CycleGAN(六)模型结构更改
目的:更改模型结构用于我们的实验,增加为两个判别器。
参考:后面链接为作者给的更改模型的模板,我们需要在cycle_gan.py的基础上进行更改。https://github.com/junyanz/pytorch-CycleGAN-and-pix2pix/blob/master/models/template_model.py
更改后代码已经共享到github:https://github.com/Xingxiangrui/cycleGAN_with_two_D/tree/master
目录
一、更改思路
二、模型名称与定义
2.1 names更改
2.2 模型定义
2.3 optimizers
二、输入集更改
2.1 数据集加载
2.2 unaligned_dataset.py
2.3 图像读取过程
三、定义结构
3.1 网络输入
3.2 网络cycle
3.3 判别器的设定
3.4 loss
四、weight更新
4.1 weight更新流程
4.2 一次性更新或者两次更新
五、运行
5.1 数据集制作
5.2 命令行
一、更改思路
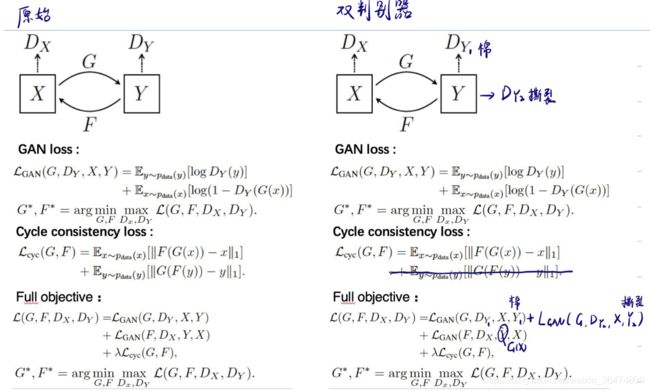
这里加两个判别器,一个判别材料类别,一个判别材料是否有损。直接讲fakeB放做B中当做B的材料。
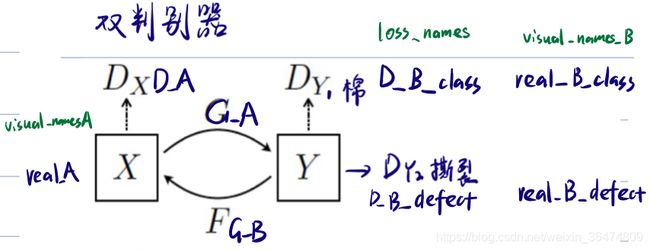
二、模型名称与定义
2.1 names更改
BaseModel.__init__(self, opt)
# specify the training losses you want to print out. The training/test scripts will call
#self.loss_names = ['D_A', 'G_A', 'cycle_A', 'idt_A', 'D_B', 'G_B', 'cycle_B', 'idt_B']
self.loss_names = ['D_A', 'G_A_class','G_A_defect', 'cycle_A', 'idt_A', 'D_B_defect' ,'D_B_class','G_B', 'idt_B']
# specify the images you want to save/display. The training/test scripts will call
visual_names_A = ['real_A', 'fake_B', 'rec_A']
#visual_names_B = ['real_B', 'fake_A', 'rec_B']
if self.isTrain:
visual_names_B = ['real_B_class','real_B_defect' ]
else:
visual_names_B = ['real_B']
if self.isTrain and self.opt.lambda_identity > 0.0: # if identity loss is used, we also visualize idt_B=G_A(B) ad idt_A=G_A(B)
visual_names_A.append('idt_B')
visual_names_B.append('idt_A')
self.visual_names = visual_names_A + visual_names_B # combine visualizations for A and B
