ILSVRC2017冠军SENet,Squeeze-and-Excitation Networks论文详解
背景:SENet以极大的优势获得了最后一届 ImageNet 2017 竞赛 Image Classification 任务的冠军,非常具有价值。
博主代码地址:https://github.com/Xingxiangrui/various_pyTorch_network_structure/blob/master/senet_and_pretrained.py
目录
一、概览
1.1 传统CNN
1.2 空间信息增强
1.3 特点与作用
二、方法
2.1 SE block概览
2.2 特征提取
2.3 squeeze操作
2.4 Excitation再校准
2.5 SE block代码
三、运用
3.1 嵌入
四、实验
五、个人总结
一、概览
1.1 传统CNN
卷积神经网络传统CNN:
- 通过每层的感受野融合了空间信息和channel层面的信息
- 局部的感受野
- 信息集中在 空间(spatial)和特征维度(channel-wise)
1.2 空间信息增强
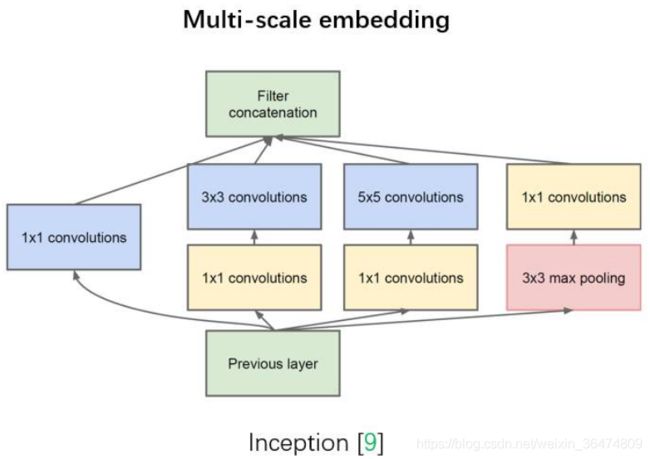
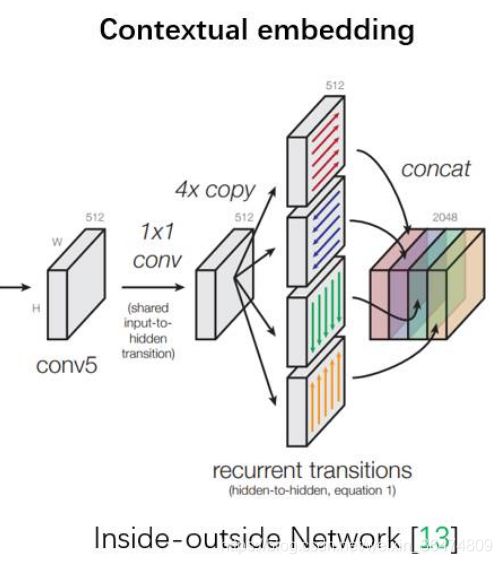
其他的相关工作:
- 如 Inception 结构中嵌入了多尺度信息,聚合多种不同感受野上的特征来获得性能增益;Conference on Neural Information Processing Systems, 2015.C. Szegedy, W. Liu, Y. Jia, P. Sermanet, S. Reed, D. Anguelov, D. Erhan, V. Vanhoucke, and A. Rabinovich, “Going deeper with convolutions,” in CVPR, 2015.
S. Ioffe and C. Szegedy, “Batch normalization: Accelerating deep network training by reducing internal covariate shift,” in ICML, 2015. - 在 Inside-Outside 网络中考虑了空间中的上下文信息 [7]S. Bell, C. L. Zitnick, K. Bala, and R. Girshick, “Inside-outside net:
Detecting objects in context with skip pooling and recurrent neural networks,” in CVPR, 2016.
[8] A. Newell, K. Yang, and J. Deng, “Stacked hourglass networks for human pose estimation,” in ECCV, 2016. - 将 Attention 机制引入到空间维度上。M. Jaderberg, K. Simonyan, A. Zisserman, and K. Kavukcuoglu, “Spatial transformer networks,” in Conference on Neural Information Processing Systems, 2015.
