AC自动机
链接网址: http://www.cppblog.com/menjitianya/archive/2014/07/10/207604.html
AC自动机
算法目的:
AC自动机主要用于解决多模式串的匹配问题,是字典树(trie树)的变种,一种伪树形结构(主体是树形的,但是由于加入了失败指针,使得它变成了一个有向图);trie图(我的理解^_^)是对AC自动机的一种改造,使得图中每个结点都有MAXC条出边(MAXC表示该图的字符集合大小), trie图上的每个结点代表一个状态,并且和AC自动机的结点是一一对应的。
算法核心思想:
学习AC自动机(AC-Automan?艾斯奥特曼?-_-|||)之前,首先需要有字典树和KMP的基础,这是每一篇关于AC自动机的文章都会论及的,所以我也就例行提一下。
例如,有四个01字符串(模式串),"01"、"10"、"110"、"11",字符集合为{'0', '1'}。那么构造trie图分三步,首先建立字典树,然后构造失败指针,最后通过失败指针补上原来不存在的边,那么现在就分三步来讨论如何构建一个完整的trie图。
图1
1) 字典树
字典树是一种树形结构,它将所有的模式串组织在一棵树的树边上,它的根结点是一个虚根,每条树边代表一个字母,从根结点到任意一个结点的路径上的边的有序集合代表某个模式串的某个前缀。
如图1,绿色点为虚根,蓝色点为内部结点,红色点为终止结点,即从根结点到终止结点的每条路径代表了一个模式串,由于"11"是"110"的前缀,所以在图中"11"这两条边是这两个字符串路径的共用部分,这样就节省了存储空间,由于trie树的根结点到每个结点的路径(边权)都代表了一个模式串的前缀,所以它又叫前缀树。
字典树实际上是一个DFA(确定性有限状态自动机),通常用转移矩阵表示。行表示状态,列表示输入字符,(行, 列)位置表示转移状态。这种方式的查询效率很高,但由于稀疏的现象严重,空间利用效率很低。所以一般采用压缩的存储方式即链表来表示状态转移,每个结点存储至少两个域:数据域data、子结点指针域next[MAXC](其中MAXC表示字符集总数)。
构造字典树的前提一般是给定一系列的模式串,然后对每个模式串进行插入字典树的操作,初始情况下字典树只有一个虚根,如图2所示,进行四个模式串的插入后就完成了图1中的字典树的构造,每次插入在末尾结点打上标记(图中红色部分),可以注意到,第四次操作实际上没有生成新的结点,只是打了一个结尾标记,由于它的这个性质,使得字典树的结点数目不会很多,大大压缩了存储结构。具体实现方式和编码会在下文中详细讲解。
图2
2) 失败指针
给定一个目标串,要求在由模式串构建的字典树中查找这个目标串中有多少个模式串,我们可以设定一个指针p,初始状态下它指向根结点,然后从前往后枚举目标串,对每一个目标串中的字符c,如果在p指向结点的出边集合中能够找到字符c对应的边,那么将p指向c对应边的子结点,循环往复,直到匹配失败,那么退回到p结点的fail指针指向的结点继续同样的匹配,当遇到一个终止结点时,计数器+1。
这里的fail指针类似KMP的next函数,每个trie结点都有一个fail指针,如图3,首先将根结点的fail指针指向NULL,根结点的直接子结点的fail指针指向根结点,这一步是很显然的,因为当一个字符都不能匹配的时候肯定是要跳到字符串首重新匹配了,每个结点的fail指针都是由它父结点的fail指针决定的,所以一次BFS就可以把所有结点的fail指针逐层求解出来了,具体实现方式和编码会在下文中详细讲解。
图3
3) trie图
