https://hadoop.apache.org/docs/r2.6.5/hadoop-project-dist/hadoop-hdfs/HDFSHighAvailabilityWithQJM.html
官方文档查看Apache Hadoop 2.6.5 - Hadoop Distributed File System-2.6.5 - High Availability

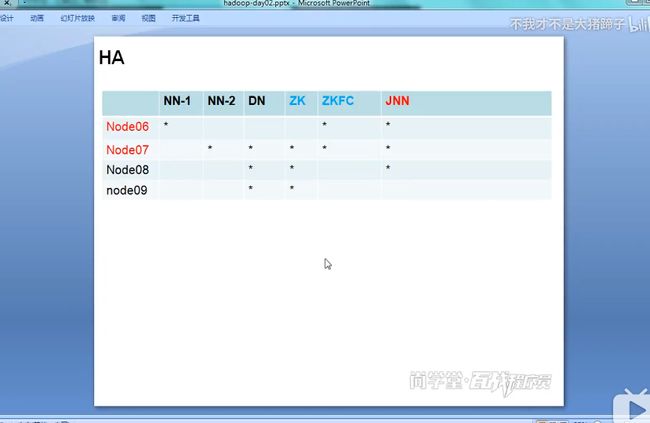
HA搭建效果图重要
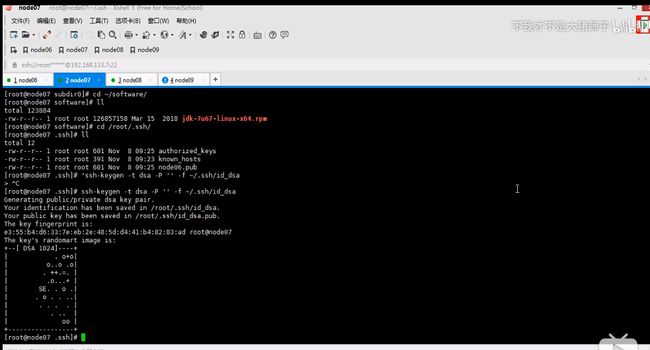
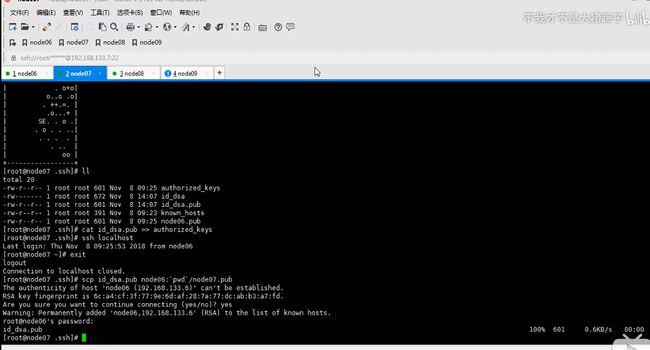
先是进行node06和node07互相的免秘钥登录

两个nn节点免秘钥
ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa
cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
搭建目标

继续搭建框架
实现自动故障转移

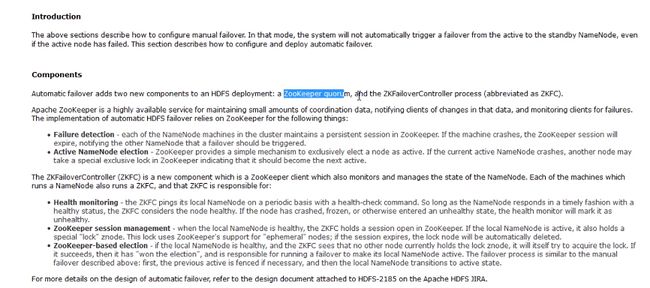
Components
Automatic failover adds two new components to an HDFS deployment: a ZooKeeper quorum, and the ZKFailoverController process (abbreviated as ZKFC).
Apache ZooKeeper is a highly available service for maintaining small amounts of coordination data, notifying clients of changes in that data, and monitoring clients for failures. The implementation of automatic HDFS failover relies on ZooKeeper for the following things:
Failure detection - each of the NameNode machines in the cluster maintains a persistent session in ZooKeeper. If the machine crashes, the ZooKeeper session will expire, notifying the other NameNode that a failover should be triggered.
Active NameNode election - ZooKeeper provides a simple mechanism to exclusively elect a node as active. If the current active NameNode crashes, another node may take a special exclusive lock in ZooKeeper indicating that it should become the next active.
