2017.1-2018.4低运算复杂度和存储复杂度的图像分类网络实现
背景:实现极小内存与运算资源占用下的手写字符、车标、人脸图像的识别。
以第一作者发表CCF B类会议ICASSP论文一篇:
Bindctnet: A Simple Binary Dct Network for Image Classification. ICASSP 2018: 1278-1282
目录
一、背景
1.1 应用场景
实际价值
理论价值
1.2 会议背景
1.3 贡献点
二、原理及公式
2.1 网络结构概览
2.2 特征提取阶段
DCT变换
聚能量效应
二维DCT变换
行列分解法与pruning algorithm
二值DCT变换
2.3 分类器阶段
分类器前特征提取
三、运算与存储消耗
3.1 卷积核的存储消耗
3.2 特征提取运算消耗
3.3 SVM分类器消耗
四、实验
4.1 数据集
4.2 准确率
4.3 运算与存储消耗
五、总结
一、背景
1.1 应用场景
实际价值
易于硬件部署,低内存占用,高速度,高帧率:
- 图像分类网络都具有层数较深,内存占用大,运算消耗大这些特点。特别是对于卷积来说,是一种运算密集型的操作。
- 但是在一些应用场景下,比如低端的硬件平台上,无论需要对小图像进行分类。因此需要较低的运算复杂度和存储复杂度。
- 再或者工厂流水线场景下,需要极快速的根据图像给出预测结果。
- 希望在尽可能低的成本下完成图像分类网络的部署,同时具有低 内存占用和高帧率的特点。
理论价值
深层的卷积神经网络对于图像的分类任务很有效果,也是主流趋势,但是浅层的图像分类网络能否达到较好的性能?
- 对于小图像来说,深层的网络并不能提升图像分类的性能,浅层的网络已经可以达到较好的结果。
几乎所有的神经网络均采用卷积的结构,可否舍弃卷积的结构来提取特征?
- 答案是可以的。比如运用这个项目中的DCT变换的方法来提取特征,既能降低运算量,也能较好的提取特征。
1.2 会议背景
ICASSP(International Conference on Acoustics, Speech and Signal Processing)即国际声学、语音与信号处理会议,是全世界最大的,也是最全面的信号处理及其应用方面的顶级会议。
信号处理领域比较强的会议Globecom, ICC, ICASSP,WCNC,VTC
ICASSP属于CCF B类会议,相当于SCI 2区。因为是会议论文,所以是EI检索。
1.3 贡献点
- 基底的存储复杂度,网络的内存开销:只用存一个一维的二值DCT基底,和线性SVM的超平面。
- 特征提权阶段由卷积操作替换为一维的二值DCT操作,乘法操作完全没有,加法操作缩减了十倍。
- 通过二值哈希与小块直方图提取特征,将featuremap的特征缩减。并且通过特征抽取进一步缩减。
- 在MNIST数据集和VLOVO数据集上达到了目前最佳的准确率。最快的速度。32×32的图像CPU预测帧率达200fps
二、原理及公式
2.1 网络结构概览

stage1 与stage2 两个阶段的特征提取阶段,将图像特征通过DCT变换提取出来。
stage 3 为特征提取阶段,通过二值哈希缩减feature map的数量,通过块直方图量化提取出feature。
2.2 特征提取阶段

DCT变换
https://baike.baidu.com/item/%E7%A6%BB%E6%95%A3%E4%BD%99%E5%BC%A6%E5%8F%98%E6%8D%A2/7118270?fr=aladdin
离散余弦变换(DCT for Discrete Cosine Transform)是与傅里叶变换相关的一种变换,它类似于离散傅里叶变换(DFT for Discrete Fourier Transform),但是只使用实数。离散余弦变换相当于一个长度大概是它两倍的离散傅里叶变换,这个离散傅里叶变换是对一个实偶函数进行的(因为一个实偶函数的傅里叶变换仍然是一个实偶函数)
聚能量效应
DCT变换之后的大值主要集中在低频部分,也与人的感知类似。人比较容易感知到低频的特征,所以图像分类中用低频的特征作为特征,因此可以用DCT变换的前几个DCT域的值,也就是频域低频的值作为提取出的特征。
如果是二维的DCT变换,聚能量效应让主要能量集中在左上角。
二维DCT变换

