Hbase的详细介绍及底层原理
一、hbase介绍
- hbase的产生背景:
当数据量过于庞大的时候 数据的快速查询是很难实现的
GFS-------分布式存储的
MAPERREDUCE------分布式计算的
BIGTABLE------分布式数据库 快速查询 - hbase是什么?
hbase是一个分布式的列式存储数据库 nosql的数据库
1)no sql hbase不支持标准sql 不支持sql语句的,基于hbase之上对外提供标准sql的组件 phoenix
2)ont only sql
列式存储 :面向列的存储
存数的时候是以’列’为单位进行存储的 假设hbase中存储的数据 stuid,name,sex,age,department 每一个‘列’会单独存储一个物理文件
一行的数据会分割在多个文件中存储。 优点:
mysql进行数据查询的时候
select id,name from stu; 减少数据查询的时候的数据的扫描范围 提示查询性能 存储的时候比较方便。
mysql、oracle、sqlserver…传统的关系型数据库 面向行存储的
mysql:user----name,password,host 同一行的数据肯定在一个物理存储文件中,同一行数据是不会被拆分存储的。
hbase的设计思想
面向列存储 可以实现一个进实时的查询一个分布式(存储数据量的)数据库。
1.HBase是什么?
hbase是一种Nosql的分布式数据存储系统。具有可靠性,高能性,列存储,可伸缩的征,可以对大型数据进行实时、随机的读写访问。
2.应用场景
- 需要存储半结构化和非结构化数据时
- 记录中含null
- 需要存储变动历史记录的数据
- 数据量超大的数据
3.Hbase的注意事项:
- 1.Hbase只能通过主键(rowkey)和主键的range来检索数据
- 2.不支持join
- 3.不支持复杂的事务
- 4.只能支持数据类型:byte[]数组
4.HBase中表的特点
-
1.大 :
-
2.面向列:通过列进行检索
-
3.稀疏:空的(null)的数据所在的列,不占存储空间
-
4.无模式:包含的列的个数可以不一致,也可以不确定,可以随机指定
5.HBase表的结构(相当于四维表,row key 和family对应的数据是一个二维表(列和记录))
-
1)行键:就是用来访问HBase中的行 ,相当于Sql中的主键。 Hbase会对表中的数据按照行键进行排序(字典顺序)。
-
2)列簇:就是一组列的集合,在建表的时候指定
6、Hbase的集群结构(主从架构)
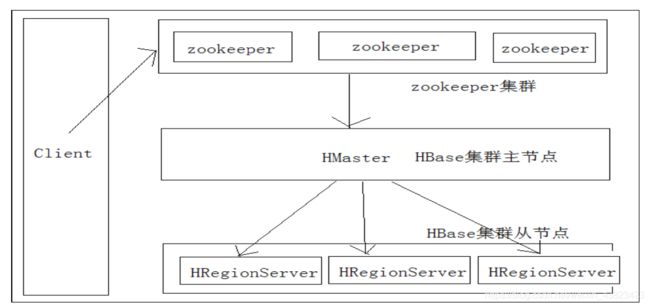
region:是hbase对表进行切割的单位。
hmaster:是hbase功能上的主节点,不是状态的主节点,如果master宕机,增删改不能用,查询可以使用。在region进行切分的时候负责负载均衡
regionserver:hbase中真正负责管理region的服务器。
zookeeper:负责集群节点之间的上下线感知
HDFS:存储hbase的表。

二、Hbase的API
1.基本套路
/**
* 这是hbase的java api的第一个代码
* @throws IOException
* */
public static void main(String[] args) throws IOException {
/*
* 获取一个配置对象
*
* 要点:获取配置信息之后,就一定要告诉这个配置对象,说接下来要创建的连接是哪个hbase集群的连接
*
* */
Configuration config = HBaseConfiguration.create();
config.set("hbase.zookeeper.quorum", "qyl01:2181,qyl02:2181,qyl03:2181");
/**
* 通过配置对象创建连接
* */
Connection connection = ConnectionFactory.createConnection(config);
/**
* 通过连接获取管理员对象
* */
Admin admin=connection.getAdmin();
/**
* 通过管理员对象就可以对表进行各种操作
* */
HTableDescriptor[] listTables = admin.listTables();
/**
* 针对结果进行处理
* */
for(HTableDescriptor list:listTables){
System.out.println(list.getNameAsString());
}
connection.close();
}
2.数据的导入和导出
1)hbase数据写入hdfs形成一个结构化的二维表
思路:(用scan)
用TableMaprReduceUtill类的initTableMapperJob方法获取habse表中的每一行的result(通过scan查询),
将其结果作为Map中的value值,然后用Cell接收,通过CellUtil中的方法获取每一行的rowkey和family等,写入到hdfs中(整个过程不需要reduce的参与)
2)将hdfs上的数据转成hbase(用put)
思路:map方法获取表的数据
reduce将表中的数据以表中的第一个字段为rowkey,其余字段为列,写入到一个hbase表特定的列簇中.
