- Flume-HBase-Kafka
正在緩沖҉99%
kafkaFlumeHBase大数据
Flume-HBase-Kafka一、各自介绍1.Flume简介和特征2.HBase简介和特征3.Kafka简介和特征二、通过Flume读取日志文件写入到Kafka中在写入HBase各自作用一、各自介绍1.Flume简介和特征一、简介Flume是一个分布式、可靠、和高可用的海量日志聚合的系统,支持在系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据进行简单处理,并写到各种数据接受方
- 大数据环境(单机版) Flume传输数据到Kafka
凡许真
大数据flumekafka数据采集
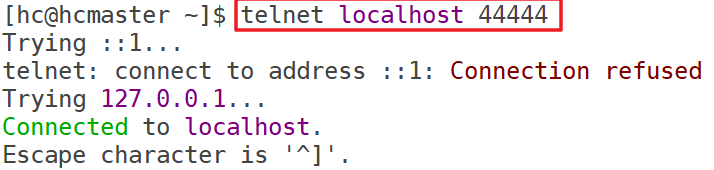
文章目录前言一、准备二、安装三、配置环境变量四、修改配置4.1、kafka配置4.2、Flume配置五、启动程序5.1、启动zk5.2、启动kafka5.3、启动flume六、测试6.1、启动一个kafka终端,用来消费消息6.2、写入日志其他前言flume监控指定目录,传输数据到kafka一、准备flume-1.10.1kafka_2.11-2.4.1zookeeper-3.4.13二、安装使用
- Kafka系列之:记录一次源头数据库刷数据,造成数据丢失的原因
快乐骑行^_^
KafkaKafka系列记录一次源头数据库刷数据造成数据丢失的原因
Kafka系列之:记录一次源头数据库刷数据,造成数据丢失的原因一、背景二、查看topic日志信息三、结论四、解决方法一、背景源头数据库在很短的时间内刷了大量的数据,部分数据在hdfs丢失了理论上debezium数据采集不会丢失,就需要排查数据链路某个节点是否有数据丢失。数据链路是:debezium——kafka——flume——hdfs根据经验定位数据在kafka侧丢失,下一面进一步确认是否数据在
- 强大的ETL利器—DataFlow3.0
lixiang2114
数据分析etlflumesqoop数据库数据仓库
产品开发背景DataFlow是基于应用数据流程的一套分布式ETL系统服务组件,其前身是LogCollector2.0日志系统框架,自LogCollector3.0版本开始正式更名为DataFlow3.0。目前常用的ETL工具Flume、LogStash、Kettle、Sqoop等也可以完成数据的采集、传输、转换和存储;但这些工具都不具备事务一致性。比如Flume工具仅能应用到通信质量无障碍的局域网
- 大数据-257 离线数仓 - 数据质量监控 监控方法 Griffin架构
m0_74823705
面试学习路线阿里巴巴大数据架构
点一下关注吧!!!非常感谢!!持续更新!!!Java篇开始了!目前开始更新MyBatis,一起深入浅出!目前已经更新到了:Hadoop(已更完)HDFS(已更完)MapReduce(已更完)Hive(已更完)Flume(已更完)Sqoop(已更完)Zookeeper(已更完)HBase(已更完)Redis(已更完)Kafka(已更完)Spark(已更完)Flink(已更完)ClickHouse(已
- 数据仓库与数据挖掘记录 三
匆匆整棹还
数据挖掘
数据仓库的数据存储和处理数据的ETL过程数据ETL是用来实现异构数据源的数据集成,即完成数据的抓取/抽取、清洗、转换.加载与索引等数据调和工作,如图2.2所示。1)数据提取(Extract)从多个数据源中获取原始数据(如数据库、日志文件、API、云存储等)。数据源可能是结构化(如MySQL)、半结构化(如JSON)、非结构化(如文本)。关键技术:SQL查询、Web爬虫、日志采集工具(如Flume)
- 【大数据技术】搭建完全分布式高可用大数据集群(Flume)
Want595
Python大数据采集与分析大数据分布式flume
搭建完全分布式高可用大数据集群(Flume)apache-flume-1.11.0-bin.tar.gz注:请在阅读本篇文章前,将以上资源下载下来。写在前面本文主要介绍搭建完全分布式高可用集群Flume的详细步骤。注意:统一约定将软件安装包存放于虚拟机的/software目录下,软件安装至/opt目录下。安装Flume用finalshell将压缩包上传到虚拟机master的/software目录下
- 计算机毕业设计hadoop+spark+hive新能源汽车数据分析可视化大屏 汽车推荐系统 新能源汽车推荐系统 汽车爬虫 汽车大数据 机器学习 大数据毕业设计 深度学习 知识图谱 人工智能
qq+593186283
hadoop大数据人工智能
(1)设计目的本次设计一个基于Hive的新能源汽车数据仓管理系统。企业管理员登录系统后可以在汽车保养时,根据这些汽车内置传感器传回的数据分析其故障原因,以便维修人员更加及时准确处理相关的故障问题。或者对这些数据分析之后向车主进行预警提示车主注意保养汽车,以提高汽车行驶的安全系数。(2)设计要求利用Flume进行分布式的日志数据采集,Kafka实现高吞吐量的数据传输,DateX进行数据清洗、转换和整
