- 安装Qt 5.15.2
noodleboy
qt
安装Qt5.15.2自Qt5.15开始,Qt不提供离线安装包了,需要使用在线安装器安装,但是Qt5.15版本不直接显示。需要勾选Archive选项,且很有可能需要梯子工具。
- Sqoop安装部署
愿与狸花过一生
大数据sqoophadoophive
ApacheSqoop简介Sqoop(SQL-to-Hadoop)是Apache开源项目,主要用于:将关系型数据库中的数据导入Hadoop分布式文件系统(HDFS)或相关组件(如Hive、HBase)。将Hadoop处理后的数据导出回关系型数据库。核心特性批量数据传输支持从数据库表到HDFS/Hive的全量或增量数据迁移。并行化处理基于MapReduce实现并行导入导出,提升大数据量场景的效率。自
- Mysql-经典实战案例(10):如何用PT-Archiver完成大表的自动归档
从不删库的DBA
Mysql经典实战案例mysql数据库
真实痛点:电商订单表存储优化场景现状分析某电商平台订单表(order_info)每月新增500万条记录主库:高频读写,SSD存储(空间告急)历史库:HDD存储,只读查询优化目标✅自动迁移7天前的订单到历史库✅每周六23:30执行,不影响业务高峰✅确保数据一致性第一章:前期准备:沙盒实验室搭建1.1实验环境架构生产库:10.33.112.22历史库:10.30.76.41.2环境初始化(双节点执行)
- Hive面试题
御风行云天
面试题大全hivehadoop数据仓库面试
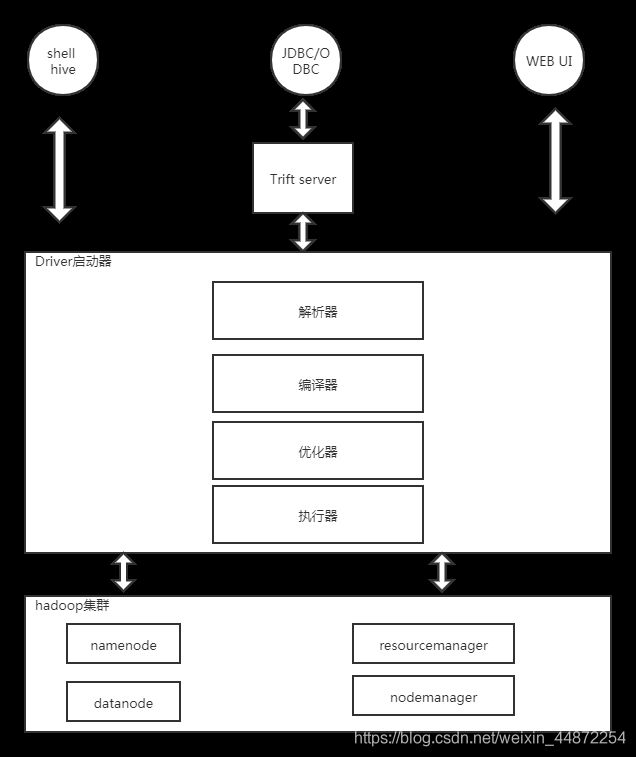
Hive面试题1Hive基础概念1.1解释Hive是什么以及它的用途Hive的主要用途:1.2描述Hive架构和组件1.HiveCLI/Beeline和WebUI2.HiveQL3.HiveDriver(驱动)4.Metastore5.Compiler(编译器)6.Optimizer(优化器)7.Executor(执行器)8.HadoopCoreComponents(核心组件)9.HiveUDFs
- Hive 实际应用场景及对应SQL示例
小技工丨
大数据随笔hivesqlhadoop大数据数据仓库
Hive实际应用场景及对应SQL示例一、日志分析场景**场景说明:**处理大规模日志数据(如Web访问日志),分析用户行为或系统运行状态。SQL示例:--统计每日UV(用户访问量)SELECTdate,COUNT(DISTINCTuser_id)ASdaily_uvFROMweb_logsWHEREevent_type='page_view'GROUPBYdate;技术要点:使用DIST
- #Hadoop全分布式安装 #mysql安装 #hive安装
砸吧砸吧
hadoophiveyarnmysql
分布式(多台机器部署不同组件)与集群(多台机器部署相同组件)概念。Linux基础命令linux具有文件数:目录、文件,从根目录开始,路径具有唯一性。pwd:显示当前路径特殊符号:/:根目录.:隐藏文件,如果路径以.开始,表示当前目录下..:当前目录下的上一级~:当前目录的home目录--help:帮助命令使用linux常用操作命令tab键:自动补全ls:显示指定目录内容默认:当前路径-a:显示所有
- hive 使用oracle数据库
sardtass
hadoophive开源项目
hive使用oracle作为数据源,导入数据使用sqoop或kettle或自己写代码(淘宝的开源项目中有一个xdata就是淘宝自己写的)。感觉sqoop比kettle快多了,淘宝的xdata没用过。hive默认使用derby作为存储表信息的数据库,默认在哪启动就在哪建一个metadata_db文件放数据,可以在conf下的hive-site.xml中配置为一个固定的位置,这样不论在哪启动都可以了。
