Neo4j数据库语言Cypher
Cypher是图数据库Neo4j的操作语言,通过它可以实现对Neo4j的存储和查询等操作。受SQL启发,Cypher采用陈述性的语言去描述图结构。而且我们只需要指出图数据库中希望增删改查的数据而不必关心如何实现它。Cypher语法用一种可视化的且符合逻辑的方式去匹配图数据库中的节点和关系。这种方式叫做ASCII-art,即通过字符的形式来抽象表示图结构,例如neo4j通过()表示节点,-->表示节点间的关系。
1、结构的表示
节点
Cypher用()表示图数据库中的节点,在括号中可以定义节点的变量名、所属标签和属性等详细信息,如果是一个空括号代表一个匿名的节点。如果为节点指定了变量名,则可以在之后通过变量名对节点进行操作或返回。
可以将同一类的节点添加标签,例如为人名添加标签Person,在标签名之前加一个冒号。标签就像传统关系型数据库中的表名,通过添加标签不仅可以更好地将节点分类,而且在查找时如果指定了标签名,数据库只会查找带有标签的节点而不是所有节点,这极大地增强了查找的效率。标签的命名采用首字母大写的驼峰命名法。
可以在节点的小括号内用大括号{}包裹的键值对的形式为节点添加属性,用以描述节点的更多性质,属性采用首字母小写的驼峰命名法。
() //匿名节点
(p) //将节点命名为p
(:Technology) //带有标签类的节点
(p:Person) //带有标签类的节点,并指定其变量名为p
(p:Person {name: 'Jennifer'}) //给节点添加属性name关系
节点之间的关系通过有方向箭头-->或者<--来表示,在箭头中间通过中括号[]来定义关系变量名、关系类型及相关属性。
同样地,在关系的类型名之前需要加冒号,如果没有则代表变量名而非类型名。关系的命名全部大写,中间用下划线连接。
以大括号包裹键值对的形式为关系添加属性用以描述关系的详细信息
在匹配时可以使用无方向箭头--,表示匹配两个方向的该关系。
//定义Person指向Technology的LIKES关系,并定义该关系变量为rel
(p:Person)-[rel:LIKES]->(t:Technology)
//定义包含属性的关系
(:Person)-[:LIKES {since:2019}]->(:Technology)
//匹配两个Person类之间的LIKES关系,不指定方向
MATCH (:Person)-[:LIKES]-(:Person) 将节点和关系连接起来就构成了路径/模式,路径的表示如下。
(a)-[*2]->(b) //表示路径长度为2,起始节点是a,终止节点是b;
(a)-[*3..5]->(b) //表示路径长度的最小值是3,最大值是5,起始节点是a,终止节点是b;
(a)-[*]->(b) //表示不限制路径长度,起始节点是a,终止节点是b;
2、数据库操作
Cypher保留了一些关键字用于实现对于数据库的增删改查的操作,关键字不区分大小写。
查询
MATCH关键字用于匹配图数据库中的节点、关系、标签、属性和路径等内容,类似于SQL中的select关键字。
RETURN关键字用于将查询到的结果进行返回,只有将指定内容命名为一个变量才可以通过return进行返回。
//查询名字为Jennifer的人并返回
MATCH (jenn:Person {name: 'Jennifer'})
RETURN jenn
//查询Jennifer工作的公司并返回公司的名字属性
MATCH (:Person {name: 'Jennifer'})-[:WORKS_FOR]->(company:Company)
RETURN company.nameAS关键字用于为返回的结果指定别称,例如下面的查询返回属性名为NO而不是kristen.customerIdNo
MATCH (kristen:Customer {name:'Kristen'})-[rel:PURCHASED]-(order:Order)
RETURN kristen.customerIdNo AS NOWHERE关键字用于对查找的条件进行限制,可以配合逻辑关键字NOT、AND、OR、XOR和比较符号一起使用。
通过方法exist()可以判别节点或关系是否含有某种属性。
//查找名字不是Jennifer的Person节点
MATCH (j:Person)
WHERE NOT j.name = 'Jennifer'
RETURN j
//查找年龄介于3~7之间的Person节点
MATCH (p:Person)
WHERE 3 <= p.age <= 7
RETURN p
// 查找年龄是5、6、7的Person节点
MATCH (p:Person)
WHERE p.age IN [5, 6, 7]
RETURN p
//查找包含birthdate属性的Person节点
MATCH (p:Person)
WHERE exists(p.birthdate)
RETURN pCypher支持使用子查询,将子查询用大括号包裹,其使用格式如下
MATCH (p:Person)
WHERE EXISTS { //前括号与主句在同一行
MATCH (p)-->(c:Company) //子查询另起一行,缩进两个空格
WHERE c.name = 'Neo4j'
