pix2pix(二)训练图像尺寸及分配显卡
背景:新的数据集上,图像的大小为496*496,与原尺寸512*512不一样,不知道能否直接运行。另外,我们现在有了四张空余显卡服务器,并且新数据集的数据量较大,我们有空余的显卡资源加快训练。
目的:搞懂代码之中关于网络输入尺寸的部分,同时搞懂如何增大显卡占用以加快训练。
目录
一、图像尺寸
1.1 作者描述
预处理
图像尺寸
关于尺寸的信息
1.2 代码信息
参数位置
调用位置
resize
crop
二、GPU占用
2.1 参数
2.2 运用
2.3 加载网络
三、训练测试
3.1 训练
3.2 测试
一、图像尺寸
https://github.com/junyanz/pytorch-CycleGAN-and-pix2pix/blob/master/docs/tips.md
1.1 作者描述
预处理
Preprocessing预处理阶段
Images can be resized and cropped in different ways using --preprocess option. 训练时,根据预处理选项 --preprocess的选项,图片会被采用不同的方式resize与crop。
- The default option
'resize_and_crop'resizes the image to be of size(opt.load_size, opt.load_size)and does a random crop of size(opt.crop_size, opt.crop_size).默认的选项是resize_and_crop,resize为(opt.load_size, opt.load_size)大小,并且随机裁剪为(opt.crop_size, opt.crop_size) 'crop'skips the resizing step and only performs random cropping. crop跳过resize直接对图像进行随机裁剪。'scale_width'resizes the image to have widthopt.crop_sizewhile keeping the aspect ratio.'scale_width_and_crop'first resizes the image to have widthopt.load_sizeand then does random cropping of size(opt.crop_size, opt.crop_size). scale_width选项将图像resize为 opt.crop_size大小,同时保持相应的宽高比,'scale_width_and_crop'先按上面方法裁剪,然后再进行随机裁剪。'none'tries to skip all these preprocessing steps. 不进行处理。
However, if the image size is not a multiple of some number depending on the number of downsamplings of the generator, you will get an error because the size of the output image may be different from the size of the input image. Therefore, 'none' option still tries to adjust the image size to be a multiple of 4. You might need a bigger adjustment if you change the generator architecture. Please see data/base_datset.py do see how all these were implemented.
如果输入图像的尺寸不满足相应的网络的下采样尺寸,则会报错。输入与输出尺寸应当一致。特别是改了网络结构之后,更应当一致。
这些参数简单而言就是先resize再crop。可以选择其中一项或者两项或者不选,其中load_size与scale_width的区别就是一个是方形图像,另一个是非方形的图像,scale_width之后亦然保持之前的长宽比。
图像尺寸
Since the generator architecture in CycleGAN involves a series of downsampling / upsampling operations, the size of the input and output image may not match if the input image size is not a multiple of 4. As a result, you may get a runtime error because the L1 identity loss cannot be enforced with images of different size. Therefore, we slightly resize the image to become multiples of 4 even with --preprocess none option. For the same reason, --crop_size needs to be a multiple of 4.
两个原因,导致图像尺寸必须是4的倍数:
- 网络经历了下采样和上采样的过程,因此输入与输出的图像尺寸必须匹配。如果尺寸不匹配,则L1 loss就不能成功。
- 同理,--crop_size必须为4的倍数
Training/Testing with high res images高分辨率图像的处理方法。简而言之就是加载resize成1024,crop成360训练,测试时加载resize到1024即可。
CycleGAN is quite memory-intensive as four networks (two generators and two discriminators) need to be loaded on one GPU, so a large image cannot be entirely loaded. In this case, we recommend training with cropped images. For example, to generate 1024px results, you can train with --preprocess scale_width_and_crop --load_size 1024 --crop_size 360, and test with --preprocess scale_width --load_size 1024. This way makes sure the training and test will be at the same scale. At test time, you can afford higher resolution because you don’t need to load all networks.