为了方便描述,我们先把所有trie树上的结点进行编号,编号顺序为结点的插入顺序,根结点编号为0。如图4的第一个图,我们发现如果现在是1号状态(状态即结点),当接收一个'1'这个字符,那么它应该进入哪个状态呢?答案很显然,是2号状态,因为沿着字符'1'的出边到达的状态正好是2号状态;但是如果接受的是'0'字符,我们发现1号状态没有'0'字符代表的出边,所以我们需要补上这条'0'边,但是这条边指向哪个状态呢?答案是1号状态的fail指针指向的状态的'0'出边对应的状态。我们发现这个状态正好是它自己,所以向自己补一条边权为'0'的边(图中的橙色边,边指向的结点称为当前状态的后继状态)。同样是利用BFS的方式逐层求解所有结点的后继状态。我们发现所有结点遍历完后,每个结点都有且仅有两条出边,这样一个trie图就诞生了。
图4
今后几乎所有关于状态机的问题都是围绕图4的那个图展开的。
新手初看算法的时候总是一头雾水,即使看懂了也要花很大力气才能把代码写出来(至少我是这样的),所以没有什么比直接阐述代码更加直观的了。
一、结构定义
2 // 结点结构
3 struct ACNode {
4 public:
5 ACNode *fail; // fail指针,指向和当前结点的某个后缀匹配的最长前缀的位置
6 ACNode *next[MAXC]; // 子结点指针
7
8 // 以下这些数据需要针对不同题目,进行适当的注释,因为可能内存会吃不消
9
10 int id; // 结点编号(每个结点有一个唯一编号)
11 int val; // 当前结点和它的fail指针指向结点的结尾单词信息的集合
12 int cnt; // 有些题中模式串有可能会有多个单词是相同的,但是计数的时候算多个
13
14 void reset( int _id) {
15 id = _id;
16 val = 0;
17 cnt = 0;
18 fail = NULL;
19 memset(next, 0, sizeof(next));
20 }
21
22 // 状态机中的 接收态 的概念
23 // 模式串为不能出现(即病毒串)的时候才有接收态
24 bool isReceiving() {
25 return val != 0;
26 }
27 };
对于trie树上的每个结点,保存了以下数据域:
1) 结点编号 int id;
每个结点的唯一标识,用于状态转移的时候的下标映射。
2) 子结点指针 ACNode *next[MAXC];
每个结点的子结点的个数就是字符串中字符集的大小,一般为26个英文字母,当然也有特殊情况,比如说和DNA有关的题,字符集为{ 'A'、'C'、'G'、'T' },那么字符集大小就为4;和二进制串有关的题,字符集大小就为2;而有的题则包含了所有的可见字符,所以字符集大小为256(有可能有中文字符...太BT了),这个就要视情况而定了。
3) 失败指针 ACNode *fail;
它的含义类似KMP中的最长前后缀的概念,即目标串在trie树上进行匹配的时候,如果在P结点上匹配失败,那么应该跳到P->fail继续匹配,如果还是失败,那么跳到P->fail->fail继续匹配,对于这个fail指针的构造,下文会详细讲解,这里先行跳过。
4) 结尾标记 int cnt, val;
每个模式串在进行插入的过程中,会对模式串本身进行一次线性的遍历,当遍历完毕即表示将整个串插入完毕,在结尾结点需要一个标记,表示它是一个模式串的末尾,有些问题会出现多个相同的模式串,所以用cnt来表示该串出现的次数,每插入一次对cnt进行一次自增;而有的题中,相同的模式串有不同的权值,并且模式串的个数较少(<= 15),那么可以将该结点是否是模式串的末尾用2的幂来表示,压缩成二进制的整数记录在val上(例如当前结点是第二个模式串和第四个模式串的结尾,则val = (1010)2)。
2 public:
3 /* 结点相关结构 */
4 ACNode* nodes[MAXQ]; // 结点缓存,避免内存重复申请和释放,节省时间
5 int nodesMax; // 缓冲区大小,永远是递增的
6 ACNode *root; // 根结点指针
7 int nodeCount; // 结点总数
8
9 /* 数据相关结构 */
