Partitioner分区过程分析
Partition的中文意思就是分区,分片的意思,这个阶段也是整个MapReduce过程的第三个阶段,就在Map任务的后面,他的作用就是使key分到通过一定的分区算法,分到固定的区域中,给不同的Reduce做处理,达到负载均衡的目的。他的执行过程其实就是发生在上篇文章提到的collect的过程阶段,当输入的key调用了用户的map函数时,中间结果就会被分区了。虽说这个过程看似不是很重要,但是也有值得学习的地方。Hadoop默认的算法是HashPartitioner,就是根据key的hashcode取摸运算,很简单的。
/** Partition keys by their {@link Object#hashCode()}.
*/
public class HashPartitioner implements Partitioner {
public void configure(JobConf job) {}
/** Use {@link Object#hashCode()} to partition. */
public int getPartition(K2 key, V2 value,
int numReduceTasks) {
return (key.hashCode() & Integer.MAX_VALUE) % numReduceTasks;
}
} 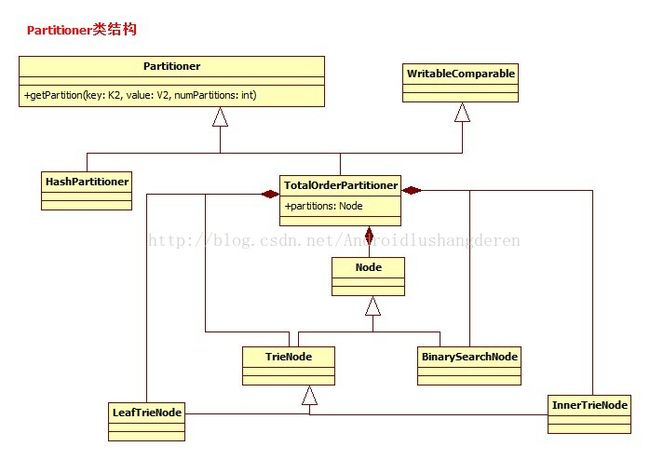
可见,TotalOrderPartitioner还是挺复杂的。
TotalOrderPartitioner的作用就是保证全局有序,对于key的划分,他划分了几个key的抽样点,作为key的划分点,比【2,4,6,8】,4个key抽样点,把区间划成了5份,如果某个key的值为5,他的区间为4-6,所以在第三区间,也就是说,这个类的作用就是围绕给定的划分点,寻找他的区间号,就代表任务的完成,至于你中间用的是二分搜索,还是其他的什么算法,都由你说了算。
好的,首先第一步,从配置文件中得到划分点,他其实是存在于一个叫partition.file的文件中,配置中只保留了路径,
public void configure(JobConf job) {
try {
//获得partition file
String parts = getPartitionFile(job);
final Path partFile = new Path(parts);
final FileSystem fs = (DEFAULT_PATH.equals(parts))
? FileSystem.getLocal(job) // assume in DistributedCache
: partFile.getFileSystem(job);
Class keyClass = (Class)job.getMapOutputKeyClass();
//从partition中读出Spilts分区点
K[] splitPoints = readPartitions(fs, partFile, keyClass, job);
....
然后开始关键的操作了,如果你的key值类型不是BinaryComparable二进制比较类型的话,比如能直接比较值的数字类型,就直接用二分算法,创建二分搜索节点,传入自己的比较器实现:
....
RawComparator comparator =
(RawComparator) job.getOutputKeyComparator();
for (int i = 0; i < splitPoints.length - 1; ++i) {
if (comparator.compare(splitPoints[i], splitPoints[i+1]) >= 0) {
throw new IOException("Split points are out of order");
}
}
boolean natOrder =
job.getBoolean("total.order.partitioner.natural.order", true);
//判断是否为BinaryComparable类型,如果是,建立Trie树
if (natOrder && BinaryComparable.class.isAssignableFrom(keyClass)) {
partitions = buildTrie((BinaryComparable[])splitPoints, 0,
splitPoints.length, new byte[0],
job.getInt("total.order.partitioner.max.trie.depth", 2));
} else {
//如果是不是则建立构建BinarySearchNode,用二分查找,用自己构建的比较器
partitions = new BinarySearchNode(splitPoints, comparator);
} /**
* For types that are not {@link org.apache.hadoop.io.BinaryComparable} or
* where disabled by total.order.partitioner.natural.order,
* search the partition keyset with a binary search.
