CDH的 Phoenix、hbase操作
 日萌社
日萌社
人工智能AI:Keras PyTorch MXNet TensorFlow PaddlePaddle 深度学习实战(不定时更新)
总帖:CDH 6系列(CDH 6.0、CHD6.1等)安装和使用
1.下载:https://mirrors.cnnic.cn/apache/phoenix/apache-phoenix-5.0.0-HBase-2.0/bin/apache-phoenix-5.0.0-HBase-2.0-bin.tar.gz
2.tar -zxvf apache-phoenix-5.0.0-HBase-2.0-bin.tar.gz
mv apache-phoenix-5.0.0-HBase-2.0-bin phoenix
3.把 phoenix-5.0.0-HBase-2.0-server.jar、phoenix-core-5.0.0-HBase-2.0.jar 拷贝到所有的每个节点下的 hbase/lib 的目录中
cd /root/phoenix
此处索性把所有的phoenix相关jar包进行拷贝:
CHD6.0.0:cp /root/phoenix/phoenix* /opt/cloudera/parcels/CDH-6.0.0-1.cdh6.0.0.p0.537114/lib/hbase/lib
scp /root/phoenix/phoenix* root@node2:/opt/cloudera/parcels/CDH-6.0.0-1.cdh6.0.0.p0.537114/lib/hbase/lib
scp /root/phoenix/phoenix* root@node3:/opt/cloudera/parcels/CDH-6.0.0-1.cdh6.0.0.p0.537114/lib/hbase/lib
CHD6.1.0:cp /root/phoenix/phoenix* /opt/cloudera/parcels/CDH-6.1.0-1.cdh6.1.0.p0.770702/lib/hbase/lib
scp /root/phoenix/phoenix* root@node2:/opt/cloudera/parcels/CDH-6.1.0-1.cdh6.1.0.p0.770702/lib/hbase/lib
scp /root/phoenix/phoenix* root@node3:/opt/cloudera/parcels/CDH-6.1.0-1.cdh6.1.0.p0.770702/lib/hbase/lib
4.hbase:修改hbase-site.xml配置
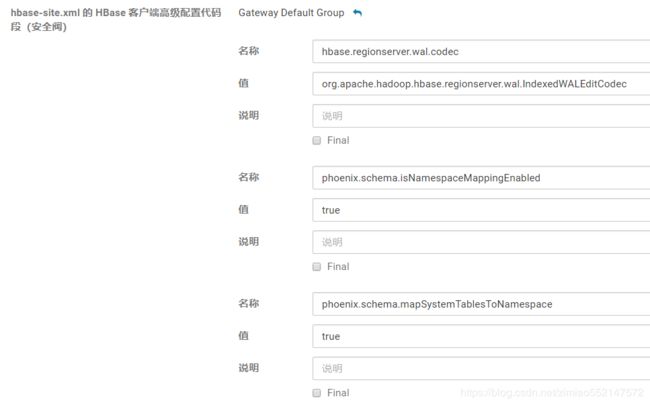
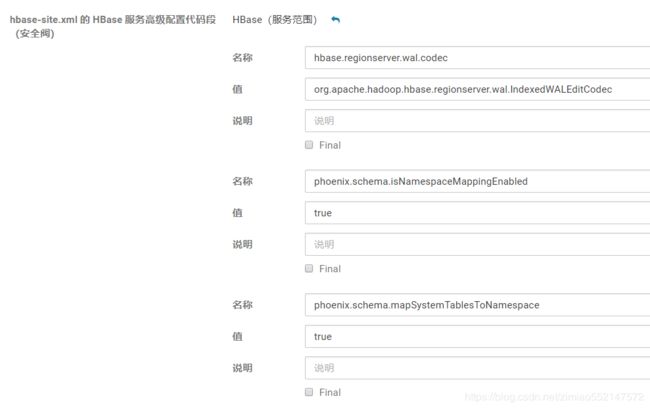
1.搜索 hbase-site.xml,下面两者都添加相同配置信息
hbase-site.xml 的 HBase 服务高级配置 代码段(会把Master和regionServer都改了, 需要重启才能生效)
hbase-site.xml 的 HBase 客户端高级配置 代码段(需要部署客户端配置才能生效)
2.hbase-site.xml 配置信息如下:(HBase 服务高级配置 和 HBase 客户端高级配置 都需要添加如下配置)
1.这个是二级索引支持
hbase.regionserver.wal.codec
org.apache.hadoop.hbase.regionserver.wal.IndexedWALEditCodec
2.这个是 命名空间开启
phoenix.schema.isNamespaceMappingEnabled
true
phoenix.schema.mapSystemTablesToNamespace
true
3.下载hbase的配置文件,点击下载客户端配置“”
把解压后的hbase-conf目录中的文件(重要如core-site.xml、hbase-site.xml、hdfs-site.xml) 拷贝并替换到 /root/phoenix/bin 目录中。
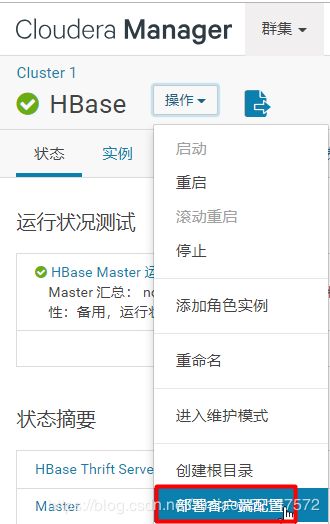
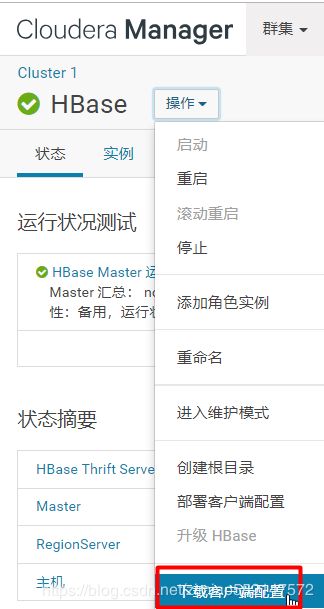
5.启动方式
1.cd /root/phoenix/bin
