Broker 怎么响应Consumer请求?
Broker 如何处理已经消费的消息?
Broker 的消息是 at least once还是exactly only once?
1.Broker 怎么响应Consumer请求
原理:
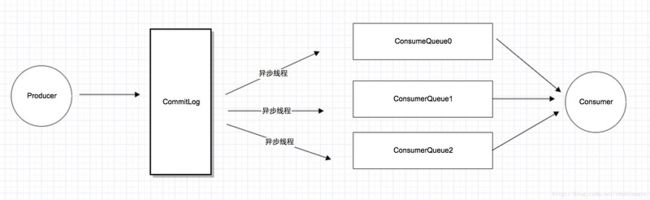
如上图所示,RocketMQ将所有消息都放在CommitLog里面,消费是维护一个ConsumeQueue帮助Consumer消费.pull操作要读两次,先读ConsumeQueue得到offset, 再读CommitLog得到消息内容.
BrokerController.initialize方法中会注册PullMessageProcessor来处理pull message 请求.
/**
* PullMessageProcessor
*/
this.remotingServer.registerProcessor(RequestCode.PULL_MESSAGE, this.pullMessageProcessor, this.pullMessageExecutor);
this.pullMessageProcessor.registerConsumeMessageHook(consumeMessageHookList);
在PullMessageProcessor.processRequest中又委托给DefaultMessageStore获取.
final GetMessageResult getMessageResult =
this.brokerController.getMessageStore().getMessage(requestHeader.getConsumerGroup(), requestHeader.getTopic(),
requestHeader.getQueueId(), requestHeader.getQueueOffset(), requestHeader.getMaxMsgNums(), subscriptionData);
进入DefaultMessageStore.getMessage之后会先通过topic和queueId获取对应的ConsumeQueue, 有了ConsumeQueue就可以操作逻辑队列.
ConsumeQueue consumeQueue = findConsumeQueue(topic, queueId);
public ConsumeQueue findConsumeQueue(String topic, int queueId) {
ConcurrentHashMap map = consumeQueueTable.get(topic);
if (null == map) {
ConcurrentHashMap newMap = new ConcurrentHashMap(128);
ConcurrentHashMap oldMap = consumeQueueTable.putIfAbsent(topic, newMap);
if (oldMap != null) {
map = oldMap;
} else {
map = newMap;
}
}
ConsumeQueue logic = map.get(queueId);
if (null == logic) {
ConsumeQueue newLogic = new ConsumeQueue(//
topic, //
queueId, //
StorePathConfigHelper.getStorePathConsumeQueue(this.messageStoreConfig.getStorePathRootDir()), //
this.getMessageStoreConfig().getMapedFileSizeConsumeQueue(), //
this);
ConsumeQueue oldLogic = map.putIfAbsent(queueId, newLogic);
if (oldLogic != null) {
logic = oldLogic;
} else {
logic = newLogic;
}
}
return logic;
}
获取到ConsumeQueue之后, 会判断offset的合理性.
minOffset = consumeQueue.getMinOffsetInQuque();
maxOffset = consumeQueue.getMaxOffsetInQuque();
if (maxOffset == 0) {
status = GetMessageStatus.NO_MESSAGE_IN_QUEUE;
nextBeginOffset = nextOffsetCorrection(offset, 0);
} else if (offset < minOffset) {
status = GetMessageStatus.OFFSET_TOO_SMALL;
nextBeginOffset = nextOffsetCorrection(offset, minOffset);
} else if (offset == maxOffset) {
status = GetMessageStatus.OFFSET_OVERFLOW_ONE;
nextBeginOffset = nextOffsetCorrection(offset, offset);
} else if (offset > maxOffset) {
status = GetMessageStatus.OFFSET_OVERFLOW_BADLY;
if (0 == minOffset) {
nextBeginOffset = nextOffsetCorrection(offset, minOffset);
} else {
nextBeginOffset = nextOffsetCorrection(offset, maxOffset);
}
} else {
//消费位置合法
}
消费的位置合法, 那么就从consumeQueue中获取SelectMapedBufferResult(封装了bytebuffer).
SelectMapedBufferResult bufferConsumeQueue = consumeQueue.getIndexBuffer(offset);
//ConsumeQueue.getIndexBuffer
public SelectMapedBufferResult getIndexBuffer(final long startIndex) {
int mapedFileSize = this.mapedFileSize;
long offset = startIndex * CQStoreUnitSize;
if (offset >= this.getMinLogicOffset()) {
MapedFile mapedFile = this.mapedFileQueue.findMapedFileByOffset(offset);
if (mapedFile != null) {
SelectMapedBufferResult result = mapedFile.selectMapedBuffer((int) (offset % mapedFileSize));
return result;
}
}
return null;
}
逻辑队列中一个数据的大小是20, 所以真正的offset需要乘以20, 然后获取对应的MapedFile.
