Kite的学习历程之SpringBoot之数据访问整合Druid数据源
Kite学习框架的第十九天
1. 整合Druid数据源
1.1 首先在pom.xml中导入依赖的数据源
<!--引入Druid数据源-->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid</artifactId>
<version>1.1.21</version>
</dependency>
1.2 在application.yml配置文件中修改原来的以来的访问使用耳朵连接池
上面的datasource是数据连接的信息
type: com.alibaba.druid.pool.DruidDataSource: 作用就是切换连接的数据池为druid
下面的这些为设置的连接属性设置:
这些属性要起作用的话需要在config类中进行配置
initialSize: 5
minIdle: 5
maxActive: 20
maxWait: 60000
timeBetweenEvictionRunsMillis: 60000
minEvictableIdleTimeMillis: 300000
validationQuery: SELECT 1 FROM DUAL
testWhileIdle: true
testOnBorrow: false
testOnReturn: false
poolPreparedStatements: true
spring:
datasource:
username: root
password: 25002500
url: jdbc:mysql:///book?characterEncoding=utf8&serverTimezone=GMT%2B8
driver-class-name: com.mysql.jdbc.Driver
type: com.alibaba.druid.pool.DruidDataSource
initialSize: 5
minIdle: 5
maxActive: 20
maxWait: 60000
timeBetweenEvictionRunsMillis: 60000
minEvictableIdleTimeMillis: 300000
validationQuery: SELECT 1 FROM DUAL
testWhileIdle: true
testOnBorrow: false
testOnReturn: false
poolPreparedStatements: true
# 配置监控统计拦截的filters,去掉后监控界面sql无法统计,'wall'用于防火墙
# filters: stat,wall,log4j
# maxPoolPreparedStatementPerConnectionSize: 20
# useGlobalDataSourceStat: true
# connectionProperties: druid.stat.mergeSql=true;druid.stat.slowSqlMillis=500
1.3 配置config类
package cn.kitey.jdbc.config;
import com.alibaba.druid.pool.DruidDataSource;
import com.alibaba.druid.support.http.StatViewServlet;
import com.alibaba.druid.support.http.WebStatFilter;
import org.springframework.boot.context.properties.ConfigurationProperties;
import org.springframework.boot.web.servlet.FilterRegistrationBean;
import org.springframework.boot.web.servlet.ServletRegistrationBean;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import javax.sql.DataSource;
import java.util.Arrays;
import java.util.HashMap;
/**
* 数据源配置类
*/
@Configuration
public class DruidConfig {
/**
* 将配置添加到容器中
* @return
*/
@ConfigurationProperties(prefix = "spring.datasource")
@Bean
public DataSource druid(){
return new DruidDataSource();
}
//配置Druid的监控
//1. 配置一个管理后台的Servlet
@Bean
public ServletRegistrationBean statViewServlet(){