- HiveMetastore 的架构简析
houzhizhen
hivehive
HiveMetastore的架构简析HiveMetastore是Hive元数据管理的服务。可以把元数据存储在数据库中。对外通过api访问。hive_metastore.thrift对外提供的Thrift接口定义在文件standalone-metastore/src/main/thrift/hive_metastore.thrift中。内容包括用到的结构体和枚举,和常量,和rpcService。如分
- Hive与Spark的UDF:数据处理利器的对比与实践
窝窝和牛牛
hivesparkhadoop
文章目录Hive与Spark的UDF:数据处理利器的对比与实践一、UDF概述二、HiveUDF解析实现原理代码示例业务应用三、SparkUDF剖析-JDBC方式使用SparkThriftServer设置通过JDBC使用UDFSparkUDF的Java实现(用于JDBC方式)通过beeline客户端连接使用业务应用场景四、Hive与SparkUDF在JDBC模式下的对比五、实际部署与最佳实践六、总结
- 尚硅谷电商数仓6.0,hive on spark,spark启动不了
新时代赚钱战士
hivesparkhadoop
在datagrip执行分区插入语句时报错[42000][40000]Errorwhilecompilingstatement:FAILED:SemanticExceptionFailedtogetasparksession:org.apache.hadoop.hive.ql.metadata.HiveException:FailedtocreateSparkclientforSparksessio
- qt-5.15.2 源码编译 Linux
weixin_40857106
服务器运维
QT官方源码下载地址:https://download.qt.io/archive/qt/5.15/5.15.12/single/qt-everywhere-opensource-src-5.15.12.tar.xz安装Qt所需的依赖:sudoaptinstallbuild-essentiallibgl1-mesa-devlibxkbcommon-devlibnss3-devlibdbus-1-d
- 鸿蒙HarmonyOS开发:应用程序静态包-HAR
让开,我要吃人了
鸿蒙开发OpenHarmonyHarmonyOSharmonyos华为移动开发前端html开发语言鸿蒙
HAR(HarmonyArchive)是静态共享包,可以包含代码、C++库、资源和配置文件。通过HAR可以实现多个模块或多个工程共享ArkUI组件、资源等相关代码。使用场景作为二方库,发布到OHPM私仓,供公司内部其他应用使用。作为三方库,发布到OHPM中心仓,供其他应用使用。约束限制HAR不支持在设备上单独安装/运行,只能作为应用模块的依赖项被引用。HAR不支持在配置文件中声明UIAbility
- flutter 使用xcodebuild 命令打包ipa
肥肥呀呀呀
flutter
苹果打ipa包(注意苹果打包需要连接真机)方式一、1.先执行flutterbuildios生成framework2.执行命令xcodebuild-exportArchive-archivePathbuild/ios/Runner.xcarchive-exportOptionsPlistexportOptions.plist-exportPathbuild/ios/ipaexportOptions.