} //后括号另起一行
RETURN p.name;可以通过关键字START WITH、CONTAINS、END WITH来对字符串进行匹配,也可以使用正则表达式进行字符串匹配
//查找名字以'M'开头的节点
MATCH (p:Person)
WHERE p.name STARTS WITH 'M'
RETURN p.name
//查找名字中包含'a'的节点
MATCH (p:Person)
WHERE p.name CONTAINS 'a'
RETURN p.name
//查找名字以'n'结尾的节点
MATCH (p:Person)
WHERE p.name ENDS WITH 'n'
//正则表达式匹配
MATCH (p:Person)
WHERE p.name =~ 'Jo.*'
RETURN p.nam匹配的条件不仅可以是属性,还可以是关系模式,例如匹配一个这样的p-r->friend关系,条件是p存在p-:WORKS_FOR->:Company关系
MATCH (p:Person)-[r:IS_FRIENDS_WITH]->(friend:Person)
WHERE exists((p)-[:WORKS_FOR]->(:Company {name: 'Neo4j'}))
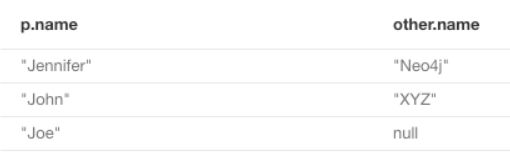
RETURN p, r, friend通过关键字OPTIONAL MATCH可以达到可选择匹配的效果。例如匹配名字以'J'开头的人p,可选的匹配条件是p为一家公司工作
MATCH (p:Person)
WHERE p.name STARTS WITH 'J'
OPTIONAL MATCH (p)-[:WORKS_FOR]-(other:Company)
RETURN p.name, other.name查询结果如下图所示,返回了名字以'J'开头的人,并且匹配了p工作的公司,最后一个Joe没有为某家公司工作,因此other.name为null。但是由于可选匹配第二个条件,因此只满足第一个条件的结果也被返回了。如果不加OPTIONAL则只会返回前两条结果,因为两个MATCH条件默认是使用AND逻辑与进行连接的。
增加
CREATE关键字用于创建节点、关系或者一个模式
//创建一个Person节点
CREATE (friend:Person {name: 'Mark'})
//创建一个模式,包括两个Person节点j、m和两者之间的关系
CREATE (j:Person {name: 'Jennifer'})-[rel:IS_FRIENDS_WITH]->(m:Person {name: 'Mark'})如果只希望创建一个关系而不是模式,例如原来的数据库中已经存在j、m两个节点,我们只希望创建两者之间的关系,则需要首先查找出数据库中的两个节点,然后用变量指代,再创建关系
MATCH (j:Person {name: 'Jennifer'})
MATCH (m:Person {name: 'Mark'})
CREATE (j)-[rel:IS_FRIENDS_WITH]->(m) //只创建关系MERGE关键字用于匹配或创建,及它会首先进行匹配节点、关系或模式,如果存在则返回结果(相当于MATCH),否则进行创建(相当于CREATE)。例如下面的语句,如果数据库中存在name为Mark的Person节点,则返回查询到的mark,否则会创建一个新的mark节点
MERGE (mark:Person {name: 'Mark'})
RETURN mark需要注意的是Cypher不会进行部分的匹配。例如下面的语句,如果数据库存在节点j、m,我们希望插入二者之间的关系r,使用MERGE不会只匹配中间的关系r,而是匹配整个模式j-r->m,它会认为数据库中不存在这个模式,从而插入整个模式,这样会导致节点j、m的重复从而操作失败。
MERGE (j:Person {name: 'Jennifer'})-[r:IS_FRIENDS_WITH]->(m:Person {name: 'Mark'})
RETURN j, r, m正确的插入关系方法如下,首先匹配出已存在的两个节点,再通过Merge进行插入
MATCH (j:Person {name: 'Jennifer'})
MATCH (m:Person {name: 'Mark'})
MERGE (j)-[r:IS_FRIENDS_WITH]->(m)
RETURN j, r, m如果希望MERGE在目标不存在创建时执行一种操作,在目标存在匹配时执行另一种操作,则可以使用关键字ON CREATE和ON MATCH。例如下面的MERGE操作,分别在创建和匹配时执行两种不同的set操作
MERGE (m:Person {name: 'Mark'})-[r:IS_FRIENDS_WITH]-(j:Person {name:'Jennifer'})
ON CREATE SET r.since = date('2018-03-01') //创建时执行
ON MATCH SET r.updated = date() //匹配时执行
RETURN m, r, j修改