10 int ID[256], IDSize; // 结点上字母的简单HASH,使得结点编号在数组中连续
11 // 例如: ID['a']=0 ID['b']=1 依此类推
12
13 /* 队列相关结构 */
14 ACNodeQueue Q;
15
16 public:
17 ACAutoman() {
18 nodesMax = 0;
19 }
20 // 初始化!!! 必须调用
21 void init() {
22 nodeCount = 0;
23 IDSize = 0;
24 root = getNode();
25 memset(ID, -1, sizeof(ID));
26 }
27
28 // 获取结点
29 ACNode *getNode() {
30 // 内存池已满,需要申请新的结点
31 if(nodeCount >= nodesMax) {
32 nodes[nodesMax++] = new ACNode();
33 }
34 ACNode *p = nodes[nodeCount];
35 p->reset(nodeCount++);
36 return p;
37 }
38
39 // 获取字母对应的ID
40 int getCharID(unsigned char c, int needcreate) {
41 if(!needcreate) return ID[c];
42 if(ID[c] == -1) ID[c] = IDSize++;
43 return ID[c];
44 }
45 }AC;
终于看到故事的主角(ACAutoman, 艾斯奥特曼)了,同样介绍一下它需要维护的数据结构:
1) 结点缓存 ACNode* nodes[MAXQ];
为了方便访问,我们将所有的结点组织在一个数组中,并且一开始不开辟空间,每次需要一个结点的时候,利用接口getNode()获取,类似内存池的概念,避免频繁申请和释放内存时候的时间开销。
2) 根结点指针ACNode *root;
trie树,既然是树,自然是有一个根结点的嘛。
3) 结点总数 int nodeCount;
4) 结点队列 ACNodeQueue Q;
ACNodeQueue是自己实现的一个队列,数据域为ACNode *,主要是因为STL的效率实在不敢恭维,在某些OJ上效率极低,自己封装一套比较好,这个队列会在BFS的时候求失败指针时用到。
二、模式串插入
2 ACNode *p = root;
3 int id;
4 for( int i = 0; str[i]; i++) {
5 // 获取字母对应的哈希ID
6 id = getCharID(str[i], true);
7 // 检查子结点是否存在,不存在则创建新的子结点
8 if(p->next[id] == NULL) p->next[id] = getNode();
9 p = p->next[id];
10 }
11 // 在这个单词的结尾打上一个标记
12 p->val |= val; // 注意有可能有相同的串
13 p->cnt ++;
14 }
str为模式串,将它插入到trie树时,需要进行一次线性遍历,为了使每个字符访问方便,我们将字母映射到整数区间[0, IDSize)中,只要采用最简单的哈希即可。初始化当前结点p为根结点,对于字符串的某个字符,转换成整数id后,检测当前结点p是否存在id这个子结点,如果不存在则利用getNode()获取一个新的结点,并且让当前结点p的id子结点指向它,然后将当前结点转到它的id子结点上,继续上述操作。直到整个模式串枚举完毕,在结点p打上结束标记即可。
三、失败指针、trie图 构造
2 ACNode *now, *son, *tmp;
3
4 root->fail = NULL;
5 Q.clear();
6 Q.push(root);
7
8 // 逐层计算每一层的结点的fail指针
