从已有CDH集群中配置CM HA
Hadoop的很多组件都是具有高可用性的,NameNode有HA,Zookeeper一般也是配置多个奇数个节点保证高可用,HBase Master可以配置多个做HA,DataNode、RegionServer等一般情况下都是配置成多个,保证数据的三副本。
大多数据情况下,我们在安装Cloudera集群的时候对于Cloudere Manager这块可能只会默认装在一个节点,且一般情况下会安装在根目录。由于根目录磁盘一般会配置成RAID1,所以即使根目录磁盘坏了一块,也不影响CM服务。
不过在某些特殊的情况下,如,CM所在的整个节点都坏掉了,那么CM的监控功能可能也因此不能用了,这时候就需要我们有CM HA的功能。关于CM HA的配置,Cloudera的官方文档中有介绍。这里我们也介绍一下如果在一个已有的CDH集群中配置CM HA。
前提:已有CDH Hadoop集群,其中HXnode01、HXnode02为两个管理节点,HXnode03-10为数据节点。HXnode01上安装有Cloudera Manager,因此可以通过HXnode01:7180来访问CM管理界面。
配置CM HA步骤如下,
-
确定备用CM节点及准备负载均衡节点
主CM节点为HXnode01
备用CM节点可以使用HXnode02
由于CM的HA机制是使用haproxy完成的,需要找一个负载均衡节点,如HXnode13 -
在备用节点HXnode02上安装Cloudera Manager Server
由于原有的集群CM Server是单节点只安装在HXnode01上,因此需要在HXnode02上安装CM Server
rpm -ivh cloudera-manager-server-5.16.2-1.cm5162.p0.7.el7.x86_64.rpm
rpm -qa | grep cloudera
输出如下,
cloudera-manager-server-5.16.2-1.cm5162.p0.7.el7.x86_64
cloudera-manager-agent-5.16.2-1.cm5162.p0.7.el7.x86_64
cloudera-manager-daemons-5.16.2-1.cm5162.p0.7.el7.x86_64
- 在负载均衡节点HXnode13安装haproxy并开启haproxy服务开机自启动
yum install -y haproxy
chkconfig haproxy on
- 在负载均衡节点HXnode13配置haproxy
修改/etc/haproxy/haproxy.cfg文件并添加以下配置保存
listen cmf :7180
mode tcp
option tcplog
server cmfhttp1 HXnode01:7180 check
server cmfhttp2 HXnode02:7180 check
listen cmfavro :7182
mode tcp
option tcplog
server cmfavro1 HXnode01:7182 check
server cmfavro2 HXnode02:7182 check
#ssl pass-through, without termination
listen cmfhttps :7183
mode tcp
option tcplog
server cmfhttps1 HXnode01:7183 check
server cmfhttps2 HXnode02:7183 check
- 在负载均衡节点HXnode13重启haproxy使上述配置修改生效
systemctl restart haproxy
systemctl status haproxy
- 在负载均衡节点HXnode13设置NFS并启动服务
yum install nfs-utils
chkconfig nfs on
systemctl start rpcbind
systemctl start nfs
- 在负载均衡节点HXnode13创建NFS文件夹并标记挂载
mkdir -p /media/cloudera-scm-server
编辑/etc/exports文件并添加以下内容保存
/media/cloudera-scm-server HXnode01(rw,sync,no_root_squash,no_subtree_check)
/media/cloudera-scm-server HXnode02(rw,sync,no_root_squash,no_subtree_check)
- 在负载均衡节点HXnode13导出挂载
exportfs -a
- 在主CM节点HXnode01和备CM节点HXnode02设置文件系统挂载
(以下命令需要在HXnode01和HXnode02都执行)
systemctl stop cloudera-scm-server
yum install nfs-utils
systemctl restart rpcbind
- 将主CM节点HXnode01和备CM节点HXnode02上的/var/lib/cloudera-scm-server/*文件拷贝到HXnode13 服务器节点
(以下命令需要在HXnode01和HXnode02都执行)
