Hadoop 2.x 原理详解
一、1.x出现的问题,2.x的解决方法
在Hadoop1.x结构中主要出现了两个问题:
1)单点故障。
2)内存受限,可扩展性低。
在Hadoop2.x结构解决上述两个的问题:
1)解决单点故障:通过HA高可用,主备Namenode切换解决。
2)解决内存受限问题:通过HDFS Federation联邦机制,水平扩展,多个Namenode分管一部分目录,共享所有的Datanode来解决。
二、为什么NFS会被QJM替代掉:
NFS的问题:①硬件设备要求高:必须是支持NAS的设备才能满足要求
②部署过程复杂:需要额外部署配置NFS挂载等,部署容易出错
③单点故障:没有彻底解决单点故障问题
QJM作为替代方案,设备不需要定制化,部署简单,解决了单点故障问题,元数据的同步也保证了高可用。
三、HA工作原理
接下来看一下2.x的架构图:
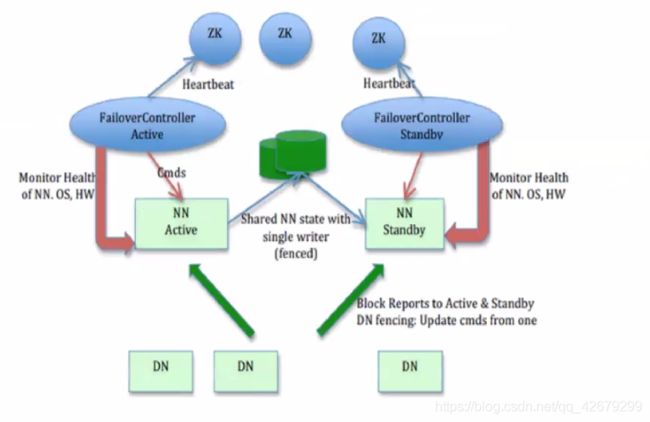
这里分为两部分来讲,一是ann与snn怎么保持数据一致,二是高可用中的主备切换。
(一)ActiveNamenode和StandbyNamenode保持内存状态一致;
① ActiveNamenode将editlog写入到本地和每一台journalNode(jn有一个简易的rpc接口,以供nn读写editlog到jn中,一般jn为奇数个)中,当journalNode中有N/2+1个写入成功时则认为该次写入操作成功。而StandbyNamenode定期检查journalNode上的editlog,然后从journalNode中获取editlog到本地。(StandbyNamenode有一个线程StandbyCheckpointer,当距离上次合并fsimage和editlog达到3600s或者editlog达到一定大小时,由StandbyNamenode对fsimage和editlog进行合并成新的fsimage,然后再传回给ActiveNamenode。)
② 在Namenode和Datanode启动的时候,会建立连接,Datanode上有每台Namenode的位置信息,Datanode定期向每台Namenode汇报心跳信息,包括Datanode的数据块信息,以及Datanode状态。如果Namenode长时间没收到心跳信息,则认为该Datanode处于“dead node”,会将该Datanode上的数据块副本拷贝到其他Datanode上。
基于上述两个条件,这个时候ActiveNamenode与StandbyNamenode保持了元数据同步,StandbyNamenode具备了转为active的条件
在上述ActiveNamenode写入过程中涉及到了隔离双写(在同一时间只能有一个Namenode对journalNode进行写入操作,如果出现两个,会争抢资源,出现脑裂的情况),和日志恢复(如果写入失败,在journalNode中会出现editlog长度不一致的情况,这时候需要进行日志恢复,来保证journalNode中的editlog长度一致)
(二)主备切换
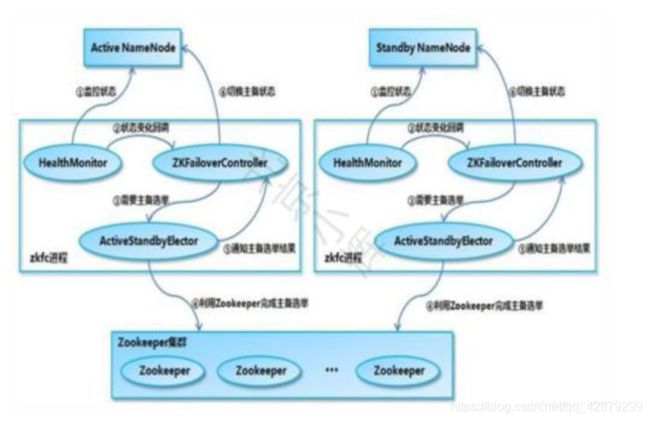 图来源于百度
图来源于百度
ZKFC内部共有三个组件:HealthMonitor,zkFailoverController,ActiveStandbyElector
