使用python读取neo4j中的数据
目前有需求需要对neo4j中的数据进行分析(一般是读到内存后跑脚本或者使用spark跑分布式),这里介绍一种较为简单和通用的方法。
定义Cypher语句
我们先写两个查询Cypher语句,目的是把我们要读取的数据的字段挑选出来。
# 1
MATCH (n) RETURN id(n) as id, labels(n) as labels
第一个语句,我们返回所有节点的id和标签数据。这里并没有返回所有属性,是因为我们后续的分析过程暂时不需要。
# 2
MATCH (a)-[r]->(b) RETURN id(a) as a_id, r.funded_amount, r.funded_rate, type(r), id(b) as b_id
第二个语句,我们返回所有的关系,同时还有起始节点、结束节点的id,还有关系的属性和类型。
我们这里用企业图谱的数据举例子,就是企业投资的金额和股权的占比。
使用py2neo连接
使用py2neo连接neo4j,然后查询并返回数据。
from py2neo import Graph
import pandas as pd
cypher_1 = "MATCH (n) RETURN id(n) as id, labels(n) as labels LIMIT 10"
cypher_2 = "MATCH (a)-[r]->(b) RETURN id(a) as a_id, r.funded_amount, r.funded_rate, type(r), id(b) as b_id LIMIT 10"
# 连接数据库
graph = Graph("http://192.168.70.40:7474/", username="neo4j", password="123")
# 查询,并使用.data()序列化数据
nodes_data = graph.run(cypher_1 ).data()
links_data = graph.run(cypher_2 ).data()
for node in nodes_data:
print(node)
for link in links_data:
print(link)
我们可以看到输出结果是字典的样子。
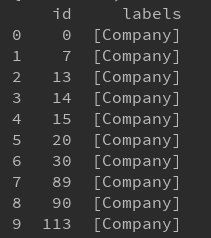
{'labels': ['Company'], 'id': 0}
{'labels': ['Company'], 'id': 7}
{'labels': ['Company'], 'id': 13}
...
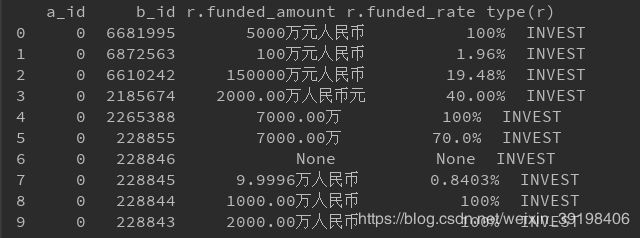
{'a_id': 0, 'r.funded_rate': '100%', 'r.funded_amount': '5000万元人民币', 'b_id': 6681995, 'type(r)': 'INVEST'}
{'a_id': 0, 'r.funded_rate': '1.96%', 'r.funded_amount': '100万元人民币', 'b_id': 6872563, 'type(r)': 'INVEST'}
{'a_id': 0, 'r.funded_rate': '19.48%', 'r.funded_amount': '150000万元人民币', 'b_id': 6610242, 'type(r)': 'INVEST'}
...
也可以使用pandas输出为dataframe,方便后续清洗和分析。
print(pd.DataFrame(nodes_data))
print(pd.DataFrame(links_data))