![]()
二维DCT变换相当于对一个patch进行两次一维的DCT变换。


可以直接用DCTMtx对小块进行变换,但真正感兴趣的是DCT变换后左上角的区域,所以可以选取DCTMtx前三行对Patch进行变换,节省一定的运算量。
行列分解法与pruning algorithm
- 行列分解法(RCM)RCM方法是将NxN数据按行(或列)方向进行N个1-D DCT计算,产生中间矩阵,然后对中间矩阵再按列(或行)方向进行N个1-D DCT计算,最后得到2-D DCT。
- 截断DCT算法(Purinng algorihtm) 输出仅需要 N0

二值DCT变换
二值DCT变换也具有DCT变换的性质,比如正交性和聚能量效应,并且浮点数的DCT运算更加节省内存消耗和运算消耗。


2.3 分类器阶段
分类器前特征提取
1)Hashing: 二值化

首先是对Second stage的每个卷积的结果做二值化,每一组得到L2张二值图片,对这L2张二值图片进行十进制编码,得到一张新的十进制图片,元素取值范围为[0, 2^L1-1]
2)Histogram:直方图统计

对每L1张图片做histBlock到vector的变换,这样就完成了一张图片的PCANet的特征提取。

3)SVM分类器
将列向量放到训练好的SVM中进行分类
三、运算与存储消耗
3.1 卷积核的存储消耗
神经网络的卷积核是二维且需要存储的。如果只通过DCT变换提取特征的话,只需要存储一维的卷积核。并且在二值化之后,更加节省内存。并且卷积核不用训练得出,只需存储一维的二值DCT的基底。只有(0,1,-1即可)
其中L1是第一层featuremap的层数,L2是第二层featuremap的层数。N是用于提取特征的patch的边长。实验之后一般取N=8.

3.2 特征提取运算消耗
mn是图像的大小。二维降为一维可以明显的缩小运算复杂度。并且二值DCT之后在矩阵中出现了大量的0值,更加简化运算。

3.3 SVM分类器消耗
所用分类器均为线性分类器。因此只用存储超平面即可。在经过了特征采样之后,SVM分类器的消耗进一步缩小。

四、实验
4.1 数据集
因为是小图像的分类问题,所以在MNIST数据集与VLOGO数据集上进行了我们的实验。


VLOGO vehicle logo dataset :a dataset of vehicle logos from top ten popular manufacturers
MNIST数据集为28×28大小,VLOGO被裁剪为32×32大小。
4.2 准确率
随着训练集的增大,网络在测试集上的测试误差迅速减小。

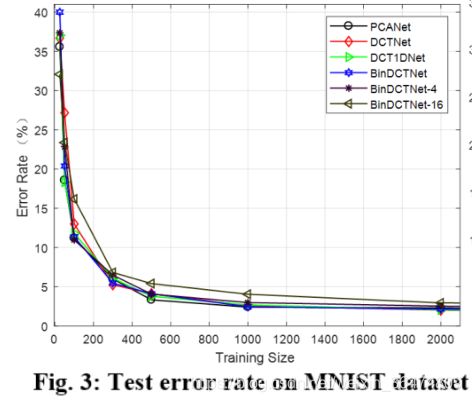


4.3 运算与存储消耗
可以看到,存储的SVM的支持向量的维度和网络参数非常小。



五、总结
运用1D-DCT替代2D-DCT,从实质上降低运算复杂度,二值DCT运算进行特征图获取,使特征图的获取不用浮点和乘法,变为基本的定点加法运算。
引入超参数Ɵ使存储近似降低为原来的 1⁄Ɵ。
在MNIST和VLOGO数据集上进行实验,准确率几乎state-of-the-art,几乎无参数存储,速度至少提升至少三倍,并且极易硬件实现