ZynqNet解析(七)实现于BRAM上的Cache
背景:我们需要仿照ZynqNet的模式构造卷积的IPcore用于FPGA的优化。
目的:搞懂zynqNet的cache的实现。
相关内容:
ZynqNet解析(六)内存的实现 https://blog.csdn.net/weixin_36474809/article/details/83409853
MTCNN(十)构建卷积IPcore https://blog.csdn.net/weixin_36474809/article/details/83658473
目录
几种Cache
一、Ocache
1.1 数据于OBRAM上累加
1.2 写出OBRAM到DRAM上
二、ImageCache
2.1 ImageCache的大小
2.2 DRAM读入IBRAM
2.3 DRAM中读出的顺序
2.4 每层之中如何读取
2.5 从IBRAM读出到PE
三、weightCache
3.1 WBRAM的大小
3.2 WBRAM上的位置关系
3.3 加载入WBRAM
3.4 从WBRAM上加载入processing element
几种Cache
四种on-chip cache(report 4.2.4)
- ICache(Image cache):line buffer,为input feature map准备的。
- OCache(Output cache)
- GPoolCache(Global pooling cache)
- WCache(weights cache):最大的cache,需要当前layer的ci×co个filter
processing_elements和memory_controller
- processing_Elements,进行MACC运算
- memory_controller, 在DRAM与BRAM之间搬运数据
注意netconfig与network不仅在CPU端定义中有运用到,在FPGA端的;定义之中也有用到。

一、Ocache
全局变量 float OutputCache::OBRAM[MAX_NUM_CHOUT];其中OBRAM的大小为MAX_NUM_CHOUT,为最大的输出的通道数。根据前面for height与for width就确定了是针对单个输出的像素点,所以for channel in与for channle out就是单个像素点上先循环feature map然后循环output channel。
for channel in时固定feature,然后权重进行循环,MACC后放入OBRAM。然后换一个channel in的9*9,再进行更换weiht然后累加与OBRAM。
BRAM与DRAM之间的数据搬运是MemoryController完成的,所以需要在memroyController之中设置相应的偏移量。
1.1 数据于OBRAM上累加
ProcessingElement::macc2d(pixels,weights,macc_sum);
if (cur_channel_in == 0) {
OutputCache::setOutChannel(cur_channel_out, macc_sum);
} else {
OutputCache::accumulateChannel(cur_channel_out, macc_sum);
}
void OutputCache::accumulateChannel(int co, float value_to_add) {
#pragma HLS inline
#pragma HLS FUNCTION_INSTANTIATE variable = co
#pragma HLS ARRAY_PARTITION variable = OBRAM cyclic factor = N_PE
#pragma HLS RESOURCE variable=OBRAM core=RAM_T2P_BRAM latency=2
float old_ch = getOutChannel(co);
float new_ch = old_ch + value_to_add;
setOutChannel(co, new_ch);
};
float OutputCache::getOutChannel(int co) {
#pragma HLS inline
return OBRAM[co];
}
void OutputCache::setOutChannel(int co, float data) {
#pragma HLS inline
#pragma HLS FUNCTION_INSTANTIATE variable = co
OBRAM[co] = data;
}如果是第一个输入通道就设定OBRAM相应的位置为MACC值,若不是第一个输入通道就表示需要在不同的输入通道之间进行累加。
1.2 写出OBRAM到DRAM上
}//channel_out loop
}//channel_in loop
for(cur_channel_out=0; cur_channel_out在进行完输入通道循环之后,所有的输入输出通道都在OBRAM上进行了累加,
然后,我们根据相应的地址映射将OBRAM上的数据写入DRAM之中。
二、ImageCache
2.1 ImageCache的大小
首先,定义flaot ImageCache::IBRAM[MAX_IMAGE_CACHE_SIZE];在zynqNet之中,这些参数被计算好在network.h文件之中。
