PyTorch项目应用实例(六)并行化|分组运算|张量乘|常用神经网络层
目的:模型需要增加GPU的并行化,下面是遇到的一些问题与方法。
博主代码地址:https://github.com/Xingxiangrui/various_pyTorch_network_structure/blob/master/group_clsgat_parallel.py
参考:
torch的官方文档:https://pytorch.org/docs/master/torch.html
目录
一、卷积的分组
1.1 conv2D的groups
1.2 分组卷积
二、结构的更改
2.1 原始的结构
2.2 reduce conv
2.3 attentions convs
2.4 torch.stack与cat
三、gmp
3.1 maxpool
3.2 pytorch中view的用法
四、用einsum取代fc
4.1 分组的fc
4.2 输入输出及参数量
总体输入输出
第一个分组
所有分组
4.3 参数初始化
4.4 einsum
4.5 einsum的写法问题
五、模型的并行化
六、分组fc
6.1 conv1d
6.2 改为torch.einsum
七、batchnorm尺寸
一、卷积的分组
1.1 conv2D的groups
conv2D的groups
https://blog.csdn.net/monsterhoho/article/details/80173400
groups 决定了将原输入分为几组,而每组channel重用几次,由out_channels/groups计算得到,这也说明了为什么需要 groups能供被 out_channels与in_channels整除。
1.2 分组卷积
将相应的卷积扩大为每个组的卷积,然后再分组卷。
class Parallel_Bottleneck(nn.Module):
expansion = 4
# groups=12 group_channels=512
def __init__(self, groups, group_channels, stride=1, downsample=None):
super(Parallel_Bottleneck, self).__init__()
expand = 2 # fixme
self.groups=groups
# squeeze from group_channels to group_channels//2*groups
self.conv1 = nn.Conv2d(group_channels, groups*group_channels//2, kernel_size=1, bias=False)
self.bn1 = nn.BatchNorm2d(groups*group_channels//2)
self.conv2 = nn.Conv2d(groups*group_channels//2, groups*group_channels//2, kernel_size=3, stride=stride,
padding=1, bias=False, groups=12)
self.bn2 = nn.BatchNorm2d(groups*group_channels//2)
self.conv3 = nn.Conv2d(groups*group_channels//2, groups*group_channels, kernel_size=1, bias=False, groups=12) # fixme
self.bn3 = nn.BatchNorm2d(groups*group_channels) # fixme
self.relu = nn.ReLU(inplace=True)
# self.ca = ChannelAttention(planes * expand) # fixme
# self.sa = SpatialAttention()
self.downsample = downsample
self.stride = stride
def forward(self, x):
# input x=residual[batch, group_channels=512, W,H]
# residual = torch.Tensor(x.size(0),0,x.size(2),x.size(3))
# residual [batch, groups*group_channels=6144, W,H]
for group_idx in range(self.groups):
if (group_idx==0):
residual=x
else:
residual=torch.cat((residual,x),dim=1)
# residual=torch.cat((x,x,x,x,x,x,x,x,x,x,x,x), dim=1)
# squeeze and to gropus=12 [batch, group_channels//2*groups=512//2*12=3072,W,H]
out = self.conv1(x)
# same as above [batch, group_channels//2*groups=512//2*12=3072,W,H]
out = self.bn1(out)
# same as above [batch, group_channels//2*groups=512//2*12=3072,W,H]
out = self.relu(out)
# same as above [batch, group_channels//2*groups=512//2*12=3072,W,H]
out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out)
# expand [batch , groups_channels*groups=6144, W,H ]
out = self.conv3(out)
out = self.bn3(out)
# out = self.ca(out) * out
# out = self.sa(out) * out
if self.downsample is not None:
residual = self.downsample(x)
# residual [batch, groups*group_channels=6144, W,H]
out += residual
out = self.relu(out)
return out
先将相应的数据重复用torch.cat按组复制到相应的结构,再进行相应的网络运算。
(可以用torch.repeat来实现同一张量的多份拼接。)
二、结构的更改
需要将原始的结构代码等价改为新的结构。
2.1 原始的结构
# input x [batch_size, 2048, W=14, H=14]
# conv from 2048 to Group_channel=512
x=self.reduce_conv(x)
# output x [B, group_channels=512, W=14, H=14]
# old serial format
temp = []
for i in range(self.groups):
y = self.attention_convs[i](x) # each y : [Batchsize, Group_Channels=512, W=14, H=14]
y = self.gmp(y).view(y.size(0), y.size(1)) # each y : [BatchSize ,Group_Channels=512 ]
temp.append(y)
# temp[groups=12], for each [ batch_size, group_channels=512]输入,经过减少通道的卷积,得到了 原始通道从2048降到了512,尺寸见标注
2.2 reduce conv
