单片机C语言程序设计基础知识全解析
标识符和关键字
(一)标识符
标识符是用来表示源程序中自定义对象名称的符号。其中的自定义对象可以是常量、变量、数组、结构、语句标号以及函数等。
在C51语言中,标识符可以由字母(a~z,A~Z)、数字(0~9)和下划线“_”组成,最多可支持32个字符。
C51标识符的定义不是随意的,应遵循“简洁”和“见名知意”的原则,并需要符合一定的规则:
➢ 标识符的第一个字符必须是字母或者下划线,不能为数字。由于有些编译系统专用的标识符以下划线开头,所以用户在定义标识符时一般不要以下划线开头。
➢ C51的标识符区分大小写,例如“ch1”和“Ch1”表示两个不同的标识符。
➢ 用户自定义的标识符不能与系统保留的关键字重复。
(二)关键字
关键字是C51编译器保留的一些特殊标识符,具有特定的含义和用法。单片机C51程序语言继承了ANSI C标准定义的32个关键字,如表3-1所示。
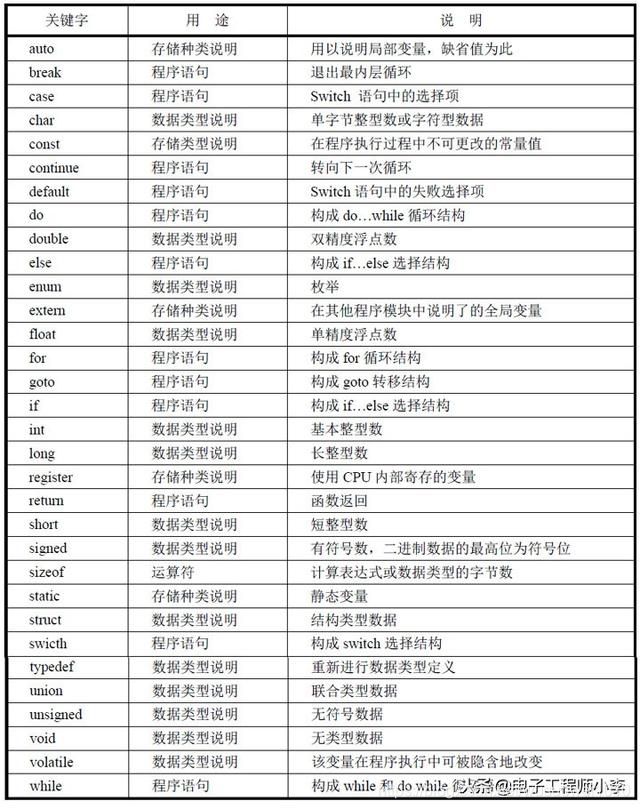
表3-1 C51的关键字
同时C51又结合单片机硬件的特点扩展了19个关键字:
at idata sfr16 alien interrupt small bdata large task code bit pdata using reentrant xdata compact sbit data sfr
C51数据类型
表3-2列出了Keil uVision2 C51编译器所支持的数据类型。
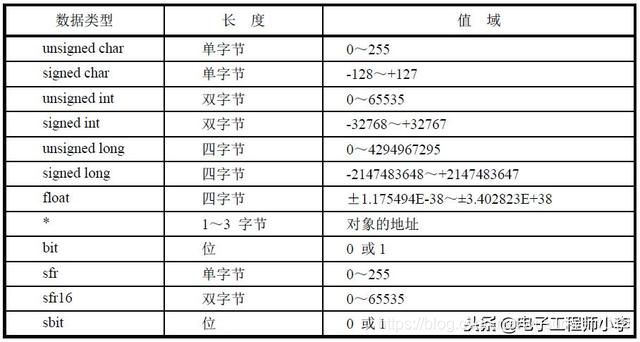
表3-2 C51编译器所支持的数据类型
1. char字符类型
char类型的长度是一个字节,通常用于定义处理字符数据的变量或常量。char字符类型分为无符号字符类型(unsigned char)和有符号字符类型(signed char),默认值为signed char类型。
unsigned char类型用字节中所有的位来表示数值,可以表达的数值范围是0~255;signed char类型中字节最高位表示数据的符号,“0”表示正数,“1”表示负数(负数用补码表示),所能表示的数值范围是-128~+127。
提示
unsigned char常用于处理ASCII字符或小于等于255的整型数。
正数的补码与原码相同,负二进制数的补码等于它的绝对值按位取反后加1。
2. int整型
int整型长度为两个字节,用于存放一个双字节数据。分为有符号整型数signed int和无符号整型数unsigned int,默认值为signed int类型。
signed int表示的数值范围是-32768~+32767,字节中最高位表示数据的符号,“0”表示正数,“1”表示负数;unsigned int表示的数值范围是0~65535。
3. long长整型
long长整型长度为四个字节,用于存放一个四字节数据。分有符号长整型signed long和无符号长整型unsigned long,默认值为signed long类型。
signed int表示的数值范围是-2147483648~+2147483647,字节中最高位表示数据的符号,“0”表示正数,“1”表示负数;unsigned long表示的数值范围是0~4294967295。
4. float浮点型
float浮点型在十进制中具有7位有效数字,是符合IEEE-754标准的单精度浮点型数据,占用四个字节。浮点数的结构较复杂,单片机使用较少,这里不做详细讨论。
5. 指针型
指针型数据本身是一个变量,在这个变量中存放着指向另一个数据的地址。根据处理器的不同,指针型数据所占的内存单元也不尽相同,在C51中它的长度一般为1~3个字节。
6. bit位标量
bit 位标量是C51编译器的一种扩充数据类型,利用它可定义一个位标量,但不能定义位指针,也不能定义位数组。它的值是一个二进制位,非0即1。
定义格式:bit 变量名=变量值。
7. sfr特殊功能寄存器
sfr是一种扩充数据类型,占用一个内存单元,地址范围为0x80~0xFF。
定义格式为:sfr 变量名=变量地址。
利用它可以访问51单片机内部的所有特殊功能寄存器。例如,用“sfr P1=0x90”这一句定P1为P1端口在片内的寄存器。
8. sfr16 16位特殊功能寄存器
sfr16是一种扩充数据类型,占用两个内存单元,sfr16和sfr一样用于操作特殊功能寄存器,所不同的是,此类型的变量可访问16为特殊功能寄存器。
定义格式:sfr16 变量名=变量地址。
此处的变量地址为16位中的低8位地址,其地址范围为0x80~0xFF。通过sfr16变量读16位特殊功能寄存器时,先读低字节,后读高字节;写特殊功能寄存器时先写高字节,后写低字节。
9. sbit可位寻址位
sbit是C51中的一种扩充数据类型,利用它可以访问芯片内部的RAM中的可寻址位或特殊功能寄存器中的可寻址位。
定义格式:
sbit 变量名=位地址;sbit 变量名=SFR地址^位序号;sbit 变量名=sfr16变量^位序号。
因P1端口的寄存器是可位寻址的,所以我们可以定义P1_1为P1中的P1.1引脚,同样我们可以用P1.1的地址去写,这样在以后的程序语句中就可以用P1_1来对P1.1引脚进行读写操作了。
例如:
sbit P1_1=P1^1;
sbit P1_1=0x91
常量与变量
(一)常量
常量是在程序运行过程中不能改变的量,如固定的数据表、字符等。常量的数据类型只有整型、浮点型、字符型、字符串型和位标量。
- 整型常量
不同数据类型的整型常量表示方法不同,十进制如123,0,-89等;十六进制则以0x开头如0x34,-0x3B等;长整型就在数字后面加字母L,如104L,034L,0xF340等。
- 浮点型常量
浮点型常量可分为十进制和指数表示形式。
十进制浮点型常量由数字和小数点组成,整数或小数部分为0,可以省略但必须有小数点,如0.888,3345.345,0.0等。
指数浮点型常量表示形式为:[±]数字[.数字]e[±]数字
[]中的内容为可选项,如125e3,7e9,-3.0e-3等。
- 字符型常量
字符型常量是单引号内的字符,如‘a’,‘d’等。表示不显示的控制字符,可以在该字符前面加一个反斜杠“\”组成专用转义字符,常用转义字符如表3-3所示。
- 字符串型常量
字符串型常量由双引号内的字符组成,如“test”,“OK”等。当引号内没有字符时,为空字符串。
在C中字符串常量是做为字符类型数组来处理的,在存储字符串时系统会在字符串尾部加上“\0”转义字符以作为该字符串的结束符。字符串常量“A”和字符常量‘A’是不同的,前者在存储时多占用一个字节的空间。
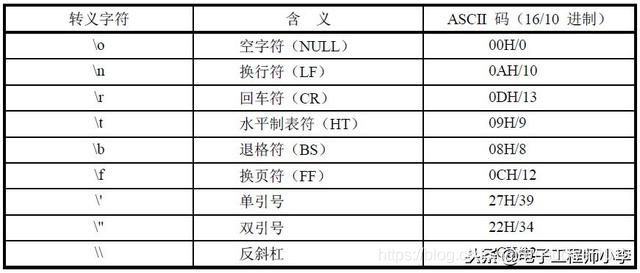
表3-3 常用转义字符表
- 位标量
位标量是C51编译器的一种扩充数据类型,它的值是一个二进制位,不是0就是1。
下面我们来看一些常量定义的例子:

