深度学习 (四)Keras利用CNN实现图片识别(Mnist、Cifar10)
视觉集
视觉数据库是用来提供给图片识别领域用素材,目前各个教材常用的主要有手写数字识别库、10中小图片分类库,详细介绍如下:
Mnist
MNIST(Mixed National Institute of Standards and Technology database)是一个计算机视觉数据集,它包含70000张手写数字的灰度图片,其中每一张图片包含 28 X 28 个像素点。可以用一个二维数字数组来表示这张图片,因为它单色只有一个通道计算会方便一些。
Cifar-10
该数据集主要是由三位作者收集、整理而成,来用于图像识别领域,其中包含60000张图片,50000是训练集,10000是测试集,每一张图片为32323个像素点,它比手写数字图片稍微复杂一点,它有RGB三个颜色通道,方便以后的爱好者专注于提高算法能力不用单独去为很多训练数据耽误太多时间,现今很多教材或者课程也都是基于这些数据集来讲解课程知识。
实战
下载
网上搜索即可
def load_data(path):
'''
加载数据图片
:param path:
:return:
'''
f = np.load(path)
x_train, y_train = f['x_train'], f['y_train']
x_test, y_test = f['x_test'], f['y_test']
f.close()
return (x_train, y_train), (x_test, y_test)
查看
def plot_images_labels_prediction(images,labels,prediction,idx,num=10):
fig = plt.gcf()
fig.set_size_inches(12,14)
if num>25:num=25
for i in range(0,num):
ax = plt.subplot(5,5,1+i)
ax.imshow(images[idx],cmap='binary')
title = 'label='+str(labels[idx])
if len(prediction)>0:
title+=",predict="+str(prediction[idx])
ax.set_title(title,fontsize=10)
ax.set_xticks([]);ax.set_yticks([])
idx+=1
plt.show()
mnist
下图为手写数字识别的图像像素展示,识别数字都是灰色单通道图像所以展示出来是28*28的矩阵,相比cifar10三通道图像比简单一些,cifar10每个图片为下面这样类似矩阵三个组成。

cifar10
十种训练集图片如下:

预处理
预处理即将图片处理为对应算法容易处理的数据格式,对于DNN一般讲图片拉伸为一维向量,CNN并不需要这样处理,他们都需要的处理是将数据标准化统一量纲,对于像素一般除以255,数字值小了算法训练容易收敛和稳定。
mnist
# print(x_Train.shape[0])
x_Train4D = x_Train.reshape(x_Train.shape[0],28,28,1).astype('float32')
x_Test4D = x_Test.reshape(x_Test.shape[0],28,28,1).astype('float32')
x_Train4D_normalize = x_Train4D/255
x_Test4D_normalize = x_Test4D/255
print(x_Train4D_normalize[0].shape)
y_TrainOneHot = np_utils.to_categorical(y_Train)
y_TestOneHot = np_utils.to_categorical(y_Test)
cifar10
确定网络结构
这里我们使用keras来实现卷积网络操作,发现这个框架对于新手来说是很容易上手,定义出来一个外层框架,然后我们依次定义里面的网络结构即可,每次add进去一层即可,并不需要我们详细定义每层网络结构,建议初学者也先尝试这个框架。
mnist
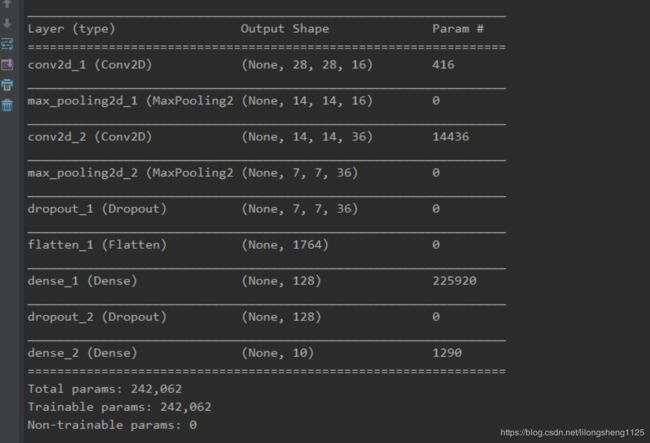
手写识别网络结构,可以通过summary查看各层信息
model = Sequential()
model.add(Conv2D(filters=16,kernel_size=(5,5),padding='same',input_shape=(28,28,1),activation='relu'))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Conv2D(filters=36,kernel_size=(5,5),padding='same',activation='relu'))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Dropout(0.25))
model.add(Flatten())
# add hidden layer1
model.add(Dense(128,activation='relu'))
model.add(Dropout(0.5))
# add output layer
model.add(Dense(10,activation='softmax'))
# model summary
print(model.summary())
cifar10
cifar10卷积结构,比mnist多了一层,因为输入的数据变复杂了,可见模型越深越大表示越复杂,能力也越强,当然越不容易训练出来结果。
model = Sequential()
# add conv1 layer
model.add(Conv2D(filters=32,kernel_size=(3,3),
input_shape=(32,32,3),activation='relu',padding='same'))
# add dropout
model.add(Dropout(rate=0.25))
# add maxpooling layer
model.add(MaxPooling2D(pool_size=(2,2)))
# add conv2 layer
model.add(Conv2D(filters=64,kernel_size=(3,3),activation='relu',padding='same'))
# add dropout
model.add(Dropout(rate=0.25))
# add maxpooling layer
model.add(MaxPooling2D(pool_size=(2,2)))
# add flatten layer
model.add(Flatten())
model.add(Dropout(0.25))
# add hidden layer
model.add(Dense(1024,activation='relu'))
model.add(Dropout(0.25))
# output layer
model.add(Dense(10,activation='softmax'))
print(model.summary())