./sqlline.py node1:2181(2181端口可以省略)
2.(推荐)建立软连接
ln -s /root/phoenix/bin/sqlline.py /usr/bin/phoenix
phoenix node1:2181(2181端口可以省略)
6.命令操作:(命令开头需要一个感叹号,使用help可以打印出所有命令)
1.查看所有表:执行 !tables
如果没有开启namespace,即如果没有设置phoenix.schema.isNamespaceMappingEnabled为true的话,那么“SYSTEM:CATALOG”表名的中间不是冒号,而是点符号
实际是在hbase中创建出SYSTEM:CATALOG、SYSTEM:FUNCTION、SYSTEM:LOG、SYSTEM:MUTEX、SYSTEM:SEQUENCE、SYSTEM:STATS 表
2.退出Phoenix:执行 !quit
3.Phoenix建立映射表 映射 hbase表:
1.先建立hbase表并存入数据
2.注意事项:
1.建立映射表之前要说明的是,Phoenix是大小写敏感的,并且所有命令都是大写,如果你建的表名没有用双引号括起来,
那么无论你输入的是大写还是小写,建立出来的表名都是大写的,要创建小写的表名和字段名话,必须使用双引号括起来。
如果你需要建立出同时包含大写和小写的表名和字段名,请把表名或者字段名用双引号括起来。
2.你可以建立读写的表或者只读的表,他们的区别如下
读写表:如果你定义的列簇不存在,会被自动建立出来,并且赋以空值
只读表:你定义的列簇必须事先存在
3.Phoenix 4.10 版本之前,在Phoenix中建立映射表的创建语句:
CREATE TABLE IF NOT EXISTS "表名(和要映射的hbase表同名)"
( "主键ID字段名(映射hbase表的rowkey)" INTEGER NOT NULL PRIMARY KEY,
"列簇名"."列簇中的字段名" VARCHAR, # 假如hbase表中该列簇中的字段为字符串类型,则定义为VARCHAR
"列簇名"."列簇中的字段名" INTEGER # 假如hbase表中该列簇中的字段为int数值类型,则定义为INTEGER
);
1.IF NOT EXISTS:可以保证如果已经有建立过这个表,配置不会被覆盖
2.作为rowkey的字段用 PRIMARY KEY 标定
3.如果在Phoenix映射表中创建的 "列簇名"."列簇中的字段名" 是本身hbase表中存在该列簇,但该列簇中不存在该字段的话,
那么Phoenix映射表中的该新增字段的值以null填充
4.Phoenix 4.10 版本之后,在Phoenix中建立映射表的创建语句:
1.注意:Phoenix 对列的编码方式有所改变(官方文档地址:http://phoenix.apache.org/columnencoding.html)。
就拿上面的例子来说,同样是"name"这个列,看起来列名是一样的,但是 Phoenix 对这个列名进行了编码,
也就是说 Phoenix 创建的 name 列实际上和 HBase 里的 name 列不是一个列了,所以继续用CREATE TABLE 会查不出来数据。
2.解决1:
在使用 Phoenix 创建表的时候,需要设置 COLUMN_ENCODED_BYTES 属性为 0,即不让 Phoenix 对 column family 进行编码。
根据官方文档的内容,“One can set the column mapping property only at the time of creating the table”,也就是说只有在创建表的时候才能够设置属性。
CREATE TABLE "表名(和要映射的hbase表同名)" ( "ROW" varchar primary key,"列簇名"."列簇中的字段名" VARCHAR) column_encoded_bytes=0;
3.解决2:视图映射
如果只做查询操作的话,建议大家使用视图映射的方式,而非表映射。
因为一旦出现问题,例如上面提到的,在创建映射表时如果忘记设置属性(4.10版之后),那么想要删除映射表的话,HBase 中该表也会被删除,
导致数据的丢失。而如果是用视图映射,则删除视图不会影响原有表的数据。创建视图的语句同创建表差不多。