9 // 当每个结点计算完毕,保证它所有后继都已经计算出来
10 while( !Q.empty() ) {
11 now = Q.pop();
12
13 if(now->fail) {
14 // 这里需要视情况而定
15 // 目的是将fail指针的状态信息传递给当前结点
16 // now->val += now->fail->val;
17 // now->val |= now->fail->val;
18
19 // 如果当前结点是个接收态,那么它的所有后继都是回到本身
20 if(now->isReceiving()) {
21 for( int i = 0; i < MAXC; i++) {
22 now->next[i] = now;
23 }
24 continue;
25 }
26 }
27 // 首先,我们把当前结点now的i号后继记为son[i]
28 // i) 如果son[i]不存在,将它指向 当前结点now的fail指针指向结点的i号后继(保证一定已经计算出来)。
29 // 2) 如果son[i]存在,将它的fail指针指向 当前结点now的fail指针指向结点的i号后继(保证一定已经计算出来)。
30 for( int i = 0; i < MAXC; i++) {
31 son = now->next[i];
32 tmp = (now == root) ? root : now->fail->next[i];
33 if(son == NULL) {
34 now->next[i] = tmp;
35 } else {
36 son->fail = tmp;
37 Q.push(son);
38 }
39 }
40 }
41 }
首先,讲一下失败指针的含义,因为之前提到,一个模式串的某个字符匹配失败的时候,就跳到它的失败指针上继续匹配,重复上述操作,直到这个字符匹配成功,所以失败指针一定满足一个性质,它指向的一定是某个串的前缀,并且这个前缀是当前结点所在前缀的后缀,而且一定是最长后缀。仔细理解一下这句话,首先,一定是某个串的前缀,这是显然的,因为trie树本来就是前缀树,它的任意一个结点都是某个模式串的前缀;然后再来看后面一句话,为了让当前字符能够找到匹配,那么当前结点的某个后缀必须要和某个模式串的前缀相匹配,这个性质就和KMP的next数组不谋而合了。
然后,就是来看如何利用BFS求出所有结点的失败指针了。
1) 对于根结点root的失败指针,我们将它直接指向NULL,对于根结点下所有的子结点,失败指针一定是指向root的,因为当一个字符都不能匹配的时候,自然也就不存在更短的能够与之匹配的前缀了;
2) 将求完失败指针的结点插入队列中;
3) 每次弹出一个结点now,询问它的每个字符对应的子结点,为了阐述方便,我们将now的i号子结点记为now->next[i]:
a) 如果now->next[i]为NULL,那么将now->next[i]指向now的失败指针的i号子结点, 即 now->next[i] = now->fail->next[i];
b) 如果now->next[i]不等于NULL,则需要构造now->next[i]的失败指针,由于a)的操作,我们知道now的失败指针一定存在一个i号子结点,即now->fail->next[i],那么我们将now->next[i]的失败指针指向它,即now->next[i]->fail = now->fail->next[i];
4) 重复2)的操作直到队列为空;
四、目标串匹配
2 ACNode *p = root, *tmp = NULL;
3 int id;
4 int cnt = 0;
5
6 for( int i = 0; str[i]; i++) {
7 id = getCharID(str[i], false);
8 if(id == -1) {