结构对比
- 为什么最后一层神经元个数为分类个数
从网上搜了下没找到,个人理解这最后一层之所以神经元个数为分类个数是为了容易出来出来结果,每一类结果都是属于这一类的概率,非常容易看出来 - 图片的单通道和多通道对结构的影响
通道多了即像素点多了,参数会成倍增加,比如32323的cifar10图片,上面第一个卷积层 卷积核为32个 receptive field 为33的大小,那么参数为32333+32(偏置项) = 869个,将会增加模型的复杂度。 - 卷积层和池化层通道计算
卷积层通道的个数是本层定义的,与上一个卷积层没有直接关系,但是每个通道生成时和上一层的所有通道计算值有关
池化层不会改变通道个数,可能改变的是每层通道(feature map)的大小
开始训练
输入训练数据训练
model.compile(loss='categorical_crossentropy',optimizer='adam',metrics=['accuracy'])
train_history = model.fit(x_img_train_normalize,y_label_train_OneHot,validation_split=0.2,epochs=10,batch_size=128,verbose=1)
模型保存
这一步个人感觉还挺重要,发现网络越深训练出来一个好的网络越困难,不容易得到结果,尤其是我们个人笔记本电脑,保存起来下次可以直接使用不在训练。
try:
model.load_weights('SaveModel/cifarCnnModel.h5')
print('加载模型成功!继续训练模型')
except:
print('加载模型是失败!开始训练一个新模型')
model.save_weights('SaveModel/cifarCnnModel.h5')
评估
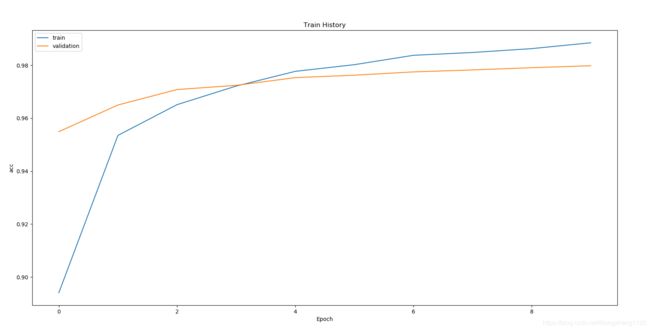
下面这个评估图是以每周期训练出来的训练集和验证集准确率为点进行画出来的,根据我们经验训练集合验证集准确率越接近表明结果越好,模型效果越好。从图来看有一些过拟合产生,因为训练集准确率大于验证集。
预测
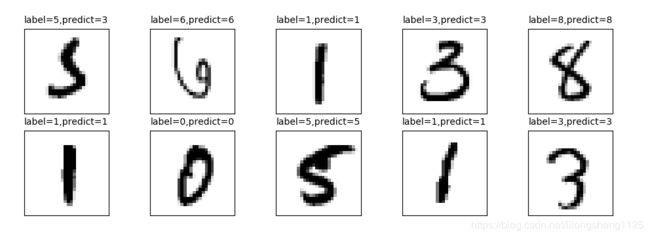
如下图为手写识别预测出来的结果
问题点
- 下载数据
下载数据时直接用keras下载是很慢的,最快的方式是自己从网上另行下载,下载完修改一些load_data()方法 - summary
该方法是model的一个摘要信息,对于了解现在的模型结构非常有帮助,它会告诉你每次结构以及每层多少个训练参数等信息 - cnn通用结构
input、[ [ conv --> relu ] * N --> pool ?] * M、[ fc-- > relu ]、fc
说明:第一层为(输入层)、紧接着为(卷积层 激活函数) 这一结构可以重复N次,然后接一个池化层,也可以不接池化层,(卷积层 激活寒素 池化层)这一结构可以重复M次出现,依据问题规则设定,其次是全连接层 激活函数,这一层可有可无,最后一层为全连接层,一般一定要有。
随笔
如何把专业的知识讲给非专业人听懂?
现在可以说各行各业都有行业壁垒,每个一个人事件、生命有限,如何在有限的时间做更多的事情、在短时间内高效率的听懂别人说什么或给别人讲懂专业知识很重要,事实是专业的内容大部分人不爱听因为听着实在没有意思,很难听懂,这往往是讲者自身没有完全懂是啥,没有结合生活中的例子讲出来,万事都是可以拿出来对应到生活中去的,科学来源于生活、实事求是是科学的本质,如何才能让别人听懂自己的专业知识呢?
1.合乎逻辑的比喻
先来一个合乎情理的比喻 ,能量守恒大家都知道如何让没学过物理的人知道理解呢,可以比如说像马儿不给草吃能长肉么,马儿跑又会掉肉,能量是不变的,另外举一个不合理比喻辜鸿铭曾拿一个茶壶多个杯子来说明应该一夫多妻制度,马上有人反驳为啥茶壶是男人而非女人,可见此比喻并不恰当。
2.简单化 忽略细节
在给非自己专业人讲东西时,要站在大家能理解的角度将问题,让别人能听懂的水平,如电视的分辨率常常说1k 高清4k等,其实4k精度是4096像素,其实对于大部分百姓我们是不需要那么清楚这个细节,说了返回效果不好。