获取到SelectMapedBufferResult之后, 就可以读取消息了, 代码中是一个循环.
if (bufferConsumeQueue != null) {
try {
status = GetMessageStatus.NO_MATCHED_MESSAGE;
long nextPhyFileStartOffset = Long.MIN_VALUE;
long maxPhyOffsetPulling = 0;
int i = 0;
final int MaxFilterMessageCount = 16000;
final boolean diskFallRecorded = this.messageStoreConfig.isDiskFallRecorded();
for (; i < bufferConsumeQueue.getSize() && i < MaxFilterMessageCount; i += ConsumeQueue.CQStoreUnitSize) {
long offsetPy = bufferConsumeQueue.getByteBuffer().getLong();
int sizePy = bufferConsumeQueue.getByteBuffer().getInt();
long tagsCode = bufferConsumeQueue.getByteBuffer().getLong();
maxPhyOffsetPulling = offsetPy;
// 说明物理文件正在被删除
if (nextPhyFileStartOffset != Long.MIN_VALUE) {
if (offsetPy < nextPhyFileStartOffset)
continue;
}
// 判断是否拉磁盘数据
boolean isInDisk = checkInDiskByCommitOffset(offsetPy, maxOffsetPy);
// 此批消息达到上限了
if (this.isTheBatchFull(sizePy, maxMsgNums, getResult.getBufferTotalSize(), getResult.getMessageCount(),
isInDisk)) {
break;
}
// 消息过滤
if (this.messageFilter.isMessageMatched(subscriptionData, tagsCode)) {
SelectMapedBufferResult selectResult = this.commitLog.getMessage(offsetPy, sizePy);
if (selectResult != null) {
this.storeStatsService.getGetMessageTransferedMsgCount().incrementAndGet();
getResult.addMessage(selectResult);
status = GetMessageStatus.FOUND;
nextPhyFileStartOffset = Long.MIN_VALUE;
} else {
if (getResult.getBufferTotalSize() == 0) {
status = GetMessageStatus.MESSAGE_WAS_REMOVING;
}
// 物理文件正在被删除, 尝试跳过
nextPhyFileStartOffset = this.commitLog.rollNextFile(offsetPy);
}
} else {
if (getResult.getBufferTotalSize() == 0) {
status = GetMessageStatus.NO_MATCHED_MESSAGE;
}
if (log.isDebugEnabled()) {
log.debug("message type not matched, client: " + subscriptionData + " server: " + tagsCode);
}
}
}
if (diskFallRecorded) {
long fallBehind = maxOffsetPy - maxPhyOffsetPulling;
brokerStatsManager.recordDiskFallBehindSize(group, topic, queueId, fallBehind);
}
nextBeginOffset = offset + (i / ConsumeQueue.CQStoreUnitSize);
long diff = maxOffsetPy - maxPhyOffsetPulling;
long memory = (long) (StoreUtil.TotalPhysicalMemorySize
* (this.messageStoreConfig.getAccessMessageInMemoryMaxRatio() / 100.0));
getResult.setSuggestPullingFromSlave(diff > memory);
} finally {
bufferConsumeQueue.release();
}
} else {
status = GetMessageStatus.OFFSET_FOUND_NULL;
nextBeginOffset = nextOffsetCorrection(offset, consumeQueue.rollNextFile(offset));
log.warn("consumer request topic: " + topic + "offset: " + offset + " minOffset: " + minOffset + " maxOffset: "
+ maxOffset + ", but access logic queue failed.");
}
}
逻辑队列是大小为20, 每次+20. 关于MappedFile的操作可以参考RocketMQ源码阅读(四)-消息存储二,
根据consumequeue的结构, 可以知道由3部分组成, 那么依次取出来commitlog offset, size, tag然后根据拿tag和SubscriptionData进行比对, 进行过滤消息消息匹配之后, 有了offset和size, 则可以调用 commitlog 的getMessage 方法获取 SelectMapedBufferResult (获取过程和上面说的getIndexBuffer类似), 然后将 SelectMapedBufferResult 添加到GetMessageResult 中.
退出循环后, 会计算下次的offset, 放到GetMessageResult中返回.
当pullMessageProcessor获取到GetMessageResult, 然后将消息体, 下次访问的offset等设置到response中返回.
