文章来自百度文库R 语言入门, 略有修改
其中部分参考y叔和生信技能树jimmy大神的帖子
https://wenku.baidu.com/view/e3515cfd04a1b0717fd5ddc5.html?sxts=1532068903493
R语言的由来
- R语言是从S语言演变而来的。
- S语言是二十世纪70年代诞生于贝尔实验室,由Rick Becker, John Chambers, Allan Wilks开发。
- 基于S语言开发的商业软件Splus,可以方便的编写函数、建立模型,具有良好的扩展性,取得了巨大成功。
- 1995年由新西兰Auckland大学统计系的Robert Gentleman和Ross Ihaka,编写了一种能执行S语言的软件,并将该软件的源代码全部公开,这就是R软件,其命令统称为R语言。
R包的安装、卸载和升级
R包的安装
- 普通安装
install.packsages()
2.bioconductor包安装
source("http://bioconductor.org/biocLite.R")
install.packages('hgu133a.db')
3.github包安装
install.packages("devtools")
devtools::install_github("GuangchuangYu/rvcheck")
- 镜像安装
library(devtools)
source("https://bioconductor.org/biocLite.R")
options("repos" = c(CRAN="https://mirrors.tuna.tsinghua.edu.cn/CRAN/"))
options(BioC_mirror="https://mirrors.ustc.edu.cn/bioc/")
BiocInstaller::biocLite('hgu133a.db')
3.如何更新R以及RStudio
section1 win用包更新R
install.packages("installr")
require(installr)
updateR()
section2 ios用包更新R
install.packages('devtools') #assuming it is not already installed
library(devtools)
install_github('andreacirilloac/updateR')
library(updateR)
updateR(admin_password = 'Admin user password')
section3 更新Rstudio
- open RStudio
- click on “help” and “Check for Updates”
- if there are any updates, you will jump >to https://www.rstudio.com/products/rstudio/download/#download
- then choose the version you like and click on “download”
- click on “RStudio ???-XXX”[where ??? is the version and XXX is your operating system]
- it may too slow to download complete, so you should use XUNLEI to download
- follow the installation procedure for your operating system
- restart RStudio
- rejoice
section4 更新全部包
来源如下,致敬y叔
- https://mp.weixin.qq.com/s?__biz=MzI5NjUyNzkxMg==&mid=2247484173&idx=1&sn=ad1817e4acd1362428b3beaa1cd4fede&scene=21#wechat_redirect
- https://github.com/GuangchuangYu/rvcheck
Get the released version from CRAN:
install.packages("rvcheck")
Or the development version from github:
install.packages("devtools")
devtools::install_github("GuangchuangYu/rvcheck")
Examples
update.packages( )
library(rvcheck)
check_r()
check_bioc('ggtree')
check_cran('emojifont')