- python消费kafka数据nginx日志实时_基于nginx+flume+kafka+mongodb实现埋点数据采集
weixin_39534208
名词解释埋点其实就是用于记录用户在页面的一些操作行为。例如,用户访问页面(PV,PageViews)、访问页面用户数量(UV,UserViews)、页面停留、按钮点击、文件下载等,这些都属于用户的操作行为。开发背景我司之前在处理埋点数据采集时,模式很简单,当用户操作页面控件时,前端监听到操作事件,并根据上下文环境,将事件相关的数据通过接口调用发送至埋点数据采集服务(简称ets服务),ets服务对数
- 大数据-267 实时数仓 - ODS Lambda架构 Kappa架构 核心思想
m0_74823336
面试学习路线阿里巴巴大数据架构
点一下关注吧!!!非常感谢!!持续更新!!!Java篇开始了!MyBatis更新完毕目前开始更新Spring,一起深入浅出!目前已经更新到了:Hadoop(已更完)HDFS(已更完)MapReduce(已更完)Hive(已更完)Flume(已更完)Sqoop(已更完)Zookeeper(已更完)HBase(已更完)Redis(已更完)Kafka(已更完)Spark(已更完)Flink(已更完)Cl
- nginx+flume网络流量日志实时数据分析实战_日志数据分析(1)
2401_84182578
程序员nginxflume数据分析
得到visits模型hadoopjar/export/data/mapreduce/web_log.jarcn.itcast.bigdata.weblog.clickstream.ClickStreamVisit网络日志数据分析-数据加载对于日志数据的分析,Hive也分为三层:ods层、dw层、app层创建数据库createdatabaseifnotexistsweb_log_ods;create
- 【大数据入门核心技术-Flume】(二)Flume安装部署
forest_long
大数据技术入门到21天通关bigdatahadoop大数据hbaseflume
目录一、准备工作1、基本Hadoop环境安装2、下载安装包二、安装1、解压2、修改环境变量3、修改并配置flume-env.sh文件4、验证是否安装成功一、准备工作1、基本Hadoop环境安装参考Hadoop安装【大数据入门核心技术-Hadoop】(五)Hadoop3.2.1非高可用集群搭建【大数据入门核心技术-Hadoop】(六)Hadoop3.2.1高可用集群搭建2、下载安装包官方网址:
- java.io.FileNotFoundException: /tmp/log/flume-ng/flume.log (Permission denied)
海洋 之心
Flume问题解决Hadoop问题解决javaflume开发语言zookeeper大数据
文章目录问题描述:原因分析:解决方案:问题描述:使用Flume将本地文件监控上传到HDFS上时出现log4j:ERRORsetFile(null,true)callfailed.java.io.FileNotFoundException:/tmp/log/flume-ng/flume.log(Permissiondenied)log4j:ERRORsetFile(null,true)callfai
- flume系列之:消费Kafka集群Topic报错java.io.IOException: Can‘t resolve address: data03:9092
快乐骑行^_^
flumeflume系列消费Kafka集群TopicOExceptionresolveaddress
flume系列之:消费Kafka集群Topic报错java.io.IOException:Can'tresolveaddress:data03:9092Causedby:java.nio.channels.UnresolvedAddressException一、flume消费Kafka集群Topic报错二、报错原因三、解决方法一、flume消费Kafka集群Topic报错21Sep202214:5
- 基于Spark的实时计算服务的流程架构
小小搬运工40
spark大数据
基于Spark的实时计算服务的流程架构通常涉及多个组件和步骤,从数据采集到数据处理,再到结果输出和监控。以下是一个典型的基于Spark的实时计算服务的流程架构:1.数据源数据源是实时计算服务的起点,常见的数据源包括:消息队列:如Kafka、RabbitMQ、AmazonKinesis等。日志系统:如Flume、Logstash等。传感器数据:物联网设备产生的数据流。数据库变更数据捕获(CDC):如
- 大数据开发的底层逻辑是什么?