以上两句它们的值都保存在程序存储器中,而程序存储器在运行中是不允许被修改的,所以如果在这两句后面用了类似a=110,a++这样的赋值语句,编译时将会出错。
(二)变量
变量是可以在程序运行过程中不断变化的量,变量的定义可以使用所有C51编译器支持的数据类型。要在程序中使用变量必须先用标识符作为变量名,并指出所用的数据类型和存储模式,这样编译系统才能为变量分配相应的存储空间。
- 变量的定义和作用范围
定义一个变量的格式如下:
[存储类型] 数据类型 [存储器类型] 变量名表
在定义格式中除了数据类型和变量名表是必要的,其它都是可选项。
(1)存储类型
不同存储类型的变量以及不同位置定义的变量具有不同的代码有效范围,也就是变量的作用域。在单片机程序中,按照变量的存储类型,可以分为:自动变量、全局变量、静态变量和寄存器变量。
① 自动变量
自动变量是以关键字auto标识的变量类型,其一般是在函数的内部或者复合语句中使用。
自动型变量的作用域范围是函数或者复合语句的内部。在C51中,函数或复合语句内部定义自动变量时,关键字auto可以省略,即默认为自动型变量。
在程序执行过程中,自动变量是动态分配存储空间的。当程序执行到该变量声明语句时,根据变量类型自动为其分配存储空间。当该函数或者复合语句执行完毕后,该变量的存储空间将立刻自动取消,此时,该自动变量失效,在函数或者复合语句外部将不能够使用该变量。
② 全局变量
全局变量是以关键字extern标识的变量类型,如果一个变量定义在所有函数的外部,即整个程序文件的最前面,那么这个变量便是全局变量。全局变量有时也称为外部变量。
在编译程序时,全局变量将被静态地分配适当的存储空间。该变量一旦分配空间,在整个程序运行过程中便不会消失。因此,全局变量对整个程序文件都有效,即全局变量可以被该程序文件中的任何函数使用。
③ 静态变量
静态变量以关键字static定义,从变量作用域来看,静态变量和自动变量类似,作用域只是定义该变量的函数内部。如果静态变量定义在函数外部,将具有全局的作用域。
而从内存占用的角度,静态变量和全局变量类似,其始终占有内存空间。
④ 寄存器变量
单片机的CPU寄存器中也可以保存少量的变量,这种变量称为寄存器变量。寄存器变量以关键字register声明。
由于单片机对CPU寄存器的读写十分快,因此寄存器变量的操作速度要原高于其他类型的变量。寄存器变量常用于某一变量名频繁使用的情况,这样做可以提高系统的运算速度。
由于单片机资源有限,程序中只允许同时定义两个寄存器变量。如果多于两个,在编译时会自动地将其他的寄存器变量当做非寄存器变量来处理。
(2)存储器类型
存储器类型的说明就是指定该变量在C51硬件系统中所使用的存储区域,并在编译时准确的定位。表3-4中是KEIL uVision2所能认别的存储器类型。