CREATE VIEW "视图名(和要映射的hbase表同名)" ( "ROW" varchar primary key,"列簇名"."列簇中的字段名" VARCHAR);
4.phoenix表 映射 hbase表 的例子:
HBase:执行 hbase shell 进入交互界面
create 'kanon','0','1'
put 'kanon', 'row001','0:name','Jane'
put 'kanon', 'row002','0:name','Tom'
put 'kanon', 'row003','0:name','Bill'
put 'kanon', 'row001','1:age',11
put 'kanon', 'row002','1:age',12
put 'kanon', 'row003','1:age',13
Phoenix:执行 phoenix node1:2181 进入交互界面
注意:Phoenix表所映射的hbase表的字段为Integer等非字符串类型的话,那么在Phoenix映射表全部字段都改为varchar字符串类型。
否则会报错如下:Illegal data. Expected length of at least xx bytes, but had xx
单纯创建Phoenix表(非映射表)是支持Integer的,可以设置为Integer。
Phoenix 4.10 及以下的版本
CREATE TABLE "kanon" ( "ROW" varchar primary key, "0"."name" varchar, "1"."age" varchar);
Phoenix 4.10 及以上的版本
CREATE TABLE "kanon" ( "ROW" varchar primary key, "0"."name" varchar, "1"."age" varchar) column_encoded_bytes=0;
(推荐)视图映射
CREATE VIEW "kanon" ( "ROW" varchar primary key, "0"."name" varchar, "1"."age" varchar);
select * from "kanon";
5.phoenix表 映射 hbase表,而 hbase表 映射 hive表 的例子:
Hive:执行 hive 进入交互界面
create database key;
use key;
CREATE TABLE ushio (key int,name string,age int,address string)
STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
WITH SERDEPROPERTIES ("hbase.columns.mapping" = ":key,f1:name,f2:age,f3:address")
TBLPROPERTIES ("hbase.table.name" = "ushio", "hbase.mapred.output.outputtable" = "ushio");
下面的语句 会启动Hive on Spark任务
insert into ushio (key,name,age,address) values(1,'nagisa',11,'japan');
insert into ushio values(2,'nagisa',22,'japan');
insert into ushio values(3,'nagisa',33,'japan'),(4,'nagisa',44,'japan'),(5,'nagisa',55,'japan');
select * from ushio;
下面的语句 会启动Hive on Spark任务
select count(*) from ushio;
HBase:执行 hbase shell 进入交互界面
list
scan 'ushio'
Phoenix:执行 phoenix node1:2181 进入交互界面
注意:Phoenix表所映射的hbase表的字段为Integer等非字符串类型的话,那么在Phoenix映射表全部字段都改为varchar字符串类型。
否则会报错如下:Illegal data. Expected length of at least xx bytes, but had xx