# specify the models you want to save to the disk. The training/test scripts will call and .
if self.isTrain:
#self.model_names = ['G_A', 'G_B', 'D_A', 'D_B']
self.model_names = ['G_A', 'G_B', 'D_A', 'D_B_class','D_B_defect']
else: # during test time, only load Gs
self.model_names = ['G_A', 'G_B'] 2.2 模型定义
两个生成器,三个判别器
self.netG_A = networks.define_G(opt.input_nc, opt.output_nc, opt.ngf, opt.netG, opt.norm,
not opt.no_dropout, opt.init_type, opt.init_gain, self.gpu_ids)
self.netG_B = networks.define_G(opt.output_nc, opt.input_nc, opt.ngf, opt.netG, opt.norm,
not opt.no_dropout, opt.init_type, opt.init_gain, self.gpu_ids)
if self.isTrain: # define discriminators
self.netD_A = networks.define_D(opt.output_nc, opt.ndf, opt.netD,
opt.n_layers_D, opt.norm, opt.init_type, opt.init_gain, self.gpu_ids)
#self.netD_B = networks.define_D(opt.input_nc, opt.ndf, opt.netD,
# opt.n_layers_D, opt.norm, opt.init_type, opt.init_gain, self.gpu_ids)
self.netD_B_class = networks.define_D(opt.input_nc, opt.ndf, opt.netD,
opt.n_layers_D, opt.norm, opt.init_type, opt.init_gain, self.gpu_ids)
self.netD_B_defect = networks.define_D(opt.input_nc, opt.ndf, opt.netD,
opt.n_layers_D, opt.norm, opt.init_type, opt.init_gain, self.gpu_ids)
生成器,G_A和G_B和D_A不用变,加两个B的判别器
2.3 optimizers
这里用了两个loss所以需要有两个optimizers,一个D class,一个D defect,加入D之中,即用一个optimizer更新两个判别器的参数。
if self.isTrain:
if opt.lambda_identity > 0.0: # only works when input and output images have the same number of channels
assert(opt.input_nc == opt.output_nc)
self.fake_A_pool = ImagePool(opt.pool_size) # create image buffer to store previously generated images
self.fake_B_pool = ImagePool(opt.pool_size) # create image buffer to store previously generated images
# define loss functions
self.criterionGAN = networks.GANLoss(opt.gan_mode).to(self.device) # define GAN loss.
self.criterionCycle = torch.nn.L1Loss()
self.criterionIdt = torch.nn.L1Loss()
# initialize optimizers; schedulers will be automatically created by function .
self.optimizer_G = torch.optim.Adam(itertools.chain(self.netG_A.parameters(), self.netG_B.parameters()), lr=opt.lr, betas=(opt.beta1, 0.999))
self.optimizer_D = torch.optim.Adam(itertools.chain(self.netD_A.parameters(), self.netD_B_defect.parameters(), self.netD_B_class.parameters()), lr=opt.lr, betas=(opt.beta1, 0.999))
#self.optimizer_D_defect= torch.optim.Adam(itertools.chain(self.netD_A.parameters(), self.netD_B_defect.parameters()), lr=opt.lr, betas=(opt.beta1, 0.999))
self.optimizers.append(self.optimizer_G)
#self.optimizers.append(self.optimizer_D_class)
self.optimizers.append(self.optimizer_D) 二、输入集更改
2.1 数据集加载
因为变换了B的输入,所以读入输入时也应当更改相应的代码。我们来理一下程序如何读入数据
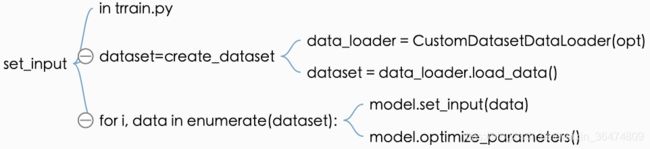
再train.py之中,通过create_dataset函数,创建datasets,然后遍历数据集,将相应的data输入set_input函数,通过相应的参数更新模型。
class CustomDatasetDataLoader():
"""Wrapper class of Dataset class that performs multi-threaded data loading"""
def __init__(self, opt):
"""Initialize this class
Step 1: create a dataset instance given the name [dataset_mode]
Step 2: create a multi-threaded data loader.