ImageCache是一次更新一行还是所有的iamge均存于Cache之中。我们需要找出答案。

data_t ImageCache::IBRAM[MAX_IMAGE_CACHE_SIZE];
imgcacheaddr_t ImageCache::line_width;
void ImageCache::setLayerConfig(layer_t &layer) {
#pragma HLS inline
width_in = layer.width;
height_in = layer.height;
ch_in = layer.channels_in;
line_width = ch_in * width_in;
loads_left = line_width * height_in;
curr_img_cache_addr = 0;
#pragma HLS Resource variable = loads_left core = MulnS latency = 2
reset();
}2.2 DRAM读入IBRAM
我们需要注意到zynqNet与MTCNN中feature-map的不同,MTCNN中的feature-map的排列方式为for channel,for height. for width.而zynqNet中的在IBRAM上的排列方式为for height,for width, for channel.所以在读取的过程中会有一定的差别。这样,无论DRAM的IBRAM还是IBRAM到PE之中,的地址映射顺序都会产生变化。我们确定BRAM上的顺序为for row,for col, for channel
//zynqNet ImageCache.cpp
void ImageCache::setNextChannel(data_t value) {
imgcacheaddr_t MAX_ADDR = (line_width * NUM_IMG_CACHE_LINES - 1);
// Write Value into IBRAM
IBRAM[curr_img_cache_addr] = value;
// Check and Wrap Write Address into IBRAM
if (curr_img_cache_addr == MAX_ADDR)
curr_img_cache_addr = 0;
else
curr_img_cache_addr++;
}
void ImageCache::preloadPixelFromDRAM(data_t *SHARED_DRAM) {
#pragma HLS inline
L_PRELOAD_PIXEL_FROM_DRAM: for (channel_t ci = 0; ci < ch_in; ci++) {
#pragma HLS LOOP_TRIPCOUNT min = 3 max = 1024 avg = 237
#pragma HLS pipeline II = 1
#pragma HLS latency min=4
data_t px = MemoryController::loadNextChannel(SHARED_DRAM);
setNextChannel(px);
}
loads_left = loads_left - ch_in;
}
void ImageCache::preloadRowFromDRAM(data_t *SHARED_DRAM) {
#pragma HLS inline
L_DRAM_PRELOADROW_X: for (coordinate_t x = 0; x < width_in; x++) {
#pragma HLS LOOP_TRIPCOUNT min = 8 max = 256 avg = 45
preloadPixelFromDRAM(SHARED_DRAM);
}
}上面为加载一个row的函数,然后在当前行中进行循环列,列中循环channel,运用嵌套的循环实现从DRAM中一行的加载。setNextChannel是将相应的值写入IBRAM之中,然后BRAM上的地址进行++以便进行下次写入。
2.3 DRAM中读出的顺序
在float px = MemoryController::loadNextInputChannel(input_ptr);将图像从DRAM读出为像素值。我们现在就要确定如何将此值从DRAM中读出。
void ImageCache::preloadPixelFromDRAM(data_t *SHARED_DRAM) {
#pragma HLS inline
L_PRELOAD_PIXEL_FROM_DRAM: for (channel_t ci = 0; ci < ch_in; ci++) {
#pragma HLS LOOP_TRIPCOUNT min = 3 max = 1024 avg = 237
#pragma HLS pipeline II = 1
#pragma HLS latency min=4
data_t px = MemoryController::loadNextChannel(SHARED_DRAM);
setNextChannel(px);
}
loads_left = loads_left - ch_in;
}唯一与之相关的语句:data_t px = MemoryController::loadNextChannel(SHARED_DRAM);
//-------------------------to IBRAM---------------------------------------
