【MapReduce】常用计算模型详解
前一阵子参加炼数成金的MapReduce培训,培训中的作业例子比较有代表性,用于解释问题再好不过了。有一本国外的有关MR的教材,比较实用,点此下载。
一.MapReduce应用场景
MR能解决什么问题?一般来说,用的最多的应该是日志分析,海量数据排序处理。最近一段时间公司用MR来解决大量日志的离线并行分析问题。
二.MapReduce机制
对于不熟悉MR工作原理的同学,推荐大家先去看一篇博文: http://blog.csdn.net/athenaer/article/details/8203990
三.常用计算模型
这里举一个例子,数据表在Oracle默认用户Scott下有DEPT表和EMP表。为方便,现在直接写成两个TXT文件如下:
1.部门表
DEPTNO,DNAME,LOC // 部门号,部门名称,所在地
10,ACCOUNTING,NEW YORK
20,RESEARCH,DALLAS
30,SALES,CHICAGO
40,OPERATIONS,BOSTON2.员工表
EMPNO,ENAME,JOB,HIREDATE,SAL,COMM,DEPTNO,MGR // 员工号,英文名,职位,聘期,工资,奖金,所属部门,管理者
7369,SMITH,CLERK,1980-12-17 00:00:00.0,800,,20,7902
7499,ALLEN,SALESMAN,1981-02-20 00:00:00.0,1600,300,30,7698
7521,WARD,SALESMAN,1981-02-22 00:00:00.0,1250,500,30,7698
7566,JONES,MANAGER,1981-04-02 00:00:00.0,2975,,20,7839
7654,MARTIN,SALESMAN,1981-09-28 00:00:00.0,1250,1400,30,7698
7698,BLAKE,MANAGER,1981-05-01 00:00:00.0,2850,,30,7839
7782,CLARK,MANAGER,1981-06-09 00:00:00.0,2450, ,10,7839
7839,KING,PRESIDENT,1981-11-17 00:00:00.0,5000,,10,
7844,TURNER,SALESMAN,1981-09-08 00:00:00.0,1500,0,30,7698
7900,JAMES,CLERK,1981-12-03 00:00:00.0,950,,30,7698
7902,FORD,ANALYST,1981-12-03 00:00:00.0,3000,,20,7566
7934,MILLER,CLERK,1982-01-23 00:00:00.0,1300,,10,77823.实例化为bean
这两个bean的实际作用都是分割传入的字符串,从字符串内得到所属的属性信息。
emp.java
public Emp(String inStr) {
String[] split = inStr.split(",");
this.empno = (split[0].isEmpty()? "" : split[0]);
this.ename = (split[1].isEmpty() ? "" : split[1]);
this.job = (split[2].isEmpty() ? "" : split[2]);
this.hiredate = (split[3].isEmpty() ? "" : split[3]);
this.sal = (split[4].isEmpty() ? "0" : split[4]);
this.comm = (split[5].isEmpty() ? "" : split[5]);
this.deptno = (split[6].isEmpty() ? "" : split[6]);
try {
this.mgr = (split[7].isEmpty() ? "" : split[7]);
} catch (IndexOutOfBoundsException e) { //防止最后一位为空的情况
this.mgr = "";
}
}
dept.java
public Dept(String string) {
String[] split = string.split(",");
this.deptno = split[0];
this.dname = split[1];
this.loc = split[2];
}
4.模型分析
4.1 求和
求各个部门的总工资
public static class Map_1 extends MapReduceBase implements Mapper {
public void map(Object key, Text value, OutputCollector output, Reporter reporter) throws IOException {
try {
Emp emp = new Emp(value.toString());
output.collect(new Text(emp.getDeptno()), new IntWritable(Integer.parseInt(emp.getSal()))); // { k=部门号,v=员工薪资}
} catch (Exception e) {
reporter.getCounter(ErrCount.LINESKIP).increment(1);
WriteErrLine.write("./input/" + this.getClass().getSimpleName() + "err_lines", reporter.getCounter(ErrCount.LINESKIP).getCounter() + " " + value.toString());
}
}
}
public static class Reduce_1 extends MapReduceBase implements Reducer {
public void reduce(Text key, Iterator values, OutputCollector output, Reporter reporter) throws IOException {
int sum = 0;
while (values.hasNext()) {
sum = sum + values.next().get();
}
output.collect(key, new IntWritable(sum));
}
}
运行结果:
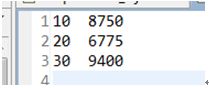
4.3 平均值
求各个部门的人数和平均工资
public static class Map_2 extends MapReduceBase implements Mapper {
public void map(Object key, Text value, OutputCollector output, Reporter reporter) throws IOException {
try {
Emp emp = new Emp(value.toString());
output.collect(new Text(emp.getDeptno()), new IntWritable(Integer.parseInt(emp.getSal()))); //{ k=部门号,v=薪资}
} catch (Exception e) {
reporter.getCounter(ErrCount.LINESKIP).increment(1);
WriteErrLine.write("./input/" + this.getClass().getSimpleName() + "err_lines", reporter.getCounter(ErrCount.LINESKIP).getCounter() + " " + value.toString());
}
}
}
public static class Reduce_2 extends MapReduceBase implements Reducer {
public void reduce(Text key, Iterator values, OutputCollector output, Reporter reporter) throws IOException {
double sum = 0; //部门工资
