CDH5 中使用HIVE的问题总结 return code 2 from org.apache.hadoop.hive.ql.exec.mr.MapRedTask
hive> create table t2 as select * from t1;
Query ID = hadoop_20150126105050_186f3554-74bb-4388-a324-bf2c8feadb7d
Total jobs = 3
Launching Job 1 out of 3
Number of reduce tasks is set to 0 since there's no reduce operator
java.net.ConnectException: Call From hd1/192.168.1.247 to hd1:8032 failed on connection exception: java.net.ConnectException: Connection refused; For more details see: http://wiki.apache.org/hadoop/ConnectionRefused
at sun.reflect.GeneratedConstructorAccessor105.newInstance(Unknown Source) at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45)
at java.lang.reflect.Constructor.newInstance(Constructor.java:408)
at org.apache.hadoop.net.NetUtils.wrapWithMessage(NetUtils.java:791)
at org.apache.hadoop.net.NetUtils.wrapException(NetUtils.java:731)
at org.apache.hadoop.ipc.Client.call(Client.java:1472)
解决方法:
是因为节点上没有启动ResourceManager进程
[hadoop@hd1]$ jps
22450 HQuorumPeer
29683 RunJar
13269 HMaster
29096 NameNode
30318 Jps
[hadoop@hd1]$
查看yarn-ste.xml文件是否配置错误
[hadoop@hd1]$ vim yarn-site.xml
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.resourcemanager.address
hd1:8032
yarn.resourcemanager.scheduler.address
hd1:8030
yarn.resourcemanager.resource-tracker.address
hd1:8031
yarn.resourcemanager.admin.address
hd1:8033
yarn.resourcemanager.webapp.address
hd1:8088
yarn.nodemanager.aux-services.mapreduce.shuffle.class
org.apache.hadoop.mapred.ShuffleHandler
[hadoop@hd1]$ stop-all.sh --停止所有服务
This script is Deprecated. Instead use stop-dfs.sh and stop-yarn.sh
15/01/26 13:20:29 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Stopping namenodes on [hd1]
hd1: stopping namenode
tong2: no datanode to stop
tong3: no datanode to stop
15/01/26 13:20:38 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
stopping yarn daemons
no resourcemanager to stop
tong3: stopping nodemanager
tong2: stopping nodemanager
no proxyserver to stop
[hadoop@hd1]$ start-all.sh --启动所有服务
This script is Deprecated. Instead use start-dfs.sh and start-yarn.sh
15/01/26 13:21:01 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Starting namenodes on [hd1]
hd1: starting namenode, logging to /usr/local/hadoop-2.6.0/logs/hadoop-hadoop-namenode-hd1.out
tong3: starting datanode, logging to /usr/local/hadoop-2.6.0/logs/hadoop-hadoop-datanode-tong3.out
tong2: starting datanode, logging to /usr/local/hadoop-2.6.0/logs/hadoop-hadoop-datanode-tong2.out
15/01/26 13:21:13 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
starting yarn daemons
starting resourcemanager, logging to /usr/local/hadoop-2.6.0/logs/yarn-hadoop-resourcemanager-hd1.out
tong3: starting nodemanager, logging to /usr/local/hadoop-2.6.0/logs/yarn-hadoop-nodemanager-tong3.out
tong2: starting nodemanager, logging to /usr/local/hadoop-2.6.0/logs/yarn-hadoop-nodemanager-tong2.out
[hadoop@hd1]$ jps --查看ResourceManager进程是否启动
29345 ResourceManager
29601 Jps
22450 HQuorumPeer
13269 HMaster
27847 RunJar
29096 NameNode
[hadoop@hd1]$
2.用创建表的方法导入数据时出现调试信息
hive> create table t2 as select * from t1;
Query ID = hadoop_20150126132323_7f964cce-7628-47f1-b7c6-fe0ab7a9fd11
Total jobs = 3
Launching Job 1 out of 3
Number of reduce tasks is set to 0 since there's no reduce operator
Starting Job = job_1422249676009_0002, Tracking URL = http://hd1:8088/proxy/application_1422249676009_0002/
Kill Command = /usr/local/hadoop-2.6.0/bin/hadoop job -kill job_1422249676009_0002
Hadoop job information for Stage-1: number of mappers: 0; number of reducers: 0
2015-01-26 13:23:19,237 Stage-1 map = 0%, reduce = 0%
Ended Job = job_1422249676009_0002 with errors
Error during job, obtaining debugging information...