表3-4 存储器类型
提示
在AT89C51芯片中RAM只有低128位,位于80H到FFH的高128位则在52芯片中才有用,并和特殊寄存器地址重叠。
如果省略存储器类型,系统则会按编译模式small,compact或large所规定的默认存储器类型去指定变量的存储区域。
① small存储模式
small存储模式将函数参数和局部变量放在片内RAM(默认变量类型为DATA,最大128字节)。另外所有对象包括栈都优先放置在片内RAM,当片内RAM用满,再向片外RAM放置。
② compact存储模式
compact存储模式中将参数和局部变量放在片外RAM(默认存储类型是PDATA,最大256字节);通过R0、R1间接寻址。
③ large存储模式
large存储模式将参数和局部变量直接放入片外RAM(默认的存储类型是XDATA,最大64KB);使用数据指针DPTR间接寻址,因此访问效率较低。
(3)对变量进行绝对定位
C51扩展的关键字_at_专门用于对变量作绝对定位,_at_使用在变量的定义中,其格式为:
[存储类型] 数据类型 [存储区] 变量名1 at 地址常数[,变量名2…]
例如:
① 对data区域中的 unsigned char变量aa作绝对定位:
unsigned char data aa at 0x30;
② 对pdata区域中的 unsigned int数组cc作绝对定位:
unsigned int pdata cc[10] at 0x34;
③ 对xdata区域中的 unsigned char变量printer_port作绝对定位:
unsigned char xdata printer_port at 0x7fff;
对变量绝对定位的几点说明:
① 绝对地址变量在定义时不能初始化,因此不能对code型常量绝对定位;
② 绝对地址变量只能够是全局变量,不能在函数中对变量绝对定位;
③ 绝对地址变量多用于I/O端口,一般情况下不对变量作绝对定位;
④ 位变量不能使用_at_绝对定位。
- 变量的初始化和赋值
(1)变量的初始化
变量的初始化是指变量在被说明的同时赋给一个初值。外部变量和静态全程变量在程序开始处被初始化,局部变量包括静态局部变量是在进入定义它们的函数或复合语句时才作初始化。所有全程变量在没有明确的初始化时将被自动清零,而局部变量和寄存器变量在未赋值前其值是不确定的。
对于外部变量和静态变量,初值必须是常数表达式,而自动变量和寄存器变量可以是任意的表达式,这个表达式可以包括常数和前面说明过的变量和函数。
例如:

(2)变量的赋值
变量赋值是给已说明的变量赋给一个特定值。
单个变量的赋值:
① 整型变量和浮点变量
赋值格式如下:
变量名=表达式;
例如:

说明:
C语言中允许给多个变量赋同一值时可用连等的方式。
例如:

② 字符型变量
字符型变量可以用三种方法赋值。
例如:

数组与指针
(一)数组
所谓数组就是指具有相同数据类型的变量集,并具有共同的名字。数组中的每个特定元素都使用下标来访问。数组由一段连续的存储地址构成,最低的地址对应于第一个数组元素,最高的地址对应最后一个数组元素。数组可以是一维的,也可以是多维的。
- 数组基本形式
(1)一维数组
一维数组的格式是:类型 变量名[长度];
类型是指数据类型,即每一个数组元素的数据类型,包括整数型、浮点型、字符型、指针型以及结构和联合。
例如:
int a[10];
unsigned long a[20];
char *s[5];
char *f[];
说明:数组都是以0作为第一个元素的下标,因此,当说明一个int a[16]的整型数组时,表明该数组有16个元素,a[0]~a[15],一个元素为一个整型变量。
大多数字符串用一维数组表示。数组元素的多少表示字符串长度,数组名表示字符串中第一个字符的地址,例如在语句char str[8]说明的数组中存入“hello”字符串后,str表示第一个字母“h”所在的内存单元地址。str[0]存放的是字母“h”的ASCII码值,以此类推,str[4]存入的是字母“o”的ASCII码值,str[5]则应存放字符串终止符‘\0’。
C语言的编译器大多对数组不作边界检查。
例如用下面语句说明两个数组
char str1[5],str2[6];
当赋给str1一个字符串“ABCDEFG”时,只有“ABCDE”被赋给,“E”将会自动的赋给str2,这点应特别注意。
(2)多维数组
多维数组的一般格式:
类型 数组名[第n维长度][第n-1维长度]……[第1维长度];
例如:
![]()
数组m[3][2]共有3*2=6 个元素,顺序为:
m[0][0],m[0][1],m[1][0],m[1][1],m[2][0],m[2][1];
数组c[2][2][3]共有223=12个元素,顺序为:
c[0][0][0],c[0][0][1],c[0][0][2],
c[0][1][0],c[0][1][1],c[0][1][2],
c[1][0][0],c[1][0][1],c[1][0][2],
c[1][1][0],c[1][1][1],c[1][1][2];
数组占用的内存空间(即字节数)的计算式为:
字节数=第1维长度第2维长度…第n维长度该数组数据类型占用的字节数。
- 数组的初始化
数组变量的初始化如:

数组进行初始化有下述规则:
① 数组的每一行初始化赋值用“{}”并用“,”分开,总的再加一对“{}”括起来,最后以“;”表示结束。
② 多维数组的存储是按最右维数的变量变化最快的原则。
③ 多维数组存储是连续的,因此可以用一维数组初始化的办法来初始化多维数组。
例如:
![]()
④ 对数组初始化时,如果初值表中的数据个数比数组元素少,则不足的数组元素用0来填补。
⑤ 对指针型变量数组可以不规定维数,在初始化赋值时,数组维数从0开始被连续赋值。
例如:
char *f[]={‘a’,‘b’,‘c’};
初始化时将会给3个字符指针赋值,即:*f[0]=‘a’,*f[1]=‘b’,*f[2]=‘c’。
- 数组变量的赋值
整型数组和浮点数组的赋值,例如:

字符串数组的赋值,例如:

上面程序在编译时,遇到char s[30]这条语句时,编译程序会在内存的某处留出连续30个字节的区域,并将第一个字节的地址赋给s。当遇到strcpy函数时,首先在目标文件的某处建立一个“Good News!\0”的字符串。其中“\0”表示字符串终止,终止符是编译时自动加上的,然后一个字符一个字符地复制到s所指的内存区域。因此定义字符串数组时,其元素个数至少应该比字符串的长度多1。
提示
① 字符串数组不能用“=”直接赋值,即s=“Good News!”是不合法的。所以应分清字符串数组和字符串指针的不同赋值方法。
② 对于长字符串,Turbo C2.0允许使用下述方法:
例如:

(二)指针
- 指针基本形式
指针定义的一般形式为:类型识别符 *指针变量名;
例如:
![]()
C51 支持一般指针(Generic Pointer)和存储器指针(Memory_Specific Pointer)。
(1)一般指针
一般指针的声明和使用均与标准C相同,不过同时还可以说明指针的存储类型。
例如:
![]()
以上的long、char等指针指向的数据可存放于任何存储器中。一般指针本身用3个字节存放,分别存储存储器类型、高位偏移和低位偏移量。
(2)存储器指针
基于存储器的指针说明时即指定了存贮类型,例如:
![]()
这种指针存放时,只需1或2个字节就够了,因为只需存放偏移量。
- 指针变量的初始化
例如:

3. 指针变量的赋值
例如:
main()
{
int *i;
char *str;
*i=100;
str=“Good”;
}
i表示i是一个指向整型数的指针,即i是一个整型变量,i是一个指向该整型变量的地址。
*str表示str是一个字符型指针,即保留某个字符地址。在初始化时,str没有什么特殊的值,而在执行str=“Good”时,编译器先在目标文件的某处保留一个空间存放“Good\0”的字符串,然后把这个字符串的第一个字母“G”的地址赋给str,其中字符串结尾符“\0”是编译程序自动加上的。
对于指针变量的使用要特别注意。上例中两个指针在说明前没有初始化,因此这两指针为随机地址,在小存储模式下使用将会有破坏机器的危险。正确的使用办法如下:
例如:
main()
{
int *i;
char *str;
i=(int*)malloc(sizeof(int));
i=420;
str=(char*)malloc(20);
str=“Good, Answer!”;
}
上例中,函数(int*)malloc(sizeof(int))表示分配连续的sizeof(int)=2个字节的整型数存储空间并返回其首地址。同样(char*)malloc(20)表示分配连续20个字节的字符存储空间并返回首地址(有关该函数以后再详述)。由动态内存分配函数malloc()分配了内存空间后,这部分内存将专供指针变量使用。
如果要使i指向三个整型数,则用下述方法。
例如:
#include
main()
{
int *i;
i=(int*)malloc(3*sizeof(int));
*i=1234;
*(i+1)=4567;
*(i+2)=234;
}
i=1234表示把1234存放到i指向的地址中去,但对于(i+1)=4567,如果认为将4567存放到i指向的下一个字节中就错了。有些C语言编译器中只要说明i为整型指针,则(i+1)等价于 i+1sizeof(int)同样(i+2)等价于i+2sizeof(int)。
(三)数组与指针的关系
数组与指针有密切的联系。数组名本身就是该数组的指针,反过来,也可以把指针看成一个数组,数组名和指针实质上都是地址,但是指针是变量,可以作运算。而数组名是常量,不能进行运算。