check_github("guangchuangyu/clusterProfiler")
section5 更新全部包R语言-查看加载包、卸除加载包及安装包与卸载包
来源文件如下
https://www.cnblogs.com/awishfullyway/p/6633700.html
- 1、查看已加载的包
(.packages())
注意外面的括号和前面的点不能省。
- 2、卸除已加载的包
如卸除RMySQL包
detach("package:RMySQL")
注意是卸除,不是卸载,也就是说不是把包从R运行环境中彻底删除,只是不希望该包被加载使用。
在包使用函数冲突,检验函数依赖时比较有用。
- 3、卸载已加载的包
彻底删除已安装的包:
remove. packages(c("pkg1","pkg2") , lib = file .path("path", "to", "library"))
section6 查看已安装的包及函数
installed.packages()[,c('Package','Version','LibPath')]
其中c('Package','Version','LibPath') 表示显示包名、版本、库路径信息,若无[,c('Package','Version','LibPath')]参数,则显示所有信息。
- 查看某个包提供的函数
help(package='TSA')
package参数为要查看的包的包名。
- 查看某个函数属于哪个包
help(函数名)
在打开的网页中查看属于哪个包。
常用R程序包
- base- R 基础功能包
- stats- R统计学包
- nlme- 线性及非线性混合效应模型
- Graphics- 绘图
- lattice- 栅格图
- ape- 系统发育与进化分析
- apTreeshape- 进化树分析
- seqinr- DNA序列分析
- ade4- 利用欧几里得方法进行生态学数据分析
- cluster- 聚类分析
- ecodist- 生态学数据相异性分析
- mefa- 生态学和生物地理学多元数据处理
- mgcv- 广义加性模型相关
- mvpart- 多变量分解
- nlme- 线性及非线性混合效应模型
- ouch- 系统发育比较
- BiodiversityR - 基于Rcmdr的生物多样性数据分析
- vegan- 植物与植物群落的排序,生物多样性计算
查看帮助文件
1 help("t.test")
2 ?t.test
3 help.search("t.test")
4 apropos("t.test")
5 RGui>Help>Html help
6 查看R包pdf手册
帮助文件的内容
以lm函数为例:
lm(stats) #函数名及所在包
Fitting Linear Models # 标题
Description #函数描述
Usage # 默认选项
Arguments # 参数
Details # 详情
Author(s) # 作者
References # 参考文献
Examples # 举例
数据表的行与列
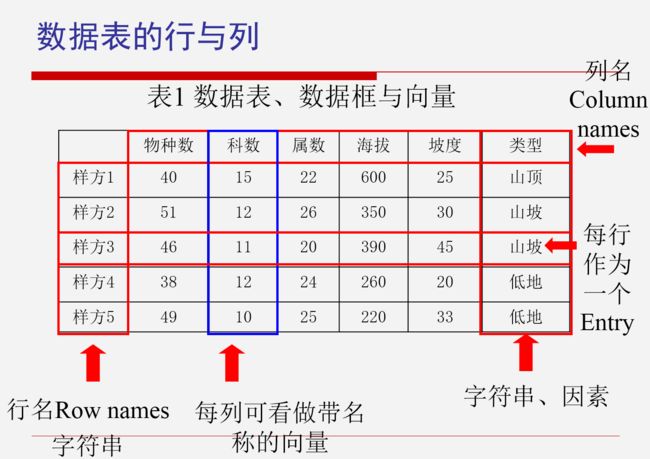 image.png
image.png
对象的类型
- 数值型 Numeric 如 100, 0, -4.335
- 字符型 Character 如 “China”
- 逻辑型 Logical 如TRUE, FALSE
- 因子型 Factor 表示不同类别
- 复数型 Complex 如:2 + 3i
对象的类别
- 向量(vector) 一系列元素的组合。
- 因子(factor) 因子是一个分类变量,如“a”,”a”,”a”,”a”,”b”,”b”,”b”,”c”,”c”
- 数组(array) 数组是k维的数据表。
- 矩阵(matrix) 矩阵是数组的一个特例,维数k = 2。
- 数据框(dataframe) 是由一个或几个向量和(或)因子构成,它们必须是等长的,但可以是不同的数据类型。
- 列表(list) 列表可以包含任何类型的对象。
(据Paradis, 2005)
运算符
数学运算 运算后给出数值结果
+, -, *, /, ^
比较运算 运算后给出判别结果(TRUE FALSE)
<, >, <=, >=, ==, !=
逻辑运算 与、或、非
!, &, &&, |, ||
外部数据读取
最为常用的数据读取方式是用read.table() 函数或read.csv()函数读取外部txt或csv格式的文件。
txt文件,制表符间隔
csv文件,逗号间隔
sep 是函数的形式参数,多数情况下, seq 参数用来指定字符的分隔符号。不仅用在你所提到的输出,也用在输入,也用在字符串的合并与拆分上。csv 文件是用逗号分隔的,故而 sep = ",", tsv 文件是用制表符分隔的,故而 sep = "\t"常用的分隔符还有空格 sep = " "