单纯创建Phoenix表(非映射表)是支持Integer的,可以设置为Integer。
Phoenix 4.10 及以下的版本
CREATE TABLE "ushio"("ROW" VARCHAR PRIMARY KEY,"f1"."name" VARCHAR,"f2"."age" VARCHAR,"f3"."address" VARCHAR);
Phoenix 4.10 及以上的版本
CREATE TABLE "ushio"("ROW" VARCHAR PRIMARY KEY,"f1"."name" VARCHAR,"f2"."age" VARCHAR,"f3"."address" VARCHAR) column_encoded_bytes=0;
(推荐)视图映射
CREATE VIEW "ushio"("ROW" VARCHAR PRIMARY KEY,"f1"."name" VARCHAR,"f2"."age" VARCHAR,"f3"."address" VARCHAR);
select * from "ushio";
5.需要将原有 HBase 中的表做映射才能后使用 Phoenix 操作。
Phoenix 区分大小写,切默认情况下会将小写转成大写,所以表名、列簇、列名需要用双引号。
Phoenix 4.10 版本之后,在创建表映射时需要将 COLUMN_ENCODED_BYTES 置为 0。
删除映射表,会同时删除原有 HBase 表。所以如果只做查询炒作,建议做视图映射。
6.主键:constraint pk primary key(字段名)
例子:单主键 constraint pk PRIMARY KEY("id")、双主键 constraint pk PRIMARY KEY("id","name")
唯一约束:constraint uk unique key(字段名)
默认约束:constrint df default('默认值') for 字段名
检查约束:constraint ck check(约束,如 len(字段名)>1)
主外键关系:constraint fk foreign(外键字段名) references 主表(主表主键字段名)
4.Phoenix中查询映射表数据
select * from "表名";
5.Phoenix中插入、更改映射表数据之后,实际就是对hbase中的数据进行插入和修改操作
1.在phoenix中插入或者更改操作均使用upsert关键字,如果表中不存在该数据则插入,否则更新
2.插入:upsert into "表名" values('123456',123456);
3.修改:upsert into "表名" ("字段名","字段名") VALUES ('123456',123456);
6.删除表:drop table "表名"; 注意:删除表的话,也同时会把所映射的hbase表也一起删除
删除视图drop view "表名";
7.Phoenix执行sql脚本
cd /root/phoenix/bin
./psql.py node1,node2,node3:2181 xxx.sql
ln -s /root/phoenix/bin/psql.py /usr/bin/psql
psql node1,node2,node3:2181 xxx.sql
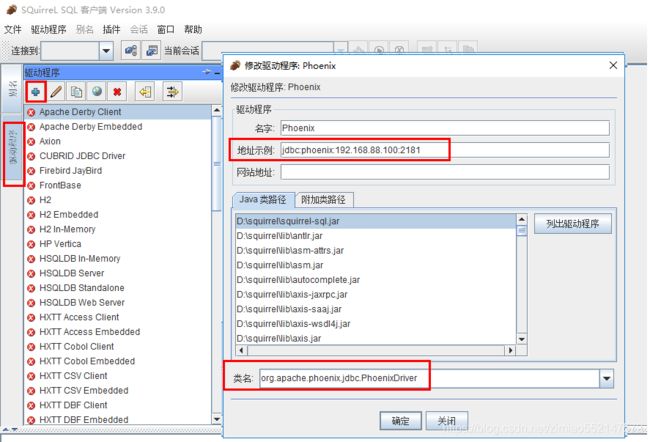
8.window客户端squirrel操作:
1.下载squirrel-sql-3.9.0-standard.jar
https://sourceforge.net/projects/squirrel-sql/files/1-stable/3.9.0/squirrel-sql-3.9.0-standard.jar/download
2.window命令窗口 安装squirrel-sql-3.9.0-standard.jar(不在中文路径下安装该文件)
执行命令 java -jar squirrel-sql-3.9.0-standard.jar 后弹出安装窗口
其中的安装选项可勾选全部,即可用于连接多种不同类型数据,安装大小70m
3.拷贝配置文件和jar包
1.把 apache-phoenix-5.0.0-HBase-2.0-bin.tar.gz 解压后的目录中所有的jar包拷贝到 squirrel安装目录的lib下