1.3 特点与作用
- 其他工作在空间维度上来提升网络的性能。那么很自然想到,网络是否可以从其他层面来考虑去提升性能,比如考虑特征通道之间的关系。
- 通过通道中间的channel independence来获取信息
- 增强有用的feature,降低无用的feature
- Squeeze-and-Excitation (SE) block, with the goal of improving the quality of representations produced by a network by explicitly modelling the interdependencies between the channels of its convolutional features.通过引入SE block单元,来实现网络的feature在channel之间提取相互依赖关系。
二、方法
2.1 SE block概览
- SE (Squeeze and excitation) block为网络的核心。SE block是一种轻量级的门限机制,专门用于对各通道的关联性进行建模。
- SE block设计简单,可以很容易地加入到已有的网络中
- 只增加少量的模型复杂度和计算开支
- 另外对不同数据集的泛化能力较强

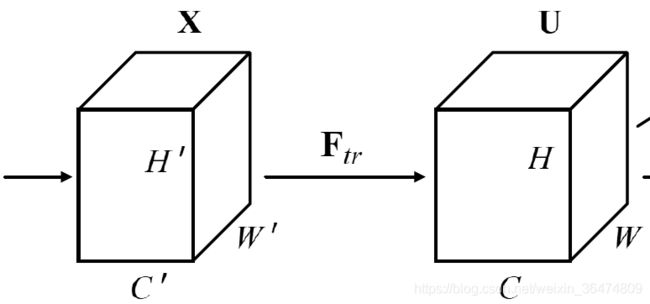
SE block如上图:
通过输入X,经过变换Ftr,获得feature U,U的维度(H,W,C)
- X为输入,维度(H',W',C')
- 变换为Ftr, 例如卷积操作
- 变换后得到的feature为U,维度(H,W,C)
SE block包括Fsq: squeeze operation与Fex: excitation operation
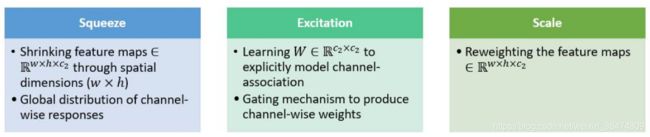
- squeeze:将各通道的全局空间特征作为该通道的表示,形成一个通道描述符. 即将之前的(H,W,C)变换为 (1,1,C),即通过对每个通道的clobal操作,将其转为channel wise的特征。
- excitation: 学习对各通道的依赖程度,并根据依赖程度的不同对特征图进行调整.
- sacle: 运用excitation学到的通道的依赖程度,对特征图进行调整。也可以看做用excitation的结果作为权重,乘在feature上。
这部分的工作归纳一下,就是squeeze提取出通道的特征,然后学到通道之间的关联性,学到之后将之前的feature映射到之后的feature,这种映射是channel wise的映射。