The ZKFailoverController (ZKFC) is a new component which is a ZooKeeper client which also monitors and manages the state of the NameNode. Each of the machines which runs a NameNode also runs a ZKFC, and that ZKFC is responsible for:
Health monitoring - the ZKFC pings its local NameNode on a periodic basis with a health-check command. So long as the NameNode responds in a timely fashion with a healthy status, the ZKFC considers the node healthy. If the node has crashed, frozen, or otherwise entered an unhealthy state, the health monitor will mark it as unhealthy.
ZooKeeper session management - when the local NameNode is healthy, the ZKFC holds a session open in ZooKeeper. If the local NameNode is active, it also holds a special "lock" znode. This lock uses ZooKeeper's support for "ephemeral" nodes; if the session expires, the lock node will be automatically deleted.
ZooKeeper-based election - if the local NameNode is healthy, and the ZKFC sees that no other node currently holds the lock znode, it will itself try to acquire the lock. If it succeeds, then it has "won the election", and is responsible for running a failover to make its local NameNode active. The failover process is similar to the manual failover described above: first, the previous active is fenced if necessary, and then the local NameNode transitions to active state.
For more details on the design of automatic failover, refer to the design document attached to HDFS-2185 on the Apache HDFS JIRA.
Configuring automatic failover
The configuration of automatic failover requires the addition of two new parameters to your configuration. In your hdfs-site.xml file, add:
This specifies that the cluster should be set up for automatic failover. In your core-site.xml file, add:

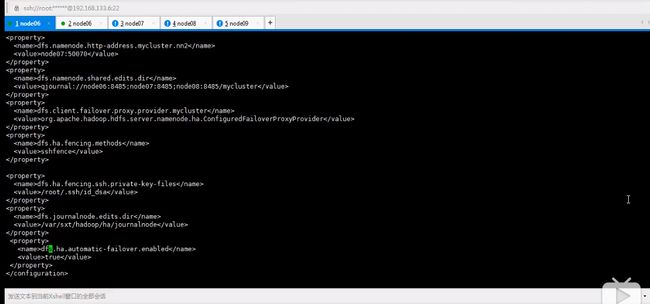
hdfs-site.mml文件
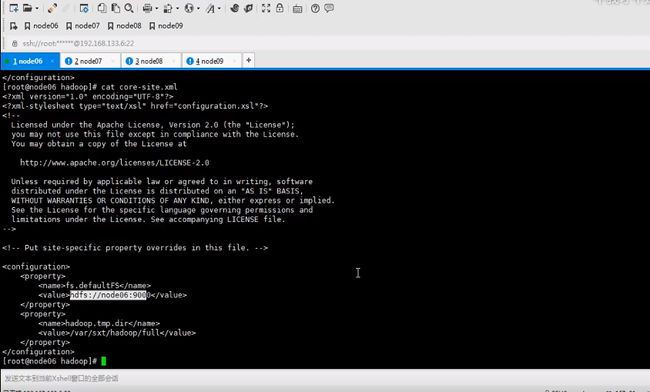
cat一下,发现只是单节点,不能这么做,因为这么做后只是单节点
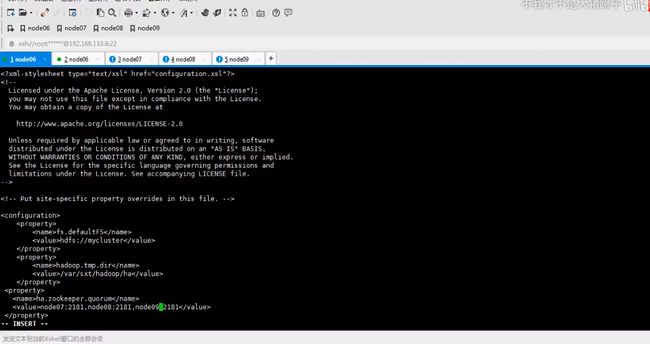
按照官方文档来配
to configure HA NameNodes, you must add several configuration options to your hdfs-site.xml configuration file.
The order in which you set these configurations is unimportant, but the values you choose for dfs.nameservices and dfs.ha.namenodes.[nameservice ID] will determine the keys of those that follow. Thus, you should decide on these values before setting the rest of the configuration options.
dfs.nameservices - the logical name for this new nameservice
Choose a logical name for this nameservice, for example "mycluster", and use this logical name for the value of this config option. The name you choose is arbitrary. It will be used both for configuration and as the authority component of absolute HDFS paths in the cluster.