"""
self.opt = opt
dataset_class = find_dataset_using_name(opt.dataset_mode)
self.dataset = dataset_class(opt)
print("dataset [%s] was created" % type(self.dataset).__name__)
self.dataloader = torch.utils.data.DataLoader(
self.dataset,
batch_size=opt.batch_size,
shuffle=not opt.serial_batches,
num_workers=int(opt.num_threads))
def load_data(self):
return self注意这里,dataset_mode定义再base_options.py之中,
parser.add_argument('--dataset_mode', type=str, default='unaligned', help='chooses how datasets are loaded. [unaligned | aligned | single | colorization]')
2.2 unaligned_dataset.py
对于图片的加载再此unaligned_dataset.py程序之中
我们在所有的path及相关的代码段后面加一个路径,多一个class_path和defect_path
def __init__(self, opt):
"""Initialize this dataset class.
Parameters:
opt (Option class) -- stores all the experiment flags; needs to be a subclass of BaseOptions
"""
BaseDataset.__init__(self, opt)
self.dir_A = os.path.join(opt.dataroot, opt.phase + 'A') # create a path '/path/to/data/trainA'
if opt.isTrain:
self.dir_B_class = os.path.join(opt.dataroot, opt.phase + 'B_class') # create a path '/path/to/data/trainB'
self.dir_B_defect = os.path.join(opt.dataroot, opt.phase + 'B_defect') # create a path '/path/to/data/trainB'
else:
self.dir_B = os.path.join(opt.dataroot, opt.phase + 'B') # create a path '/path/to/data/trainB'
self.A_paths = sorted(make_dataset(self.dir_A, opt.max_dataset_size)) # load images from '/path/to/data/trainA'
if opt.isTrain:
self.B_class_paths = sorted(make_dataset(self.dir_B_class, opt.max_dataset_size)) # load images from '/path/to/data/trainB'
self.B_defect_paths = sorted(make_dataset(self.dir_B_defect, opt.max_dataset_size)) # load images from '/path/to/data/trainB'
else:
self.B_paths = sorted(
make_dataset(self.dir_B, opt.max_dataset_size)) # load images from '/path/to/data/trainB'
self.A_size = len(self.A_paths) # get the size of dataset A
#self.B_size = len(self.B_paths) # get the size of dataset B
#self.B_size = len(self.B_paths)
if opt.isTrain:
self.B_class_size = len(self.B_class_paths)
self.B_defect_size= len(self.B_defect_paths) # get the size of dataset B
else:
self.B_size = len(self.B_paths)
btoA = self.opt.direction == 'BtoA'
input_nc = self.opt.output_nc if btoA else self.opt.input_nc # get the number of channels of input image
output_nc = self.opt.input_nc if btoA else self.opt.output_nc # get the number of channels of output image
self.transform_A = get_transform(self.opt, grayscale=(input_nc == 1))
self.transform_B = get_transform(self.opt, grayscale=(output_nc == 1))2.3 图像读取过程
def __getitem__(self, index):
"""Return a data point and its metadata information.
Parameters:
index (int) -- a random integer for data indexing
Returns a dictionary that contains A, B, A_paths and B_paths
A (tensor) -- an image in the input domain
B (tensor) -- its corresponding image in the target domain
A_paths (str) -- image paths
B_paths (str) -- image paths
"""
A_path = self.A_paths[index % self.A_size] # make sure index is within then range
if self.opt.isTrain:
if self.opt.serial_batches: # make sure index is within then range
#index_B = index % self.B_size
index_B_class = index % self.B_class_siz
index_B_defect= index % self.B_defect_size
else: # randomize the index for domain B to avoid fixed pairs.
#index_B = random.randint(0, self.B_size - 1)
index_B_class = random.randint(0, self.B_class_size - 1)
index_B_defect= random.randint(0, self.B_defect_size - 1)
else:
if self.opt.serial_batches: # make sure index is within then range
index_B = index % self.B_size
else: # randomize the index for domain B to avoid fixed pairs.
index_B = random.randint(0, self.B_size - 1)将B读为B_class与B_defect
三、定义结构
3.1 网络输入
之前两输入现在变为三输入
def set_input(self, input):
"""Unpack input data from the dataloader and perform necessary pre-processing steps.
