hbase集群搭建,hbase单个节点重启
1.1 hbase集群结构
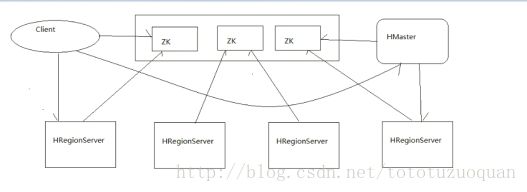
REGION:是HBASE中对表进行切割的单元
HMASTER: HBASE的主节点,负责整个集群的状态感知,负载分配、负责用户表的元数据管理
(可以配置多个用来实现HA)
为regionserver分配region,负责regionserver负载均衡
用户对表的增删改查
如果当前的regionserver宕机,会把region迁移
REGION-SERVER: HBASE中真正负责管理region的服务器,也就是负责为客户端进行表数据读写的服务器
维护master给它的region
当这个region过大的情况下,他还负责切分这个过大的region
(负责客户端的IO请求,去hdfs上进行读写数据)
ZOOKEEPER: 整个HBASE中的主从节点协调,主节点之间的选举,集群节点之间的
上下线感知……都是通过zookeeper来实现
Region 存储寻址入口
监控:REGION SERVER 上下线 把这个状态告诉master
存储hbase的schema(当前哪些表,表里有哪些列族)
1.2 hbase集群搭建
(1)上传hbase安装包(上传到hadoop1,hadoop2,hadoop3这三台服务器上),上传后的位置如下:
[root@hadoop1 software]# cd /home/tuzq/software
[root@hadoop1 software]# pwd
/home/tuzq/software
[root@hadoop1 software]# ls
hbase-1.3.1-bin.tar.gz(2)解压,并配置环境变量
[root@hadoop1 software]# tar -zxvf hbase-1.3.1-bin.tar.gz
[root@hadoop1 software]# cd hbase-1.3.1
[root@hadoop1 hbase-1.3.1]# ll
总用量 348
drwxr-xr-x. 4 root root 4096 4月 5 11:02 bin
-rw-r--r--. 1 root root 148959 4月 7 09:45 CHANGES.txt
drwxr-xr-x. 2 root root 4096 4月 5 11:02 conf
drwxr-xr-x. 12 root root 4096 4月 7 10:35 docs
drwxr-xr-x. 7 root root 4096 4月 7 10:26 hbase-webapps
-rw-r--r--. 1 root root 261 4月 7 10:37 LEGAL
drwxr-xr-x. 3 root root 4096 6月 22 11:25 lib
-rw-r--r--. 1 root root 130696 4月 7 10:37 LICENSE.txt
-rw-r--r--. 1 root root 43258 4月 7 10:37 NOTICE.txt
-rw-r--r--. 1 root root 1477 9月 21 2016 README.txt
[root@hadoop1 hbase-1.3.1]#
[root@hadoop1 hbase-1.3.1]# vim /etc/profile
#set hbase env
export HBASE_HOME=/home/tuzq/software/hbase-1.3.1
export PATH=$PATH:$HBASE_HOME/bin
[root@hadoop1 hbase-1.3.1]# source /etc/profile(3)配置hbase集群,要修改3个文件
注意: 要把hadoop的hdfs-site.xml和core-site.xml 放到hbase/conf下
[root@hadoop1 hadoop]# pwd
/home/tuzq/software/hadoop-2.8.0/etc/hadoop
[root@hadoop1 hadoop]# cp hdfs-site.xml /home/tuzq/software/hbase-1.3.1/conf
[root@hadoop1 hadoop]# cp core-site.xml /home/tuzq/software/hbase-1.3.1/conf
[root@hadoop1 hadoop]# cd $HBASE_HOME
[root@hadoop1 conf]# ll
总用量 52
-rw-r--r--. 1 root root 1376 6月 22 11:48 core-site.xml
-rw-r--r--. 1 root root 1811 9月 21 2016 hadoop-metrics2-hbase.properties
-rw-r--r--. 1 root root 4537 11月 7 2016 hbase-env.cmd
-rw-r--r--. 1 root root 7468 11月 7 2016 hbase-env.sh
-rw-r--r--. 1 root root 2257 9月 21 2016 hbase-policy.xml
-rw-r--r--. 1 root root 934 9月 21 2016 hbase-site.xml
-rw-r--r--. 1 root root 5203 6月 22 11:48 hdfs-site.xml
-rw-r--r--. 1 root root 4722 4月 5 11:02 log4j.properties
-rw-r--r--. 1 root root 10 12月 1 2015 regionservers
[root@hadoop1 conf]#(3.1)修改hbase-env.sh
export JAVA_HOME=/usr/local/jdk1.8.0_73
#告诉hbase使用外部的zk,HBASE不管理zookeeper集群
export HBASE_MANAGES_ZK=false
#配置hadoop的环境变量
export HADOOP_HOME=/home/tuzq/software/hadoop-2.8.0(3.2)修改 hbase-site.xml
<configuration>
<property>
<name>hbase.rootdirname>
<value>hdfs://mycluster/hbasevalue>
property>
<property>
<name>hbase.cluster.distributedname>
<value>truevalue>
property>
<property>
<name>hbase.zookeeper.quorumname>
<value>hadoop11,hadoop12,hadoop13value>
property>
configuration>(3.3)修改 regionservers
通过这个告诉slave有那些台(hadoop1(Master),hadoop2,hadoop3,hadoop4,hadoop5为slave)
[root@hadoop1 conf]# vim regionservers
hadoop2
hadoop3
hadoop4
hadoop5(3.3) 修改 backup-masters来指定备用的主节点
[root@mini1 conf]# vi backup-masters
hadoop2(3.4) 拷贝hbase到其他节点
[root@hadoop1 software]# pwd
/home/tuzq/software
[root@hadoop1 software]# scp -r hbase-1.3.1 root@hadoop2:$PWD
[root@hadoop1 software]# scp -r hbase-1.3.1 root@hadoop3:$PWD
[root@hadoop1 software]# scp -r hbase-1.3.1 root@hadoop4:$PWD
[root@hadoop1 software]# scp -r hbase-1.3.1 root@hadoop5:$PWD注意:修改这些机器上的storm的环境变量
(4) 将配置好的HBase拷贝到每一个节点并同步时间。
(可以用 ntpdate time.nist.gov 进行同步)
(5) 启动所有的hbase进程
首先要同步集群的时间
首先启动zk集群
./zkServer.sh start
启动hdfs集群
start-dfs.sh
检验dfs是否启动了的命令是:
hdfs dfsadmin -report
或者访问:
http://hadoop2:50070/explorer.html#/
http://hadoop1:8088/cluster
启动hbase,在主节点上运行:
[root@hadoop1 bin]# pwd
/home/tuzq/software/hbase-1.3.1/bin
[root@hadoop1 bin]#./start-hbase.sh (这里不用在其它机器上执行命令)
停止hbase的方式是:
[root@hadoop1 bin]# ./stop-hbase.sh
stopping hbase.....................