瑰茵
大数据
大数据开发的底层逻辑主要围绕数据的生命周期进行,包括数据的采集、存储、处理、分析和可视化等环节。以下是大数据开发的一些关键底层逻辑:数据采集:目的:从不同的数据源(如日志文件、数据库、传感器等)收集数据。方法:使用数据采集工具(如ApacheFlume、ApacheKafka、ApacheSqoop)来捕获和传输数据。数据存储:目的:将收集到的数据存储在可靠且可扩展的存储系统中。方法:使用分布式文
- flume+ Elasticsearch +kibana环境搭建及讲解
pincharensheng
大数据flumekibanaelasticsearch分布式
1、软件介绍1.1、flume1.1.1、flume介绍1)flume概念1、flume是一个分布式的日志收集系统,具有高可靠、高可用、事务管理、失败重启等功能。数据处理速度快,完全可以用于生产环境;2、flume的核心是agent。agent是一个java进程,运行在日志收集端,通过agent接收日志,然后暂存起来,再发送到目的地;3、agent里面包含3个核心组件:source、channel
- Hive数据仓库中的数据导出到MySQL的数据表不成功
sin2201
出错问题数据仓库hivemysql
可能的原因:(1)没有下载flume和sqoop(2)权限问题:因为MySQL数据库拒绝了root用户从hadoop3主机的连接请求,root用户没有从hadoop3主机进行连接的权限解决:通过MySQL的授权命令来授予权限mysql>GRANTALLPRIVILEGESONsqoop_weblog.*TO'root'@'hadoop3'IDENTIFIEDBY'2020';QueryOK,0ro
- python消费kafka数据nginx日志实时_Openresty+Lua+Kafka实现日志实时采集
weixin_39997311
简介在很多数据采集场景下,Flume作为一个高性能采集日志的工具,相信大家都知道它。许多人想起Flume这个组件能联想到的大多数都是Flume跟Kafka相结合进行日志的采集,这种方案有很多他的优点,比如高性能、高吞吐、数据可靠性等。但是我们如果要求对日志进行实时的采集,这显然不是一个好的解决方案。原因如下:就目前来说,Flume能支持实时监控一个目录的数据文件,一旦对某个目录的文件采集完成,就会
- openresty+lua实现实时写kafka
sky@梦幻未来
大数据openrestynginxopenrestylua
一.背景在使用openresty+lua+nginx+flume,通过定时切分日志发送kafka的方式无法满足实时性的情况下,小编开始研究openresty+lua+nginx+kafka实时写kafka,从而达到数据实时性,和高性能保证。二.实现1.openresty安装nginx,以及lua的使用请看博主上一篇博客https://blog.csdn.net/qq_29497387/articl
- SeaTunnel 与 DataX 、Sqoop、Flume、Flink CDC 对比
不二人生
#数据集成工具SeaTunnel
文章目录SeaTunnel与DataX、Sqoop、Flume、FlinkCDC对比同类产品横向对比2.1、高可用、健壮的容错机制2.2、部署难度和运行模式2.3、支持的数据源丰富度2.4、内存资源占用2.5、数据库连接占用2.6、自动建表2.7、整库同步2.8、断点续传2.9、多引擎支持2.10、数据转换算子2.11、性能2.12、离线同步2.13、增量同步&实时同步2.14、CDC同步2.15
- flume系列之:flume落cos
快乐骑行^_^
日常分享专栏flume系列
flume系列之:flume落cos一、参考文章二、安装cosjar包三、添加hadoop-cos的相关配置四、flume环境添加hadoop类路径五、使用cos路径六、启动/重启flume一、参考文章Kafka数据通过Flume存储到HDFS或COSflumetocos使用指南二、安装cosjar包将对应hadoop版本的hadoop-cos的jar包(hadoop-cos-{hadoop.ve