2. Broker 如何处理已经消费的消息
由于RocketMQ操作CommitLog, ConsumeQueue文件, 都是基于内存映射方法并在启动的时候, 会加载commitlog, ConsumeQueue目录下的所有文件, 为了避免内存与磁盘的浪费, 不可能将消息永久存储在消息服务器上, 所以需要一种机制来删除已过期的文件. RocketMQ顺序写Commitlog、ConsumeQueue文件, 所有写操作全部落在最后一个CommitLog或ConsumeQueue文件上, 之前的文件在下一个文件创建后, 将不会再被更新,RocketMQ清除过期文件的方法是: 如果非当前写文件在一定时间间隔内没有再次被更新, 则认为是过期文件, 可以被删除, RocketMQ不会管这个这个文件上的消息是否被全部消费. 默认每个文件的过期时间为72小时. 通过在Broker配置文件中设置fileReservedTime来改变过期时间, 单位为小时. 接下来详细分析RocketMQ是如何设计与实现上述机制的.
Broker在启动时加入一个定时任务.
this.scheduledExecutorService.scheduleAtFixedRate(new Runnable() {
@Override
public void run() {
DefaultMessageStore.this.cleanFilesPeriodically();
}
}, 1000 * 60, this.messageStoreConfig.getCleanResourceInterval(), TimeUnit.MILLISECONDS);
RocketMQ会每隔10s调度一次cleanFilesPeriodically, 检测是否需要清除过期文件. 执行频率可以通过设置cleanResourceInterval, 默认为10s.
DefaultMessageStore#cleanFilesPeriodically
private void cleanFilesPeriodically() {
this.cleanCommitLogService.run();
this.cleanConsumeQueueService.run();
}
主要清除CommitLog、ConsumeQueue的过期文件.
CommitLog与ConsumeQueue对于过期文件的删除算法、逻辑大同小异, 本文将以CommitLog过期文件为例来详细分析其实现原理.
DefaultMessageStore$CleanCommitLogService#run
public void run() {
try {
this.deleteExpiredFiles();
this.redeleteHangedFile();
} catch (Throwable e) {
DefaultMessageStore.log.warn(this.getServiceName() + " service has
exception. ", e);
}
}
整个执行过程分为两个大的步骤, 第一个步骤: 尝试删除过期文件;第二个步骤: 重试删除被hange(由于被其他线程引用在第一阶段未删除的文件), 在这里再重试一次.
DefaultMessageStore$CleanCommitLogService#deleteExpiredFiles
long fileReservedTime = DefaultMessageStore.this.getMessageStoreConfig().getFileReservedTime();
int deletePhysicFilesInterval = DefaultMessageStore.this.getMessageStoreConfig().getDeleteCommitLogFilesInterval();
int destroyMapedFileIntervalForcibly = DefaultMessageStore.this.getMessageStoreConfig().getDestroyMapedFileIntervalForcibly();
Step1: 解释一下这个三个配置属性的含义.
fileReservedTime: 文件保留时间, 也就是从最后一次更新时间到现在, 如果超过了该时间, 则认为是过期文件, 可以被删除.
deletePhysicFilesInterval: 删除物理文件的间隔, 因为在一次清除过程中, 可能需要删除的文件不止一个, 该值指定两次删除文件的间隔时间.
destroyMapedFileIntervalForcibly: 在清除过期文件时, 如果该文件被其他线程所占用(引用次数大于0, 比如读取消息), 此时会阻止此次删除任务,
同时在第一次试图删除该文件时记录当前时间戳, destroyMapedFileIntervalForcibly 表示第一次拒绝删除之后能保留的最大时间, 在此时间内, 同样可以被拒绝删除, 同时会将引用减少1000个, 超过该时间间隔后, 文件将被强制删除.
DefaultMessageStore$CleanCommitLogService#deleteExpiredFiles:
boolean timeup = this.isTimeToDelete();
boolean spacefull = this.isSpaceToDelete();
boolean manualDelete = this.manualDeleteFileSeveralTimes > 0;
if (timeup || spacefull || manualDelete) {
//继续执行删除逻辑
return;
} else {
// 本次删除任务无作为.
}
Step2: RocketMQ在如下三种情况任意满足之一的情况下将继续执行删除文件操作.
1)到了删除文件的时间点, RocketMQ通过deleteWhen设置一天的固定时间执行一次删除过期文件操作, 默认为凌晨4点.
2)判断磁盘空间是否充足, 如果不充足, 则返回true, 表示应该触发过期文件删除操作.
3)预留, 手工触发, 可以通过调用excuteDeleteFilesManualy方法手工触发过期文件删除, 目前RocketMQ暂未封装手工触发文件删除的命令.
重点分析一下磁盘不足的判断依据.
