hive数据排序、和窗口函数
一、hive的四种排序
1. Order by 可以指定desc降序 asc升序
Order by会对输入做全局排序,因此只有一个Reducer(多个Reducer无法保证全局有序,即使设置了多个Reduce,程序依然会按照一个Reduce进行排序)。Order by全局排序,又一个缺点,就是只有一个Reducer,会导致数据规模较大是,消耗较长的计算时间。
案例演示:
-- 创建一个分数表
create table score(
stu_id int,
stu_name string,
stu_class string,
stu_score double
);
-- 插入数据
insert into score values
(1,'zhangsan','math',90),
(1,'zhangsan','English',82),
(1,'zhangsan','Chinese',92),
(2,'lisi','math',87),
(2,'lisi','English',95),
(2,'lisi','Chinese',85),
(3,'wangwu','math',94),
(3,'wangwu','English',93),
(3,'wangwu','Chinese',90);
-- 按成绩降序排列
select * from score order by stu_score desc;

2. sort by
sort by 不是全局排序,其在数据进行reducer前完成排序。使用sort by是可以指定执行的reduce的个数set mapred.reduce.tasks=n,对输出的数据再执行归并排序,即可得到全部结果。
案例演示:
#设置reducer个数为3
set mapred.reduce.tasks=3;
#用sort by 成绩 按降序排序
select * from score sort by stu_score desc;

3.Distribute by (最重要)
distribute by是控制在map端如何拆分数据给reduce端的。hive会根据distribute by 后面列,对应reducer的个数进行并发,默认是采用hash算法。sort by为每个reduce产生一个排序文件。一般情况下,distribute by经常和sort by配合使用。
案例演示:
# distribute by和sort by连用,按每个学生分类,并进行科目成绩排序
select * from score distribute by stu_id sort by stu_id asc,stu_score desc;

注:这个select语句是通过按stu_id分区,并且排序,排序的规则是用stu_id与分区数取余,余数小的排在前面,然后再进行区内对成绩排序。
4.Cluster by
cluster by除了具有distribute by的功能外还兼具sort by的功能。但是排序只能是倒叙排序,不能指定排序规则。
二、Hive聚合运算
GROUP BY用于分组
- Hive基本内置聚合函数与GROUP BY一起使用
- 如果没有指定GROUP BY子句,则默认聚合整个表
- 除聚合函数外,所选的其他列也必须包含在GROUP BY中
- GROUP BY支持使用CASE WHEN或表达式
HAVING:对GROUP BY聚合结果的条件过滤
- 可以避免在GROUP BY之后使用子查询
- HAVING之后可以使用表达式,但不建议使用,性能比较差
基础聚合
基础聚合函数
- max, min, count, sum, avg
- max(distinct col1)、avg(col2)等
- collect_set, collect_list:返回每个组列中的对象集/列表
注意事项
- 一般与GROUP BY一起使用(不一起使用就会都查询显示出来)
- 可应用于列或表达式
- 对NULL的count聚合为0
- select count(null) = 0
三、窗口函数
窗口函数介绍
窗口函数是一组特殊函数
- 扫描多个输入行来计算每个输出值,为每行数据生成一行结果
- 可以通过窗口函数来实现复杂的计算和聚合
窗口函数语法
- PARTITION BY类似于GROUP BY,未指定则按整个结果集
- 只有指定ORDER BY子句之后才能进行窗口定义
- 可同时使用多个窗口函数
- 过滤窗口函数计算结果必须在外面一层
窗口函数功能划分
排序,聚合,分析
窗口函数-排序
ROW_NUMBER()
对所有数值输出不同的序号,序号唯一连续
案例演示:
select *,ROW_NUMBER() OVER () AS row_num from score;
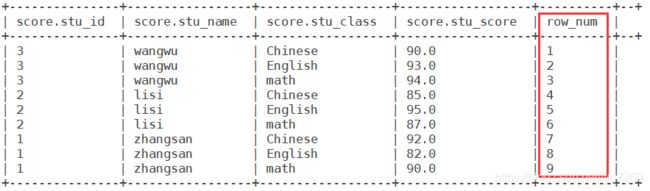
注:增加的一列不会出现重复的序号,唯一且连续。
RANK()
对相同数值,输出相同的序号,下一个序号跳过(1,1,3)
select *,RANK() OVER (PARTITION BY stu_id ORDER BY stu_score) AS rank from score;