2.2 特征提取
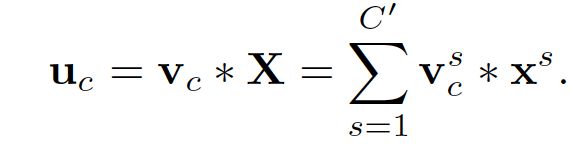
此公式代表,输入X经过卷积得到输出U
- 其中*表示卷积操作
- 卷积核
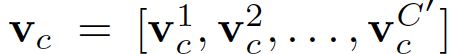
- 输入X=
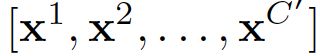
- 输出
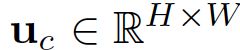
2.3 squeeze操作
squeeze的操作是为了找到channel之间的依赖。通过squeeze操作,将空间信息用channel descriptor来描述。
通过对U的维度进行收缩,获得一个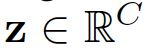 维度的向量,分别表示C个通道上的特征。
维度的向量,分别表示C个通道上的特征。
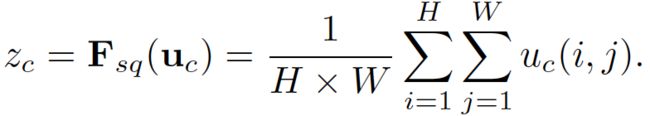
- 其中Fsq表示squeeze操作
- H,W分别表示U的宽和高,C表示U的通道
- 归纳来看,z相当于对每个通道做一个average pooling
2.5中代码之中果然也为average pooling
2.4 Excitation再校准

相当于运用通道之间的依赖,对通道进行再校准,并且需要满足下面的条件:
- 通道之间的校准相互作用是非线性的,为了更好的拟合非线性的特性
- 通道校准之后相互之间要独立
- 为了满足这些条件,作者运用gating mechnism加上sigmoid激活来实现
![]()
- Fex即excitation操作,即相当于用之前提取出的特征z对权重W进行再校准
- δ表示ReLU操作
- σ表示sigmoid操作
- W1维度
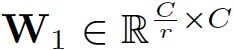
- W2维度
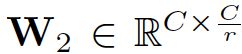
最终的输出相当于用此步得到的s来对前面的feature进行操作:
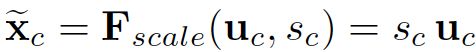
- Sc为通过通道间获得的activations
- Uc为前面说的提取出的特征
2.5 SE block代码
代码很简单,均为上面说的结构。
class SELayer(nn.Module):
def __init__(self, channel, reduction=16):
super(SELayer, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.fc = nn.Sequential(