reduce conv没有变化,将输入通道由2048变到了512
self.reduce_conv = utils.BasicConv(in_planes=2048, out_planes=group_channels, kernel_size=1)
2.3 attentions convs
输入为x,尺寸为 x [B, group_channels=512, W=14, H=14]
输出为y,有12个元素,每个元素为 [B, group_channels=512, W=14, H=14]
我们希望并为 [B, groups=12*group_channels=512, W=14, H=14]
class Parallel_AttentionBottleneck(nn.Module):
expansion = 4
def __init__(self, inplanes, planes, stride=1, downsample=None):
# inplanes is group_channels=512, planes=group_channels//2
super(Parallel_AttentionBottleneck, self).__init__()
expand = 2 # fixme
self.conv1 = nn.Conv2d(inplanes, planes, kernel_size=1, bias=False)
self.bn1 = nn.BatchNorm2d(planes)
self.conv2 = nn.Conv2d(planes, planes, kernel_size=3, stride=stride,
padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(planes)
self.conv3 = nn.Conv2d(planes, planes * expand, kernel_size=1, bias=False) # fixme
self.bn3 = nn.BatchNorm2d(planes * expand) # fixme
self.relu = nn.ReLU(inplace=True)
# self.ca = ChannelAttention(planes * expand) # fixme
# self.sa = SpatialAttention()
self.downsample = downsample
self.stride = stride
def forward(self, x):
# input [ batch, group_channels=512, W=14,H=14]
residual = x
# squeeze out [ batch, group_channels/expand= 256, W, H ]
out = self.conv1(x)
# BN (planes: group_channels//expand= 256), out [ batch, group_channels/expand= 256, W, H ]
out = self.bn1(out)
# out same as above [ batch, group_channels/expand= 256, W,H]
out = self.relu(out)
# same [ batch, group_channels/expand= 256, W,H]
out = self.conv2(out)
# same [ batch, group_channels/expand= 256, W,H]
out = self.bn2(out)
# same [ batch, group_channels/expand= 256, W,H]
out = self.relu(out)
# expand out [ batch, group_channels=512 , W,H]
out = self.conv3(out)
# same as above [ batch, group_channels=512 , W,H]
out = self.bn3(out)
# out = self.ca(out) * out
# out = self.sa(out) * out
if self.downsample is not None:
residual = self.downsample(x)
# same as input [ batch, group_channels=512 , W,H]
out += residual
# same as input [ batch, group_channels=512 , W,H]
out = self.relu(out)
return out相当于先squeeze,squeeze之后再expand回来。
2.4 torch.stack与cat
stack这样会创建出一个新的维度,并不好,比如
# input x=residual[batch, group_channels=512, W,H]
# residual = x
residual=torch.stack((x,x,x,x,x,x,x,x,x,x,x,x), dim=1)
原始[batch, group_channels=512, W,H],
stack后改为了 [batch, groups ,group_channels=512, W,H],
改为torch.cat就可以了。相当于相应的维度cat
https://blog.csdn.net/qq_39709535/article/details/80803003
for group_idx in range(self.groups):
if (group_idx==0):
residual=x
else:
residual=torch.cat((residual,x),dim=1)例如并行12个cat的x。可以直接用torch.repeat来实现多个张量的拼接。
2.5
三、gmp
global max pooling
https://blog.csdn.net/caicaiatnbu/article/details/88955272
3.1 maxpool
https://www.programcreek.com/python/example/107647/torch.nn.AdaptiveAvgPool2d
源码解释:
class AdaptiveMaxPool2d(_AdaptiveMaxPoolNd):
r"""Applies a 2D adaptive max pooling over an input signal composed of several input planes.
The output is of size H x W, for any input size.
The number of output features is equal to the number of input planes.
Args:
output_size: the target output size of the image of the form H x W.
Can be a tuple (H, W) or a single H for a square image H x H.
H and W can be either a ``int``, or ``None`` which means the size will
be the same as that of the input.
return_indices: if ``True``, will return the indices along with the outputs.