3)mysql 数据导入到 hbase
jdbc:mysql://hadoop01/mytest
--username root
--password root
--table student
--hbase-table studenttest1
--column-family name
--hbase-row-key id
4)hbase 数据导入到 mysql(没有直接的命令)
可以把hbase的数据导入到hdfs中,然后再导入到mysql中。
5)HBase整合hive
create external table mingxing(rowkey string, base_info map, extra_info
map)
创建的字段类型为map类型
select * from mingxing;
select rowkey,base_info['name'] from mingxing;
select rowkey,extra_info['province'] from mingxing;
select rowkey,base_info['name'], extra_info['province'] from mingxing;
三、HBase的底层原理
1、系统架构
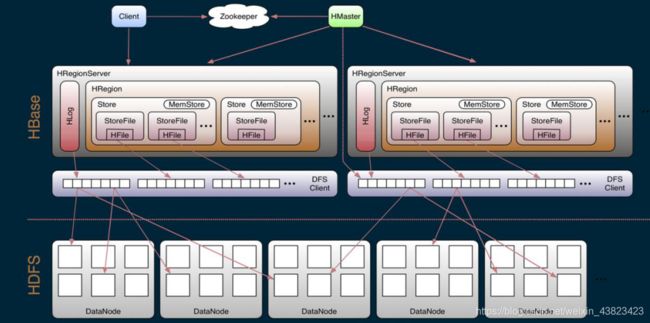
1.HBase有两张特殊的表:
- .META:记录用户所有表拆分出来的Region映射的信息,META可以有多个Region
-ROOT-:记录.META表的Region信息, -ROOT-只有一个Region
各个组件的职责:
Client的职责:
- client访问用户数据前需要先访问Zookeeper,找到-ROOT-表的Region所在的位置后访问-ROOT-表,接着访问.MATE表,最后找到用户数据的位置去访问。
Zookeeper职责:
- 1.为Hbase提供选举机制,选举Mster
2.存储寻址入口(-ROOT-的位置)
3.实时监控RegionServer的状态,通过创建读锁
4.存储Hase的Schema,表,视图等
Master的职责:
- 1.为RegionServer分配Region
2.负责RegionServe的负载均衡
3.发现失效的RegionServer并重新分配其上的Region
4.处理数据库对象的更新请求
RegionServer职责:
- 1.负责真正的读写请求
2.负责和底层的文件系统HDFS的交互,存储数据到HDFS
3.负责Store和HFile的合并工作
2、物理架构
- 1、Table 中的所有行都按照 RowKsey 的字典序排列。
- 2、Table 在行的方向上分割为多个 HRegion。
- 3、HRegion 按大小分割的(默认 10G),每个表一开始只有一个 HRegion,随着数据不插入表,HRegion 不断增大,当增大到一个阀值的时候,HRegion 就会等分会两个新的HRegion。当表中的行不断增多,就会有越来越多的 HRegion。
- 4、HRegion 是 Hbase 中分布式存储和负载均衡的最小单元。最小单元就表示不同的 HRegion可以分布在不同的 HRegionServer 上。但一个 HRegion 是不会拆分到多个 server 上的。
- 5、HRegion 虽然是负载均衡的最小单元,但并不是物理存储的最小单元。事实上,HRegion由一个或者多个 Store 组成,每个
Store 保存一个 Column Family。每个 Strore 又由一个MemStore 和 0 至多个 StoreFile 组成
StoreFile和Hfile结构
StoreFile 以 HFile 格式保存在 HDFS 上,请看下图 HFile 的数据组织格式:

HFile 分为六个部分:
- Data Block 段–保存表中的数据,这部分可以被压缩
- Meta Block 段 (可选的)–保存用户自定义的 kv 对,可以被压缩。
- File Info 段–Hfile 的元信息,不被压缩,用户也可以在这一部分添加自己的元信息。
- Data Block Index 段–Data Block 的索引。每条索引的 key 是被索引的 block 的第一条记录的 key。
- Meta Block Index 段 (可选的)–Meta Block 的索引。
- Trailer 段–这一段是定长的。保存了每一段的偏移量,读取一个 HFile 时,会首先读取 Trailer,
Trailer保存了每个段的起始位置(段的Magic Number用来做安全check),然后,DataBlockIndex会被读取到内存中,这样,当检索某个 key 时,不需要扫描整个 HFile,而只需从内存中找到key所在的block,通过一次磁盘io将整个block读取到内存中,再找到需要的key。DataBlockIndex 采用 LRU 机制淘汰。
