metadata needed to restore the table.hfiles required by the snapshot are in the
/hbase/data// / / /
location if the table is still using them; otherwise, they are in
/hbase/.archive// / / /.
修改bulkload配置参数;(新集群已经修改)
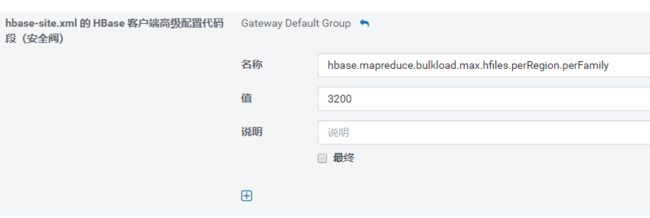
image.png
导入命令(CDH6支持全表导入):(全量)
#默认最大的HFile个数最大32,需要修改参数;hbase.mapreduce.bulkload.max.hfiles.perRegion.perFamily,如上:
./bin/hbase org.apache.hadoop.hbase.tool.LoadIncrementalHFiles \
-Dcreate.table=no \
/hbase/archive/data/default/${TableName}/ \
${TableName} -loadTable
#命令实例参考:
hbase org.apache.hadoop.hbase.tool.LoadIncrementalHFiles -Dcreate.table=no /hbase/archive/data/default/TableName/ ${TRableName} -loadTable
目标集群验证表迁移操作
检查HBase的region一致性与table完整性
#命令
./bin/hbase hbck ${tableName} -checkCorruptHFiles -sidelineCorruptHFiles -boundaries -summary -exclusive
#命令参考;
-----------------------------------------------------------------------
NOTE: As of HBase version 2.0, the hbck tool is significantly changed.
In general, all Read-Only options are supported and can be be used
safely. Most -fix/ -repair options are NOT supported. Please see usage
below for details on which options are not supported.
-----------------------------------------------------------------------
Usage: fsck [opts] {only tables}
where [opts] are:
-help Display help options (this)
-details Display full report of all regions.
-timelag Process only regions that have not experienced any metadata updates in the last seconds.
-sleepBeforeRerun Sleep this many seconds before checking if the fix worked if run with -fix
-summary Print only summary of the tables and status.
-metaonly Only check the state of the hbase:meta table.
-sidelineDir HDFS path to backup existing meta.
-boundaries Verify that regions boundaries are the same between META and store files.
-exclusive Abort if another hbck is exclusive or fixing.
Datafile Repair options: (expert features, use with caution!)
-checkCorruptHFiles Check all Hfiles by opening them to make sure they are valid
-sidelineCorruptHFiles Quarantine corrupted HFiles. implies -checkCorruptHFiles
Replication options
-fixReplication Deletes replication queues for removed peers
Metadata Repair options supported as of version 2.0: (expert features, use with caution!)
-fixVersionFile Try to fix missing hbase.version file in hdfs.
-fixReferenceFiles Try to offline lingering reference store files
-fixHFileLinks Try to offline lingering HFileLinks
-noHdfsChecking Don't load/check region info from HDFS. Assumes hbase:meta region info is good. Won't check/fix any HDFS issue, e.g. hole, orphan, or overlap
-ignorePreCheckPermission ignore filesystem permission pre-check
验证表中数据一致性:
小表:
通过hbase count命令
大表:
#大表通过MR验证
./bin/hbase org.apache.hadoop.hbase.mapreduce.RowCounter -Dhbase.client.scanner.caching=100 -Dmapreduce.map.speculative=true ${tableName}
迁移完成,观察线上HBase运行
遇到问题
经过测试,在一定宽带及IO下,小表EXportSnapshot没有问题,大表会出现archive下HFile找不到问题;如果小表使用更低宽带EXportSnapshot,也会出现此类问题;
解决:
已解决:
使用HBase导出命令:hbase org.apache.hadoop.hbase.snapshot.ExportSnapshot -snapshot ycsbTable02.snapshot -copy-to hdfs://10.10.15.56:8020/hbase/ycsb -chuser hbase -chgroup hbase -chmod 755 -mappers 1 -bandwidth 1 -overwrite 可以解决大表迁移是失败问题。
不要放到目标集群的/hbase/archive 目录下,切换别的目录
原因:因为master上会启动一个定期清理archive中垃圾文件的线程(HFileCleaner),定期会对这些被删除的垃圾文件进行清理(5分钟扫描一次)。如果目标集群下的snap文件没有被引用,就会被HFileCleaner 清理掉