scp -r /var/lib/cloudera-scm-server/* hxnode13:/media/cloudera-scm-server
- 在主CM节点HXnode01和备CM节点HXnode02上配置/var/lib/cloudera-scm-server 文件夹
(以下命令需要在HXnode01和HXnode02都执行)
mv /var/lib/cloudera-scm-server /var/lib/cloudera-scm-server.bak
mkdir -p /var/lib/cloudera-scm-server
- 在主CM节点HXnode01和备CM节点HXnode02上挂载共享文件夹并设置权限
(以下命令需要在HXnode01和HXnode02都执行,其中10.19.41.29为HXnode13的IP)
mount -t nfs 10.19.41.29:/media/cloudera-scm-server /var/lib/cloudera-scm-server
chown -R cloudera-scm:cloudera-scm /var/lib/cloudera-scm-server
chmod 770 /var/lib/cloudera-scm-server
- 在主CM节点HXnode01和备CM节点HXnode02上编辑/etc/fstab 文件并添加以下行来设置 fstab以便在重新启动时持久化挂载
(以下命令需要在HXnode01和HXnode02都执行,其中10.19.41.29为HXnode13的IP)
编辑/etc/fstab添加以下配置
10.19.41.29:/media/cloudera-scm-server /var/lib/cloudera-scm-server nfs auto,noatime,nolock,intr,tcp,actimeo=1800 0 0
- 在备CM节点HXnode02节点上配置备Cloudera Manager Server服务
(1)为备CM节点HXnode02节点 上的 CM 服务设置元数据库
将 HXnode01 节点上的/etc/cloudera-scm-server/db.properties 文件拷贝到 HXnode02 节点,并修改权限
scp HXnode01:/etc/cloudera-scm-server/db.properties /etc/cloudera-scm-server/db.properties
chown cloudera-scm:cloudera-scm /etc/cloudera-scm-server/db.properties
chmod 600 /etc/cloudera-scm-server/db.properties
(2)关闭备CM节点HXnode02节点上的CM自启动
chkconfig cloudera-scm-server off
- 启动主CM节点HXnode01上的CM Server服务并打开7180检查
service cloudera-scm-server start
打开HXnode01:7180验证页面是否正常访问
- 停止主CM节点HXnode01上的CM Server服务并打开备CM节点HXnode02上的CM Server服务并打开7180检查
HXnode01执行
service cloudera-scm-server stop
HXnode02执行
service cloudera-scm-server start
打开HXnode13:7180页面访问
(注:这里要打开HXnode13:7180而非HXnode02:7180)
备注:
如果HXnode02上的CM Server服务无法启动,要先查出 supervisor的进程,并将其 kill 掉,然后再重启 cloudera-scm-server
[root@HXnode02 cloudera-scm-server]# ps -ef | grep supervisor
root 3342 1 0 Apr06 ? 01:18:13 /usr/lib64/cmf/agent/build/env/bin/python /usr/lib64/cmf/agent/build/env/bin/supervisord
root 430975 295188 0 22:15 pts/0 00:00:00 grep --color=auto supervisor
[root@HXnode02 cloudera-scm-server]# kill -9 3342
此时打开的HXnode13:7180网页如下,
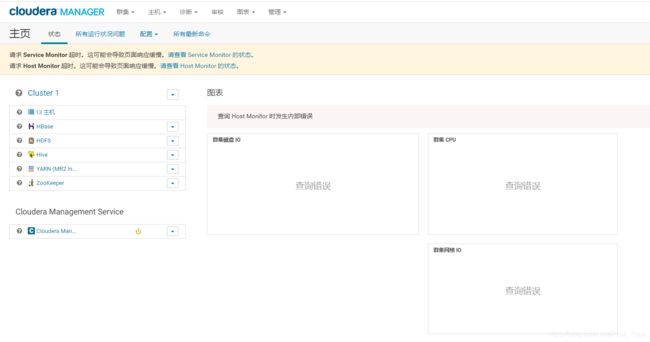
17. 更新所有节点的CM agent配置并重启所有Agent服务
通过以下7180网页可以看出,由于现在配置了CM HA,相关的CM Agent服务的配置地址要修改为HXnode13
编辑所有节点的/etc/cloudera-scm-agent/config.ini,修改server_host为
server_host = HXnode13
重启所有节点的CM Agent服务
service cloudera-scm-agent restart
现在网页显示如下,

至此,我们的CM HA就已经搭建完毕!