内容简要
人在家中坐,无聊天上来
背景:之前在不灵不灵大学学了MySQL、python等,回不去学校,也找不到工作,一直也没用的上
目的:获取疫情的所有数据信息,将数据存入数据库
意义:将存入数据库的数据用来练习Mysql和pandas的运用,以及matplotlib绘图或者pyecharts
技术路线:获取数据,简单整理,存入数据库,数据库取出数据
要求:了解requests和bs4的基本使用,熟悉python的数据结构,了解mysql的基本语法和pymysql的基本使用
收获:加深了requests和bs4的基本使用,熟悉了 爬取流程,以及数据存入的过程和出现的问题,包括数据取出遇到
的问题。
总结:本文主要针对简单的数据爬取和存入以及取出和绘图进行了流程介绍,其中的每个内容的具体部分不涉及,
本次的抓取主要是为了在mysql里数据练习基本操作,所绘图也是为了绘图而绘图,而在数据分析里,每次进行
操作必须有明确的目的。
目录:目录就不做了,内容也不多
注意:本内容设计的代码较多的是重复的,例如写入数据库,为的是,在复制运行的时候能够直接成功打到运行的目的。
参考:部分实现参考了咱们CSDN其他博主的文章,在此以以下格式表达感谢【refCSDN:文章号】
1.1 获取数据和清洗数据
主要包含了3各功能函数和1个主函数,分别是:获取页面,解析页面,提取信息和运行函数
需要一提的是在页面解析中“soup.find("script",{"id":"getAreaStat"}).get_text()”的使用,能够将script标签里的getAreaStat属性的内容全部获取出来,方便提取更多信息。
随后信息提取用到的多是列表索引和字典索引,进行嵌套列表和字典的取值。
import requests
from bs4 import BeautifulSoup
import datetime
def getHTMLText(url):
r = requests.get(url)
r.raise_for_status
r.encoding = "utf8"
return r.text
def parserPage(html):
soup = BeautifulSoup(html,"html.parser")
getAreaStat = soup.find("script",{"id":"getAreaStat"}).get_text()
getAreaStat = getAreaStat.replace("try ",'')
getAreaStat = getAreaStat.replace("catch(e){}",'')
getAreaStat = getAreaStat.replace(" window.getAreaStat = ",'"window.getAreaStat":')
getAreaStat = dict(eval(getAreaStat))
getAreaStat = getAreaStat["window.getAreaStat"]
return getAreaStat
def getProCitLists(dictry):
provinces = []
cities = []
for i in dictry:
provinces.append({"地区":i["provinceName"],"现存确诊":i["currentConfirmedCount"],"疑似病例":i["suspectedCount"],"累计确诊":i["confirmedCount"],"死亡":i["deadCount"],"治愈":i["curedCount"],"往日信息":i["statisticsData"],"描述":i["comment"],"信息获取时间":str(datetime.date.today()),"p_locationID":i["locationId"]})
if i["cities"]:
for info in i["cities"]:
cities.append({"地区":info["cityName"],"现存确诊":info["currentConfirmedCount"],"疑似病例":info["suspectedCount"],"累计确诊":info["confirmedCount"],"死亡":info["deadCount"],"治愈":info["curedCount"],"信息获取时间":str(datetime.date.today()),"c_locationID":info["locationId"],"所属":i["provinceName"]})
return provinces,cities
def main(url):
return getProCitLists(parserPage(getHTMLText(url)))
if __name__ == "__main__":
url = "https://3g.dxy.cn/newh5/view/pneumonia_peopleapp"
provinces_list,cities_list = main(url)
[{'地区': '香港',
'现存确诊': 672,
'疑似病例': 37,
'累计确诊': 862,
'死亡': 4,
'治愈': 186,
'往日信息': 'https://file1.dxycdn.com/2020/0223/331/3398299755968040033-135.json',
'描述': '',
'信息获取时间': '2020-04-05',
'p_locationID': 810000},
{}....]