nn.Linear(channel, channel // reduction, bias=False),
nn.ReLU(inplace=True),
nn.Linear(channel // reduction, channel, bias=False),
nn.Sigmoid()
)
def forward(self, x):
b, c, _, _ = x.size()
y = self.avg_pool(x).view(b, c)
y = self.fc(y).view(b, c, 1, 1)
return x * y.expand_as(x)三、运用
3.1 嵌入
SE block可以用于目前的模型之中,例如inception与resnet,即将se block直接嵌入

SE 模块还可以嵌入到含有 skip-connections 的模块中。上右图是将 SE 嵌入到 ResNet 模块中的一个例子,操作过程基本和 SE-Inception 一样,只不过是在 Addition 前对分支上 Residual 的特征进行了特征重标定。如果对 Addition 后主支上的特征进行重标定,由于在主干上存在 0~1 的 scale 操作,在网络较深 BP 优化时就会在靠近输入层容易出现梯度消散的情况,导致模型难以优化。
目前大多数的主流网络都是基于这两种类似的单元通过 repeat 方式叠加来构造的。由此可见,SE 模块可以嵌入到现在几乎所有的网络结构中。通过在原始网络结构的 building block 单元中嵌入 SE 模块,我们可以获得不同种类的 SENet。如 SE-BN-Inception、SE-ResNet、SE-ReNeXt、SE-Inception-ResNet-v2 等等
四、实验
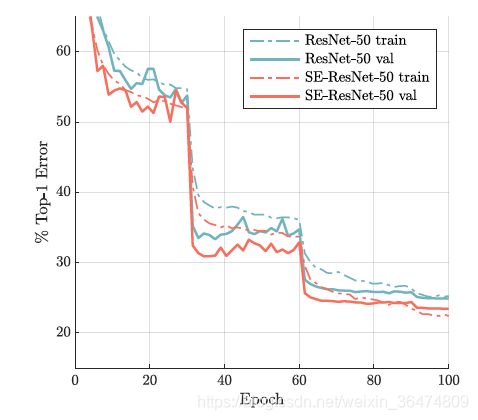
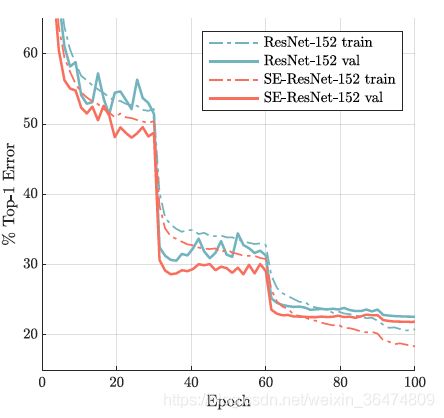
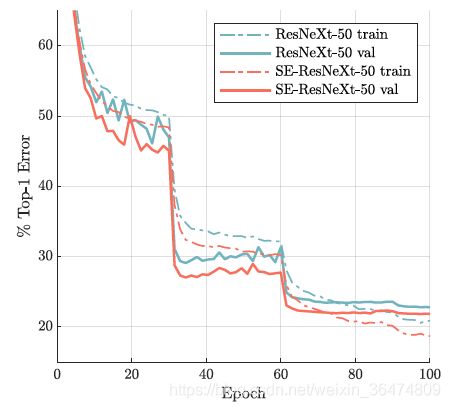
SE block非常有效,实验部分不细讲。
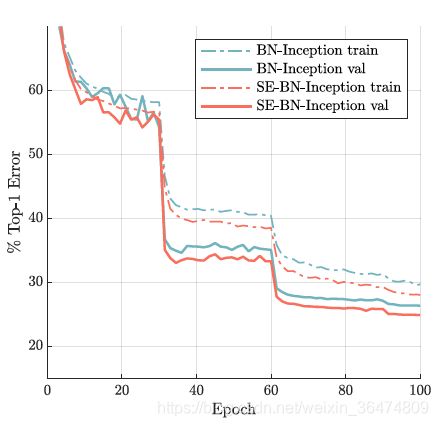
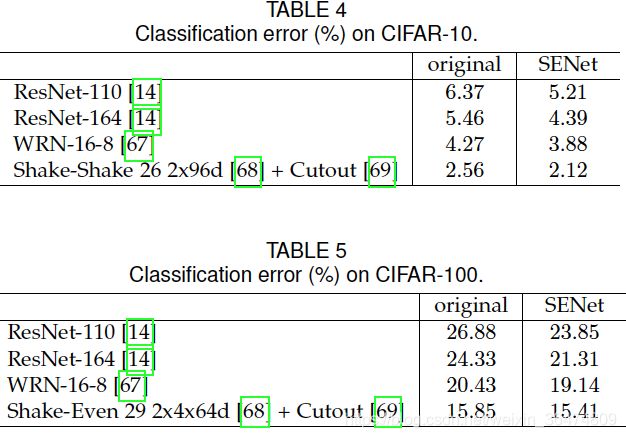
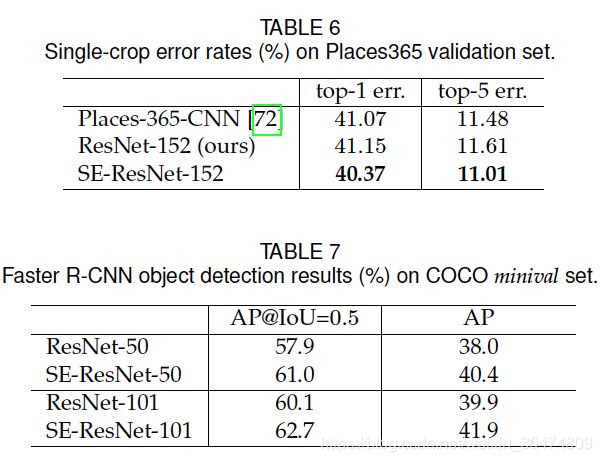
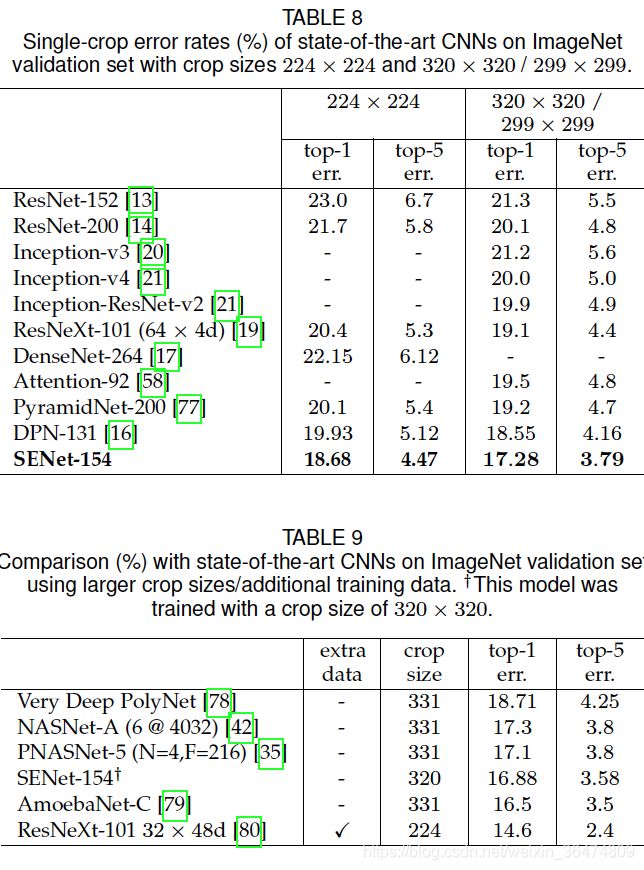
五、个人总结
模型中加入se-block之后能够更好的提取特征。