- Hadoop相关面试题
努力的搬砖人.
java面试hadoop
以下是150道Hadoop面试题及其详细回答,涵盖了Hadoop的基础知识、HDFS、MapReduce、YARN、HBase、Hive、Sqoop、Flume、ZooKeeper等多个方面,每道题目都尽量详细且简单易懂:Hadoop基础概念类1.什么是Hadoop?Hadoop是一个由Apache基金会开发的开源分布式计算框架,主要用于处理和存储大规模数据集。它提供了高容错性和高扩展性的分布式存
- oracle cdc logminer与oracle xstream
24k小善
java大数据flink
以下为OracleCDC技术中XStream与LogMiner的核心差异解析,结合技术背景、实现原理、性能表现等维度进行系统化对比。一、技术背景与定位差异LogMiner:官方日志分析工具的非正式应用最初设计用于数据库管理员(DBA)审计和分析历史日志,非专为CDC场景优化[1][9][16]。通过解析归档日志(ArchiveLog)或在线日志(OnlineRedoLog)提取变更记录,采用轮询机
- csv转为utf8编码_中文的csv文件的编码改成utf8的方法
John Sheppard
csv转为utf8编码
直奔主题:把包含中文的csv文件的编码改成utf-8的方法:啰嗦几句:在用pandas读取hive导出的csv文件时,经常会遇到类似UnicodeDecodeError:'gbk'codeccan'tdecodebyte0xa3inposition12这样的问题,这种问题是因为导出的csv文件包含中文,且这些中文的编码不是gbk,直接用excel打开这些文件还会出现乱码,但用记事本打开这些csv则
- 企业信息化整体架构图
weixin_33937913
系统架构
今天无意间发现一张企业信息化的图,放在这里以后参考。CollaboraticeCommerce转载于:https://www.cnblogs.com/Masterpiece/archive/2004/12/29/83696.html
- Hive函数大全:从核心内置函数到自定义UDF实战指南(附详细案例与总结)
一个天蝎座 白勺 程序猿
大数据开发从入门到实战合集hivehadoop数据仓库
目录背景一、Hive函数分类与核心函数表1.内置函数分类2.用户自定义函数(UDF)分类二、常用函数详解与实战案例1.数学函数2.字符串函数3.窗口函数4.自定义UDF实战三、总结与优化建议1.核心总结2.性能优化建议3.常问问题背景Hive作为Hadoop生态中最常用的数据仓库工具,其强大的函数库是高效处理和分析海量数据的核心能力之一。Hive函数分为内置函数和用户自
- dcm4che
jamie_zhengmin
dcm4chearchivejboss工具服务器
dcm4che工具包DICOMtoolkitDICOM工具包dcm4chee归档服务器器IHE影像管理器和影像归档执行器(dcm4jbossarchive影像归档器,影像扫描检查和报告的管理)dcm4che2重架构dcm4che的重架构实现
- 将Hive数据导出为CSV和Excel格式的方法
翠绿探寻
hiveexcelhadoop编程
将Hive数据导出为CSV和Excel格式的方法在Hive中存储和处理大规模数据是一项常见的任务。有时候,我们需要将Hive中的数据导出为CSV或Excel格式,以便进行进一步的分析或与其他工具进行集成。本文将介绍如何使用编程的方式将Hive数据导出为CSV和Excel格式,并提供相应的源代码。Hive数据导出为CSV格式要将Hive数据导出为CSV格式,我们可以使用Hive的内置函数INSERT
- debian11安装MongoDB
韩搏
Linux基础mongodb数据库
debian11bit64安装MongoDB6.0安装必要的包sudoaptinstallgnupgcurl导入MongoDB公钥curl-fsSLhttps://www.mongodb.org/static/pgp/server-6.0.asc|sudogpg--dearmor-o/usr/share/keyrings/mongodb-archive-keyring.gpg创建MongoDB源列
- linux 安装anaconda与jupyter notebook配置
土豆土豆,我是洋芋
python
一、anaconda安装在官网或清华镜像下载anaconda在载前看一下自己的系统版本,下载对应的anaconda版本。在系统中输入:cat/proc/version,如下图所示##下载地址1)官网:https://www.anaconda.com/distribution/2)清华镜像:https://mirrors.tuna.tsinghua.edu.cn/anaconda/archive/安
- Hive 与 SparkSQL 的语法差异及性能对比