9 // 当前单词从来没有出现过,直接回到匹配之初
10 p = root;
11 continue;
12 }
13 p = p->next[id];
14 tmp = p;
15 while(tmp != root && tmp->cnt != -1) {
16 if(tmp->cnt) {
17 // 找到一个子串以tmp结点结尾
18 // 这里一般需要做题目要求的操作,不同题目不同
19 // 有的是统计子串数目、有的则是输出子串位置
20 cnt += tmp->cnt;
21 tmp->cnt = -1;
22 }
23 tmp = tmp->fail;
24 }
25 }
26 return cnt;
27 }
对目标串进行匹配的时候,同样需要扫描目标字符串。由于trie图已经创建完毕,每个结点读入一个字符的时候都能够进入到下一个状态,所以我们只需要根据目标串给定的字符进行遍历,然后每次检查当前的结点是否是结尾结点,当然还需要检查p的失败指针指向的结点...累加所有的cnt和即为模式串的个数。
对于AC自动机,各大OJ都有相关习题,来看几道比较经典的:
HDU 2222 Keywords Search
题意:给定N(N <= 10000)个长度不大于50的模式串,再给定一个长度为L(L <= 106)目标串,求目标串出现了多少个模式串。
题解:AC自动机模板题,在每个trie结点存储一个count值,每次插入一个单词的时候对单词结尾结点的count值进行自增(不能将count值直接置为1,因为有可能模式串中有多个相同的串,它们是要被算作多次的),然后在询问的时候,每次计数完毕之后,将count值标为-1表示它已经被计算过了。最后输出所有count的累加和即可。
HDU 2896 病毒侵袭
题意:N(N <= 500)个长度不大于200的模式串(保证所有的模式串都不相同),M(M <= 1000)个长度不大于10000的待匹配串,问待匹配串中有哪几个模式串,题目保证每个待匹配串中最多有三个模式串。
题解:构造trie树和fail指针,由于每个模式串都不同,所以每个代表模式串结尾的trie结点存储模式串对应的编号idx,扫描所有带匹配串,对于每个待匹配串利用失败指针模拟匹配,匹配的模式串个数到达三个的时候放弃扫描该串。
可见字符包括空格,所以读入的时候需要用gets(),子结点个数为128。
HDU 3065 病毒侵袭持续中
题意:N(N <= 1000)个长度不大于50的模式串(保证所有的模式串都不相同),一个长度不大于2000000的待匹配串,求模式串在待匹配串中的出现次数。
题解:由于每个病毒串不会完全相同,对于每个病毒串末尾记录一个编号标记,完全匹配后对编号对应的数组进行累加和计算。
PKU 1204 Word Puzzles
题意:给定一个L x C(C <= 1000, L <= 1000)的字母矩阵,再给定W(W <= 1000)个字符串,保证这些字符串都会在字母矩阵中出现(8种方向),求它们的出现位置和方向。
题解:先缓存所有数据,然后对W个字符串建立字典树和失败指针,再扫描字母矩阵所有8个方向的字符串进行匹配。
ZJY 3228 Searching the String
题意:给定一个长度为N(N <= 105)的目标串,然后再给定M(M <= 105)个长度不大于6的字符串,问这些字符串在目标串的出现次数(分可重叠和不可重叠两种)。
题解:将M个串作为模式串建立自动机,对于可重叠的情况直接询问即可,类似HDU 3065,不可重叠的情况需要记录每个串的长度Li以及之前这个串匹配到的最大位置Pi,对于当前位置Pos,如果Pi + Li <= Pos,那么认为和之前的一次匹配没有重叠,计数累加,并且更新Pi = Pos。
为了方便,我把两种计算方式的模式串分别建立了两个自动机。
PKU 3208 Apocalypse Someday
题意:求第K(K <= 5*107)个有连续3个6的数。