Parameters:
input (dict): include the data itself and its metadata information.
The option 'direction' can be used to swap domain A and domain B.
"""
#AtoB = self.opt.direction == 'AtoB'
#self.real_A = input['A' if AtoB else 'B'].to(self.device)
#self.real_B = input['B' if AtoB else 'A'].to(self.device)
#self.image_paths = input['A_paths' if AtoB else 'B_paths']
self.real_A = input['A'].to(self.device)
if self.isTrain:
self.real_B_class = input['B_class'].to(self.device)
self.real_B_defect= input['B_defect'].to(self.device)
else:
self.real_B = input['B'].to(self.device)
self.image_paths = input['A_paths']3.2 网络cycle
只设置一道cycle,A-fakeB-recA
def forward(self):
"""Run forward pass; called by both functions and ."""
self.fake_B = self.netG_A(self.real_A) # G_A(A)
self.rec_A = self.netG_B(self.fake_B) # G_B(G_A(A))
#self.fake_A = self.netG_B(self.real_B) # G_B(B)
#self.rec_B = self.netG_A(self.fake_A) # G_A(G_B(B)) 3.3 判别器的设定
多一个类别判别器和缺陷判别器,一个用于判别类别,真样本用real_B_class之中的样本,一个用于判别缺陷,用real_B_defect之中的样本,用这两个判别器去训练生成器。
注意:我们为了更方便理解,编写的程序之中,D_A用于判别A,D_B用于判别B。作者原代码之中,D_A用于训练G_A,所以判别的是B。
def backward_D_B_class(self):
"""Calculate GAN loss for discriminator D_A"""
fake_B = self.fake_B_pool.query(self.fake_B)
self.loss_D_B_class = self.backward_D_basic(self.netD_B_class, self.real_B_class, fake_B)
def backward_D_B_defect(self):
"""Calculate GAN loss for discriminator D_A"""
fake_B = self.fake_B_pool.query(self.fake_B)
self.loss_D_B_defect = self.backward_D_basic(self.netD_B_defect, self.real_B_defect, fake_B)
def backward_D_A(self):
"""Calculate GAN loss for discriminator D_B"""
rec_A = self.fake_A_pool.query(self.rec_A)
#self.loss_D_B = self.backward_D_basic(self.netD_B, self.real_A, fake_A)
self.loss_D_A = self.backward_D_basic(self.netD_A, self.real_A, rec_A)3.4 loss
不设idt loss,所以idt loss直接设置为0
其他几个loss
# G_BA generates rec_A, use D_A for loss
self.loss_G_B = self.criterionGAN(self.netD_A(self.rec_A), True)
# G_AB generates fake B ,use D_B_class and D_B_defect for loss
self.loss_G_A_class = self.criterionGAN(self.netD_B_class(self.fake_B), True)
self.loss_G_A_defect = self.criterionGAN(self.netD_B_defect(self.fake_B), True)
# Forward cycle loss || G_B(G_A(A)) - A||
self.loss_cycle_A = self.criterionCycle(self.rec_A, self.real_A) * lambda_A
# Backward cycle loss || G_A(G_B(B)) - B||
#self.loss_cycle_B = self.criterionCycle(self.rec_B, self.real_B) * lambda_B
# combined loss and calculate gradients
self.loss_G = self.loss_G_A_class + self.loss_G_A_defect + self.loss_G_B + self.loss_cycle_A
self.loss_G.backward()四、weight更新
4.1 weight更新流程
def optimize_parameters(self):
"""Calculate losses, gradients, and update network weights; called in every training iteration"""
# forward
self.forward() # compute fake images and reconstruction images.