FAILED: Execution Error, return code 2 from org.apache.hadoop.hive.ql.exec.mr.MapRedTask
MapReduce Jobs Launched:
Stage-Stage-1: HDFS Read: 0 HDFS Write: 0 FAIL
Total MapReduce CPU Time Spent: 0 msec
hive>
解决方法:
hive> add jar /usr/local/hive-1.1.1/lib/hive-contrib-0.14.0.jar; --添加hive-contrib-0.14.0.jar包
Added [/usr/local/hive-1.1.1/lib/hive-contrib-0.14.0.jar] to class path
Added resources: [/usr/local/hive-1.1.1/lib/hive-contrib-0.14.0.jar]
hive> create table t2 as select * from t1;
Query ID = hadoop_20150126135959_3f589f00-4287-48ce-8446-fc044e7bf814
Total jobs = 3
Launching Job 1 out of 3
Number of reduce tasks is set to 0 since there's no reduce operator
Starting Job = job_1422249676009_0004, Tracking URL = http://hd1:8088/proxy/application_1422249676009_0004/
Kill Command = /usr/local/hadoop-2.6.0/bin/hadoop job -kill job_1422249676009_0004
Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 0
2015-01-26 13:59:39,072 Stage-1 map = 0%, reduce = 0%
2015-01-26 13:59:46,455 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 1.62 sec
MapReduce Total cumulative CPU time: 1 seconds 620 msec
Ended Job = job_1422249676009_0004
Stage-4 is selected by condition resolver.
Stage-3 is filtered out by condition resolver.
Stage-5 is filtered out by condition resolver.
Moving data to: hdfs://hd1:9000/tmp/hive/hadoop/c8ed6f95-d55d-4d1d-ba74-10170523f138/hive_2015-01-26_13-59-25_903_5009964644074632621-1/-ext-10001
Moving data to: hdfs://hd1:9000/user/hive/warehouse/tong.db/t2
Table tong.t2 stats: [numFiles=1, numRows=7, totalSize=29, rawDataSize=22]
MapReduce Jobs Launched:
Stage-Stage-1: Map: 1 Cumulative CPU: 1.62 sec HDFS Read: 239 HDFS Write: 92 SUCCESS
Total MapReduce CPU Time Spent: 1 seconds 620 msec --数据导入成功
OK
Time taken: 22.209 seconds
hive> select * from t2; --查看数据
OK
1 2
3 4
1 2
3 41
3 4
1 2
3 4
Time taken: 0.108 seconds, Fetched: 7 row(s)
hive>
3.在hadoop-2.6中查询时出错
hive> select count(*) from db_elec_fence;
Query ID = hadoop_20150130171717_84a6e727-9199-4492-87c3-be669af21288
Total jobs = 1
Launching Job 1 out of 1
Number of reduce tasks determined at compile time: 1
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=
.............................................................................................................
Task with the most failures(4):
-----
Task ID:
task_1422600506219_0007_m_000000
URL:
http://hd1:8088/taskdetails.jsp?jobid=job_1422600506219_0007&tipid=task_1422600506219_0007_m_000000
-----
Diagnostic Messages for this Task:
Container launch failed for container_1422600506219_0007_01_000011 : org.apache.hadoop.yarn.exceptions.InvalidAuxServiceException: The auxService:mapreduce_shuffle does not exist
at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method)
at sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:57)
at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45)
at java.lang.reflect.Constructor.newInstance(Constructor.java:526)
at org.apache.hadoop.yarn.api.records.impl.pb.SerializedExceptionPBImpl.instantiateException(SerializedExceptionPBImpl.java:168)
at org.apache.hadoop.yarn.api.records.impl.pb.SerializedExceptionPBImpl.deSerialize(SerializedExceptionPBImpl.java:106)
at org.apache.hadoop.mapreduce.v2.app.launcher.ContainerLauncherImpl$Container.launch(ContainerLauncherImpl.java:155)
at org.apache.hadoop.mapreduce.v2.app.launcher.ContainerLauncherImpl$EventProcessor.run(ContainerLauncherImpl.java:369)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1145)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:615)
at java.lang.Thread.run(Thread.java:745)
FAILED: Execution Error, return code 2 from org.apache.hadoop.hive.ql.exec.mr.MapRedTask
MapReduce Jobs Launched:
Stage-Stage-1: Map: 3 Reduce: 1 HDFS Read: 0 HDFS Write: 0 FAIL
Total MapReduce CPU Time Spent: 0 msec
解决方法:
在yarn-site.xml文件添加相应的属性
[root@hd1 ~]# cd /usr/local/hadoop-2.6.0/etc/hadoop/
[root@hd1 ]# vim yarn-site.xml
在yarn-site.xml 配置文件中增加:
-
yarn.nodemanager.aux-services -
mapreduce_shuffle
重启
额上述是转载的:http://blog.itpub.net/25854343/viewspace-1415529/
然而上面的方法我也 是用过了发现在CDH上没用,然并卵啊!!!