//load image from DRAM to reg
void MemoryController::setPixelLoadRow(coordinate_t y) {
layer_pixel_offset = layer_input_offset + pixels_per_row * y;
}
//load image from DRAM to BRAM (channel)
data_t MemoryController::loadNextChannel(data_t* SHARED_DRAM) {
#pragma HLS inline
#pragma HLS pipeline II=1
data_t pixel_from_ram = reg(SHARED_DRAM[dram_data_offset + layer_pixel_offset]);
layer_pixel_offset++; // increment address for next fetch
return pixel_from_ram;
};我们可以看出,此为从DRAM加载一行的值到读出来到reg的相关语句。前语句为设置相应的偏移地址,后一行为从DRAM的偏移地址之中读出相应的值。zynqNet之中的值为for row for col for channel,所以直接设置每行的偏移地址然后顺序读取即可。
memoryController与IBRAM中的地址变量一直在自己自增,以确保对应的关系。在IBRAM之中,初始的reset将IBRAM的地址置零,在DRAM之中,初始的地址由setPixelLoadRow确定。
2.4 每层之中如何读取
在FPGA开始行列循环之前,先读取行0与像素点列(0,1)
// Preload Row 0 + Pixel (1,0)
MemoryController::setPixelLoadRow(0);
ImageCache::preloadRowFromDRAM(SHARED_DRAM);
MemoryController::setPixelLoadRow(1);
ImageCache::preloadPixelFromDRAM(SHARED_DRAM);我们现在需要搞明白一个问题,在BRAM之中的图像到底如何只存4个row,卷积完成之后是擦掉重写还是只更新一行。后续发现是直接将像素值写入前一行,一个像素一个像素的写入。因为IBAM的地址在自增,自增到最大值后返回0.后续用取模的运算来实现对单个行的读取。
void ImageCache::setNextChannel(data_t value) {
imgcacheaddr_t MAX_ADDR = (line_width * NUM_IMG_CACHE_LINES - 1);
// Write Value into IBRAM
IBRAM[curr_img_cache_addr] = value;
// Check and Wrap Write Address into IBRAM
if (curr_img_cache_addr == MAX_ADDR)
curr_img_cache_addr = 0;
else
curr_img_cache_addr++;
}自增的IBRAM地址。
//calculate row offset in IBRAM
imgcacheaddr_t ImageCache::precalcYOffset(const coordinate_t y) {
#pragma HLS inline
cacheline_t req_line = (y) % NUM_IMG_CACHE_LINES;
imgcacheaddr_t addr_line_offset = req_line * line_width;
#pragma HLS RESOURCE variable=addr_line_offset core=MulnS latency=2
return addr_line_offset;
}通过取模来读出在BRAM之中的哪一行。然后将新读入的继续进行写入。

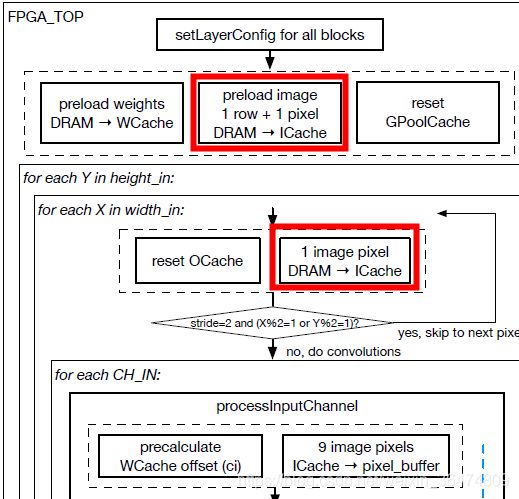
// Preload Row 0 + Pixel (1,0)
MemoryController::setPixelLoadRow(0);
ImageCache::preloadRowFromDRAM(SHARED_DRAM);
MemoryController::setPixelLoadRow(1);
ImageCache::preloadPixelFromDRAM(SHARED_DRAM);
// Y Loop
L_Y:
for (y = 0; y < layer.height; y++) {
#pragma HLS LOOP_TRIPCOUNT min = 8 max = 256 avg = 45
// X Loop
L_X:
for (x = 0; x < layer.width; x++) {
#pragma HLS LOOP_TRIPCOUNT min = 8 max = 256 avg = 45
p_pixelSetup : {
// Load Next Pixel (automatically checks #pixels left)
ImageCache::preloadPixelFromDRAM(SHARED_DRAM);
