技术控
作者:lyl
由萝卜兔编辑整理
CNN模型虽然在各类任务上大放异彩,但一直以来都被诟病缺乏可解释性。针对这个问题,过去几年研究人员除了从理论层面去寻找解释外,也提出了一些可视化的方法直观地理解CNN的内部机理。本文主要介绍两类方法,一种是基于Deconvolution, 另一种则是基于反向传播的方法。
基于Deconvolution的方法
基于Deconvolution的方法一篇来自Matthew D Zeiler, Rob Fergus的工作《Visualizing and Understanding Convolutional Networks》
本文主要是将激活函数的特征映射回像素空间,来揭示什么样的输入模式能够产生特定的输出。
整个架构如图所示:
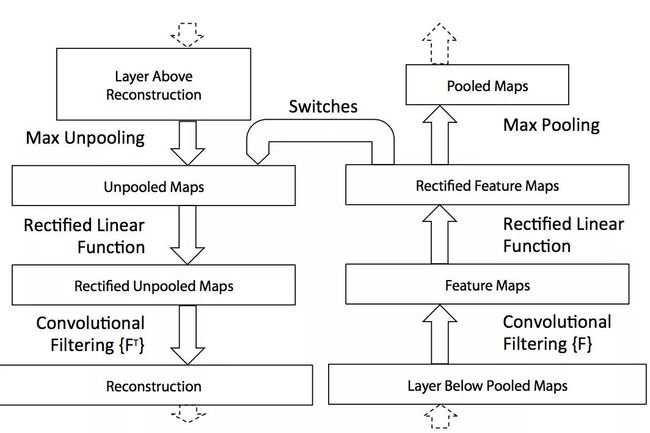
如图所示,每一个卷积层都连接着一个deconvnet,最后将特征映射回像素空间。给定一个输入,经过网络计算得到特征,保留某个特定的激活值,其他激活值置零,然后作为deconvnet的输入,逐渐映射回像素空间,这个过程中涉及三个操作及其逆操作:
1、Unpooling
实际上max-pooling是不可逆的,这里采用了一个近似操作,在max-pooling的时候记录下相应的索引,在unpooling时,将特征放在这些索引的位置上,如图所示:

2、ReLU
为了保证所有的激活值都是正的,直接使用了ReLU激活函数 。
3、Deconvolution
对于卷积的逆操作,使用的卷积核是对应卷积层的卷积核的转置 。
基于上述方法得到的可视化结果第一次直观地给出了不同层级学到特征的不同,总的结论就是越靠近输入的层级学到的是越通用的特征,越靠近输出的层级学到的特征越抽象,与实际任务越相关,具体的结果可以参考论文。
基于Backpropagation的方法
1、Guided-Backpropagation
这个方法来自于ICLR-2015 的文章《Striving for Simplicity: The All Convolutional Net》,文中提出了使用stride convolution 替代pooling 操作,这样整个结构都只有卷积操作。作者为了研究这种结构的有效性,提出了guided-backpropagation的方法。
基于backpropagation的方法,一种最简单的思路是,选择某一种输出模式,然后通过反向传播计算输出对输入的梯度。这种方式与上一种deconvnet的方式的唯一区别在于对ReLU梯度的处理。如图所示:
在图c中,ReLU处反向传播的计算采用的前向传播的特征作为门阀,而deconvnet采用的是梯度值。图b是一个具体的数值计算例子。guided-backpropagation则将两者组合在一起使用,这样有助于得到的重构都是正数,并且这些非零位置都是对选择的特定输出起到正向作用。这种方法能够很好的可视化高层的特征,而deconvnet会失效。这种方法与deconvnet的方法结果对比如下图,可以看出明显的差异:

2、CAM(Class Activation Map)
这个方法严格来说不是基于梯度的,但后面一种方法基于它,因此这儿归在一起一并介绍。CAM 来自CVPR 2016 《Learning Deep Features for Discriminative Localization》,作者在研究global average pooling(GAP)时,发现GAP不止作为一种正则,减轻过拟合,在稍加改进后,可以使得CNN具有定位的能力(当然RCNN系列已经说明CNN中蕴含着目标的位置信息,但是在进行分类任务时,引入全连接层,将目标的空间位置信息丢弃了)。CAM(class activation map)是指输入中的什么区域能够指示CNN进行正确的识别,作者提出了一种简单的方法,整个流程图如下:

网络结构分为两部分,一部分是特征提取(CNN),一部分是分类层(softmax),在特征提取的最后一层我们使用全局平均池化,这样GAP的将会输出每个feature map的平均值,接下来进行一个加权求和得到最后的输出。那么对应的,我们可以对最后一层feature map利用分类层的权值进行加权。
通常特征图上每个位置的值在存在其感知野里面某种模式时被激活,最后的class activation map是这些模式的线性组合。为了简便,可以直接使用上采样,将class activation map 还原到与原图一样的大小,通过叠加,我们就可以知道哪些区域是与最后分类结果息息相关的部分。

3、Grad-CAM
与CAM不同的是,CAM的特征加权系数是分类器的权值,Grad-CAM的加权系数是通过反向传播得到的。整个流程如下图:

如何求得各个feature map的加权权值,本文采用梯度回传的方法:

也很简单,分两步:第1步求logits对卷积特征的梯度,第2步,这些梯度进行一个global average pooling,那么得到的heatmap图为:
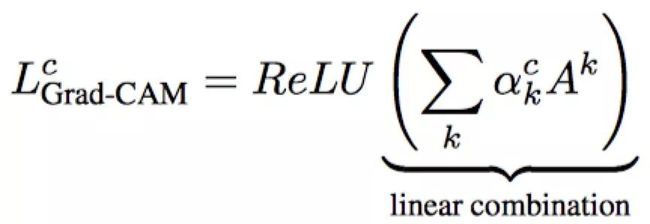
得到的这个heatmap是个粗略的图,它的大小与特征图大小一致,如VGG 最后一层特征图大小是14x14,然后使用双线性插值得到与原图同样的大小。
Grad-CAM 与 CAM相比,它的优点是适用的范围更广,不像CAM要求最后一层是GAP,Grad-CAM对各类结构,各种任务都可以使用。这两种方法也可以应用于进行弱监督下的目标检测,后续也有相关工作基于它们进行改进来做弱监督目标检测。
总结
上述几种方法可以让我们对CNN有一些感性直观的认识,有助于理解CNN不同层级的特征的差异,可以指导我们如何更好的利用CNN的特征来研究某些任务。下篇文章将简单地实现上述几种可视化方法。
参考文献:
Zeiler, Matthew D., and Rob Fergus. "Visualizing and understanding convolutional networks." European conference on computer vision. Springer, Cham, 2014.
Springenberg, Jost Tobias, et al. "Striving for simplicity: The all convolutional net." arXiv preprint arXiv:1412.6806 (2014).
Zhou, Bolei, et al. "Learning deep features for discriminative localization." Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2016.
Selvaraju, Ramprasaath R., et al. "Grad-cam: Visual explanations from deep networks via gradient-based localization." https://arxiv.org/abs/1610.02391 v3 7.8 (2016).