自然术算
Hivehivehadoop大数据spark
在大数据处理领域,Hive和SparkSQL都是极为重要的工具,它们为大规模数据的存储、查询和分析提供了高效的解决方案。虽然二者都致力于处理结构化数据,并且都采用了类似SQL的语法来方便用户进行操作,但在实际使用中,它们在语法细节和性能表现上存在诸多差异。了解这些差异,对于开发者根据具体业务场景选择合适的工具至关重要。语法差异数据定义语言(DDL)表创建语法Hive:在Hive中创建表时,需要详细
- Oracle V$SESSION详解
雨的遐想
oracle数据库
V$SESSION是SYS用户下面对于SYS.V_$SESSION视图的同义词。在本视图中,每一个连接到数据库实例中的session都拥有一条记录。包括用户session及后台进程如DBWR,LGWR,arcchiver等等。1.V$SESSION中的常用列V$SESSION是基础信息视图,用于找寻用户SID或SADDR,及检查用户的动态:(1)SQL_HASH_VALUE,SQL_ADDRESS
- Spark任务读取hive表数据导入es
小小小小小小小小小小码农
hiveelasticsearchsparkjava
使用elasticsearch-hadoop将hive表数据导入es,超级简单1.引入pomorg.elasticsearchelasticsearch-hadoop9.0.0-SNAPSHOT2.创建sparkconf//spark参数设置SparkConfsparkConf=newSparkConf();//要写入的索引sparkConf.set("es.resource","");//es集
- Redis 安装详细教程(小白版)
小小鸭程序员
springjavaAI编程springcloudredis
一、Windows系统安装Redis方法1:直接安装(推荐新手)下载RedisforWindows访问微软维护的Redis版本:https://github.com/microsoftarchive/redis/releases下载Redis-x64-3.2.100.msi(或最新版本)安装包。安装Redis双击下载的.msi文件点击下一步,勾选“AddRedisinstallationfolde
- Hive SQL 精进系列:REGEXP_REPLACE 函数的用法
进一步有进一步的欢喜
HiveSQL精进系列hivesqlhadoop
目录一、引言二、REGEXP_REPLACE函数基础2.1基本语法参数详解2.2简单示例三、REGEXP_REPLACE函数的应用场景3.1去除特殊字符3.2统一字符串格式四、REGEXP_REPLACE与REPLACE函数的对比4.1功能差异4.2适用场景五、REGEXP_REPLACE与REGEXP函数的对比5.1功能差异5.2适用场景六、总结一、引言字符串处理是数据处理中的常见需求,Hive
- Hive SQL 精进系列:SUBSTR 函数的多样用法
进一步有进一步的欢喜
HiveSQL精进系列hivesqlhadoop
目录一、引言二、SUBSTR函数基础介绍2.1基本语法2.2参数详解2.3简单示例三、SUBSTR函数常见应用场景3.1提取日期中的年份、月份或日期3.2隐藏部分敏感信息四、SUBSTR函数高级用法4.1结合条件判断动态截取4.2处理复杂字符串模式五、总结一、引言SUBSTR函数是HiveSQL中一个用于字符串截取的重要函数,在处理文本数据时发挥着关键作用。本文将全面且深入地介绍HiveSQL中S
- Hive----Hive进阶操作(三) HIVE 特殊分隔符处理
XiaodunLP
Hive
HIVE特殊分隔符处理补充:hive读取数据的机制:1、首先用InputFormat的一个具体实现类读入文件数据,返回一条一条的记录(可以是行,或者是你逻辑中的“行”)2、然后利用SerDe的一个具体实现类,对上面返回的一条一条的记录进行字段切割Hive对文件中字段的分隔符默认情况下只支持单字节分隔符,如果数据文件中的分隔符是多字符的,如下所示:01||huangbo02||xuzheng03||
- hive-进阶版-1
数据牧马人
hivehadoop数据仓库
第6章hive内部表与外部表的区别Hive是一个基于Hadoop的数据仓库工具,用于对大规模数据集进行数据存储、查询和分析。Hive支持内部表(ManagedTable)和外部表(ExternalTable)两种表类型,它们在数据存储、管理方式和生命周期等方面存在显著区别。以下是内部表和外部表的主要区别:1.数据存储位置内部表:数据存储在Hive的默认存储目录下,通常位于HDFS(HadoopDi
- [黑洞与暗粒子]没有光的世界
comsci
无论是相对论还是其它现代物理学,都显然有个缺陷,那就是必须有光才能够计算
但是,我相信,在我们的世界和宇宙平面中,肯定存在没有光的世界....