}之所以只读一行一个像素,我们的理解为padding的时候当作padding的变量了。经过下面查找,zynqNet经过了padding。并且应该为左padding
//in "network.cpp"
network_t *get_network_config() {
network_t *net = new network_t(27, 2528800);
// Layer Attributes: ( NAME , W, H, CI, CO, K, P, S, R, S1, S2, GP)
addLayer(net, layer_t("c1 ", 256, 256, 3, 64, 3, 1, 2, 1, 0, 0, 0));
addLayer(net, layer_t("f2/s3 ", 128, 128, 64, 16, 3, 1, 2, 1, 0, 0, 0));
addLayer(net, layer_t("f2/e1 ", 64, 64, 16, 64, 1, 0, 1, 1, 1, 0, 0));
addLayer(net, layer_t("f2/e3 ", 64, 64, 16, 64, 3, 1, 1, 1, 0, 1, 0));
addLayer(net, layer_t("f3/s1 ", 64, 64, 128, 16, 1, 0, 1, 1, 0, 0, 0));
addLayer(net, layer_t("f3/e1 ", 64, 64, 16, 64, 1, 0, 1, 1, 1, 0, 0));
。。。
// in "netconfig.cpp" addLayer function
// Align to memory borders (float needed because of ceil() operation below)
float mem_border = MEMORY_ALIGNMENT / sizeof(data_t);
// Data Size Calculations
int input_data_pixels = layer.width * layer.height * layer.channels_in;
int width_out =
1 + std::floor((float)(layer.width + 2 * layer.pad - layer.kernel) /
layer.stride);
int height_out =
1 + std::floor((float)(layer.height + 2 * layer.pad - layer.kernel) /
layer.stride);
int output_data_pixels = width_out * height_out * layer.channels_out;
int num_weights = // conv + bias weights
layer.channels_out * layer.channels_in * layer.kernel * layer.kernel +
layer.channels_out;2.5 从IBRAM读出到PE
//zynqNet之中的读取
void ProcessingElement::processInputChannel(const coordinate_t y,
const coordinate_t x,
const channel_t ci_in,
const channel_t ch_out) {
#pragma HLS inline off
#pragma HLS FUNCTION_INSTANTIATE variable = ci_in
#pragma HLS dataflow
channel_t ci = ci_in;
weightaddr_t ci_offset;
data_t pixel_buffer[9];
#pragma HLS ARRAY_PARTITION variable = pixel_buffer complete dim = 0
// Preload Image Pixel Buffer (fetch pixels around (y,x,ci))
preloadPixelsAndPrecalcCIoffset(y, x, ci, ch_out, ci_offset, pixel_buffer);
// MACC All Output Channels
processAllCHout(ch_out, ci, ci_offset, pixel_buffer);
}在preloadPiexlsAndPrecalcCIoffset之中,先根据相应的行,设置行的偏移量,再根据列读出当前列的值。
void ProcessingElement::preloadPixels(const coordinate_t y_center,
const coordinate_t x_center,
const channel_t ci, data_t buffer[9]) {
#pragma HLS inline
#pragma HLS pipeline
L_PE_loadPixel_Y:
for (int j = 0; j < 3; j++) {
coordinate_t y = y_center + j - 1;
imgcacheaddr_t y_offset = ImageCache::precalcYOffset(y);
L_PE_loadPixel_X:
for (int i = 0; i < 3; i++) {
coordinate_t x = x_center + i - 1;