data <- read.table('cancer.txt', header=TRUE)
header=TRUE代表读入数据时将第一行作为列名(若是FALSE则相反,不使用文件中第一行作为列名),也可以简写问header=T(或是header=F)
不用指定sep参数,因为read.txt函数默认参数sep='\t'。当然愿意的话你也可以指定,那样的话会显得有点多余
一些R程序包(如foreign)也提供了直接读取Excel, SAS, dbf, Matlab, spss, systat, Minitab文件的函数。
data <- read.txt('cancer.csv', header=TURE, sep=',')
必须指定sep=','不指定不会报错但是会出现你读入的数据只有一列的情况
data <- read.csv('cancer.txt', header=TURE, sep='\t')
必须指定sep参数
读入csv文件
data <- read.csv('cancer.csv', header=TURE)
不强制指定sep参数,因为默认sep=','
总结:格式一致不指定分隔符,格式不一致必须指定分隔符。
例:
test.data<-read.table("D:/R/test2.txt",header=T)
header=T表示将数据的第一行作为标题。
read.table(file=file.choose(),header=T) 可以弹出对话框,选择文件。
从txt文档读取数据。每一行作为一个观测值。每一行的变量用制表符,空格或逗号间隔开。
read.table(”位置”, header=T)
read.csv(”位置”,header=T)
data1<-read.table("d:/t.test.data.txt",header=T)
bmi<- data1$weight/data1$height^2
t.test(bmi, mu=22.5) #t检验
R函数调用及其选项
函数的调用方法, 函数名+() 如 plot(), lm(),并将对象放入括号中,“=”表示设定参数。
例如:
boxplot(day~type, data=bac, col="red", xlab="Virus", ylab="days")
day~type,以type为横轴,day为纵轴绘制箱线图。
data=bac,数据来源bac
col="red",箱线图为红色
xlab="Virus", 横轴名称为Virus
ylab="days" ,纵轴名称为days
实例:从数据输入到单因素方差分析
将三种不同菌型的伤寒病毒a,b,c分别接种于10,9,和11只小白鼠上,观察其存活天数,问三种菌型下小白鼠的平均存活天数是否有显著差异。
a菌株:2, 4, 3, 2, 4, 7, 7, 2, 5, 4
b菌株:5, 6, 8, 5, 10, 7, 12, 6, 6
c菌株:7,11,6, 6, 7, 9, 5, 10, 6, 3, 10

数据读取,将test1.txt中的内容保存到bac中, header=T表示保留标题行。
# 将ba数据框中的type转换为因子(factor)
bac$type<-as.factor(bac$type)
ba.an<-aov(lm(day~type, data=bac))
summary(ba.an)
boxplot(day~type,data=bac,col="red")
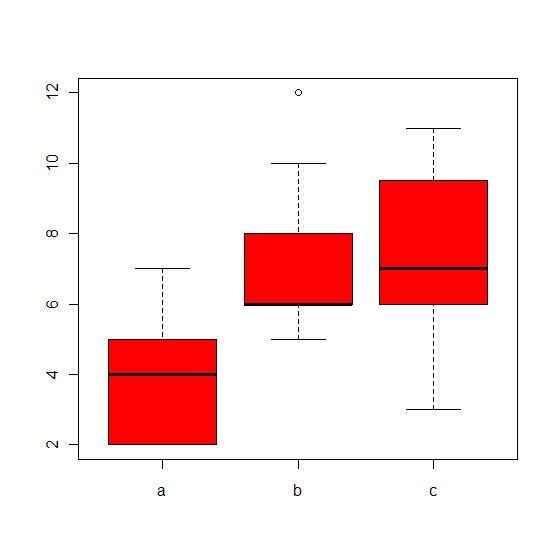
三种菌型对小白鼠影响的箱线图
定义矩阵的维度
x <- 1:12
dim(x) <- c(3,4)
[,1] [,2] [,3] [,4]
[1,] 1 4 7 10
[2,] 2 5 8 11
[3,] 3 6 9 12
matrix.x <- matrix(1:12,nrow=3,byrow=T)
t(x)#转置
为行或列添加名称:
row.names()
col.names()
数据框的创建
country.data<-cbind(character,numeric,logical)
rbind() # 按行组合成数据框
data.frame() #生成数据框
d <- data.frame(character,numeric,logical)
head(d) #访问数据的前6行:
列表的创建
列表可以是不同类型甚至不同长度的向量(数值型,逻辑型,字符型等等)、数据框甚至是列表的组合。
list()
例如
list(character,numeric,logical,matrix.x)
对象类型判断
class()
is.numeric() #返回值为TRUE或FALSE
is.logical()
is.charactor()
is.data.frame()
对象类型转换
as.logical()
as.charactor()
as.matrix()
as.dataframe()
$ 提取
d$intake.pre
[,] 方括号引用