那么,在没有光的世界,光子和其它粒子的规律无法被应用和考察,那么以光速为核心的
&nbs
- jQuery Lazy Load 图片延迟加载
aijuans
jquery
基于 jQuery 的图片延迟加载插件,在用户滚动页面到图片之后才进行加载。
对于有较多的图片的网页,使用图片延迟加载,能有效的提高页面加载速度。
版本:
jQuery v1.4.4+
jQuery Lazy Load v1.7.2
注意事项:
需要真正实现图片延迟加载,必须将真实图片地址写在 data-original 属性中。若 src
- 使用Jodd的优点
Kai_Ge
jodd
1. 简化和统一 controller ,抛弃 extends SimpleFormController ,统一使用 implements Controller 的方式。
2. 简化 JSP 页面的 bind, 不需要一个字段一个字段的绑定。
3. 对 bean 没有任何要求,可以使用任意的 bean 做为 formBean。
使用方法简介
- jpa Query转hibernate Query
120153216
Hibernate
public List<Map> getMapList(String hql,
Map map) {
org.hibernate.Query jpaQuery = entityManager.createQuery(hql);
if (null != map) {
for (String parameter : map.keySet()) {
jp
- Django_Python3添加MySQL/MariaDB支持
2002wmj
mariaDB
现状
首先,
[email protected] 中默认的引擎为 django.db.backends.mysql 。但是在Python3中如果这样写的话,会发现 django.db.backends.mysql 依赖 MySQLdb[5] ,而 MySQLdb 又不兼容 Python3 于是要找一种新的方式来继续使用MySQL。 MySQL官方的方案
首先据MySQL文档[3]说,自从MySQL
- 在SQLSERVER中查找消耗IO最多的SQL
357029540
SQL Server
返回做IO数目最多的50条语句以及它们的执行计划。
select top 50
(total_logical_reads/execution_count) as avg_logical_reads,
(total_logical_writes/execution_count) as avg_logical_writes,
(tot
- spring UnChecked 异常 官方定义!
7454103
spring
如果你接触过spring的 事物管理!那么你必须明白 spring的 非捕获异常! 即 unchecked 异常! 因为 spring 默认这类异常事物自动回滚!!