- Flume 简介01 作用 核心概念 事务机制 安装 配置入门实战
湖中屋
Flumeflume
Flume1.业务系统为什么会产生用户行为日志,怎么产生的用户行文日志:每一次访问的行为(访问、搜索)产生的日志记录用户行为日志的目的:1.商家会精准的给你呈现符合你的个人界面2.商家会给你个人添加用户标签,更加精准的分析埋点等2.flume用来做什么的(采集传输数据的,分布式的,可靠的)ApacheFlume是一个从可以收集例如日志,事件等数据资源,并将这些数量庞大的数据从各项数据资源中集中起来
- 大数据-257 离线数仓 - 数据质量监控 监控方法 Griffin架构
武子康
大数据离线数仓大数据数据仓库java后端hadoophive
点一下关注吧!!!非常感谢!!持续更新!!!Java篇开始了!目前开始更新MyBatis,一起深入浅出!目前已经更新到了:Hadoop(已更完)HDFS(已更完)MapReduce(已更完)Hive(已更完)Flume(已更完)Sqoop(已更完)Zookeeper(已更完)HBase(已更完)Redis(已更完)Kafka(已更完)Spark(已更完)Flink(已更完)ClickHouse(已
- kafka直接对接nginx
Lu_Xiao_Yue
nginxkafka
很多时候我们要对nginx产生的日志进行分析都是通过flume监控nginx产生的日志,通过flume把日志文件发送该kafka,flume作为生产者,但是这种方式的缺点就是可能效率会比较慢,除此之外还可以使用kafka直接对接nginx,nginx作为生产者,把log日志直接对接到kafka的某些分区中,这种方法的效率比较高,但是缺点就是可能会出现数据丢失,可以通过把nginx的日志进行一份给k
- 大数据新视界 --大数据大厂之大数据实战指南:Apache Flume 数据采集的配置与优化秘籍
青云交
大数据新视界数据库ApacheFlume数据采集安装部署配置优化高级功能大数据工具集成
亲爱的朋友们,热烈欢迎你们来到青云交的博客!能与你们在此邂逅,我满心欢喜,深感无比荣幸。在这个瞬息万变的时代,我们每个人都在苦苦追寻一处能让心灵安然栖息的港湾。而我的博客,正是这样一个温暖美好的所在。在这里,你们不仅能够收获既富有趣味又极为实用的内容知识,还可以毫无拘束地畅所欲言,尽情分享自己独特的见解。我真诚地期待着你们的到来,愿我们能在这片小小的天地里共同成长,共同进步。本博客的精华专栏:大数
- nosql数据库技术与应用知识点
皆过客,揽星河
NoSQLnosql数据库大数据数据分析数据结构非关系型数据库
Nosql知识回顾大数据处理流程数据采集(flume、爬虫、传感器)数据存储(本门课程NoSQL所处的阶段)Hdfs、MongoDB、HBase等数据清洗(入仓)Hive等数据处理、分析(Spark、Flink等)数据可视化数据挖掘、机器学习应用(Python、SparkMLlib等)大数据时代存储的挑战(三高)高并发(同一时间很多人访问)高扩展(要求随时根据需求扩展存储)高效率(要求读写速度快)
- Flume:大规模日志收集与数据传输的利器
傲雪凌霜,松柏长青
后端大数据flume大数据
Flume:大规模日志收集与数据传输的利器在大数据时代,随着各类应用的不断增长,产生了海量的日志和数据。这些数据不仅对业务的健康监控至关重要,还可以通过深入分析,帮助企业做出更好的决策。那么,如何高效地收集、传输和存储这些海量数据,成为了一项重要的挑战。今天我们将深入探讨ApacheFlume,它是如何帮助我们应对这些挑战的。一、Flume概述ApacheFlume是一个分布式、可靠、可扩展的日志
- 解决flume在抽取不断产生的日志文件时,hdfs上出现很多小文件的问题
lzhlizihang
flumehdfs大数据
