【专题2:qt工程师】 之 【39.音视频基础概念 之 下】
笔者在嵌入式领域深耕6年,对嵌入式项目构建,BLDC电机控制,产品上位机开发以及产品量产和产品售后维护有多年工作经验。经验分享,从0到1, 让我带你从实际工作的角度走进嵌入式成长之路。
原创不易,欢迎大家关注我的微信公众号:嵌入式工程师成长之路 或 扫下面二维码

所有文章总目录:【电子工程师 qt工程师】
原创视频总目录:【电子工程师 qt工程师】
1.视频像素数据
(1)屏幕只能播放RGB或YUV的数据。
(2)像素数据保存了屏幕上每个像素点的像素值。
(3)常见的像素数据格式有RGB24, RGB32, YUV420P,YUV422P,YUV444P等。压缩编码中一般使用的是YUV格式的像素数据,最为常见的格式为YUV420P。
(4)视频像素数据体积很大,一般情况下1小时高清视频的RGB24格式的数据体积为:
360025192010803=559.9GByte
这里假定帧率为25Hz,取样精度8bit。
(5)YUV格式像素数据查看工具:YUV Player
2.RGB格式
(1)Red、Green、Blue三种颜色,可以混合成世界上所有的颜色。彩色图像中每个点,由R、G、B三个分量组成,R,G,B分别用一个字节的数据表示,即总共用3个字节表示。
(2)以RGB24为例,图像像素数据的存储方式如下:

从图中可以看出,RGB24依次存储了每个像素点的R、G、B信息。
注:BMP文件中存储的就是RGB格式的像素数据。
为了提高算法的效率,很多程序,譬如ffmpeg,会将数据补齐,譬如补齐为4字节或8字节对齐(原本用3个字节表示RGB,但为了提高算法效率,用4个字节来表示RGB)。这里有一个坑,在显示时,需要将这些ffmpeg自动补齐的直接去掉,否则显示会有问题(很多显示问题都是由这个造成)。
自动补齐的效果就是,第4个像素不是从第9个字节开始,因为第8个字节后面补了一个3个字节,也就是第4个像素是从第12个字节开始的。所以在复制像素数据时,一般是一行一行的复制,但一行一行的复制效率低一些。如果不想一行一行的复制,需要保证 像素个数是4的倍数或者是8的倍数,譬如1280或1920。
软解码比硬解码性能和兼容性都更强,我们通常说的软解码性能会差指的是在一些嵌入式设备中,譬如在一些嵌入式设备中只有一个dsp芯片,其主频才1G,即单核1G,所以它的解码性能很差;而我们现在的CPU一般都是8核2G的,所以软解码的兼容器和性能一般都是强于硬解码的。硬解码一般是固定死的,即每秒钟只能解码60帧数据,但因为硬解码是固化在CPU里面的程序,类似于用硬件实现了解码功能,所以它不用做指令转换,CPU开销就小,省电。
在某些应用,譬如需要每秒钟解码200帧数据,用硬解码肯定解不了(某些安霸的芯片可以做到,但大部分手机芯片都做不到),只能用软解码。在直播或播放器领域,硬解码绰绰有余;但硬解码解出来的YUV格式数据和软解码解出来的YUV格式数据可能不一样,这时需要进行转换。
3.YUV格式
YUV是视频的像素数据。
(1)相关实验表明,人眼对亮度敏感而对色度不敏感。因而可以将亮度信息和色度信息分离,并对色度信息采用更“狠”一点的压缩方案,从而提高压缩效率。

实心圆表示Y,空心的大圆表示UV。
“Y”指亮度,也就是灰度值,“U”和“V”是成套/一起出现的,UV指色度。
(1)YUV444:如果8bit话,一个像素一个3个字节表示。
(2)YUV422:第一个Y用一个UV,第二个Y,用的也是第一个UV,即两个亮度共用一个色度。
(3)YUV420:一般解出来的都是这种格式的数据。四个Y共用一个UV,即四个亮度共用一个色度。这里的四个亮度不是连续的四个,而是上下四个,上下附近的点的色度变化不会太大,但亮度可能变化比较大。每个像素点用12bit来表示。
(4)示例
① 一个320*180大小的YUV420文件。