题解:建立DFA如下图,其中0为初态,1为非法状态(存在前导0),2为后缀没有6的状态,3、4、5分别为后缀有1个、2个、3个6的状态,所以5为接收态,因为一旦出现了3个6,那么无论接下来的是什么数都认为是合法数。
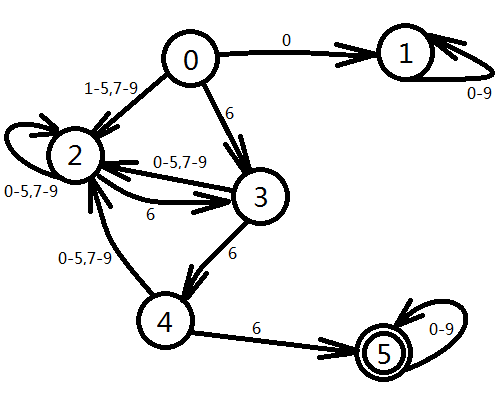
既然有了状态转移图就可以轻松地利用状态转移方程求出长度为n有连续3个6的数字的个数,当长度小于等于L的满足条件的数字总数大于等于K的时候,就表明第K个满足条件的数字的长度为L,然后枚举每一位的数字判可行即可。
PKU 2778 DNA Sequence
题意:给定m(m <= 10)个DNA片段,每个串长度不超过10。求长度为N(N <= 2*109)的串中不包括任何给定的DNA片段的串的总数。
题解:利用模式串建立trie图,将trie图转化为矩阵表示,利用二分求幂加速。
为了更加直观,举例说明:
例如,m=2,两个DNA片段分别为A和CAG,可以建立如下AC自动机:
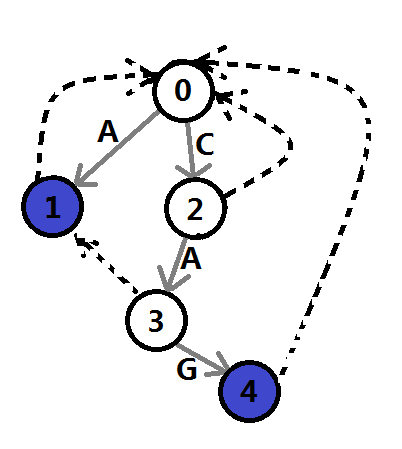
图5
其中,灰色箭头代表树边,虚线代表失败指针,蓝色结点代表终止状态,0为起始状态。
然后我们利用它来构造trie图,如图6。
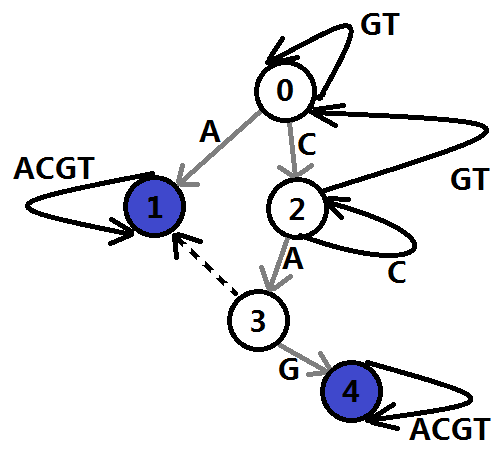
图6
构造方法是利用BFS,依次处理每个状态可以到达哪些状态,建立可达矩阵。
具体步骤如下:
1) 初始状态入队。
2) 每次弹出一个状态结点进行处理,直到队列为空。
a) 对于当前处理的结点P,判断P是否是一个终止结点,如果不是,则判断P的fail指针指向的是否是一个终止结点,一直迭代到fail指针为空,如果迭代过程中找到某个结点为终止结点,那么表示P所在串的某个后缀包含了给定的DNA片段,那么标记P为终止结点,重复2),否则转b)。
b) 枚举P的所有子结点Q[i](这里的子结点是包含所有字符集的):
i) 如果Q[i]这个结点不为空,那么DFA[P][Q[i]] ++,Q[i]入队;
ii) 否则沿着P的fail指针一直找,直到找到一个结点S的对应子结点T[i]不为空,那么DFA[P][T[i]]++,如果一直找不到,那么DFA[P][root]++;
当队列为空的时候,有限状态自动机也就构造完毕了,按照这种方式,我们可以发现,除了终止状态,所有状态都有四条出边(A、C、G、T),但是终止状态并非真正意义上的终止状态,于是我们在终止状态上添加四条回边(指向自己),表示如果状态进入了终止状态就再也出不去了,这样一来,这个状态机就完整了,任意一个状态只要接收A、C、G、T四个字符中的一个就能进入下一个状态,这样就转化成了一个动态规划问题,假设状态方程DP[i][j]表示长度为i的串在j状态下的字符串个数,那么对于图2的状态机,有如下关系:
DP[i][0] = 2 * DP[i-1][2] + 2 * DP[i-1][0];
DP[i][1] = DP[i-1][0] + 4 * DP[i-1][1];
DP[i][2] = DP[i-1][0] + DP[i-1][2];
DP[i][3] = DP[i-1][2] + 4*DP[i-1][3];
由于在DFA状态处理的时候3号状态为终止状态,所以DP[i][4]其实已经是一个冗余状态了,所以不列入讨论范围。
按照递推方程,DP[N][0] + DP[N][2]就是我们要求的答案,但是N很大,所以可以将DP转移转化成矩阵,即:
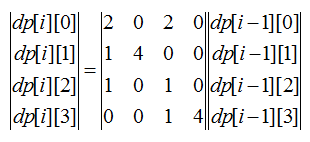
然后利用矩阵的二分求幂来加速了。
这题更加直观的理解是:从起点0开始,走N步,经过的路径就是一个DNA串,如果最后到达的是终止状态,那么表示它包含了m个DNA片段中的至少一个。所有路径长度为N,终点非终止状态的路径数目之和就是我们要求的解。
PKU 1625 Censored!