SET关键字用于设置节点或关系的属性值,想要修改属性值,首先通过MATCH找到需要修改的关系或节点,之后通过SET设置新的属性值,最后通过RETURN将修改结果返回确保更新。例如找到Person节点Jenifer并修改其birthday属性:
MATCH (p:Person {name: 'Jennifer'})
SET p.birthdate = date('1980-01-01')
RETURN p
删除
DELETE关键字用于删除节点和关系,删除节点时必须保证节点不存在关系,否则会报错。
//删除节点Mark
MATCH (m:Person {name: 'Mark'})
DELETE m
//删除Mark和Jennifer直接的关系
MATCH (j:Person {name: 'Jennifer'})-[r:IS_FRIENDS_WITH]->(m:Person {name: 'Mark'})
DELETE r可以通过DETACH DELETE删除节点以及该节点所有相关的关系
MATCH (m:Person {name: 'Mark'})
DETACH DELETE mREMOVE关键字用于删除节点或关系的属性,也可以通过SET属性值为null的形式达到删除属性的目的,因为neo4j不会存储值为null的属性
//REMOVE的方式
MATCH (n:Person {name: 'Jennifer'})
REMOVE n.birthdate
//set属性为null的方式
MATCH (n:Person {name: 'Jennifer'})
SET n.birthdate = null3、查询结果处理
通过函数count()可以对查询的结果进行统计,它会自动忽略值为null的结果。我们需要把统计的节点、关系或属性放在括号内。count(*)默认统计返回的结果条数。
MATCH (p:Person)
RETURN count(p.twitter) //统计具有p.twitter属性的结果数函数collect()可以将查询的结果进行分类。例如查询的p.name和friend结果,将friend按类别聚集在一个列表中,实际上是按p.name分类
MATCH (p:Person)-[:IS_FRIENDS_WITH]->(friend:Person)
RETURN p.name, collect(friend.name) AS friend
函数size()可以用于统计列表中的元素个数,例如将上面分类之后的列表进行计数。
MATCH (p:Person)-[:IS_FRIENDS_WITH]->(friend:Person)
RETURN p.name, size(collect(friend.name)) AS friend
通过关键字WITH可以连接两条查询语句,将查询的结果进行简单的处理,再传给下一条语句,经过处理的语句或变量更加简洁,便于操作或返回。想要传给下一条的语句必须在WITH中用变量指明。WITH也可以用于查询之前对一些数据进行预处理。
MATCH (p:Person)-[:IS_FRIENDS_WITH]->(friend:Person)
//将之后需要用到的变量在WITH中声明,例如p
WITH p, collect(friend.name) AS friendsList, size((friend)-[:IS_FRIENDS_WITH]-(:Person)) AS numberOfFoFs
WHERE numberOfFoFs > 1 //处理后的变量更加简洁
RETURN p.name, friendsList, numberOfFoFs关键字UNWIND可以将列表数据拆分成单个数据,然后分别执行每个数据。例如要查询工作经验在4、5、6、7年的人,可以使用UNWIND将工作年龄数组拆分并分别执行查询
WITH [4, 5, 6, 7] AS experienceRange //WITH预处理
UNWIND experienceRange AS number //将数组拆分成单个number分别执行
MATCH (p:Person)
WHERE p.yearsExp = number
RETURN p.name, p.yearsExp
关键字ORDER BY用于将结果按指定属性进行排序,类似于SQL,可以通过DESC指定降序排列
WITH [4, 5, 6, 7] AS experienceRange
UNWIND experienceRange AS number
MATCH (p:Person)
WHERE p.yearsExp = number
RETURN p.name, p.yearsExp ORDER BY p.yearsExp DESC关键字DISTINCT用于返回不重复的结果,LIMIT限制返回结果的条数。例如查询拥有twitter并且喜欢Graph和Query Language的人
MATCH (user:Person)
WHERE user.twitter IS NOT null
WITH user //通过WITH将上一条查询的user传递到下一条查询
MATCH (user)-[:LIKES]-(t:Technology)
WHERE t.type IN ['Graphs','Query Languages']
RETURN DISTINCT user.name //返回不同的人名
LIMIT 3 //只返回三条