② Y数据

③ V数据

④ U数据
 (5)以YUV420P为例,图像像素数据的存储方式如图所示。从图中可以看出,YUV420P首先存储了整张图像的Y信息,然后存储整张图像的U信息,最后存储了整张图像的V信息。
(5)以YUV420P为例,图像像素数据的存储方式如图所示。从图中可以看出,YUV420P首先存储了整张图像的Y信息,然后存储整张图像的U信息,最后存储了整张图像的V信息。

⑤ 格式

YUV420和YUV420P的区别?
音频和视频都有这种带P的格式,带P的表示是以平面的形式存放数据。
譬如YUV420P,它是先将所有Y存在一起,然后再将所有U存在一起,最后再把所有V存在一起,即Y U V不是交织在一起的。
在ffmpeg中,可能会有三个地址,也就是有三个数组,用来分别存放Y U V,这需要注意。如果是RGBP也是一样的道理。而YUV420,是将Y U V交织在一起进行存储的。
思考:什么是分辨率?
譬如PC的屏幕是1200800的分辨率,表示屏幕的宽有1200个像素点,高有800个像素点。如果一个视频的分辨率是1200800,表示每一张视频画面(每一帧视频)的宽由1200个像素点组成,高由800个像素点组成。
但因为人对色度不敏感,所以在采集色素数据(U和V)时,可以每两个像素点只采集其中的一个为采样值,即采样数据是:第一个像素点、第三个像素点、第五个像素点…这样就可以减少视频的容量。
行和列都按照这种方式采集,所以U的数据就是原始数据的1/2 × 1/2 = 1/4,V也同理。所以整个YUV数据的大小 = 原始分辨率的宽 × 高 × (1+1/4+1/4) = 原始分辨率的宽 × 高 × 3/2。如果不这样处理:整个YUV数据的大小 = 原始分辨率的宽 × 高 × 3。
格式转换:

基于YUV格式的压缩算法非常高效(这是YUV出现的原因),YUV格式的数据需要转为RGB数据才能在显示器上显示。YUV转RGB这个部非常耗费资源,譬如画面的分辨率是1920*1800,每个像素点是3个字节,也就是一帧画面需要YUV转RGB转200多万次,数据量非常大,所以这部分工作可以交给GPU来做,GPU很擅长做这个事情。
BGRA中的A指透明度,视频播放一般直接是不透明,即A为255。
4.音频采样数据
(1)作用:保存了音频中每个采样点的值。
(2)音频采样数据体积很大,一般情况下一首4分钟的PCM格式的歌曲体积为:
4604410022=42.3MByte
这里假定采样率为44100Hz,采样精度为16bit。
(3)音频采样数据查看工具:Adobe Audition。
5.PCM格式
(1)PCM是音频(录音机)的采样数据。有三个参数比较重要:
- 声道 : 2声道,也称为通道(左右声道,左右声道都有称为立体声),5point1环绕声。如果是双声道采样,那么每秒钟采样的数据量就变成了44100*2个采样点。
- 采样率 : 1秒钟采样多少个点,人耳最好的采样率:44100HZ。所以一般音频的采样率都是44100,即一秒钟采集44100个数据。这个值越大,听到的声音的质量就越好。
- 位深度/样本格式/样本大小 : 16位,用两个字节来记存储一个左声道采样点的信息 ,右声道也同理。
①AV_SAMPLE_FMT_S16:用两个字节来存储的。
②AV_SAMPLE_FMT_FLET:用一个浮点类型来存储,即32bit/4字节来存储一个采样点,用float来存储
有利于编码算法的优化,但这种相机很少。如果解码之后的声音是这种格式,普通的声卡是播不了的,所以还需要先进行重采样,然后转为AV_SAMPLE_FMT_S16格式,即由32bit转为16bit。
(2)单声道的情况下按照顺序存储每个采样点的数据。
(3)双声道的情况下按照“左右、左右”的顺序存储每个采样点两个声道的数据。


S16P以平面的形式展开,就将左声道和右声道的数据分开来存储,所以也会有两个数组。做重采样的时候,如果是S16P的格式,需要给这两个数组,如果只给一个,重采样就会出错。非P形式就是一种交错格式的。
6.视频解码
- 纯净的视频解码流程:压缩编码数据->像素数据。例如解码H.264,就是“H.264码流->YUV”。
- 视频码流一般存储在一定的封装格式(例如MP4、AVI等)中。封装格式中通常还包含音频码流等内容。对于封装格式中的视频,需要先从封装格式中提取中视频码流,然后再进行解码。例如解码MKV格式的视频文件,就是“MKV->H.264码流->YUV”。
7.图解