data_t px = reg(ImageCache::getPixel(y, y_offset, x, ci));
buffer[j * 3 + i] = px;
}
}
}相应偏移量的计算及读取为:
//calculate row offset in IBRAM
imgcacheaddr_t ImageCache::precalcYOffset(const coordinate_t y) {
#pragma HLS inline
cacheline_t req_line = (y) % NUM_IMG_CACHE_LINES;
imgcacheaddr_t addr_line_offset = req_line * line_width;//row_offset
#pragma HLS RESOURCE variable=addr_line_offset core=MulnS latency=2
return addr_line_offset;
}
//get pixel out from BRAM
data_t ImageCache::getPixel(const coordinate_t y, const imgcacheaddr_t y_offset,
const coordinate_t x, const channel_t ci) {
#pragma HLS inline
#pragma HLS RESOURCE variable = IBRAM core = RAM_S2P_BRAM
imgcacheaddr_t addr_pixel_offset = x * ch_in;//col_offset
imgcacheaddr_t addr = y_offset + addr_pixel_offset + ci;//row_offset+col_offset+channel_offset
bool is_padding_pixel = x < 0 | x >= width_in | y < 0 | y >= height_in;
data_t px = is_padding_pixel ? 0.0f : IBRAM[addr];
return px;
}至此,我们搞懂了zynqNet的IBRAM的运用。我们可以进行MTCNN的IPcore中的IBRAM相关的编写。
MTCNN(十)构建卷积IPcore https://blog.csdn.net/weixin_36474809/article/details/83658473
三、weightCache
相较于图像,权重是一次性将一层的权重一起读到WBRAM之中。所以WBRAM是占用最大的BRAM
3.1 WBRAM的大小
zynqNet之中:
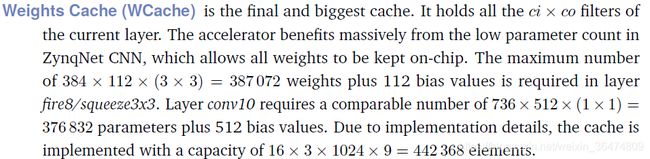
WBRAM为最大的Cache,每次要将整层的权重写入WBRAM,大小为ci×3×3×co个。
定义为data_t WeightsCache::WBRAM[N_PE][NUM_BRAMS_PER_PE][BLOCK_SIZE][9];
我们需要搞明白其中每个变量的意思
- N_PE:用于并行的processing element的数量
- NUM_BRAMS_PER_PE,每块PE上的BRAM的数量
- BLOCK_SIZE,每个BRAM的大小
即,每个PE上有BRAM用于存储Weight
所以,N_PE×NUM_BRAMS_PER_PE×BLOCK_SIZE的大小为ci×co
注意相应的优化指令为:
// Array Partitioning
#pragma HLS ARRAY_PARTITION variable = WBRAM complete dim = 1 // PE ID
#pragma HLS ARRAY_PARTITION variable = WBRAM complete dim = 2 // block ID
#pragma HLS ARRAY_PARTITION variable = WBRAM complete dim = 4 // weight ID
#pragma HLS RESOURCE variable = WBRAM core = RAM_S2P_BRAM latency = 3关于其优化指令,参考 FPGA基础知识(十二)HLS增大吞吐量的优化 https://blog.csdn.net/weixin_36474809/article/details/81665911
可以看出,把第一维,第二维,第四维给完全分开。留下第三维为 BlockSize

3.2 WBRAM上的位置关系
#define CEIL_DIV(x, y) (((x) + (y)-1) / (y))
// Depth of single BRAM36 in (1K x 32b) configuration
const int BLOCK_SIZE = 1024;
// Number of BRAM36 needed per PE
const int NUM_BRAMS_PER_PE =
(CEIL_DIV(((MAX_WEIGHTS_PER_LAYER) / 8), BLOCK_SIZE) / N_PE);
// Type Definitions needed
typedef ap_uint PEID_t;
typedef ap_uint blockID_t;
typedef ap_uint rowID_t;
typedef ap_uint weightID_t;