最后发现CDH5 最多的是权限问题
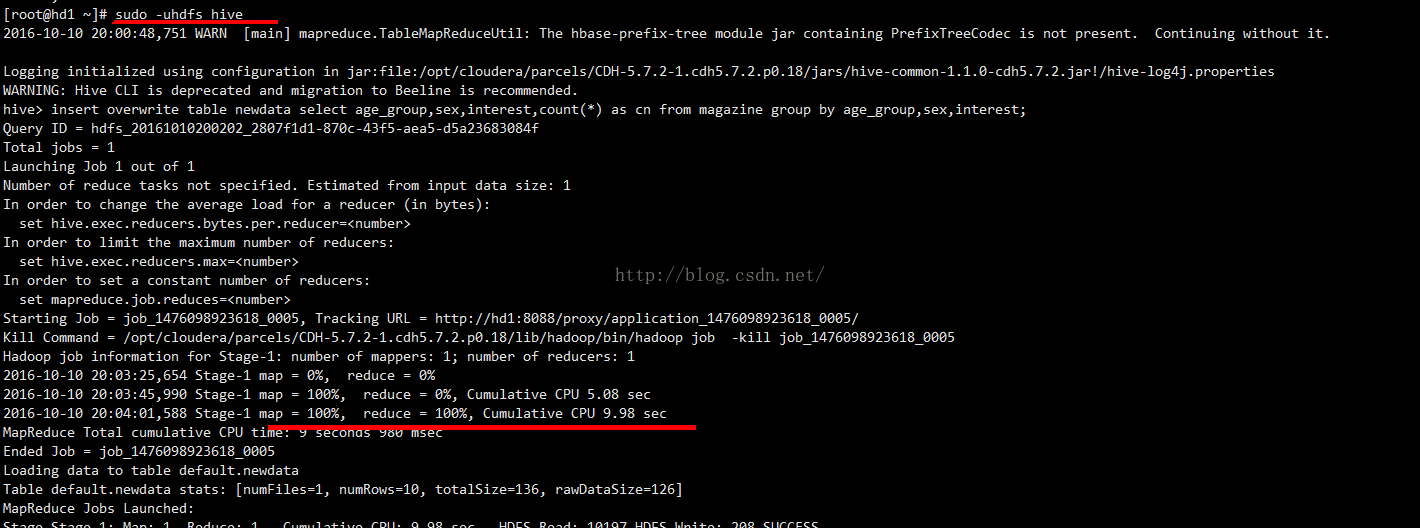
insert overwrite table newdata select age_group,sex,interest,count(*) as cn from magazine group by age_group,sex,interest;
Query ID = root_20161010194141_927452d4-f3c5-439e-ae2c-9db031d853f9
Total jobs = 1
Launching Job 1 out of 1
Number of reduce tasks not specified. Estimated from input data size: 1
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=
In order to set a constant number of reducers:
set mapreduce.job.reduces=
Starting Job = job_1476098923618_0002, Tracking URL = http://hd1:8088/proxy/application_1476098923618_0002/
Kill Command = /opt/cloudera/parcels/CDH-5.7.2-1.cdh5.7.2.p0.18/lib/hadoop/bin/hadoop job -kill job_1476098923618_0002
Hadoop job information for Stage-1: number of mappers: 0; number of reducers: 0
2016-10-10 19:41:43,604 Stage-1 map = 0%, reduce = 0%
Ended Job = job_1476098923618_0002 with errors
Error during job, obtaining debugging information...
FAILED: Execution Error, return code 2 from org.apache.hadoop.hive.ql.exec.mr.MapRedTask
MapReduce Jobs Launched:
Stage-Stage-1: HDFS Read: 0 HDFS Write: 0 FAIL
Total MapReduce CPU Time Spent: 0 msec
FAILED: Execution Error, return code 2 from org.apache.hadoop.hive.ql.exec.mr.MapRedTask
其实看jobhistory里面的application_1476098923618_0002日志发现问题
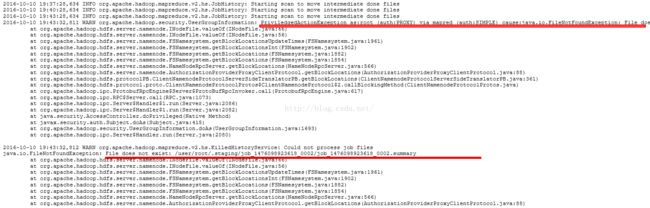
然后就用HDFS 用户来使用hive ,最终执行成功了!!!!!!!!!1
sudo -uhdfs hive