处于Active的Namenode的ZKFC中ActiveStandbyElector会在zk上创建了一个/hadoopha/${dfs.nameservices}/ActiveStandbyElectorLock 临时节点作为锁。其他StandbyNamenode的ActiveStandbyElector会监测该节点。
ZKFC随着Namenode启动而启动,ZKFC启动后会在Zookeeper内注册该Namenode的信息
① HealthMonitor定期对本地的Namenode发送health-check命令,如果Namenode正确返回,则该Namenode正常,否则认为该Namenode失效。
②然后HealthMonitor触发回调函数通知zkFailoverController该Namenode状态发生了变化,然后zkFailoverController调用ActiveStandbyElector的API管理Zookeeper上的节点状态,删除临时节点,然后Zookeeper的watcher监听起作用
③Zookeeper上的排他锁释放后,其他处于健康状态的StandbyNamenode的ZKFC监测的临时节点消失,其他的StandbyNamenode就向Zookeeper争抢锁,然后Zookeeper进行投票主备选举,选举完成后,一个StandbyNamenode争抢到锁。
④拿到锁的StandbyNamenode在Zookeeper上创建/hadoopha/${dfs.nameservices}/ActiveStandbyElectorLock 临时节点作为排他锁,所有Namenode的ZKFC中的ActiveStandbyElector监控到Zookeeper中的节点变化,然后通过回调函数becomeActive 通知zkFailoverController选举结果,争抢到锁的StandbyNamenode在进行fence隔离后转为active状态,其他的Namenode依然是standby状态。就此主备转换完毕。(注意一定要进行fence隔离后才能转为active状态)
fence隔离的作用:解决脑裂的情况
ActiveNamenode在进行垃圾回收的时候,会在长时间内系统无法响应,这时HealthMonitor发送的心跳信息会无法正常返回,这时可能会导致临时节点掉线的情况,然后其他处于Standby状态的Namenode会转为Active状态,而当ActiveNamenode垃圾回收结束后,就会出现两台Active的Namenode,就会争抢资源,出现脑裂的情况。
四、Federation联邦机制 官方文档
Hadoop 1.x:

Hadoop 2.x:
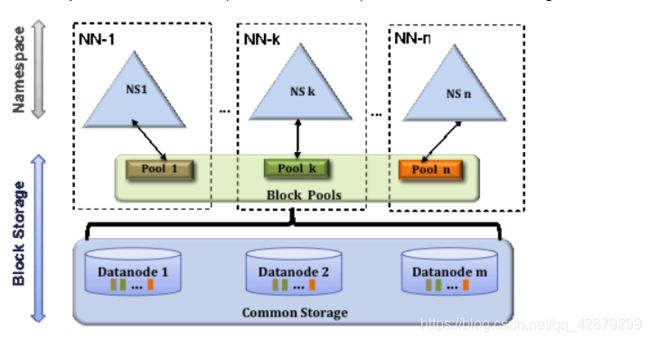
Federation横向扩展,解决了内存受限的问题。
这些Namenode之间是相互独立的,各自管理一部分目录,不需要与其他Namende进行协调,一个Namenode挂掉,并不会影响其他Namenode 的运行。
一个block pool由属于同一个namespace的数据块组成,每个datanode可能会存储集群中所有block pool 数据块。每个block pool内部自治,各自管理各自的block,不会与其他block pool交流。
namenode和block pool一起被称作namespace volume,它是管理的基本单位,当一个namespace被删除后,所有datanode上与其对应的block pool也会被删除。当集群升级时,每个namespace volume作为一个基本单元进行升级。