2.把 hbase-site.xml 拷贝到 squirrel安装目录
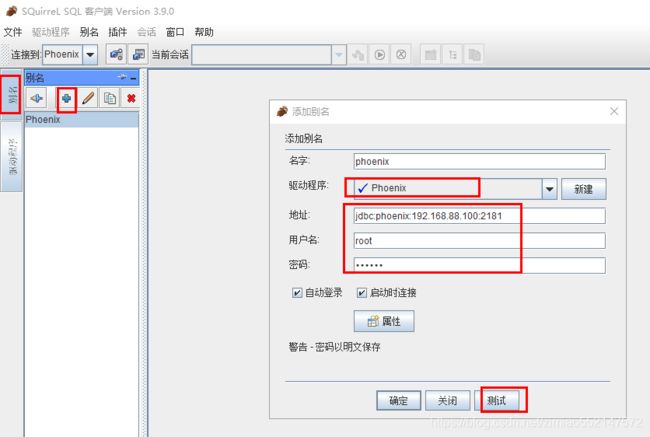
3.squirrel 配置连接 Phoenix
1.输入 jdbc:phoenix:192.168.88.100:2181 和 org.apache.phoenix.jdbc.PhoenixDriver
9.hbase API操作 hbase表、Phoenix API操作 Phoenix表、Phoenix API操作“映射hbase表的”Phoenix表
1.如果maven所依赖的jar包始终无法加载成功,可以执行如下
call mvn -f pom.xml dependency:copy-dependencies
mvn clean
mvn install
2.依赖
org.apache.phoenix
phoenix-core
5.0.0-HBase-2.0
org.apache.hadoop
hadoop-auth
3.0.0
3.hbase API操作 hbase表、Phoenix API操作 Phoenix表、Phoenix API操作“映射hbase表的”Phoenix表 都需要在 resources目录下 添加 hbase-site.xml
![]()
hbase.rootdir
hdfs://nameservice1/hbase
hbase.client.write.buffer
2097152
hbase.client.pause
100
hbase.client.retries.number
10
hbase.client.scanner.caching
100
hbase.client.keyvalue.maxsize
10485760
hbase.ipc.client.allowsInterrupt
true
hbase.client.primaryCallTimeout.get
10
hbase.client.primaryCallTimeout.multiget
10
hbase.client.scanner.timeout.period
60000
hbase.coprocessor.region.classes
org.apache.hadoop.hbase.security.access.SecureBulkLoadEndpoint
hbase.regionserver.thrift.http
false
hbase.thrift.support.proxyuser
false
hbase.rpc.timeout
60000
hbase.snapshot.enabled
true
hbase.snapshot.region.timeout
300000
hbase.snapshot.master.timeout.millis
300000
hbase.security.authentication
simple
hbase.rpc.protection
authentication
zookeeper.session.timeout
60000
zookeeper.znode.parent
/hbase
zookeeper.znode.rootserver
root-region-server
hbase.zookeeper.quorum
node3,node1,node2
hbase.zookeeper.property.clientPort
2181
hbase.rest.ssl.enabled
false
hbase.regionserver.wal.codec
org.apache.hadoop.hbase.regionserver.wal.IndexedWALEditCodec
phoenix.schema.isNamespaceMappingEnabled
true
phoenix.schema.mapSystemTablesToNamespace
true
注意:如果 hbase-site.xml中 不配置 phoenix.schema.isNamespaceMappingEnabled 为 true的话,
则会报错如下
Inconsistent namespace mapping properties. Cannot initiate connection as SYSTEM:CATALOG is found