d[,1]; d[5,]
访问数据框内的元素
-
直接调用数据框内的列向量
attatch()
detatch()
-
在函数内部,对数据进行相应调整
subset()
within()
transform()
条件筛选
条件筛选是先对变量否满足条件进行判断,满足为TRUE,不满足为FALSE。之后再用逻辑值对向量内的元素进行筛选。
[1] FALSE FALSE FALSE FALSE FALSE FALSE FALSE TRUE TRUE TRUE TRUE
intake.pre[intake.pre > 7000]
intake.post[intake.pre > 7000 & intake.pre <= 8000]
intake.pre > 7000 & intake.pre <= 8000
排序
将向量中的元素按照一定顺序排列。
sort() 按数值大小排序
举例:
sort(intake$post)
order() 给出从小到大的出现序号。
order(intake$post)
o <- order(intake$post)
在R中,和排序相关的函数主要有三个:sort(),rank(),order()。
sort(x)是对向量x进行排序,返回值排序后的数值向量。rank()是求秩的函数,它的返回值是这个向量中对应元素的“排名”。而order()的返回值是对应“排名”的元素所在向量中的位置。
下面以一小段R代码来举例说明:
> x<-c(97,93,85,74,32,100,99,67)
> sort(x)
[1] 32 67 74 85 93 97 99 100
> order(x)
[1] 5 8 4 3 2 1 7 6
> rank(x)
[1] 6 5 4 3 1 8 7 2
工作空间
ls() 列出工作空间中的对象
rm() 删除工作空间中的对象
rm(list=ls()) 删除空间中所有对象
save.image() 保存工作镜像
sink() 将运行结果保存到指定文件中
getwd() 显示当前工作文件夹
setwd() 设定工作文件夹
了解工作路径
- 1 查看当前R工作的空间目录
getwd()
- 2 将R工作的路径设置为 d:/data/
setwd(“d:/data”)
编辑器
R自带的脚本编辑器
Editplus (www.editplus.com )
TinnR (http://www.sciviews.org/Tinn-R/ )
Ultraedit (www.ultraedit.com/ )
Emacs (www.gnu.org/software/emacs/ )
Notepad++ 与NpptoR组合
(http://notepad-plus.sourceforge.net/ )
记事本或写字板 等等
运行脚本
三种运行方式
- 1 通过source()函数运行
source(“d:/regression.r”) - 2 通过R脚本编辑器运行
路径:RGui>File>Open Script #Ctrl+R运行 - 3 直接粘贴到R控制台
ctrl+c, ctrl+v
低水平绘图函数
lines() 添加线
curve() 添加曲线
abline() 添加给定斜率的线
points() 添加点
segments() 折线
arrows() 箭头
axis() 坐标轴
box() 外框
title() 标题
text() 文字
mtext() 图边文字
...
高水平绘图函数
hist() 直方图
boxplot() 箱线图
stripchart() 点图
barplot() 条形图
dotplot() 点图
piechart() 饼图
interaction.plot()
matplot()
...
参数用在函数内部,在没有设定值时使用默认值。
font= 字体
lty= 线类型
lwd= 线宽度
pch= 点的类型,
xlab= 横坐标
ylab= 纵坐标
xlim= 横坐标范围
ylim= 纵坐标范围
par()
par(mfrow=c(2,2)
注意:ggplot2中图形函数与R基础图形函数有区别,例如
ggplot2中线宽 size=
ggplot2颜色填充 fil=
col= 为线框的颜色
举例:
hist(x,freq=F) # 绘制直方图
curve(dnorm(x),add=T) # 添加曲线
h <- hist(x, plot=F) # 绘制直方图
ylim <- range(0, h$density, dnorm(0)) #设定纵轴的取值范围
hist(x, freq=F, ylim=ylim) #绘制直方图
curve(dnorm(x),add=T,col="red") #添加曲线
 image.png
image.png
数据保存
sink()
unlink()
若有LaTeX基础,可以用
Sweave() 函数
该函数能将脚本、程序说明和运算结果直接保存成.tex文件,用LaTeX编译成pdf文件。