int count =0 ; //人数
while (values.hasNext()) {
count++;
sum = sum + values.next().get();
}
output.collect(key, new Text( count+" "+sum/count));
}
}
运行结果
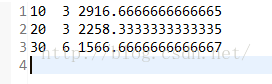
4.4 分组排序
求每个部门最早进入公司的员工姓名
public static class Map_3 extends MapReduceBase implements Mapper {
public void map(Object key, Text value, OutputCollector output, Reporter reporter) throws IOException {
try {
Emp emp = new Emp(value.toString());
output.collect(new Text(emp.getDeptno()), new Text(emp.getHiredate() + "~" + emp.getEname())); // { k=部门号,v=聘期}
} catch (Exception e) {
reporter.getCounter(ErrCount.LINESKIP).increment(1);
WriteErrLine.write("./input/" + this.getClass().getSimpleName() + "err_lines", reporter.getCounter(ErrCount.LINESKIP).getCounter() + " " + value.toString());
}
}
}
public static class Reduce_3 extends MapReduceBase implements Reducer {
public void reduce(Text key, Iterator values, OutputCollector output, Reporter reporter) throws IOException {
DateFormat sdf = DateFormat.getDateInstance();
Date minDate = new Date(9999, 12, 30);
Date d;
String[] strings = null;
while (values.hasNext()) {
try {
strings = values.next().toString().split("~"); // 获取名字和日期
d = sdf.parse(strings[0].toString().substring(0, 10));
if (d.before(minDate)) {
minDate = d;
}
} catch (ParseException e) {
e.printStackTrace();
}
}
output.collect(key, new Text(minDate.toLocaleString() + " " + strings[1]));
}
}
运行结果
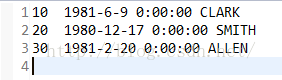
4.5 多表关联
求各个城市的员工的总工资
public static class Map_4 extends MapReduceBase implements Mapper {
public void map(Object key, Text value, OutputCollector output, Reporter reporter) throws IOException {
try {
String fileName = ((FileSplit) reporter.getInputSplit()).getPath().getName();
if (fileName.equalsIgnoreCase("emp.txt")) {
Emp emp = new Emp(value.toString());
output.collect(new Text(emp.getDeptno()), new Text("A#" + emp.getSal()));
}
if (fileName.equalsIgnoreCase("dept.txt")) {
Dept dept = new Dept(value.toString());
output.collect(new Text(dept.getDeptno()), new Text("B#" + dept.getLoc()));
}
} catch (Exception e) {
reporter.getCounter(ErrCount.LINESKIP).increment(1);
WriteErrLine.write("./input/" + this.getClass().getSimpleName() + "err_lines", reporter.getCounter(ErrCount.LINESKIP).getCounter() + " " + value.toString());
}
}
}
public static class Reduce_4 extends MapReduceBase implements Reducer {
public void reduce(Text key, Iterator values, OutputCollector output, Reporter reporter) throws IOException {
String deptV;
Vector empList = new Vector(); // 保存EMP表的工资数据
Vector deptList = new Vector(); // 保存DEPT表的位置数据
while (values.hasNext()) {
deptV = values.next().toString();
if (deptV.startsWith("A#")) {
empList.add(deptV.substring(2));
}
if (deptV.startsWith("B#")) {
deptList.add(deptV.substring(2));
}
}
double sumSal = 0;
for (String location : deptList) {
for (String salary : empList) {
//每个城市员工工资总和
sumSal = Integer.parseInt(salary) + sumSal;
}
output.collect(new Text(location), new Text(Double.toString(sumSal)));
}
}
}
运行结果
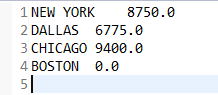
4.6 单表关联
工资比上司高的员工姓名及其工资
public static class Map_5 extends MapReduceBase implements Mapper {
public void map(Object key, Text value, OutputCollector output, Reporter reporter) throws IOException {
try {
Emp emp = new Emp(value.toString());
output.collect(new Text(emp.getMgr()), new Text("A#" + emp.getEname() + "~" + emp.getSal())); // 员工表 { k=上司名,v=员工工资}
output.collect(new Text(emp.getEmpno()), new Text("B#" + emp.getEname() + "~" + emp.getSal()));// “经理表” { k=员工名,v=员工工资}
} catch (Exception e) {
reporter.getCounter(ErrCount.LINESKIP).increment(1);