but client does not have phoenix.schema.isNamespaceMappingEnabled enabled
4.hbase中 建立employee的映射表:数据准备
进入 hbase 交互模式:shell命令 连接集群(任意一个路径下访问都可以):hbase shell
1.数据准备然后,我们来建立一个映射表,映射我之前建立过的一个hbase表 employee,有2个列族 company、family
1.create 'employee','company','family'
2.put 'employee','row1','company:name','ted'
put 'employee','row1','company:position','worker'
put 'employee','row1','family:tel','13600912345'
put 'employee','row2','company:name','michael'
put 'employee','row2','company:position','manager'
put 'employee','row2','family:tel','1894225698'
3.scan 'employee'
2.在建立映射表之前要说明的是,Phoenix是大小写敏感的,并且所有命令都是大写,如果你建的表名没有用双引号括起来,
那么无论你输入的是大写还是小写,建立出来的表名都是大写的,要创建小写的表名和字段名话,必须使用双引号括起来。
如果你需要建立出同时包含大写和小写的表名和字段名,请把表名或者字段名用双引号括起来。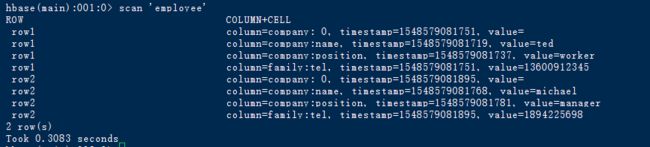
5.phoenix中 建立 phoenix表
CREATE TABLE IF NOT EXISTS "user" ("no" VARCHAR NOT NULL PRIMARY KEY, "name" VARCHAR,"position" VARCHAR(20),"tel" VARCHAR(20));
upsert into "user" values('row1','qwe','eqw','12121');
upsert into "user" values('row2','qwe','eqw','12121');
upsert into "user" values('row3','qwe','eqw','12121');
6.phoenix中 建立映射hbase表的 phoenix表
cd /root/phoenix/bin
./sqlline.py NODE1:2181 # 端口可以省略 (hbase表 employee,有2个列族 company、family)
CREATE TABLE IF NOT EXISTS "employee" ("ROW" VARCHAR(10) NOT NULL PRIMARY KEY, "company"."name" VARCHAR(30),"company"."position" VARCHAR(20), "family"."tel" VARCHAR(20), "family"."age" INTEGER);
这个语句有几个注意点:
1.IF NOT EXISTS:可以保证如果已经有建立过这个表,配置不会被覆盖
2.作为rowkey的字段用 PRIMARY KEY 标定
3.列簇用 columnFamily.columnName 来表示,如:"company"."name"
4.family.age("family"."age") 是新增的字段,我之前建立测试数据的时候没有建立这个字段的原因是在hbase shell下无法直接写入数字型,
使用UPSERT 命令插入数据的时候你就可以看到真正的数字型在hbase 下是如何显示的。建立好后,查询一下数据
7.hbase API操作 hbase表 代码
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.*;
import org.apache.hadoop.hbase.client.*;
import org.apache.hadoop.hbase.util.Bytes;
import java.io.IOException;
import java.util.List;