public static boolean isCheckedException(Throwable ex)
{
return !(ex instanceof RuntimeExcep
- mongoDB 入门指南、示例
adminjun
javamongodb操作
一、准备工作
1、 下载mongoDB
下载地址:http://www.mongodb.org/downloads
选择合适你的版本
相关文档:http://www.mongodb.org/display/DOCS/Tutorial
2、 安装mongoDB
A、 不解压模式:
将下载下来的mongoDB-xxx.zip打开,找到bin目录,运行mongod.exe就可以启动服务,默
- CUDA 5 Release Candidate Now Available
aijuans
CUDA
The CUDA 5 Release Candidate is now available at http://developer.nvidia.com/<wbr></wbr>cuda/cuda-pre-production. Now applicable to a broader set of algorithms, CUDA 5 has advanced fe
- Essential Studio for WinRT网格控件测评
Axiba
JavaScripthtml5
Essential Studio for WinRT界面控件包含了商业平板应用程序开发中所需的所有控件,如市场上运行速度最快的grid 和chart、地图、RDL报表查看器、丰富的文本查看器及图表等等。同时,该控件还包含了一组独特的库,用于从WinRT应用程序中生成Excel、Word以及PDF格式的文件。此文将对其另外一个强大的控件——网格控件进行专门的测评详述。
网格控件功能
1、
- java 获取windows系统安装的证书或证书链
bewithme
windows
有时需要获取windows系统安装的证书或证书链,比如说你要通过证书来创建java的密钥库 。
有关证书链的解释可以查看此处 。
public static void main(String[] args) {
SunMSCAPI providerMSCAPI = new SunMSCAPI();
S
- NoSQL数据库之Redis数据库管理(set类型和zset类型)
bijian1013
redis数据库NoSQL
4.sets类型
Set是集合,它是string类型的无序集合。set是通过hash table实现的,添加、删除和查找的复杂度都是O(1)。对集合我们可以取并集、交集、差集。通过这些操作我们可以实现sns中的好友推荐和blog的tag功能。
sadd:向名称为key的set中添加元
- 异常捕获何时用Exception,何时用Throwable
bingyingao
用Exception的情况
try {
//可能发生空指针、数组溢出等异常
} catch (Exception e) {
- 【Kafka四】Kakfa伪分布式安装
bit1129
kafka
在http://bit1129.iteye.com/blog/2174791一文中,实现了单Kafka服务器的安装,在Kafka中,每个Kafka服务器称为一个broker。本文简单介绍下,在单机环境下Kafka的伪分布式安装和测试验证 1. 安装步骤
Kafka伪分布式安装的思路跟Zookeeper的伪分布式安装思路完全一样,不过比Zookeeper稍微简单些(不
- Project Euler
bookjovi
haskell
Project Euler是个数学问题求解网站,网站设计的很有意思,有很多problem,在未提交正确答案前不能查看problem的overview,也不能查看关于problem的discussion thread,只能看到现在problem已经被多少人解决了,人数越多往往代表问题越容易。
看看problem 1吧:
Add all the natural num
- Java-Collections Framework学习与总结-ArrayDeque
BrokenDreams
Collections
表、栈和队列是三种基本的数据结构,前面总结的ArrayList和LinkedList可以作为任意一种数据结构来使用,当然由于实现方式的不同,操作的效率也会不同。
这篇要看一下java.util.ArrayDeque。从命名上看
- 读《研磨设计模式》-代码笔记-装饰模式-Decorator
bylijinnan
java设计模式
声明: 本文只为方便我个人查阅和理解,详细的分析以及源代码请移步 原作者的博客http://chjavach.iteye.com/
import java.io.BufferedOutputStream;
import java.io.DataOutputStream;
import java.io.FileOutputStream;
import java.io.Fi
- Maven学习(一)
chenyu19891124
Maven私服
学习一门技术和工具总得花费一段时间,5月底6月初自己学习了一些工具,maven+Hudson+nexus的搭建,对于maven以前只是听说,顺便再自己的电脑上搭建了一个maven环境,但是完全不了解maven这一强大的构建工具,还有ant也是一个构建工具,但ant就没有maven那么的简单方便,其实简单点说maven是一个运用命令行就能完成构建,测试,打包,发布一系列功
- [原创]JWFD工作流引擎设计----节点匹配搜索算法(用于初步解决条件异步汇聚问题) 补充
comsci
算法工作PHP搜索引擎嵌入式
本文主要介绍在JWFD工作流引擎设计中遇到的一个实际问题的解决方案,请参考我的博文"带条件选择的并行汇聚路由问题"中图例A2描述的情况(http://comsci.iteye.com/blog/339756),我现在把我对图例A2的一个解决方案公布出来,请大家多指点
节点匹配搜索算法(用于解决标准对称流程图条件汇聚点运行控制参数的算法)
需要解决的问题:已知分支
- Linux中用shell获取昨天、明天或多天前的日期
daizj
linuxshell上几年昨天获取上几个月
在Linux中可以通过date命令获取昨天、明天、上个月、下个月、上一年和下一年
# 获取昨天
date -d 'yesterday' # 或 date -d 'last day'
# 获取明天
date -d 'tomorrow' # 或 date -d 'next day'
# 获取上个月
date -d 'last month'
#
- 我所理解的云计算
dongwei_6688
云计算
在刚开始接触到一个概念时,人们往往都会去探寻这个概念的含义,以达到对其有一个感性的认知,在Wikipedia上关于“云计算”是这么定义的,它说:
Cloud computing is a phrase used to describe a variety of computing co
- YII CMenu配置
dcj3sjt126com
yii
Adding id and class names to CMenu
We use the id and htmlOptions to accomplish this. Watch.