DefaultMessageStore$CleanCommitLogService#isSpaceToDelete
private boolean isSpaceToDelete() {
double ratio = DefaultMessageStore.this.getMessageStoreConfig().getDiskMaxUsedSpaceRatio() / 100.0; //@1
cleanImmediately = false;
{
String storePathPhysic = DefaultMessageStore.this.getMessageStoreConfig().getStorePathCommitLog(); //@2
double physicRatio = UtilAll.getDiskPartitionSpaceUsedPercent(storePathPhysic); //@3
if (physicRatio > diskSpaceWarningLevelRatio) {
boolean diskok = DefaultMessageStore.this.runningFlags.getAndMakeDiskFull();
if (diskok) {
DefaultMessageStore.log.error("physic disk maybe full soon " + physicRatio + ", so mark disk full");
}
cleanImmediately = true;
} else if (physicRatio > diskSpaceCleanForciblyRatio) {
cleanImmediately = true;
} else {
boolean diskok = DefaultMessageStore.this.runningFlags.getAndMakeDiskOK();
if (!diskok) {
DefaultMessageStore.log.info("physic disk space OK " + physicRatio + ", so mark disk ok");
}
}
if (physicRatio < 0 || physicRatio > ratio) {
DefaultMessageStore.log.info("physic disk maybe full soon, so reclaim space, " + physicRatio);
return true;
}
}
{
String storePathLogics = StorePathConfigHelper
.getStorePathConsumeQueue(DefaultMessageStore.this.getMessageStoreConfig().getStorePathRootDir());
double logicsRatio = UtilAll.getDiskPartitionSpaceUsedPercent(storePathLogics);
if (logicsRatio > diskSpaceWarningLevelRatio) {
boolean diskok = DefaultMessageStore.this.runningFlags.getAndMakeDiskFull();
if (diskok) {
DefaultMessageStore.log.error("logics disk maybe full soon " + logicsRatio + ", so mark disk full");
}
cleanImmediately = true;
} else if (logicsRatio > diskSpaceCleanForciblyRatio) {
cleanImmediately = true;
} else {
boolean diskok = DefaultMessageStore.this.runningFlags.getAndMakeDiskOK();
if (!diskok) {
DefaultMessageStore.log.info("logics disk space OK " + logicsRatio + ", so mark disk ok");
}
}
if (logicsRatio < 0 || logicsRatio > ratio) {
DefaultMessageStore.log.info("logics disk maybe full soon, so reclaim space, " + logicsRatio);
return true;
}
}
return false;
}
代码@1: 获取maxUsedSpaceRatio, 表示commitlog、consumequeue文件所在磁盘分区的最大使用量, 如果超过该值, 则需要立即清除过期文件.
代码@2: 通过File#getTotalSpace()获取commitlog所在磁盘分区总的存储容量, 通过File#getFreeSpace()获取commitlog目录所在磁盘文件剩余容量并得出当前该分区的物理磁盘使用率physicRatio .
代码@3: RocketMQ另外提供了两个与磁盘空间使用率相关的系统级参数:
-Drocketmq.broker.diskSpaceWarningLevelRatio=0.90: 如果磁盘分区使用率超过该阔值, 将设置磁盘不可写, 此时会拒绝新消息的写入.
-Drocketmq.broker.diskSpaceCleanForciblyRatio=0.85: 如果磁盘分区使用超过该阔值, 建议立即执行过期文件清除, 但不会拒绝新消息的写入.
判断磁盘是否可用, 用当前已使用物理磁盘率maxUsedSpaceRatio、diskSpaceWarningLevelRatio、diskSpaceCleanForciblyRatio, 如果当前磁盘使用率达到上述阔值, 将返回true表示磁盘已满, 需要进行过期文件删除操作.
Step3: 然后根据文件的最后一次更新时间与当前时间做比较, 判断是否过期, 如果已过期, 调用MappedFile的destory.
关于ConsumeQueue的过期文件删除机制与Commitlog文件机制类似, 本文就不重复讲解.
Broker 的消息是 at least once还是exactly only once?
at least once:
- 是指每个消息必须投递一次,RocketMQ Consumer 先 pull 消息到本地, 消费完成后, 才向服务器返回 ack, 如果没有消费一定不会ack消息, 所以RocketMQ可以很好的支持此特性.
exactly only once:
- (1). 发送消息阶段, 不允许发送重复的消息.
- (2). 消费消息阶段, 不允许消费重复的消息. 只有以上两个条件都满足情况下, 才能认为消息是"Exactly Only Once", 而要实现以上两点, 在分布式系统环境下, 不可避免要产生巨大的开销. 所以 RocketMQ 为了追求高性能, 并不保证此特性, 要求在业务上进行去重, 也就是说消费消息要做到幂等性. RocketMQ 虽然不能严格保证不重复, 但是正常情况下很少会出现重复发送、消 费情况, 只有网络异常, Consumer 启停等异常情况下会出现消息重复. 此问题的本质原因是网络调用存在不确定性, 即既不成功也不失败的第三种状态, 所以才产生了消息重复性问题.
参考:
https://segmentfault.com/a/1190000011042216
https://blog.csdn.net/prestigeding/article/details/79482339