// WBRAM:
// dim0 = PEID = ID of Processing Element associated with this memory portion
// dim1 = blockID = Used to split memory into junks that fit into BRAM32 units
// dim2 = rowID = Row address inside one BRAM32 unit
// dim3 = weightID = last dimension
// - either contains 1 filter = 9 weights (3x3 kernel)
// - or 8 individual weights (1x1 kernel or bias values) 确定相应的权重的位置需要四个参数,PEID,blockID, rowID,weightID,这四个分别为WBRAM上的参数。下面函数就根据相应的weight来算出在WBRAM上的位置。
void WeightsCache::getAddrForSingleWeight(const channel_t co,
const weightaddr_t ci_offset,
PEID_t &PEID, blockID_t &blockID,
rowID_t &rowID,
weightID_t &weightID) {
#pragma HLS INLINE
if (kernel == 3) {
// ci_offset = ci * ch_out
PEID = co % N_PE;
blockID = (((ci_offset + co) / N_PE)) / BLOCK_SIZE;
rowID = (((ci_offset + co) / N_PE)) % BLOCK_SIZE;
weightID = 0;
} else { // kernel == 1
// ci_offset = ci * ch_out
PEID = co % N_PE;
blockID = (((ci_offset + co) / N_PE) / 8) / BLOCK_SIZE;
rowID = (((ci_offset + co) / N_PE) / 8) % BLOCK_SIZE;
weightID = ((ci_offset + co) / N_PE) % 8;
}
}第二个blockID,运用的是整型的除法,c++中的除法是四舍五入还是舍去小数点后面的?经过实验,发现是舍去小数点后面的。
我们发现zynqNet中权重的存储是for ci,for co,for 3×3 filter的。
所以给定一个权重,其线性的位置为 cur_ci×outChannelNum×9+cur_co×9+filterLoc。每一个3×3filter的初始的位置为 filterSize×(cur_ci*outChannelNum+cur_co). 暂且不管1×1卷积的相关问题,我们只关注3×3卷积。
所以,权重是以co为单位均分入了PE,然后具体的CO在PE之中以相应的规律排列。但是,zynqNet的保证了通道与N_PE的数量是整除的,否则,第一个PEID的计算应该为 (ci_offset+co)%N_PE。
3.3 加载入WBRAM
void WeightsCache::loadFromDRAM(data_t *SHARED_DRAM) {
#pragma HLS inline
weightaddr_t dram_addr = 0;
// Weights:
L_LOADWEIGHTS_CI:
for (channel_t ci = 0; ci < ch_in + 1; ci++) {
#pragma HLS LOOP_TRIPCOUNT MIN = 3 AVG = 238 MAX = 1024
weightaddr_t ci_offset = precalcInputOffset(ci);
bool bias_or_1x1 = (kernel == 1 | ci == ch_in);
numfilterelems_t weights_per_filter = (bias_or_1x1) ? 1 : 9;
weightaddr_t weights_per_ch_out = ch_out * weights_per_filter;
weightaddr_t addr = 0;
ap_uint weight_index = 0;
channel_t co = 0;
L_LOADWEIGHTS_CO:
for (addr = 0; addr < weights_per_ch_out; addr++) {
#pragma HLS LOOP_TRIPCOUNT MIN = 16 AVG = 258 MAX = 1024
#pragma HLS PIPELINE II = 2
data_t weight = MemoryController::loadNextWeight(SHARED_DRAM, dram_addr);
dram_addr++;
PEID_t PEID;
blockID_t blockID;
rowID_t rowID;
weightID_t weightID;
getAddrForSingleWeight(co, ci_offset, PEID, blockID, rowID, weightID);
if (bias_or_1x1) {
WBRAM[PEID][blockID][rowID][weightID] = weight;