[{'地区': '武汉',
'现存确诊': 644,
'疑似病例': 0,
'累计确诊': 50008,
'死亡': 2570,
'治愈': 46794,
'信息获取时间': '2020-04-05',
'c_locationID': 420100,
'所属': '湖北省'},
....{}]
1.2 获取往日信息存入字典
因为该信息是一个json文件链接格式,所以只需要获取到页面之后json.loads()下即可直接提取
import json
import requests
def getDictFromJson(url):
r = requests.get(url)
r.raise_for_status
r.encoding = "utf8"
return json.loads(r.text)
olddata = []
for i in provinces_list:
olddata.append({"p_locationID":i["p_locationID"],"往日信息":getDictFromJson(i["往日信息"])["data"]})
0
2 将cities_list数据写入Mysql
将数据分为不同的表,之间用locationID关联(也就是邮政编码),以便进行关联操作
通过pymysql与mysql连接,在写入之前要确认是否需要创建专一的库和表,表的字段和需要插入的数据是否一致
建议将创建表和库与插入数据的代码分开,以防止表成功创建内容插入错误出现一系列不必要的中断
在此提一下用到的多条信息插入的函数executemany(sql语句,列表嵌套列表或元组的多条数据)
多次整理数据其方法一致,就不再赘述,另外,其实可以将插入等功能封装成一个类,在这里就不花时间了,因为不常用
import pymysql
conn=pymysql.connect(host="127.0.0.1",port=3306,user="root",password="123qwe",charset="utf8")
cur = conn.cursor()
cur.execute("USE getareastat")
cur.execute("""CREATE TABLE IF NOT EXISTS cities_count(
c_locationID INT PRIMARY KEY,
现存确诊 INT,
疑似病例 INT,
累计确诊 INT,
治愈 INT,
死亡 INT,
所属 INT,
信息获取时间 varchar(20) )""")
data = []
for i in cities_list:
for info in provinces_list:
if i["所属"]==info["地区"] and i["c_locationID"] > 60:
data.append((i["c_locationID"],i["现存确诊"],i["疑似病例"],i["累计确诊"],i["治愈"],i["死亡"],info["p_locationID"],i["信息获取时间"]))
try:
sql = 'insert into cities_count values(%s, %s, %s,%s,%s,%s,%s,%s)'
cur.executemany(sql, data)
conn.commit()
print('成功...')
except Exception as e:
conn.rollback()
print("错误信息:", e)
cur.close()
conn.close()
成功...
3 将provinces_list数据写入Mysql
import pymysql
conn=pymysql.connect(host="127.0.0.1",port=3306,user="root",password="123qwe",charset="utf8")
cur = conn.cursor()
cur.execute("USE getareastat")
cur.execute("""CREATE TABLE IF NOT EXISTS provinces_count(
p_locationID INT PRIMARY KEY,
现存确诊 INT,
疑似病例 INT,
累计确诊 INT,
治愈 INT,
死亡 INT,
所属 INT,
信息获取时间 varchar(20) )""")
data = []
for i in provinces_list:
data.append((i["p_locationID"],i["现存确诊"],i["疑似病例"],i["累计确诊"],i["治愈"],i["死亡"],999999,i["信息获取时间"]))
print(data)
try:
sql = 'insert into provinces_count values(%s, %s, %s,%s,%s,%s,%s,%s)'
cur.executemany(sql, data)
conn.commit()
print('成功...')
except Exception as e:
conn.rollback()
print("错误信息:", e)
cur.close()
conn.close()
4 将描述信息数据写入Mysql
import pymysql
conn=pymysql.connect(host="127.0.0.1",port=3306,user="root",password="123qwe",charset="utf8")
cur = conn.cursor()
cur.execute("USE getareastat")
cur.execute("""CREATE TABLE IF NOT EXISTS pcnames(
locationID INT PRIMARY KEY,
地区 varchar(20)
)""")
data = []
for i in provinces_list:
data.append((i["p_locationID"],i["地区"]))
for i in cities_list:
if i["c_locationID"] > 60:
data.append((i["c_locationID"],i["地区"]))
print(data)
try:
sql = 'insert into pcnames values(%s, %s)'
cur.executemany(sql, data)
conn.commit()
print('成功...')
except Exception as e:
conn.rollback()
print("错误信息:", e)
cur.close()
conn.close()
[(810000, '香港'), ........ , (420000, '湖北省')]
成功...
4 将往日信息写入Mysql
import pymysql
conn=pymysql.connect(host="127.0.0.1",port=3306,user="root",password="123qwe",charset="utf8")
cur = conn.cursor()
cur.execute("USE getareastat")
data = []
for i in olddata:
for info in i["往日信息"]:
data.append((i["p_locationID"],info["confirmedCount"],info["confirmedIncr"],info["curedCount"],info["curedIncr"],info["currentConfirmedCount"],info["currentConfirmedIncr"],info["dateId"],info["deadCount"],info["deadIncr"],info["suspectedCount"],info["suspectedCountIncr"]))
try:
sql = 'insert into olddata values(%s, %s, %s,%s,%s,%s,%s,%s,%s,%s,%s,%s)'
cur.executemany(sql, data)
conn.commit()
print('成功...')
except Exception as e:
conn.rollback()
print("错误信息:", e)
cur.close()
conn.close()
成功...