由上例可以看出数组和指针有如下关系:
(p+i)=&(s[i]),*(p+i)=s[i];
因此,利用上述表达式可以对数组和指针进行互换。两者的区别仅在于:数组s是程序自动为它分配了所需的存储空间;而指针p则是利用动态分配函数为它分配存储空间或赋给它一个已分配的空间地址。
结构与联合
前面介绍了C语言中的基本数据类型,在实际进行C语言程序设计时仅有这些基本类型的数据是不够的,有时需要将一批各种类型的数据放在一起使用,从而引入了构造类型的数据——结构与联合。
(一)结构
结构是-种构造类型的数据,它能将多个不同类型的数据变量组合在一起,是一种数据的集合体。组成该集合体的各个数据变量称为结构成员,集合体使用单独的结构变量名。结构中的各个变量之间通常具有一定的关联性,如时间数据中的时、分、秒,日期数据中的星期、午、月、日等。结构是将一组相关联的数据变作为一个整体来进行处理,在程序中使用结构有利于对一些复杂而又具有内在联系的数踞进行处理。
- 结构变量的定义
方法一:先定义结构类型再定义结构变量名。
定义结构类型的一般形式为:
struct 结构名
{结构元素表};
结构元素表为该结构中的各个成员(又称为结构的域),由于结构可以由不同类型的数据组成,因此对结构中的各个成员都要进行类型说明。
例如定义一个日期结构类型date的格式如下:

定义好一个结构类型之后,就可用它来定义结构变量。一般格式为:
struct 结构名 结构变量名l,结构变量名2,…,结构变量名n;
例如:
struct date d1,d2;
方法二:在定义结构类型的同时定义结构变量名。
将方法一的两个步骤舍在一起,一般格式为:
struct 结构名
{ 结构元素表} 结构变量名1,结构变量名2,…,结构变量名n;
例:

方法三:直接定义结构变量。这种方法可以省略掉结构名,又称为无名结构,-般形式为:
strut
{ 结构元素表} 结构变量名1,结构变量名2,…,结构变量名n;
例如:

方法四:用typedef命名一个结构类型(这时结构名就不太重要了)。
例如:

提示
结构类型与结构变量是两个不同的概念。定义一个结构类型时只是给出该结构的组织形式,并没有给出具体的组织成员,结构名不占用任何存储空间,不能对结构名进行赋值、存取和运算。而结构变量则是一个结构中的具体成员,编译器会为具体的结构变量名分配确定的存储空间,因此可以对结构变量名赋值、存取和运算。
将-个变量定义为基本类型与将其定义为结构类型的不同之处是:前者只是说明变量的类型,后者不仅说明该变量为结构类型,同时还要指出该变量所属结构类型的名字。
一个结构中的结构元素可以是另外一个结构类型的变量,即可以形成结构的嵌套。
例如:

其中,结构类型mrec中的结构元素time又是另一个结构类型clock的结构变量,形成了结构的结构,即结构的嵌套,结构的嵌套可以是多层次的,但这种嵌套不能包含其自身,即结构不能自己定义自己。
结构中的结构元素可以与结构外其他变量同名。它们各自代表不同的对象,在使用中不会互相影响。
在定义结构变量时,还可以说明它的存储种类,可以extern、auto和static三种形式。
- 结构变量的引用
结构变量定义之后就要考虑对它的引用问题(赋值、存取、运算)。对结构变量的引用是通过所属的结构元素的引用实现的。引用结构元素的一般格式为:
结构变量名.结构元素
其中“.”是存取结构元素的成员运算符。如d1.month表示结构变量d1中的成员month。如果-个结构变量中的结构元素又是另外一个结构变量.即出现结构的嵌套时,则需要采用若干个成员运算符一级一级地找到最低一级的结构元素,而且只能对这个最低级的结构元素进行访问,例:m1.time.min。
对结构变量中的各个元素可以像普通变量一样进行赋值、存取和运算。
例:
d1.year=2006;
sum=d1.day+d2.day;
d1.month++;
m1.time.hour=0x22;
成员运算符的优先级别最高。
对于结构变量和结构元素在程序可以直接引用它们的地址。
例:scanf(“%d”&d1.year);
结构变量的地址通常用作函数参数,用来传递结构的地址。
- 结构变量的初值
当结构变量为外部全局变量或静态变量时可以在定义结构类型时给它赋初值,但不能给自动存储种类的动态局部结构变量赋初值。
例如:

自动结构变量不能在定义时赋初值,只能在程序执行中用赋值语句为各结构元素分别赋值。结构变量初值个数必须小于等于结构变量中元素的个数。初值不够时,余下的结构变量元素以0为其初值,如果初值个数多于元素个数时则会导致编译出错。
- 结构数组
在实际使用中,结构变量往往不止一个,通常是将多个相同的结构组成一个结构数组,结构数组的定义方法与结构变量完全一致。
例如:

例:结构数组赋初值

5. 结构型指针
(1)结构型指针的概念
一个指向结构类型变量的指针称为结构型指针,该指针变量的值也是它所指向的结构变量的起始地址。结构型指针也用来指向结构数组或结构数组中的元素。
定义结构型指针的一般形式为:
struct 结构类型标识符 * 结构指针标识符
其中“结构指针标识符”就是所定义的结构型指针变量的名字,“结构类型标识”就是该指针所指向的结构变量的具体类型名称。
例:struct mepoint * mp;
(2)用结构型指针引用结构元素
通过结构型指针引用结构元素的一般形式为:
结构指针→结构元素
例:mp→pressure等同于(* mp).pressure
- 结构与函数
(1)结构作为函数的参数
一般来说,结构既可作为函数的参敏,也可作为函数的返回值。当结构被用作函数的参数时,其用法与普通变量作为实参是一样的,其参数传递属于“值传递”方式。
程序在进行函数调用时,将整个结构变量作为参数传递给被调函数。系统为形式参数的结构变量分配存储空间,并从相应的实际参数中取得各个元素的值。函数对形参中各个结构无素值进行的修改不会对相应的实参结构变量产生任何影响。
(2)结构型指针作为函数的参数
当结构较大时,若将该结构作为函数的参数,由于参数传递采用值传递方式,需要较大的存储空间(堆栈)来将所有的结构元素压栈和出栈,尤其当函数参数是结构数组时,影响更大,此外还会影响程序的执行速度。实际上可以用结构型指针来作为函数的参数,此时参数的传递是按地址传递方式进行的。由于采用的是地址传递方式,只需要传递一个地址值,与前者相比,既可节省存储空间,同时还可加快程序的执行速度。缺点是在调用函数时对结构指针所作的任何变动都会影响到原来的结构变量。
(二)联合
联合也是C语言中一种构造类型的数据结构。在一个联合中可以包含多个不同类型的数据元素。各种类型的变量放在同-个地址开始的内存单元中,实现了多层数据覆盖,一方面有效地提高内存的利用率,另一方面也方便了数据类型间的转换。
- 联合的定义
定义联合类型变量的一般形式:
union 联合类型名
{ 成员表列 } 变量表列;

也可以将类型定义与变量定义分开。即先定义一个union data类型,再将a、b、c定义为union data类型的变量。

还可以直接定义联合变量。

由此可见,联合类型与结构类型的定义方法是很相似的,只是将关键字struct改成了union。但是在内存的分配上它们之间有着本质的区别。结构变量所占用的内存长度是其中各个元素所占用内存长度的总和;而联合变量所占用的时存长度是其中最长的元素的长度。联合变量中的元素分时占用相同的存储空间。
- 联合变量的引用
与结构变量类似,对联合变量的引用也是通过对联合元素的引用来实现的,引用联合元素的一般格式为:
联合变量名.联合元素
或
联合变量名->联台元素
例:
a.i //引用联合变量a中的float型元素
a.j //引用联合变量a中的long型元素
b.k //引用联合变量b中的int型元素
c.m //引用联合变量c中的char型元素
在引用联合元素时,要注意联合变量用法的一致性。因为联合类型中定义的各个不同类型的元素都可以分时地赋给变量,而所读取变量的值是最近放入的某一元素的值,因此在表达式中对它进行处理时,必须注意其类型要与表达式所要求的类型保持一致,否则将导致程序运行出错。
联合变量不能整体引用,例如下面的写法就是错误的:
printf(“%f”,a);
因为变量a可能是 float、long、int和char三种类型,分别占用不同长度的内存区域,若在引用时仅写联合变量名a,系统将难以确定究竟应该输出哪一个联合元素的值。
正确的写法为:
printf(“%f”,a.i);
联合类型的数据占用的内存空间在某一时刻只能存放一种类型的元素。