关于尺寸的信息
网络在图像输入之前对图像进行了预处理,就是resize和crop。
简而言之,输入进网络的图像尺寸必须为4的倍数,比如如果最后一步是crop,则crop size必须为4的倍数。若最后一步为resize,则resize之后必须为4的倍数,若none,则原始图像必须为4的倍数
1.2 代码信息
参数位置
关于resize与crop的的默认选项:
parser.add_argument('--load_size', type=int, default=286, help='scale images to this size')
parser.add_argument('--crop_size', type=int, default=256, help='then crop to this size')
parser.add_argument('--max_dataset_size', type=int, default=float("inf"), help='Maximum number of samples allowed per dataset. If the dataset directory contains more than max_dataset_size, only a subset is loaded.')
parser.add_argument('--preprocess', type=str, default='resize_and_crop', help='scaling and cropping of images at load time [resize_and_crop | crop | scale_width | scale_width_and_crop | none]')默认是对输入图像既resize又crop,并且resize尺寸为286?搞不懂为什么选了这个值,crop的尺寸为256.
我们初期训练纺织品项目的时候图象为256*256,近似的认为没有精度损失,并且crop之后更多送入进行训练。
为了方便训练,且不损失精度,我们就在所有代码后面加 --preprocess none
调用位置
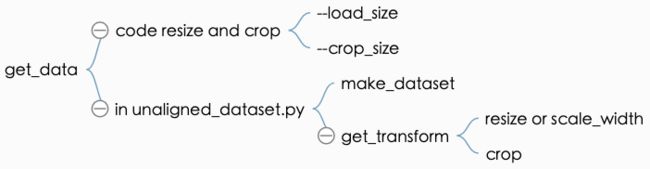
最终执行resize与crop是在base_dataset.py之中的get_transform函数。
def get_transform(opt, params=None, grayscale=False, method=Image.BICUBIC, convert=True):
transform_list = []
if grayscale:
transform_list.append(transforms.Grayscale(1))
if 'resize' in opt.preprocess:
osize = [opt.load_size, opt.load_size]
transform_list.append(transforms.Resize(osize, method))
elif 'scale_width' in opt.preprocess:
transform_list.append(transforms.Lambda(lambda img: __scale_width(img, opt.load_size, method)))
if 'crop' in opt.preprocess:
if params is None:
transform_list.append(transforms.RandomCrop(opt.crop_size))
else:
transform_list.append(transforms.Lambda(lambda img: __crop(img, params['crop_pos'], opt.crop_size)))
if opt.preprocess == 'none':
transform_list.append(transforms.Lambda(lambda img: __make_power_2(img, base=4, method=method)))
if not opt.no_flip:
if params is None:
transform_list.append(transforms.RandomHorizontalFlip())
elif params['flip']:
transform_list.append(transforms.Lambda(lambda img: __flip(img, params['flip'])))
if convert:
transform_list += [transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5),
(0.5, 0.5, 0.5))]
return transforms.Compose(transform_list)其中,用到的就是pytorch的transforms包。 import torchvision.transforms as transforms
其用法就是根据需要的图像处理创建一个transform_list,然后根据transform_list之中的变换进行transform。
官方文档: https://pytorch.org/docs/master/torchvision/transforms.html
class torchvision.transforms.Lambda(lambd)即用用户自定义的变形函数。进行transfrom
resize
裁剪就是按照相应的尺寸进行裁剪,很简单

transform_list = []
if grayscale:
transform_list.append(transforms.Grayscale(1))
if 'resize' in opt.preprocess:
osize = [opt.load_size, opt.load_size]
transform_list.append(transforms.Resize(osize, method))
elif 'scale_width' in opt.preprocess:
transform_list.append(transforms.Lambda(lambda img: __scale_width(img, opt.load_size, method)))
def __scale_width(img, target_width, method=Image.BICUBIC):
ow, oh = img.size
if (ow == target_width):
return img
w = target_width
h = int(target_width * oh / ow)
return img.resize((w, h), method)crop
裁剪成指定大小,其裁剪中心点是随机生成的。
if 'crop' in opt.preprocess:
if params is None:
transform_list.append(transforms.RandomCrop(opt.crop_size))