//in your view
$this->widget('zii.widgets.CMenu', array(
'id'=>'myMenu',
'items'=>$this-&g
- 设计模式之静态代理与动态代理
come_for_dream
设计模式
静态代理与动态代理
代理模式是java开发中用到的相对比较多的设计模式,其中的思想就是主业务和相关业务分离。所谓的代理设计就是指由一个代理主题来操作真实主题,真实主题执行具体的业务操作,而代理主题负责其他相关业务的处理。比如我们在进行删除操作的时候需要检验一下用户是否登陆,我们可以删除看成主业务,而把检验用户是否登陆看成其相关业务
- 【转】理解Javascript 系列
gcc2ge
JavaScript
理解Javascript_13_执行模型详解
摘要: 在《理解Javascript_12_执行模型浅析》一文中,我们初步的了解了执行上下文与作用域的概念,那么这一篇将深入分析执行上下文的构建过程,了解执行上下文、函数对象、作用域三者之间的关系。函数执行环境简单的代码:当调用say方法时,第一步是创建其执行环境,在创建执行环境的过程中,会按照定义的先后顺序完成一系列操作:1.首先会创建一个
- Subsets II
hcx2013
set
Given a collection of integers that might contain duplicates, nums, return all possible subsets.
Note:
Elements in a subset must be in non-descending order.
The solution set must not conta
- Spring4.1新特性——Spring缓存框架增强
jinnianshilongnian
spring4
目录
Spring4.1新特性——综述
Spring4.1新特性——Spring核心部分及其他
Spring4.1新特性——Spring缓存框架增强
Spring4.1新特性——异步调用和事件机制的异常处理
Spring4.1新特性——数据库集成测试脚本初始化
Spring4.1新特性——Spring MVC增强
Spring4.1新特性——页面自动化测试框架Spring MVC T
- shell嵌套expect执行命令
liyonghui160com
一直都想把expect的操作写到bash脚本里,这样就不用我再写两个脚本来执行了,搞了一下午终于有点小成就,给大家看看吧.
系统:centos 5.x
1.先安装expect
yum -y install expect
2.脚本内容:
cat auto_svn.sh
#!/bin/bash
- Linux实用命令整理
pda158
linux
0. 基本命令 linux 基本命令整理
1. 压缩 解压 tar -zcvf a.tar.gz a #把a压缩成a.tar.gz tar -zxvf a.tar.gz #把a.tar.gz解压成a
2. vim小结 2.1 vim替换 :m,ns/word_1/word_2/gc
- 独立开发人员通向成功的29个小贴士
shoothao
独立开发
概述:本文收集了关于独立开发人员通向成功需要注意的一些东西,对于具体的每个贴士的注解有兴趣的朋友可以查看下面标注的原文地址。
明白你从事独立开发的原因和目的。
保持坚持制定计划的好习惯。
万事开头难,第一份订单是关键。
培养多元化业务技能。
提供卓越的服务和品质。
谨小慎微。
营销是必备技能。
学会组织,有条理的工作才是最有效率的。
“独立
- JAVA中堆栈和内存分配原理
uule
java
1、栈、堆
1.寄存器:最快的存储区, 由编译器根据需求进行分配,我们在程序中无法控制.2. 栈:存放基本类型的变量数据和对象的引用,但对象本身不存放在栈中,而是存放在堆(new 出来的对象)或者常量池中(字符串常量对象存放在常量池中。)3. 堆:存放所有new出来的对象。4. 静态域:存放静态成员(static定义的)5. 常量池:存放字符串常量和基本类型常量(public static f