题意:给定p(p <= 10)个长度不大于10的模式串,求长度为m(m <= 50)的串中不包含任何模式串的串的种类数。
题解:首先利用模式串建立trie图,用DP[i][j]表示长度为i,状态为j的字符串的种类数,枚举所有字符进行状态转移即可。最后Sum{DP[m][i], i表示非终止状态} 就是答案,这题如果将字符直接进行下标映射,有可能会RE,就是它的字符的ASCII码有可能是在128-255之间的(例如中文),如果用scanf读入,转换成char就变成了负数,如果映射到下标就RE了,所以在映射之前最好先转成unsigned char。
PKU 3691 DNA repair
题意:给定N(N <= 50)个长度不超过20的模式串,再给定一个长度为M(M <= 1000)的目标串S,求在目标串S上最少改变多少字符,可以使得它不包含任何的模式串(所有串只有ACGT四种字符)。
题解:利用模式串建立trie图,trie图的每个结点(即下文讲到的状态j)维护三个结构,
Node{
Node *next[4]; // 能够到达的四个状态 的结点指针
int id; // 状态ID,用于到数组下标的映射
int val; // 当前状态是否是一个非法状态 (以某些模式串结尾)
}
用DP[i][j]表示长度为i (i <= 1000),状态为j(j <= 50*20 + 1)的字符串变成目标串S需要改变的最少字符,设初始状态j = 0,那么DP[0][0] = 0,其它的DP[i][j]均为无穷大。从长度i到i+1进行状态转移,每次转移枚举共四个字符(A、C、G、T),如果枚举到的字符和S对应位置相同则改变值T=0,否则T=1;那么有状态转移方程DP[i][j] = Min{ DP[i-1][ fromstate ] + T, fromstate为所有能够到达j的状态 };最后DP[n][j]中的最小值就是答案。
PKU 1699 Best Sequence
题意:给定N(N <= 10)个长度不超过20的模式串,求一个长度最短的串使得它包含所有的模式串。
题解:利用模式串建立trie图,trie图的每个结点维护一个二进制权值,(val & 2i)不为0表示从根结点到该结点的某条路径上有第i个模式串,用DP[i][j]表示状态为i,模式串的二进制组合为j的最短串的长度,初始化DP[0][0] = 0,然后就转化成了一个在trie图上求(0, 0)到(i, 2n-1)点的最短路问题,最后求出来的DP[i][2n-1] (i < 200, 最多200个结点) 的最小值就是答案。
注意:本题中的模式串有重复的情况需要特殊处理。
HDU 2296 Ring
题意:给定N (N <= 50) 和M(M <= 100)个长度不超过10的字符串以及每个字符串的权值Hi,求一个长度不超过N的字符串使得她包含的权值最大,如果有多个解输出长度最短的,如果还是有多个解,输出字典序最小的。
题解:利用模式串建立trie图,用DP[i][j]表示长度为i,处于j状态下的字符串的最大权值,然后枚举26个字符进行状态转移,转移的过程中需要记录每个状态的前驱,每次进行最大值比较的时候,遇到最大值相等的情况则需要回溯,取字典序最小的。
HDU 2825 Wireless Password
题意:给定m(m <= 10)个长度不大于10的模式串,求长度为n(n <= 25)的至少包含k个模式串的字符串的种数,答案模上20090717。
题解:类似PKU 1699利用模式串建立trie图,trie图上每个结点表示为一个状态,第i个模式串的权值为2i。用DP[i][j][l]表示长度为i,状态为j,已经有t个模式串的种类数(其中l表示这t个模式串的权值的位或),那么对于每个状态j,输入’a-z’这26个字符后必定能够到达下一个状态,从DP[0][0][0]=1开始迭代计算,最终SUM { DP[n][j][s] , s的二进制表示中1的个数大于等于k}就是答案。
HDU 3341 Lost 's revenge