else:
transform_list.append(transforms.Lambda(lambda img: __crop(img, params['crop_pos'], opt.crop_size)))def get_params(opt, size):
w, h = size
new_h = h
new_w = w
if opt.preprocess == 'resize_and_crop':
new_h = new_w = opt.load_size
elif opt.preprocess == 'scale_width_and_crop':
new_w = opt.load_size
new_h = opt.load_size * h // w
x = random.randint(0, np.maximum(0, new_w - opt.crop_size))
y = random.randint(0, np.maximum(0, new_h - opt.crop_size))
flip = random.random() > 0.5
return {'crop_pos': (x, y), 'flip': flip}
def __crop(img, pos, size):
ow, oh = img.size
x1, y1 = pos
tw = th = size
if (ow > tw or oh > th):
return img.crop((x1, y1, x1 + tw, y1 + th))
return img
二、GPU占用
CycleGAN is quite memory-intensive as four networks (two generators and two discriminators) need to be loaded on one GPU, so a large image cannot be entirely loaded.四个网络存在一张显卡上,所以多加载显卡对于加速训练没有作用?后续通过代码发现并无作用。实验中发现即使输入--gpu_ids 0,1,2,3,程序也只是占用其中一张显卡。
2.1 参数
parser.add_argument('--gpu_ids', type=str, default='0', help='gpu ids: e.g. 0 0,1,2, 0,2. use -1 for CPU')
直接加 --gpu_ids 0,1,2,3
2.2 运用
base_options.py
# set gpu ids
str_ids = opt.gpu_ids.split(',')
opt.gpu_ids = []
for str_id in str_ids:
id = int(str_id)
if id >= 0:
opt.gpu_ids.append(id)
if len(opt.gpu_ids) > 0:
torch.cuda.set_device(opt.gpu_ids[0])
self.opt = opt
return self.opt代码中即如果有多个gpu则只用第一个gpu
base_model.py
def __init__(self, opt):
"""Initialize the BaseModel class.
Parameters:
opt (Option class)-- stores all the experiment flags; needs to be a subclass of BaseOptions
When creating your custom class, you need to implement your own initialization.
In this fucntion, you should first call
Then, you need to define four lists:
-- self.loss_names (str list): specify the training losses that you want to plot and save.
-- self.model_names (str list): specify the images that you want to display and save.
-- self.visual_names (str list): define networks used in our training.
-- self.optimizers (optimizer list): define and initialize optimizers. You can define one optimizer for each network. If two networks are updated at the same time, you can use itertools.chain to group them. See cycle_gan_model.py for an example.
"""
self.opt = opt
self.gpu_ids = opt.gpu_ids
self.isTrain = opt.isTrain
self.device = torch.device('cuda:{}'.format(self.gpu_ids[0])) if self.gpu_ids else torch.device('cpu') # get device name: CPU or GPU
也是只用单显卡。
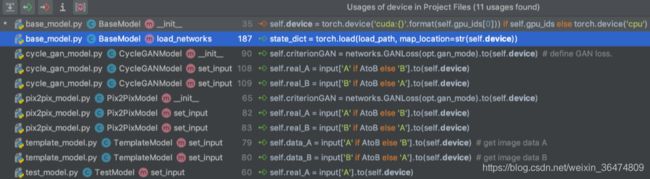
2.3 加载网络
再base_model.py之中,把gpu通过torch.device存入self.device之中,
三、训练测试
3.1 训练
读图如果不进行crop则CUDA out of memory,必须load为496,即原图,裁剪为256*256大小才可以。
python train.py --dataroot datasets/single2poly-OK-dataset --name single2poly_OK_cyclegan --model cycle_gan --no_html --max_dataset_size 1000 --preprocess scale_width_and_crop --load_size 496 --crop_size 256 --gpu_ids 0
(torch) [[email protected] cyclegan_pix2pix]$ python train.py
--dataroot datasets/single2poly-OK-dataset --name single2poly_OK_cyclegan
--model cycle_gan --no_html --max_dataset_size 1000
--preprocess scale_width_and_crop --load_size 496 --crop_size 256
--gpu_ids 0,1,2,3