// 1)创建一个hbase的connection
Configuration config = HBaseConfiguration.create();
Connection connection = ConnectionFactory.createConnection(config);
//拿到这个表才能对该表进行表操作:connection.getTable(TableName.valueOf("表名"))
Table user1 = connection.getTable(TableName.valueOf("employee"));
ResultScanner scanner = user1.getScanner(scan);
Result result1 = null;
while ((result1 = scanner.next())!=null)
{
List| cells1 = result1.listCells();
for (Cell cell : cells1)
{
// 打印rowkey,family列簇,qualifier列名,value列值
System.out.println(Bytes.toString(CellUtil.cloneRow(cell)) //rowkey
+ "==> " + Bytes.toString(CellUtil.cloneFamily(cell)) //family列簇
+ "{" + Bytes.toString(CellUtil.cloneQualifier(cell)) //qualifier列名
+ ":" + Bytes.toString(CellUtil.cloneValue(cell)) + "}"); //value列值
}
}
user1.close();//表关闭 | 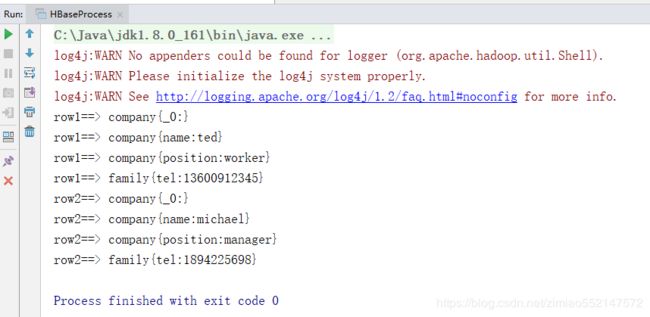
8.Phoenix API操作 Phoenix表 代码
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.sql.Statement;
public class phoenix
{
public static void main(String[] args) throws SQLException {
Connection conn = null;
Statement state = null;
ResultSet rs = null;
try {
Class.forName("org.apache.phoenix.jdbc.PhoenixDriver");
conn = DriverManager.getConnection("jdbc:phoenix:node1:2181");
state = conn.createStatement();
//CREATE VIEW "ushio"("ROW" VARCHAR PRIMARY KEY,"f1"."name" VARCHAR,"f2"."age" VARCHAR,"f3"."address" VARCHAR);
rs = state.executeQuery("select * from \"ushio\"");
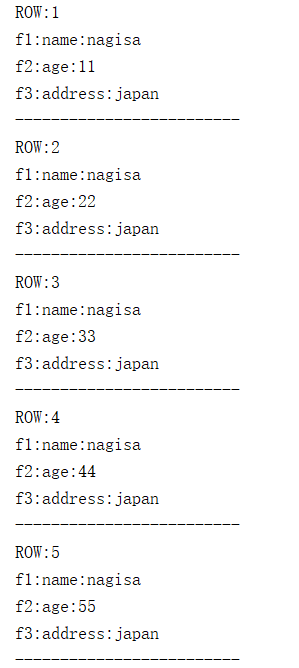
while (rs.next())
{
System.out.println("ROW:" + rs.getString("ROW"));
System.out.println("f1:name:" + rs.getString("name"));
System.out.println("f2:age:" + rs.getString("age"));
System.out.println("f3:address:" + rs.getString("address"));
System.out.println("-------------------------");
}
} catch (Exception e) {
e.printStackTrace();
} finally {
if (rs != null) rs.close();
if (state != null) state.close();
if (conn != null) conn.close();
}
}
}