5 从Mysql中选取数据
import pymysql
conn=pymysql.connect(host="127.0.0.1",port=3306,user="root",password="123qwe",charset="utf8")
cur = conn.cursor()
cur.execute("USE getareastat")
cur.execute("select p_locationID,现存确诊,地区 from provinces_count p left join pcnames pc on p.p_locationID = pc.locationID where 现存确诊 >100")
data = cur.fetchall()
6 将数据转为pandas
import pandas as pd
df = pd.DataFrame(data,columns = ['p_locationID','现存确诊',"地区"]).set_index("p_locationID")
df.head()
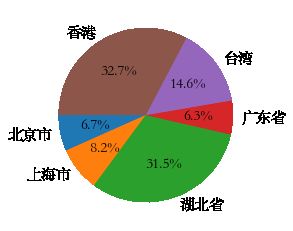
|
现存确诊 |
地区 |
| p_locationID |
|
|
| 110000 |
137 |
北京市 |
| 310000 |
169 |
上海市 |
| 420000 |
648 |
湖北省 |
| 440000 |
129 |
广东省 |
| 710000 |
300 |
台湾 |
df["现存确诊"]
df.loc[420000]
现存确诊 648
Name: 420000, dtype: int64
df["现存确诊"]
df.loc[420000]
现存确诊 648
地区 湖北省
Name: 420000, dtype: object
7 从pandas读取相关数据绘图_简单例子1
import matplotlib.pyplot as plt
import matplotlib as mat
mat.rcParams["font.family"]='STSong'
mat.rcParams['font.size']=15
a
plt.pie(df["现存确诊"],labels = df["地区"],autopct = "%0.1f%%",shadow = False,startangle=900)
plt.show()
7 从pandas读取相关数据绘图_简单例子2
import pymysql
conn=pymysql.connect(host="127.0.0.1",port=3306,user="root",password="123qwe",charset="utf8")
cur = conn.cursor()
cur.execute("USE getareastat")
cur.execute("select p_locationID,现存确诊,地区 from provinces_count p left join pcnames pc on p.p_locationID = pc.locationID")
data = cur.fetchall()
import pandas as pd
df = pd.DataFrame(data,columns = ['p_locationID','现存确诊',"地区"]).set_index("p_locationID")
df.head()
|
现存确诊 |
地区 |
| p_locationID |
|
|
| 110000 |
137 |
北京市 |
| 120000 |
33 |
天津市 |
| 130000 |
11 |
河北省 |
| 140000 |
5 |
山西省 |
| 150000 |
42 |
内蒙古自治区 |
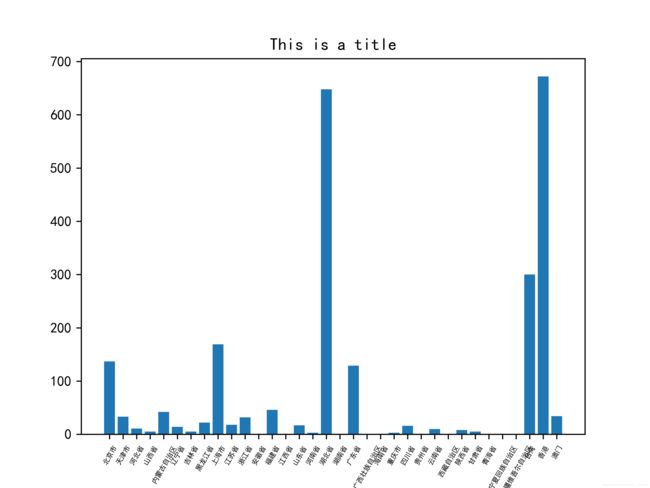
import matplotlib.pyplot as plt
import numpy as np
import pylab
import matplotlib
matplotlib.rcParams["font.family"] = "SimHei"
index_ls = list(df["地区"])
plt.bar([i for i in range(len(index_ls))], df["现存确诊"])
plt.xticks([i for i in range(len(index_ls))],index_ls)
plt.title('This is a title')
plt.xticks(fontsize=5)
pylab.xticks(rotation=60)
plt.savefig("D:/pick/test_1",dpi = 600)
plt.show()