问题在使用flume时,需要编写conf文件,然后执行,明明sinks已经指定了roll的三个参数:a1.sinks.k1.hdfs.rollInterval=0(根据写入时间来切割)a1.sinks.k1.hdfs.rollSize=0(根据写入的文件大小来切割)a1.sinks.k1.hdfs.rollCount=0(根据Event数量来切割)其中0代表不根据其属性来切割文件但是hdfs上还会
- pyspark kafka mysql_数据平台实践①——Flume+Kafka+SparkStreaming(pyspark)
weixin_39793638
pysparkkafkamysql
蜻蜓点水Flume——数据采集如果说,爬虫是采集外部数据的常用手段的话,那么,Flume就是采集内部数据的常用手段之一(logstash也是这方面的佼佼者)。下面介绍一下Flume的基本构造。Agent:包含Source、Channel和Sink的主体,它是这3个组件的载体,是组成Flume的数据节点。Event:Flume数据传输的基本单元。Source:用来接收Event,并将Event批量传
- html页面js获取参数值
0624chenhong
html
1.js获取参数值js
function GetQueryString(name)
{
var reg = new RegExp("(^|&)"+ name +"=([^&]*)(&|$)");
var r = windo
- MongoDB 在多线程高并发下的问题
BigCat2013
mongodbDB高并发重复数据
最近项目用到 MongoDB , 主要是一些读取数据及改状态位的操作. 因为是结合了最近流行的 Storm进行大数据的分析处理,并将分析结果插入Vertica数据库,所以在多线程高并发的情境下, 会发现 Vertica 数据库中有部分重复的数据. 这到底是什么原因导致的呢?笔者开始也是一筹莫 展,重复去看 MongoDB 的 API , 终于有了新发现 :
com.mongodb.DB 这个类有
- c++ 用类模版实现链表(c++语言程序设计第四版示例代码)
CrazyMizzz
数据结构C++
#include<iostream>
#include<cassert>
using namespace std;
template<class T>
class Node
{
private:
Node<T> * next;
public:
T data;
- 最近情况
麦田的设计者
感慨考试生活
在五月黄梅天的岁月里,一年两次的软考又要开始了。到目前为止,我已经考了多达三次的软考,最后的结果就是通过了初级考试(程序员)。人啊,就是不满足,考了初级就希望考中级,于是,这学期我就报考了中级,明天就要考试。感觉机会不大,期待奇迹发生吧。这个学期忙于练车,写项目,反正最后是一团糟。后天还要考试科目二。这个星期真的是很艰难的一周,希望能快点度过。
- linux系统中用pkill踢出在线登录用户
被触发
linux
由于linux服务器允许多用户登录,公司很多人知道密码,工作造成一定的障碍所以需要有时踢出指定的用户
1/#who 查出当前有那些终端登录(用 w 命令更详细)
# who
root pts/0 2010-10-28 09:36 (192
- 仿QQ聊天第二版
肆无忌惮_
qq
在第一版之上的改进内容:
第一版链接:
http://479001499.iteye.com/admin/blogs/2100893
用map存起来号码对应的聊天窗口对象,解决私聊的时候所有消息发到一个窗口的问题.
增加ViewInfo类,这个是信息预览的窗口,如果是自己的信息,则可以进行编辑.
信息修改后上传至服务器再告诉所有用户,自己的窗口
- java读取配置文件
知了ing
1,java读取.properties配置文件
InputStream in;
try {
in = test.class.getClassLoader().getResourceAsStream("config/ipnetOracle.properties");//配置文件的路径
Properties p = new Properties()
- __attribute__ 你知多少?