} else { // (kernel == 3)
WBRAM[PEID][blockID][rowID][weight_index] = weight;
}
weight_index++;
if (weight_index == weights_per_filter) {
weight_index = 0;
co = co + 1;
}
}
}
} 循环ci与每个ci上的元素个数,然后运算相应WBRAM地址,从DRAM上的地址读出,写入WBRAM上,然后将DRAM上的地址自增指向下一个地址。我们发现DRAM上的地址总是线性的读入BRAM,所以对于zynqNet来说,其DRAM上的地址基本不用运算,只用自增。而对于我们的MTCNN来说,相应的地址应当进行一定的计算才能得出。
3.4 从WBRAM上加载入processing element
//getting from WBRAM to processing element
void WeightsCache::getNineWeights(const channel_t co,
const weightaddr_t ci_offset,
data_t weights_buf[9]) {
#pragma HLS FUNCTION_INSTANTIATE variable = co
#pragma HLS inline
#pragma HLS pipeline
// Array Partitioning
#pragma HLS ARRAY_PARTITION variable = WBRAM complete dim = 1 // PE ID
#pragma HLS ARRAY_PARTITION variable = WBRAM complete dim = 2 // block ID
#pragma HLS ARRAY_PARTITION variable = WBRAM complete dim = 4 // weight ID
#pragma HLS RESOURCE variable = WBRAM core = RAM_S2P_BRAM latency = 3
// Calculate Memory Address
PEID_t PEID;
blockID_t blockID;
rowID_t rowID;
weightID_t weightID;
getAddrForSingleWeight(co, ci_offset, PEID, blockID, rowID, weightID);
data_t *WBRAM_BLOCK = WBRAM[PEID][blockID][rowID];
// Fetch Weights into Filter Template
data_t weights_temp[9];
#pragma HLS array_partition variable = weights_temp complete dim = 0
L_getNineWeights:
for (int i = 0; i < 9; i++) {
// Fetch all 9 elements in last dimension into registers (weights_temp)
weights_temp[i] = WBRAM_BLOCK[i];
// Fill weights_buf with 0.0f for 1x1 kernel / with weights for 3x3 kernel
weights_buf[i] = (kernel == 1) ? 0.0f : weights_temp[i];
}
// Fill single relevant weight into weights_buf for 1x1 kernel
if (kernel == 1) weights_buf[4] = weights_temp[weightID];
}
data_t WeightsCache::getOneWeight(const channel_t co,
const weightaddr_t ci_offset) {
#pragma HLS FUNCTION_INSTANTIATE variable=co
#pragma HLS pipeline
#pragma HLS inline
PEID_t PEID;
blockID_t blockID;
rowID_t rowID;
weightID_t weightID;
getAddrForSingleWeight(co, ci_offset, PEID, blockID, rowID, weightID);
data_t weight = WBRAM[PEID][blockID][rowID][weightID];
return weight;
}运算出相应的PEID,blockID, rowID,与weightID然后就进行读取。
四、ProcessingElement的实现
4.1 算法流图
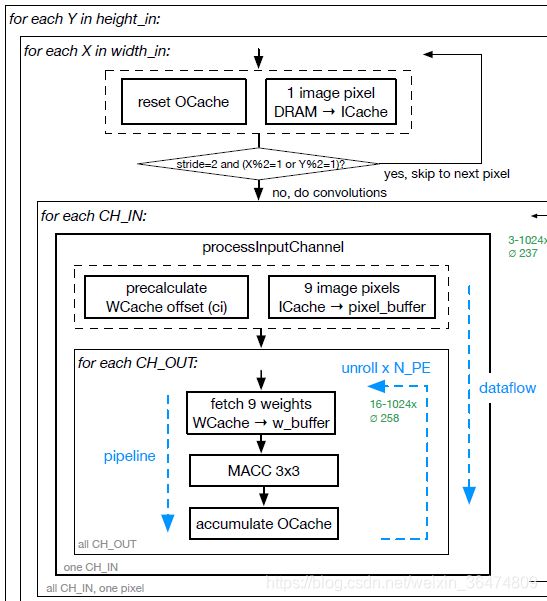
通过流程图看出来是定着imageCache然后取权重。
我们需要在代码中找到如下问题:
- 不同的PE是否加载相同的imagePixel_buffer[9]
- weight是如何进行加载与循环的
4.2 实现代码
先加载pixels[9],然后针对此pixel[9]进行每个channel out的MACC循环累加操作。
//load pixels[9] and loop weight on them