*/
class BinarySearchNode implements Node {
//比较的内容节点
private final K[] splitPoints;
//比较器
private final RawComparator comparator;
BinarySearchNode(K[] splitPoints, RawComparator comparator) {
this.splitPoints = splitPoints;
this.comparator = comparator;
}
/**
* 通过自己传入的比较器方法进行二分查找
*/
public int findPartition(K key) {
final int pos = Arrays.binarySearch(splitPoints, key, comparator) + 1;
return (pos < 0) ? -pos : pos;
}
} 。有种二分搜索树的感觉。每个inner节点保留255个字节点,代表着255个字符
/**
* An inner trie node that contains 256 children based on the next
* character.
*/
class InnerTrieNode extends TrieNode {
private TrieNode[] child = new TrieNode[256];
InnerTrieNode(int level) {
super(level);
}
...
可以想象这个树完全展开还是非常大的,所以这是标准的空间换时间的算法实现,所以创建TrieTree的过程应该是递归的过程,直到到达最深的深度,此时应该创建的Leaf叶子节点,至此,树创建完毕,看代码实现:
private TrieNode buildTrie(BinaryComparable[] splits, int lower,
int upper, byte[] prefix, int maxDepth) {
final int depth = prefix.length;
if (depth >= maxDepth || lower == upper) {
//深度抵达最大的时候,应创建叶子节点了
return new LeafTrieNode(depth, splits, lower, upper);
}
InnerTrieNode result = new InnerTrieNode(depth);
byte[] trial = Arrays.copyOf(prefix, prefix.length + 1);
// append an extra byte on to the prefix
int currentBound = lower;
//每个父节点拥有着255个子节点
for(int ch = 0; ch < 255; ++ch) {
trial[depth] = (byte) (ch + 1);
lower = currentBound;
while (currentBound < upper) {
if (splits[currentBound].compareTo(trial, 0, trial.length) >= 0) {
break;
}
currentBound += 1;
}
trial[depth] = (byte) ch;
//result.child为首节点,递归创建子节点
result.child[0xFF & ch] = buildTrie(splits, lower, currentBound, trial,
maxDepth);
}
// pick up the rest
trial[depth] = 127;
result.child[255] = buildTrie(splits, currentBound, upper, trial,
maxDepth);
return result;
}
接下来的步骤就是关键的输入key,进而查找分区的过程了,非二进制比较类型的情况很简单,直接通过自己的插入的比较器,二分搜索即可知道结果。我们看看TrieTree实现的字符串类型的查找分区如何实现,从以上构建的过程,我们知道,他是一层层的逐层查找过程,比如你要找,aad这个字符,你当然首先得第一个节点找a,然后再往这个节点的第一个子节点就是字符a在查找,最后找到叶子节点,在叶子节点的查找,Hadoop还是用了二分查找,这时因为本身的划分数据不是很多,不需要排序直接查找即可。
下面看看代码的实现,首先是innner节点,但字符的查找:
....
/**
* 非叶子的节点的查询
*/
public int findPartition(BinaryComparable key) {
//获取当前的深度
int level = getLevel();
if (key.getLength() <= level) {
return child[0].findPartition(key);
}
//从key在此位置对应的字符child开始继续搜寻下一个,key.getBytes()[level]为第level位置的字符
return child[0xFF & key.getBytes()[level]].findPartition(key);
}
....
//在叶子节点,进行二分查找分区号
public int findPartition(BinaryComparable key) {
final int pos = Arrays.binarySearch(splitPoints, lower, upper, key) + 1;
return (pos < 0) ? -pos : pos;
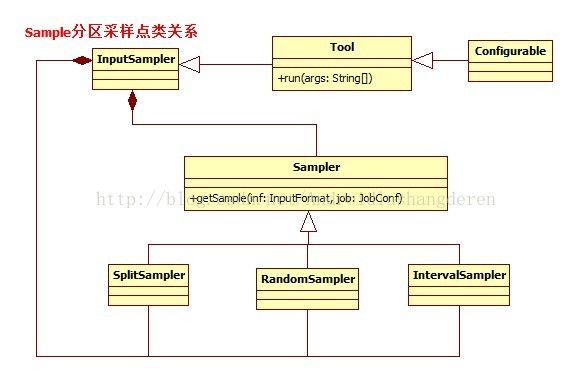
}SplitSampler:对前n个记录进行采样
RandomSampler:遍历所有数据,随机采样
IntervalSampler:固定间隔采样
小小的partition算法也蕴藏着很多奇妙的算法,MapReduce的代码真的是一份不可多得的好资料啊。