----------------- Options ---------------
batch_size: 1
beta1: 0.5
checkpoints_dir: ./checkpoints
continue_train: False
crop_size: 256
dataroot: datasets/single2poly-OK-dataset [default: None]
dataset_mode: unaligned
direction: AtoB
display_env: main
display_freq: 400
display_id: 1
display_ncols: 4
display_port: 8097
display_server: http://localhost
display_winsize: 256
epoch: latest
epoch_count: 1
gan_mode: lsgan
gpu_ids: 0,1,2,3 [default: 0]
init_gain: 0.02
init_type: normal
input_nc: 3
isTrain: True [default: None]
lambda_A: 10.0
lambda_B: 10.0
lambda_identity: 0.5
load_iter: 0 [default: 0]
load_size: 496 [default: 286]
lr: 0.0002
lr_decay_iters: 50
lr_policy: linear
max_dataset_size: 1000 [default: inf]
model: cycle_gan
n_layers_D: 3
name: single2poly_OK_cyclegan [default: experiment_name]
ndf: 64
netD: basic
netG: resnet_9blocks
ngf: 64
niter: 100
niter_decay: 100
no_dropout: True
no_flip: False
no_html: True [default: False]
norm: instance
num_threads: 4
output_nc: 3
phase: train
pool_size: 50
preprocess: scale_width_and_crop [default: resize_and_crop]
print_freq: 100
save_by_iter: False
save_epoch_freq: 5
save_latest_freq: 5000
serial_batches: False
suffix:
update_html_freq: 1000
verbose: False
----------------- End -------------------
dataset [UnalignedDataset] was created
The number of training images = 10003.2 测试
测试的时候,需要保证加载进去的是--preprocess scale_width --load_size 496
python test.py --dataroot datasets/single2poly-OK-dataset --name single2poly_OK_cyclegan --model cycle_gan --num_test 200 --preprocess scale_width --load_size 496 --gpu_ids 1
(torch) [[email protected] cyclegan_pix2pix]$ python test.py --dataroot datasets/single2poly-OK-dataset --name single2poly_OK_cyclegan --model cycle_gan --num_test 200 --preprocess scale_width --load_size 496 --gpu_ids 1
----------------- Options ---------------
aspect_ratio: 1.0
batch_size: 1
checkpoints_dir: ./checkpoints
crop_size: 256
dataroot: datasets/single2poly-OK-dataset [default: None]
dataset_mode: unaligned
direction: AtoB
display_winsize: 256
epoch: latest
eval: False
gpu_ids: 1 [default: 0]
init_gain: 0.02
init_type: normal
input_nc: 3
isTrain: False [default: None]
load_iter: 0 [default: 0]
load_size: 496 [default: 256]
max_dataset_size: inf
model: cycle_gan [default: test]
n_layers_D: 3
name: single2poly_OK_cyclegan [default: experiment_name]
ndf: 64
netD: basic
netG: resnet_9blocks
ngf: 64
no_dropout: True
no_flip: False
norm: instance
ntest: inf
num_test: 200 [default: 50]
num_threads: 4
output_nc: 3
phase: test
preprocess: scale_width [default: resize_and_crop]
results_dir: ./results/
serial_batches: False
suffix:
verbose: False
----------------- End -------------------
dataset [UnalignedDataset] was created
initialize network with normal
initialize network with normal
model [CycleGANModel] was created
loading the model from ./checkpoints/single2poly_OK_cyclegan/latest_net_G_A.pth
loading the model from ./checkpoints/single2poly_OK_cyclegan/latest_net_G_B.pth
---------- Networks initialized -------------
[Network G_A] Total number of parameters : 11.378 M
[Network G_B] Total number of parameters : 11.378 M