void ProcessingElement::processInputChannel(const coordinate_t y,
const coordinate_t x,
const channel_t ci_in,
const channel_t ch_out) {
#pragma HLS inline off
#pragma HLS FUNCTION_INSTANTIATE variable = ci_in
#pragma HLS dataflow
channel_t ci = ci_in;
weightaddr_t ci_offset;
data_t pixel_buffer[9];
#pragma HLS ARRAY_PARTITION variable = pixel_buffer complete dim = 0
// Preload Image Pixel Buffer (fetch pixels around (y,x,ci))
preloadPixelsAndPrecalcCIoffset(y, x, ci, ch_out, ci_offset, pixel_buffer);
// MACC All Output Channels
processAllCHout(ch_out, ci, ci_offset, pixel_buffer);
}
void ProcessingElement::processAllCHout(const channel_t ch_out,
const channel_t ci,
const weightaddr_t ci_offset,
const data_t pixels[9]) {
#pragma HLS INLINE off
L_CH_OUT:
for (channel_t co = 0; co < ch_out; co++) {
#pragma HLS LOOP_TRIPCOUNT min = 16 max = 1024 avg = 258
#pragma HLS unroll factor = N_PE
#pragma HLS PIPELINE II = 1
data_t result, weights_local[9];
#pragma HLS ARRAY_PARTITION variable = weights_local complete dim = 0
// fetch weights
WeightsCache::getNineWeights(co, ci_offset, weights_local);
// multiply-accumulate
macc2d(pixels, weights_local, result);
// save result to Output Buffer
if (ci == 0) {
OutputCache::setChannel(co, result);
} else {
OutputCache::accumulateChannel(co, result);
}
};
}4.3 硬件相关
//load and loop all channel out weight MACC on pixel[9]
void ProcessingElement::processAllCHout(const channel_t ch_out,
const channel_t ci,
const weightaddr_t ci_offset,
const data_t pixels[9]) {
#pragma HLS INLINE off
L_CH_OUT:
for (channel_t co = 0; co < ch_out; co++) {
#pragma HLS LOOP_TRIPCOUNT min = 16 max = 1024 avg = 258
#pragma HLS unroll factor = N_PE
#pragma HLS PIPELINE II = 1
data_t result, weights_local[9];注意展开的地方为N_PE是在processAllCHout函数之中。在for co的后面有个 #pragma HLS unroll factor = N_PE
即pixel[9]只加载一次到BRAM之中,在不同的PE实现MACC与OBRAM的累加。OBRAM只与Out_channel有关,所以加载一次pixel[9],然后送入并行的MACC,运算之后在OBRAM之中累加。
因此,每一个MACC模块都运行了每一个ci的pixel,但是不同的MACC模块运行了不同的co
data_t WeightsCache::WBRAM[N_PE][NUM_BRAMS_PER_PE][BLOCK_SIZE][9];
//ci_offset = ci * ch_out
PEID = co % N_PE;
blockID = (((ci_offset + co) / N_PE)) / BLOCK_SIZE;
rowID = (((ci_offset + co) / N_PE)) % BLOCK_SIZE;
weightID = 0;
WBRAM[PEID][blockID][rowID][weightID] = weight;平均每个PE上有 co/N_PE个in_channel_num
至此,我们搞懂了zynqNet如何在DRAM与BRAM与processing Element之间搬运数据的,现在,在运行MTCNN时,我们就可以运用此步骤来实现。