[root@hadoop1 bin]# jps
10864 ConsoleConsumer
4624 DataNode
112387 Jps
109748 DFSZKFailoverController
10680 ConsoleConsumer
108618 ResourceManager
3981 JournalNode
108735 NodeManager
4095 NameNode
[root@hadoop1 bin]# (6) 通过浏览器访问hbase管理页面
192.168.1.201:60010
http://hadoop1:16010/
Ip:16010 
进入hadoop-ha集群中,查看数据发现已经多出了一个hbase的文件夹 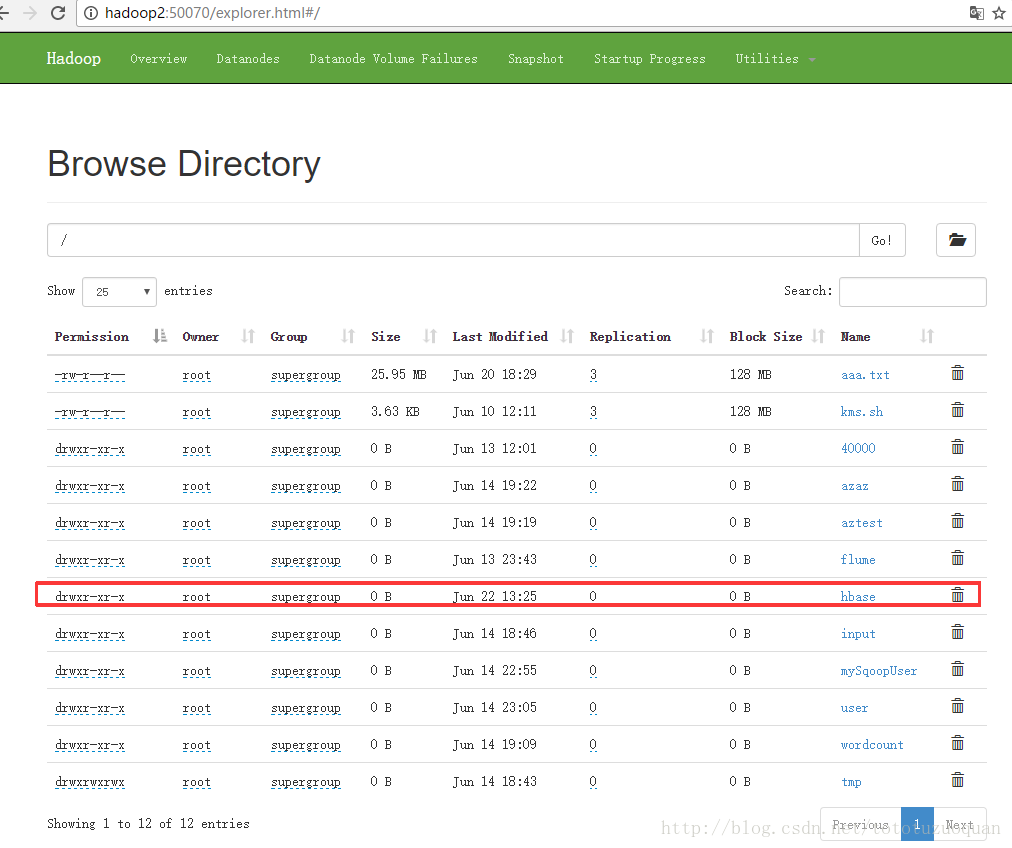
(7) 为保证集群的可靠性,要启动多个HMaster
[root@hadoop1 software]# cd $HBASE_HOME/bin
[root@hadoop1 software]# ./hbase-daemon.sh start master (这个可以到hadoop2上启动)
HBASE:
很多时候,节点失效是因为pid文件被删除引起(默认pid文件中/tmp下),所以最好把很多默认是/tmp的目录修改成自己的目录,比如hbase的pid配置可以在hbase-env.sh中,修改export HBASE_PID_DIR=/var/hadoop/pids就可以。hbase节点失效常对应60020端口异常。
进入hbase shell
1、查看节点情况:
status
当然,也可以通过web页面查看(如果服务开放的话):
http://serviceIp:60010/master.jsp
http://serviceIp:60030/regionserver.jsp
http://serviceIp:60010/zk.jsp
2、重启
$bin/hbase-daemon.sh stop regionserver
$bin/hbase-daemon.sh start regionserver也可以添加新的master(默认只有一个master),$bin/hbase-daemon.sh start master