HFile 的 Data Block,Meta Block 通常采用压缩方式存储,压缩之后可以大大减少网络 IO 和磁盘 IO,随之而来的开销当然是需要花费 cpu 进行压缩和解压缩。
目标 Hfile 的压缩支持两种方式:Gzip,LZO。
3、寻址机制

流程:
- 第 1 步:Client 请求 ZooKeeper 获取.META.所在的 RegionServer 的地址。
- 第 2 步:Client 请求.META.所在的 RegionServer 获取访问数据所在的 RegionServer
地址,Client会将.META.的相关信息 cache 下来,以便下一次快速访问。 - 第 3 步:Client 请求数据所在的 RegionServer,获取所需要的数据。
四、HBase高级应用
.1、建表高级属性
下面几个 shell 命令在 HBase 操作中可以起到很到的作用,且主要体现在建表的过程中,看
下面几个 create 属性
1、 BLOOMFILTER(布隆过滤器)
- 默认是 NONE 是否使用布隆过虑及使用何种方式,布隆过滤可以每列族单独启用 使用
HColumnDescriptor.setBloomFilterType(NONE | ROW | ROWCOL)
对列族单独启用布隆Default = ROW 对行进行布隆过滤 对 ROW,行键的哈希在每次插入行时将被添加到布隆 对 ROWCOL,行键 列族 + 列族修饰的哈希将在每次插入行时添加到布隆 使用方法: create ‘table’,{NAME => ‘baseinfo’ BLOOMFILTER => ‘ROW’} 作用:用布隆过滤可以节省读磁盘过程,可以有助于降低读取延迟
2、 VERSIONS(版本号)
- 默认是 1 这个参数的意思是数据保留 1 个 版本,如果我们认为我们的数据没有这么大
的必要保留这么多,随时都在更新,而老版本的数据对我们毫无价值,那将此参数设为 1能 节约 2/3 的空间
使用方法: create ‘table’,{ NAME => ‘baseinfo’ VERSIONS=>‘2’}
3、 COMPRESSION(压缩)
默认不使用压缩,建议采用SNAPP压缩算法
设置:create ‘table’,{NAME=>‘info’,COMPRESSION=>‘SNAPPY’}

2、表设计
1、列簇设计
追求的原则是:在合理范围内能尽量少的减少列簇就尽量减少列簇。
最优设计是:将所有相关性很强的 key-value 都放在同一个列簇下,这样既能做到查询效率最高,也能保持尽可能少的访问不同的磁盘文件
2、RowKey 设计
HBase 中,表会被划分为 1…n 个 Region,被托管在 RegionServer 中。Region 二个重要的
属性:StartKey 与 EndKey 表示这个 Region 维护的 rowKey 范围,当我们要读/写数据时,如果 rowKey 落在某个 start-end key 范围内,那么就会定位到目标 region 并且读/写到相关的数据
RowKey设计的三原则
一、 rowkey 长度原则
- Rowkey 是一个二进制码流,Rowkey 的长度被很多开发者建议说设计在 10~100 个字节,不过建议是越短越好,不要超过 16
个字节。
原因如下:
- 1、数据的持久化文件 HFile 中是按照 KeyValue 存储的,如果 Rowkey 过长比如 100 个字 节,1000 万列数据光
Rowkey 就要占用 100*1000 万=10 亿个字节,将近 1G 数据,这会极大影响 HFile 的存储效率; - 2、MemStore 将缓存部分数据到内存,如果 Rowkey 字段过长内存的有效利用率会降低,
系统将无法缓存更多的数据,这会降低检索效率。因此 Rowkey 的字节长度越短越好。 - 3、目前操作系统是都是 64 位系统,内存 8 字节对齐。控制在 16 个字节,8 字节的整数 倍利用操作系统的最佳特性。
二、rowkey 散列原则
- 如果 Rowkey 是按时间戳的方式递增,不要将时间放在二进制码的前面,建议将 Rowkey 的高位作为散列字段,由程序循环生成,低位放时间字段,这样将提高数据均衡分布在每个 Regionserver 实现负载均衡的几率。如果没有散列字段,首字段直接是时间信息将产生所有 新数据都在一个 RegionServer
上堆积的热点现象,这样在做数据检索的时候负载将会集中 在个别 RegionServer,降低查询效率。
三、 rowkey 唯一原则
- 必须在设计上保证其唯一性。rowkey 是按照字典顺序排序存储的,因此,设计 rowkey
的时候,要充分利用这个排序的特点,将经常读取的数据存储到一块,将最近可能会被访问的数据放到一块。