音频帧每秒钟的帧率和视频帧每秒帧的帧率一般是不一样的。视频一般是一秒25帧数据(1秒播放2副画面),但音频,因为音频数据是根据采样率来定的,譬如采样率为44100(1秒中采集44100个单声道数据),如果把它做成25帧,则每一帧有多少个样本数量就不太好计算。音频帧帧率可以是22.5,即一个音频帧里面存放1024个样本,这样可以方便解码和编码的算法。
Aac解码出来之后一般使用一个float类型的空间来存放一个音频样本,这样方便做浮点运算和做编码和解码的性能运算。但float一般是4个字节,也就是32bit;除非专业显卡可能会支持32bit,普通显卡一般只支持16bit,好一点的支持24bit,所以需要进行重采样,即,将32bit的数据转为16bit,放到s16上播放(这里就是为什么需要重采样的原因)。
8.H.264/AVC视频编码标准
(1)视频编码层面(VCL):主要是视频数据的如何编码等内容。
(2)网络抽象层面(NAL):格式化数据并提供头信息,即,编码之后的数据如何存放。
9.NAL格式


我们平时说的每一帧压缩数据就是一个NAL单元(SPS与PPS除外)。因为文件头只存了关键帧(I帧)的索引,所以在实际的H264数据帧中,每一帧前面带有00 00 00 01或00 00 01分隔符,两个分隔符之间就是一个NAL单元。
ffmpeg解码之后会自动将这些分隔符去掉。一般来说编码器编出的首帧数据为PPS与SPS,接着为I帧。PPS、SPS指参数信息,譬如视频画面的分辨率等参数信息。
10.GOP
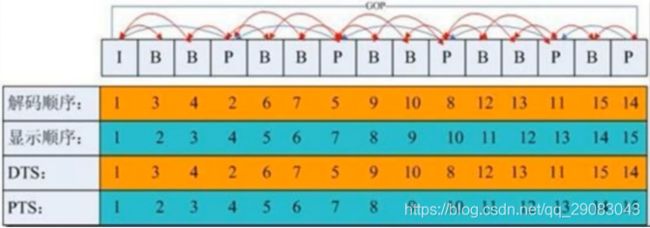
Gop是指一组图片,一组里面有一个关键帧,也就是I帧 ,关键帧存放完整的信息。这组图片的其他帧都是通过这个关键帧推算出来的。
P帧,存放的是相对于上一帧的变化,B帧存放的是相对于上一帧和下一帧之间的变化。GOP是可以独立播放的一组数据。注意:音频帧直接按采样顺序存储即可。
解码的时候,必须先找到关键帧(关键帧的索引在头信息中),才能开始解码,因为GOP中的其他帧都是根据关键帧推算出来的。一般设置为25或者50,譬如设置为50,也就是50帧里面有一个关键帧,如果50帧里面的关键帧丢失,会导致后面的解码出问题,譬如出现花屏。在做有些应用的时候,可能需要降低帧率,譬如1s中更新一次画面,其实只要找到所有的关键帧,然后解码播放即可,其他的帧直接跳过不解。
存放帧的顺序是按照显示的时间(pts)存放的。但解码的时候,B帧是根据前一帧和后一帧的变化计算出来的,所以解码B帧的时候,必须先知道其后一帧和前一帧数据,也就是必须后一帧数据必须先解码出来,才能再解码B帧。所以这就存在解码顺序和视频帧显示顺序不一致的现象,即dts和pts不一致。
总结:
视频解码出来之后是YUV数据,所以需要将YUV转为RGB数据。音频解码出来的就是pcm数据,不需要再次转换,但需要重采样,因为ffmpeg为了优化编解码算法,用一个float类型的空间来存储一个采样点的pcm数据,也就是32bit的数据。
但实际声卡只能播放16bit的数据,所以需要对32bit的数据进行重采样,重采样为16bit的数据,然后给声卡播放。也就是说,音频需要重采样,视频需要格式转换。