Useful to pass to nn.MaxUnpool2d. Default: ``False``
Examples:
>>> # target output size of 5x7
>>> m = nn.AdaptiveMaxPool2d((5,7))
>>> input = torch.randn(1, 64, 8, 9)
>>> output = m(input)
>>> # target output size of 7x7 (square)
>>> m = nn.AdaptiveMaxPool2d(7)
>>> input = torch.randn(1, 64, 10, 9)
>>> output = m(input)
>>> # target output size of 10x7
>>> m = nn.AdaptiveMaxPool2d((None, 7))
>>> input = torch.randn(1, 64, 10, 9)
>>> output = m(input)
"""
@weak_script_method
def forward(self, input):
return F.adaptive_max_pool2d(input, self.output_size, self.return_indices)self.gmp = nn.AdaptiveMaxPool2d(1)我们的代码为:
self.gmp = nn.AdaptiveMaxPool2d(1)y = self.gmp(y).view(y.size(0), y.size(1)) # each y : [BatchSize ,Group_Channels=512 ]
3.2 pytorch中view的用法
安装行优先的顺序重新排列
https://blog.csdn.net/york1996/article/details/81949843
比如,原始尺寸为 [x.size(0) , x.size(1), 1,1 ]重排之后为 [x.size(0) , x.size(1)]
x = self.gmp(x).view(x.size(0), x.size(1))相应的实例为:
>>> import torch
>>> a = torch.arange(1, 17)
>>> a
tensor([ 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16])
>>> a.view(4, 4)
tensor([[ 1, 2, 3, 4],
[ 5, 6, 7, 8],
[ 9, 10, 11, 12],
[13, 14, 15, 16]])
>>> a.view(2, 2, 4)
tensor([[[ 1, 2, 3, 4],
[ 5, 6, 7, 8]],
[[ 9, 10, 11, 12],
[13, 14, 15, 16]]])维度越靠后越需要保持顺序。这样看来,我们用的feature排列为[ group0[group channel size], group1 [group channel size] ... ]
四、用einsum取代fc
4.1 分组的fc
原始fc写法,用torch.modulist, 逐个进行卷积。
count = 0
outside = []
for i in range(self.groups):
inside = []
for j in range(self.nclasses_per_group[i]):
inside.append(self.class_fcs[count](x[:, i, :])) # [B,C]
count += 1
inside = torch.stack(inside, dim=1) # [B,N,C]
# inside = self.gat2s[i](inside) # [B,N,C]
outside.append(inside)
x = torch.cat(outside, dim=1) # [B,nclasses,C]
x = self.gat(x)
x = torch.cat([self.fcs[i](x[:, i, :]) for i in range(self.nclasses)], dim=1) # [B,nclasses]定义时用modulelist
self.fcs = nn.ModuleList(
[nn.Sequential(
utils.ResidualLinearBlock(in_channels=class_channels, reduction=2, out_channels=class_channels),
nn.Linear(in_features=class_channels, out_features=1)
) for _ in range(nclasses)])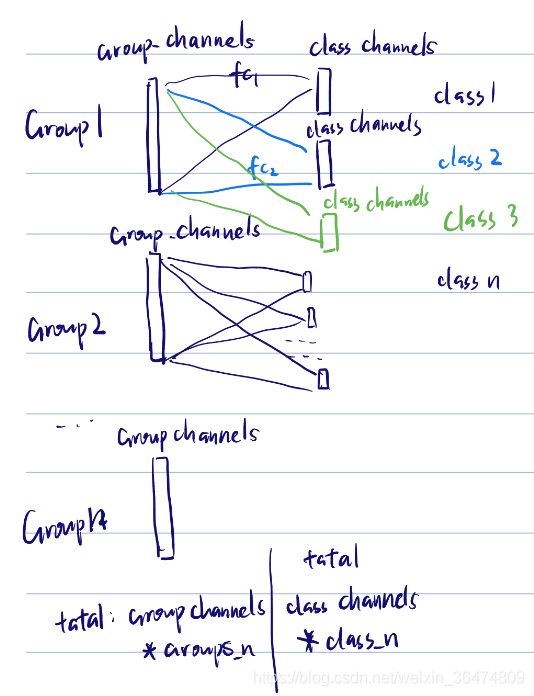
4.2 输入输出及参数量
总体输入输出
输入为 :group_channels* n_groups
输出为: class_channels*n_classes
如果整层为一个fc,参数量为 (group_channels* n_groups) *(class_channels*n_classes)
第一个分组
输入:group_channels
输出:class_channels* nclasses_per_group[1]
第一组参数量 卷积核: group_channels*( class_channels* nclasses_per_group[1] )
偏置:class_channels* nclasses_per_group[1]
所有分组
总参数量 group_channels*( class_channels* (nclasses_per_group[1] + nclasses_per_group[2] +... + nclasses_per_group[group n]) )
总参数量:group_channels* class_channels* n_classes
偏置参数量: class_channels* n_classes
4.3 参数初始化
按照上面的参数模式,进行初始化
def __init__(self, n_groups, n_classes, group_channels,class_channels,nclasses_per_group, bias=True):
super(Parallel_GroupLinear, self).__init__()
self.n_groups = n_groups
self.n_classes=n_classes
self.group_channels = group_channels
self.class_channels = class_channels
self.nclasses_per_group=nclasses_per_group