# G_A and G_B
self.set_requires_grad([self.netD_A, self.netD_B_class, self.netD_B_defect], False) # Ds require no gradients when optimizing Gs
self.optimizer_G.zero_grad() # set G_A and G_B's gradients to zero
self.backward_G() # calculate gradients for G_A and G_B
self.optimizer_G.step() # update G_A and G_B's weights
# D_A and D_B
self.set_requires_grad([self.netD_A, self.netD_B_class , self.netD_B_defect], True)
self.optimizer_D_class.zero_grad() # set D_A and D_B's gradients to zero
self.optimizer_D_defect.zero_grad()
self.backward_D_A() # calculate gradients for D_A
self.backward_D_B_class() # calculate graidents for D_B
self.backward_D_B_defect()
self.optimizer_D_class.step() # update D_A and D_B's weights
self.optimizer_D_defect.step()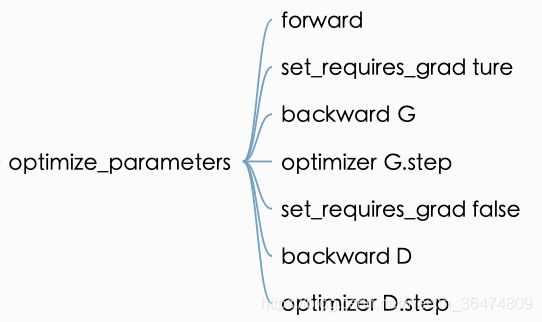
我们按照此流程,过一遍weight更新的过程以保证网络结构修改正确。
forward更改过,单cycle
几个net_D_B的值均为双判别器
backwardG的即生成器的loss在上面修改过
backwardD即判别器的loss,几个loss都设置上了。
至此,初步认为修改成功。后续需要运行及bug查找。
4.2 一次性更新或者两次更新
因为代码有一定bug,所以我们更新流程可以进行选择。
一种方法是,优化器选用单优化器优化三个网络的weight,分别为D_A , D_B_class, D_B_defect
self.optimizer_D_class = torch.optim.Adam( itertools.chain( self.netD_A.parameters(), self.netD_B_class.parameters()), lr=opt.lr, betas=(opt.beta1, 0.999))
另一种方法是,设置两个优化器,分别优化D_A, D_B_class, 另一个优化器优化 D_A, D_B_defect, 这样相当于对D_A更新了两次。我们暂时选用下面这种方法。
# initialize optimizers; schedulers will be automatically created by function .
self.optimizer_G = torch.optim.Adam(itertools.chain(self.netG_A.parameters(), self.netG_B.parameters()), lr=opt.lr, betas=(opt.beta1, 0.999))
self.optimizer_D_class = torch.optim.Adam(itertools.chain(self.netD_A.parameters(), self.netD_B_class.parameters()), lr=opt.lr, betas=(opt.beta1, 0.999))
self.optimizer_D_defect= torch.optim.Adam(itertools.chain(self.netD_A.parameters(), self.netD_B_defect.parameters()), lr=opt.lr, betas=(opt.beta1, 0.999))
self.optimizers.append(self.optimizer_G)
self.optimizers.append(self.optimizer_D_class)
self.optimizers.append(self.optimizer_D_defect) 五、运行
5.1 数据集制作
数据集名称 nor2_cott_tear
其中子文件夹,trainA放100张正常样本,trainB_class放24张棉样本,trainB_defect放20张撕裂样本,就可进行训练。
5.2 命令行
模型名称 nor2cott_tear
训练
env/bin/python /home/xingxiangrui/CycleGAN_with_two_D/train.py --dataroot /home/xingxiangrui/CycleGAN_with_two_D/datasets/nor2_cott_tear --name nor2cott_tear --model cycle_gan --no_html --lambda_A 10 --lambda_B 10 --lambda_identity 0
测试
env/bin/python /home/xingxiangrui/CycleGAN_with_two_D/test.py --dataroot /home/xingxiangrui/CycleGAN_with_two_D/datasets/nor2_cott_tear --name nor2cott_tear --model cycle_gan --num_test 100