注:因为数据中没有重复向,不太好观察,可以自行插入重复项进行观察。
DENSE_RANK()
对相同数值,输出相同的序号,下一个序号连续(1,1,2)
select *,DENSE_RANK() OVER (PARTITION BY stu_id ORDER BY stu_score) AS dense_rank from score;

NLITE(n)
将有序的数据集合平均分配到n个桶中, 将桶号分配给每一行,根据桶号,选取前或后 n分之几的数据。
select *,NTILE(3) OVER(PARTITION BY stu_id ORDER BY stu_score) AS ntile from score;
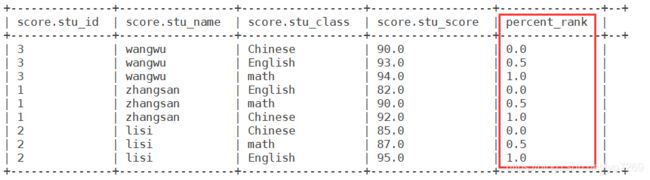
PERCENT_RANK()
(目前排名- 1)/(总行数- 1),值相对于一组值的百分比排名
select *,PERCENT_RANK() OVER(PARTITION BY stu_id ORDER BY stu_score) AS percent_rank from score;
窗口函数-聚合
- COUNT()
- 计数,可以和DISTINCT一起用(DISTINCT 去重)
- SUM():求和
- AVG():平均值
- MAX()/MIN(): 最大/小值
- 从Hive 2.1.0开始在OVER子句中支持聚合函数
窗口函数-分析
- CUME_DIST
小于等于当前值的行数/分组内总行数
select *,LEAD(stu_score,2) OVER(PARTITION BY stu_id) AS lead from score;
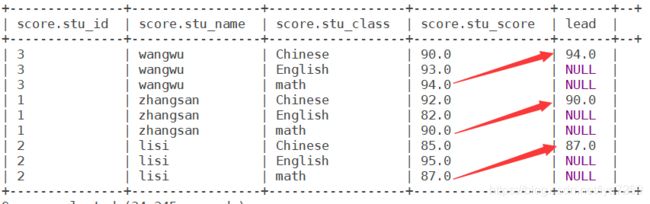
- LEAD/LAG(col,n)
某一列进行往前/后第n行值(n可选,默认为1)
select *,LAG(stu_score,2) OVER(PARTITION BY stu_id) AS lead from score;

- FIRST_VALUE
对该列到目前为止的首个值
select *,FIRST_VALUE(stu_score) OVER(PARTITION BY stu_id) AS first_value from score;

- LAST_VALUE
到目前行为止的最后一个值
select *,LAST_VALUE(stu_score) OVER(PARTITION BY stu_id) AS last_value from score;

窗口定义
-
窗口定义由[
]子句描述 - 用于进一步细分结果并应用分析函数
-
支持两类窗口定义
- 行类型窗口
- 范围类型窗口
-
RANK、NTILE、DENSE_RANK、CUME_DIST、PERCENT_RANK、LEAD、LAG和ROW_NUMBER函数不支持与窗口子句一起使用
-
行窗口:根据当前行之前或之后的行号确定的窗口
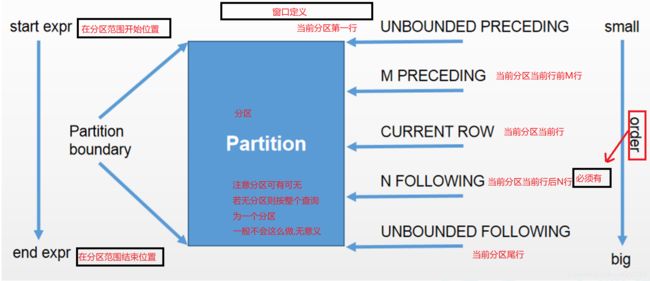
-
范围窗口是取分组内的值在指定范围区间内的行
该范围值/区间必须是数字或日期类型
目前只支持一个ORDER BY列。