ServletRegistrationBean bean = new ServletRegistrationBean(new StatViewServlet(), "/druid/*");
HashMap<String, String> map = new HashMap<>();
map.put("loginUsername","kite");
map.put("loginPassword","250025");
map.put("allow",""); //允许所有访问
map.put("delly","192.168.11.21"); //不允许访问
//可以配置一定初始化参数
bean.setInitParameters(map);
return bean;
}
//2. 配置一个web监控的filter
@Bean
public FilterRegistrationBean webStatFilter(){
FilterRegistrationBean bean = new FilterRegistrationBean(new WebStatFilter());
HashMap<String, String> stringStringHashMap = new HashMap<>();
//不拦截那些请求
stringStringHashMap.put("exclusions","*.js, *.css, /druid");
bean.setInitParameters(stringStringHashMap);
//拦截那些请求
bean.setUrlPatterns(Arrays.asList("/*"));
return bean;
}
}
这个方法是将我们前面配置的连接池的属性,添加到容器中
/**
* 将配置添加到容器中
* @return
*/
@ConfigurationProperties(prefix = "spring.datasource")
@Bean
public DataSource druid(){
return new DruidDataSource();
}
配置一个servlet的后台管理
setInitParameters:设置访问信息,例如:用户名,密码等。通过map添加数据
可以设置的属性如下:
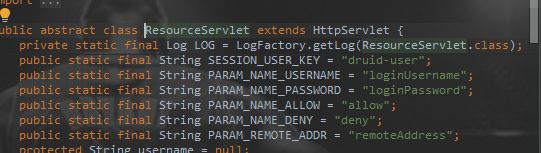
//1. 配置一个管理后台的Servlet
@Bean
public ServletRegistrationBean statViewServlet(){
ServletRegistrationBean bean = new ServletRegistrationBean(new StatViewServlet(), "/druid/*");
HashMap<String, String> map = new HashMap<>();
map.put("loginUsername","kite");
map.put("loginPassword","250025");
map.put("allow",""); //允许所有访问
map.put("delly","192.168.11.21"); //不允许访问
//可以配置一定初始化参数
bean.setInitParameters(map);
return bean;
}
配置一个过滤器
setInitParameters()可以设置以下属性,同样使用map进行添加
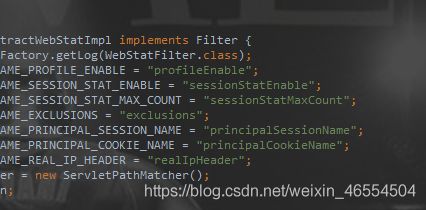
我们这里设置了exclusions 不过滤的信息 :stringStringHashMap.put(“exclusions”,"*.js, .css, /druid");
bean.setUrlPatterns(Arrays.asList("/")) :设置拦截所有的请求
//2. 配置一个web监控的filter
@Bean
public FilterRegistrationBean webStatFilter(){
FilterRegistrationBean bean = new FilterRegistrationBean(new WebStatFilter());
HashMap<String, String> stringStringHashMap = new HashMap<>();
//不拦截那些请求
stringStringHashMap.put("exclusions","*.js, *.css, /druid");
bean.setInitParameters(stringStringHashMap);
//拦截那些请求
bean.setUrlPatterns(Arrays.asList("/*"));
return bean;
}
1.4 访问druid
登录页面:这里输入我们设置用户名,以及密码
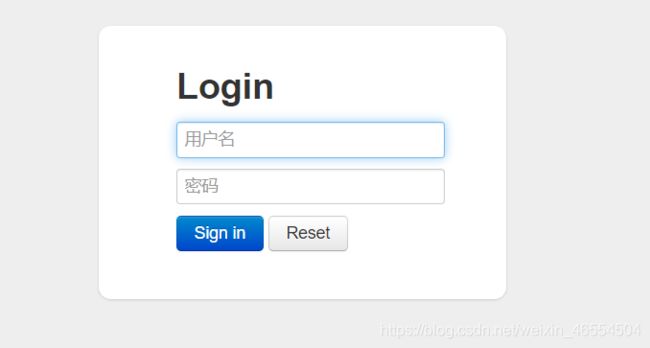
下面就是登录的首页
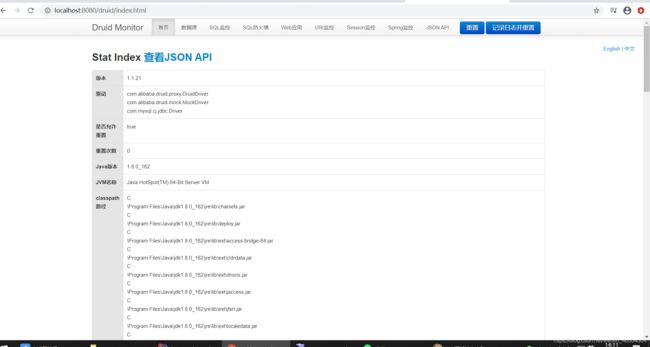
以上就是简单的配置druid数据源