self.weight = nn.Parameter(torch.Tensor(group_channels,class_channels*n_classes))
if bias:
self.bias = nn.Parameter(torch.Tensor(class_channels, n_classes))
else:
self.register_parameter('bias', None)
self.reset_parameters()相应的维度对应
4.4 einsum
https://www.colabug.com/4597405.html
https://blog.csdn.net/LoseInVain/article/details/81143966
相当于张量的缩约:

相应的代码定义为:
class Parallel_GroupLinear(nn.Module):
def __init__(self, n_groups, n_classes, group_channels,class_channels,nclasses_per_group, bias=True):
super(Parallel_GroupLinear, self).__init__()
self.n_groups = n_groups
self.n_classes=n_classes
self.group_channels = group_channels
self.class_channels = class_channels
self.nclasses_per_group=nclasses_per_group
self.weight = nn.Parameter(torch.Tensor(group_channels,n_classes,class_channels))
if bias:
self.bias = nn.Parameter(torch.Tensor(class_channels, n_classes))
else:
self.register_parameter('bias', None)
self.reset_parameters()
def reset_parameters(self):
stdv = 1. / math.sqrt(self.weight.size(1))
self.weight.data.uniform_(-stdv, stdv)
if self.bias is not None:
self.bias.data.uniform_(-stdv, stdv)
def forward(self, input):
# input [batch, groups=12, group_channels ]
groups_input=torch.Tensor(input.size(0),0,self.group_channels)
for group_idx in range(len(self.nclasses_per_group)):
for class_per_group_idx in range(self.nclasses_per_group[group_idx]):
groups_input=torch.cat((groups_input,input[:,group_idx,:].view(input.size(0),1,self.group_channels)),dim=1)
# groups input [ batch, n_classes, group_channels ]
output = torch.einsum('gik,gkj->gij', groups_input, self.weight)4.5 einsum的写法问题
pycharm编译时候,下面这种写法没问题,不会报错,但是服务器上运行会报错(后面两个点乘的向量没有加中括号)
output = torch.einsum('bgi,gio->bgo', [input, self.weight])应当写为下面这种:
output = torch.einsum('bgi,gio->bgo', [input, self.weight])五、模型的并行化
https://blog.csdn.net/xizero00/article/details/60139098
torch.nn.parallel.data_parallel
六、分组fc
6.1 conv1d
https://blog.csdn.net/sunny_xsc1994/article/details/82969867
不可行
self.fc = nn.Conv1d(in_channels=in_channels, out_channels=out_channels, kernel_size=in_channels//fc_groups ,bias=False,groups=fc_groups)
RuntimeError: Expected 3-dimensional input for 3-dimensional weight 10240 256,
but got 2-dimensional input of size [2, 20480] instead6.2 改为torch.einsum
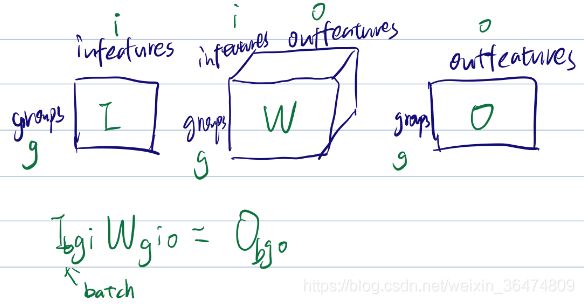
输入输出
# fixme group divided fc
class group_divided_linear(nn.Module):
def __init__(self, ngroups, in_features, out_features, bias=True):
super(group_divided_linear, self).__init__()
self.ngroups = ngroups
self.in_features = in_features
self.out_features = out_features
self.weight = nn.Parameter(torch.Tensor(ngroups, in_features, out_features))
if bias:
self.bias = nn.Parameter(torch.Tensor(ngroups, out_features))
else:
self.register_parameter('bias', None)
self.reset_parameters()
七、batchnorm尺寸
https://blog.csdn.net/smallflyingpig/article/details/78862525
https://blog.csdn.net/u014532743/article/details/78456350
https://blog.csdn.net/u014532743/article/details/78456350
https://blog.csdn.net/tmk_01/article/details/80679549