矮蛋蛋
C++gcc
原文地址:
http://www.cnblogs.com/astwish/p/3460618.html
GNU C 的一大特色就是__attribute__ 机制。__attribute__ 可以设置函数属性(Function Attribute )、变量属性(Variable Attribute )和类型属性(Type Attribute )。
__attribute__ 书写特征是:
- jsoup使用笔记
alleni123
java爬虫JSoup
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.7.3</version>
</dependency>
2014/08/28
今天遇到这种形式,
- JAVA中的集合 Collectio 和Map的简单使用及方法
百合不是茶
listmapset
List ,set ,map的使用方法和区别
java容器类类库的用途是保存对象,并将其分为两个概念:
Collection集合:一个独立的序列,这些序列都服从一条或多条规则;List必须按顺序保存元素 ,set不能重复元素;Queue按照排队规则来确定对象产生的顺序(通常与他们被插入的
- 杀LINUX的JOB进程
bijian1013
linuxunix
今天发现数据库一个JOB一直在执行,都执行了好几个小时还在执行,所以想办法给删除掉
系统环境:
ORACLE 10G
Linux操作系统
操作步骤如下:
第一步.查询出来那个job在运行,找个对应的SID字段
select * from dba_jobs_running--找到job对应的sid
&n
- Spring AOP详解
bijian1013
javaspringAOP
最近项目中遇到了以下几点需求,仔细思考之后,觉得采用AOP来解决。一方面是为了以更加灵活的方式来解决问题,另一方面是借此机会深入学习Spring AOP相关的内容。例如,以下需求不用AOP肯定也能解决,至于是否牵强附会,仁者见仁智者见智。
1.对部分函数的调用进行日志记录,用于观察特定问题在运行过程中的函数调用
- [Gson六]Gson类型适配器(TypeAdapter)
bit1129
Adapter
TypeAdapter的使用动机
Gson在序列化和反序列化时,默认情况下,是按照POJO类的字段属性名和JSON串键进行一一映射匹配,然后把JSON串的键对应的值转换成POJO相同字段对应的值,反之亦然,在这个过程中有一个JSON串Key对应的Value和对象之间如何转换(序列化/反序列化)的问题。
以Date为例,在序列化和反序列化时,Gson默认使用java.
- 【spark八十七】给定Driver Program, 如何判断哪些代码在Driver运行,哪些代码在Worker上执行
bit1129
driver
Driver Program是用户编写的提交给Spark集群执行的application,它包含两部分
作为驱动: Driver与Master、Worker协作完成application进程的启动、DAG划分、计算任务封装、计算任务分发到各个计算节点(Worker)、计算资源的分配等。
计算逻辑本身,当计算任务在Worker执行时,执行计算逻辑完成application的计算任务
- nginx 经验总结
ronin47
nginx 总结
深感nginx的强大,只学了皮毛,把学下的记录。
获取Header 信息,一般是以$http_XX(XX是小写)
获取body,通过接口,再展开,根据K取V
获取uri,以$arg_XX
&n
- 轩辕互动-1.求三个整数中第二大的数2.整型数组的平衡点
bylijinnan
数组
import java.util.ArrayList;
import java.util.Arrays;
import java.util.List;
public class ExoWeb {
public static void main(String[] args) {
ExoWeb ew=new ExoWeb();
System.out.pri
- Netty源码学习-Java-NIO-Reactor
bylijinnan
java多线程netty
Netty里面采用了NIO-based Reactor Pattern
了解这个模式对学习Netty非常有帮助
参考以下两篇文章:
http://jeewanthad.blogspot.com/2013/02/reactor-pattern-explained-part-1.html
http://gee.cs.oswego.edu/dl/cpjslides/nio.pdf
- AOP通俗理解
cngolon
springAOP
1.我所知道的aop 初看aop,上来就是一大堆术语,而且还有个拉风的名字,面向切面编程,都说是OOP的一种有益补充等等。一下子让你不知所措,心想着:怪不得很多人都和 我说aop多难多难。当我看进去以后,我才发现:它就是一些java基础上的朴实无华的应用,包括ioc,包括许许多多这样的名词,都是万变不离其宗而 已。 2.为什么用aop&nb
- cursor variable 实例
ctrain
variable
create or replace procedure proc_test01
as
type emp_row is record(
empno emp.empno%type,
ename emp.ename%type,
job emp.job%type,
mgr emp.mgr%type,
hiberdate emp.hiredate%type,
sal emp.sal%t
- shell报bash: service: command not found解决方法
daizj
linuxshellservicejps
今天在执行一个脚本时,本来是想在脚本中启动hdfs和hive等程序,可以在执行到service hive-server start等启动服务的命令时会报错,最终解决方法记录一下:
脚本报错如下:
./olap_quick_intall.sh: line 57: service: command not found
./olap_quick_intall.sh: line 59
- 40个迹象表明你还是PHP菜鸟
dcj3sjt126com
设计模式PHP正则表达式oop
你是PHP菜鸟,如果你:1. 不会利用如phpDoc 这样的工具来恰当地注释你的代码2. 对优秀的集成开发环境如Zend Studio 或Eclipse PDT 视而不见3. 从未用过任何形式的版本控制系统,如Subclipse4. 不采用某种编码与命名标准 ,以及通用约定,不能在项目开发周期里贯彻落实5. 不使用统一开发方式6. 不转换(或)也不验证某些输入或SQL查询串(译注:参考PHP相关函
- Android逐帧动画的实现
dcj3sjt126com
android
一、代码实现:
private ImageView iv;
private AnimationDrawable ad;
@Override
protected void onCreate(Bundle savedInstanceState)
{
super.onCreate(savedInstanceState);
setContentView(R.layout
- java远程调用linux的命令或者脚本
eksliang
linuxganymed-ssh2
转载请出自出处:
http://eksliang.iteye.com/blog/2105862
Java通过SSH2协议执行远程Shell脚本(ganymed-ssh2-build210.jar)
使用步骤如下:
1.导包
官网下载:
http://www.ganymed.ethz.ch/ssh2/
ma
- adb端口被占用问题
gqdy365
adb
最近重新安装的电脑,配置了新环境,老是出现:
adb server is out of date. killing...