题意:给定N(N <= 50)个长度不超过10的模式串(ACGT串),再给定一个长度为M(M <= 40)的目标串S,求将目标串重排列,使得它包含最多的模式串,求这个最多的数目。
题解:利用模式串建立trie图,trie图上最多有500个结点( N*10 ),然后朴素的思想就是用S(i, iA, iC, iG, iT)表示在i状态下,拥有iA个A、iC个C、iG个G、iT个T的串拥有的最多的模式串的个数,但是iA, iC, iG, iT的取值均是[0, 40],所以我们需要把状态压缩一下,我们知道当四种字符都取10的时候可以让状态数达到最大,即114 = 14641, 所以可以令MaxA、
MaxC、MaxG、MaxT分别表示四种字符出现的个数,那么T字符的权值为1,G字符的权值为(MaxT + 1),C字符的权值为(MaxG + 1) *(MaxT + 1),A字符的权值为(MaxC + 1) *(MaxG + 1) *(MaxT + 1),进行进制压缩之后总的状态数不会超过114,可以用DP[i][j]表示在trie的i号结点时ACGT四个字符个数的压缩状态为j时的字符串包含模式串的最多数目,然后就是进行O(4*500*114)的状态转移了。
HDU 2243 考研路茫茫——单词情结
题意:给定N(N < 6)个长度不超过5的单词,求包含至少一个单词并且长度不超过L(L < 231)的字符串的种数。
题解:利用PKU 2778的方法构造矩阵,由于求的是长度不超过L的种数,即长度为1、2、3...L,假设原有矩阵为M,那么构造一个新的矩阵M',它由两个原矩阵M,一个零矩阵O和一个单位阵I构成:
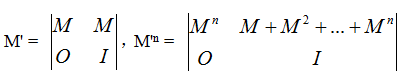 该矩阵的右上角的子矩阵就是我们所求的方案矩阵,然后对 M' 二分求幂即可。这里需要总数模264,利用补码的性质,可以直接声明unsigned __int64直接运算即可,不需要用到大数。
该矩阵的右上角的子矩阵就是我们所求的方案矩阵,然后对 M' 二分求幂即可。这里需要总数模264,利用补码的性质,可以直接声明unsigned __int64直接运算即可,不需要用到大数。
HDU 3247 Resource Archiver
题意:给定n(n <= 10)个长度小于等于1000的源字符串以及m(m <= 1000)个病毒串(所有病毒串总长度不超过50000),求一个串使得它包含所有的源字符串并且不包含任何一个病毒串,求这个字符串的最短长度(所有的串保证都是01串)。
题解:PKU 1699的加强版。
PKU 4052 Hrinity
题意:给定n(n <= 2500)个长度小于等于1100的模式串,求长度不大于5100000的目标串S中包含的模式串的数目,如果包含了模式串A和B,并且B是A的子串,那么只记录A。
题解:建立trie图,每个字符串结尾标记记录模式串编号,进行目标串匹配的时候,利用哈希将所有是目标串子串的模式串标记为1,然后枚举所有标记过的模式串,对他们进行模式匹配,利用同样的方法将模式串的所有模式串子串标记为0,最后统计有多少个模式串的标记为1就是答案了。
posted on 2014-07-10 14:26 英雄哪里出来 阅读(6043) 评论(6) 编辑 收藏 引用 所属分类: 算法专辑
评论
# re: AC自动机 回复 更多评论
这么多题哦,有的做做啦 ^_^# re: AC自动机 回复 更多评论
求这个字符串的最短长度# re: AC自动机 回复 更多评论
一直没有勇气学这个算法...# re: AC自动机 回复 更多评论
赞~\(≧▽≦)/~# re: AC自动机 回复 更多评论
看了好几篇关于失败指针的文章,终于明白是什么意思啦,谢谢( ⊙o⊙ )# re: AC自动机 回复 更多评论
建立trie图,每个字符串结尾标记记录模式串编号,进行目标串匹配的时候,利用哈希将所有是目标串子串的模式串标记为1,然后枚举所有标记过的模式串,对他们进行模式匹配,利用同样的方法将模式串的所有模式串子串标记为0,最后统计有多少个模式串的标记为1就是答案了,比如科室牌设计www.yfkeshipai.com也可以计算出每个字符串结尾标记记录模式串编号。