WriteErrLine.write("./input/" + this.getClass().getSimpleName() + "err_lines", reporter.getCounter(ErrCount.LINESKIP).getCounter() + " " + value.toString());
}
}
}
public static class Reduce_5 extends MapReduceBase implements Reducer {
public void reduce(Text key, Iterator values, OutputCollector output, Reporter reporter) throws IOException {
String value;
Vector empList = new Vector(); // 员工表
Vector mgrList = new Vector(); // 经理表
while (values.hasNext()) {
value = values.next().toString();
if (value.startsWith("A#")) {
empList.add(value.substring(2));
}
if (value.startsWith("B#")) {
mgrList.add(value.substring(2));
}
}
String empName, empSal, mgrSal;
for (String emploee : empList) {
for (String mgr : mgrList) {
String[] empInfo = emploee.split("~");
empName = empInfo[0];
empSal = empInfo[1];
String[] mgrInfo = mgr.split("~");
mgrSal = mgrInfo[1];
if (Integer.parseInt(empSal) > Integer.parseInt(mgrSal)) {
output.collect(key, new Text(empName + " " + empSal));
}
}
}
}
} 运行结果
4.7 TOP N
列出工资最高的头三名员工姓名及其工资
public static class Map_8 extends MapReduceBase implements Mapper {
public void map(Object key, Text value, OutputCollector output, Reporter reporter) throws IOException {
try {
Emp emp = new Emp(value.toString());
output.collect(new Text("1"), new Text(emp.getEname() + "~" + emp.getSal())); // { k=随意字符串或数字,v=员工名字+薪资}
} catch (Exception e) {
reporter.getCounter(ErrCount.LINESKIP).increment(1);
WriteErrLine.write("./input/" + this.getClass().getSimpleName() + "err_lines", reporter.getCounter(ErrCount.LINESKIP).getCounter() + " " + value.toString());
}
}
}
public static class Reduce_8 extends MapReduceBase implements Reducer {
public void reduce(Text key, Iterator values, OutputCollector output, Reporter reporter) throws IOException {
Map emp = new TreeMap(); // TreeMap默认key升序排列,巧妙利用这点可以实现top N
while (values.hasNext()) {
String[] valStrings = values.next().toString().split("~");
emp.put(Integer.parseInt(valStrings[1]), valStrings[0]);
}
int count = 0; // 计数器
for (Iterator keySet = emp.keySet().iterator(); keySet.hasNext();) {
if (count < 3) { // N =3
Integer current_key = keySet.next();
output.collect(new Text(emp.get(current_key)), new Text(current_key.toString())); // 迭代key,即SAL
count++;
} else {
break;
}
}
}
}

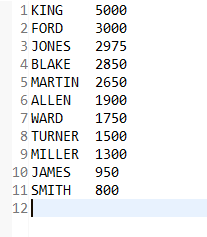
4.8 降序排序
将全体员工按照总收入(工资+提成)从高到低排列,要求列出姓名及其总收入
public static class Map_9 extends MapReduceBase implements Mapper {
public void map(Object key, Text value, OutputCollector output, Reporter reporter) throws IOException {
try {
Emp emp = new Emp(value.toString());
int totalSal = Integer.parseInt(emp.getComm()) + Integer.parseInt(emp.getSal());
output.collect(new Text("1"), new Text(emp.getEname() + "~" + totalSal));
} catch (Exception e) {
reporter.getCounter(ErrCount.LINESKIP).increment(1);
WriteErrLine.write("./input/" + this.getClass().getSimpleName() + "err_lines", reporter.getCounter(ErrCount.LINESKIP).getCounter() + " " + value.toString());
}
}
}
public static class Reduce_9 extends MapReduceBase implements Reducer {
public void reduce(Text key, Iterator values, OutputCollector output, Reporter reporter) throws IOException {
Map emp = new TreeMap(
// 重写比较器,使降序排列
new Comparator() {
public int compare(Integer o1, Integer o2) {
return o2.compareTo(o1);
}
});
while (values.hasNext()) {
String[] valStrings = values.next().toString().split("~");
emp.put(Integer.parseInt(valStrings[1]), valStrings[0]);
}
for (Iterator keySet = emp.keySet().iterator(); keySet.hasNext();) {
Integer current_key = keySet.next();
output.collect(new Text(emp.get(current_key)), new Text(current_key.toString())); // 迭代key,即SAL
}
}
} 运行结果
四.总结
把sql里常用的计算模型写成MR是一件比较麻烦的事,因为很多情况下一行sql估计要十几甚至几十行代码来实现,略显笨拙。但是从数据计算速度来说,MR跟sql不是一个级别的。
但不可否认的一点是,无论是什么技术都有各自的适用范围,MR不是万能的,具体要看使用场景再选择适当的技术。