ADB server didn't ACK
* failed to start daemon *
百度了一下,说是端口被占用,我开个eclipse,然后打开cmd,就提示这个,很烦人。
一个比较彻底的解决办法就是修改
- ASP.NET使用FileUpload上传文件
hvt
.netC#hovertreeasp.netwebform
前台代码:
<asp:FileUpload ID="fuKeleyi" runat="server" />
<asp:Button ID="BtnUp" runat="server" onclick="BtnUp_Click" Text="上 传" />
- 代码之谜(四)- 浮点数(从惊讶到思考)
justjavac
浮点数精度代码之谜IEEE
在『代码之谜』系列的前几篇文章中,很多次出现了浮点数。 浮点数在很多编程语言中被称为简单数据类型,其实,浮点数比起那些复杂数据类型(比如字符串)来说, 一点都不简单。
单单是说明 IEEE浮点数 就可以写一本书了,我将用几篇博文来简单的说说我所理解的浮点数,算是抛砖引玉吧。 一次面试
记得多年前我招聘 Java 程序员时的一次关于浮点数、二分法、编码的面试, 多年以后,他已经称为了一名很出色的
- 数据结构随记_1
lx.asymmetric
数据结构笔记
第一章
1.数据结构包括数据的
逻辑结构、数据的物理/存储结构和数据的逻辑关系这三个方面的内容。 2.数据的存储结构可用四种基本的存储方法表示,它们分别是
顺序存储、链式存储 、索引存储 和 散列存储。 3.数据运算最常用的有五种,分别是
查找/检索、排序、插入、删除、修改。 4.算法主要有以下五个特性:
输入、输出、可行性、确定性和有穷性。 5.算法分析的
- linux的会话和进程组
网络接口
linux
会话: 一个或多个进程组。起于用户登录,终止于用户退出。此期间所有进程都属于这个会话期。会话首进程:调用setsid创建会话的进程1.规定组长进程不能调用setsid,因为调用setsid后,调用进程会成为新的进程组的组长进程.如何保证? 先调用fork,然后终止父进程,此时由于子进程的进程组ID为父进程的进程组ID,而子进程的ID是重新分配的,所以保证子进程不会是进程组长,从而子进程可以调用se
- 二维数组 元素的连续求解
1140566087
二维数组ACM
import java.util.HashMap;
public class Title {
public static void main(String[] args){
f();
}
// 二位数组的应用
//12、二维数组中,哪一行或哪一列的连续存放的0的个数最多,是几个0。注意,是“连续”。
public static void f(){
- 也谈什么时候Java比C++快
windshome
javaC++
刚打开iteye就看到这个标题“Java什么时候比C++快”,觉得很好笑。
你要比,就比同等水平的基础上的相比,笨蛋写得C代码和C++代码,去和高手写的Java代码比效率,有什么意义呢?
我是写密码算法的,深刻知道算法C和C++实现和Java实现之间的效率差,甚至也比对过C代码和汇编代码的效率差,计算机是个死的东西,再怎么优化,Java也就是和C