Note: If you are also using HDFS Federation, this configuration setting should also include the list of other nameservices, HA or otherwise, as a comma-separated list.
dfs.ha.namenodes.[nameservice ID] - unique identifiers for each NameNode in the nameservice
Configure with a list of comma-separated NameNode IDs. This will be used by DataNodes to determine all the NameNodes in the cluster. For example, if you used "mycluster" as the nameservice ID previously, and you wanted to use "nn1" and "nn2" as the individual IDs of the NameNodes, you would configure this as such:
Note: Currently, only a maximum of two NameNodes may be configured per nameservice.
dfs.namenode.rpc-address.[nameservice ID].[name node ID] - the fully-qualified RPC address for each NameNode to listen on
For both of the previously-configured NameNode IDs, set the full address and IPC port of the NameNode processs. Note that this results in two separate configuration options. For example:
Note: You may similarly configure the "servicerpc-address" setting if you so desire.
dfs.namenode.http-address.[nameservice ID].[name node ID] - the fully-qualified HTTP address for each NameNode to listen on
Similarly to rpc-address above, set the addresses for both NameNodes' HTTP servers to listen on. For example:
看了上面的文档,有点乱,总结一下
打开hdfs-site.xml
去掉snn的配置
没必要了
增加:
Choose a logical name for this nameservice, for example "mycluster", and use this logical name for the value of this config option. The name you choose is arbitrary. It will be used both for configuration and as the authority component of absolute HDFS paths in the cluster.
名字可以随便改,nameservice,叫主节点服务id,id叫mycluster,用来指向需要做namenode配置的主从节点,入口
Configure with a list of comma-separated NameNode IDs. This will be used by DataNodes to determine all the NameNodes in the cluster. For example, if you used "mycluster" as the nameservice ID previously, and you wanted to use "nn1" and "nn2" as the individual IDs of the NameNodes, you would configure this as such。
名字必须和上一个配置相同,都是mycluster
2.0只能搭建两个,一主一从
dfs.namenode.rpc-address.[nameservice ID].[name node ID] - the fully-qualified RPC (远程物理调用)address for each NameNode to listen on
For both of the previously-configured NameNode IDs, set the full address and IPC port of the NameNode processs. Note that this results in two separate configuration options. For example:
上面都是逻辑id,怎么和机器联系起来呢?
下面的配置描述了
物理机和物理映射做了修改
dfs.namenode.http-address.[nameservice ID].[name node ID] - the fully-qualified HTTP address for each NameNode to listen on
Similarly to rpc-address above, set the addresses for both NameNodes' HTTP servers to listen on. For example:
为了浏览器配置
dfs.namenode.shared.edits.dir - the URI which identifies the group of JNs where the NameNodes will write/read edits
This is where one configures the addresses of the JournalNodes which provide the shared edits storage, written to by the Active nameNode and read by the Standby NameNode to stay up-to-date with all the file system changes the Active NameNode makes. Though you must specify several JournalNode addresses, you should only configure one of these URIs. The URI should be of the form: "qjournal://host1:port1;host2:port2;host3:port3/journalId". The Journal ID is a unique identifier for this nameservice, which allows a single set of JournalNodes to provide storage for multiple federated namesystems. Though not a requirement, it's a good idea to reuse the nameservice ID for the journal identifier.
For example, if the JournalNodes for this cluster were running on the machines "node1.example.com", "node2.example.com", and "node3.example.com" and the nameservice ID were "mycluster", you would use the following as the value for this setting (the default port for the JournalNode is 8485):
这是为了配置journalnode集群,管理日志文件
mycluster代表当前集群的日志信息,代表信息放在此下
qjorual固定写法
直接写就是了,实现故障转移,代理
这是私钥。dsa和rsa原理一样
改配置保证隔离。一旦故障,把他状态降低
保证任何时候只有一台处于存活状态,另一台standby
表示存放地址
实现自动故障转移
在core-site.xml
-----------------------------------------
hadoop.tmp.dir的配置要变更:/var/sxt/hadoop-2.6/ha
原来为node006:9000,现在改变就是为了集群,名称为mycluster,电脑可以从mycluster进入,一主一从,开启服务
可以随意搭建,最小节点三台
然后
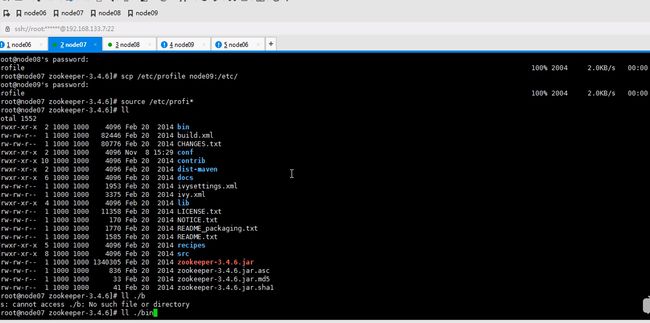
分发 hdfs.xml 和core.xml 给其他节点
scp core-site.xml hdfs-site .xml node07:`pwd`还有八和九
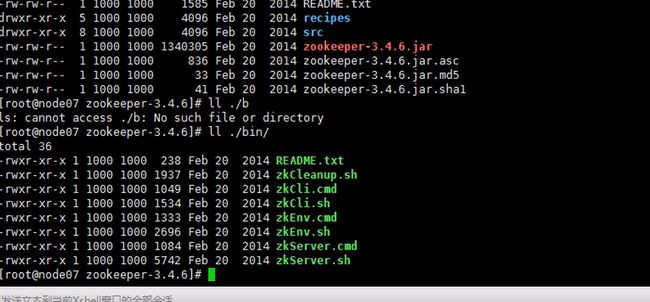
开始搭建zookeeper
注意
这里安装在node07并不是node06
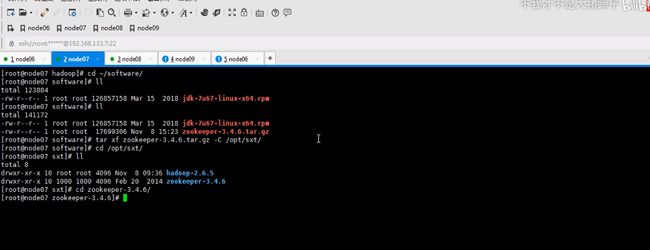
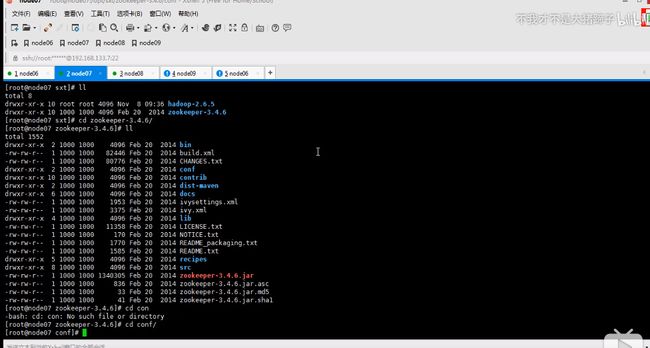
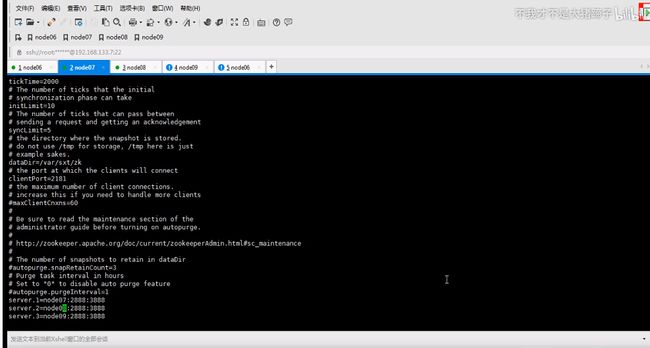
zookeeper是一主多从的机制,这里配置serverid,id谁大谁优先级高这里编号123
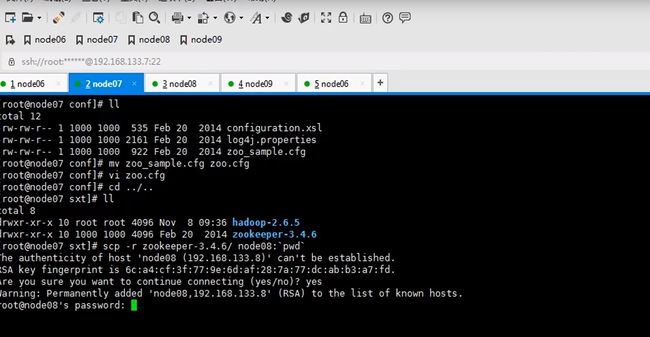
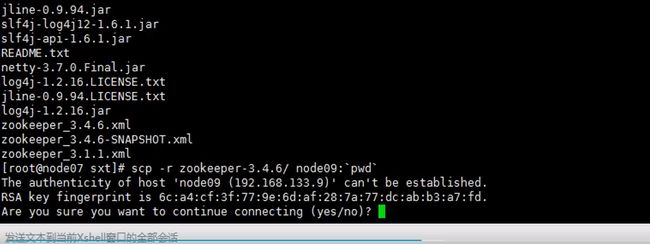
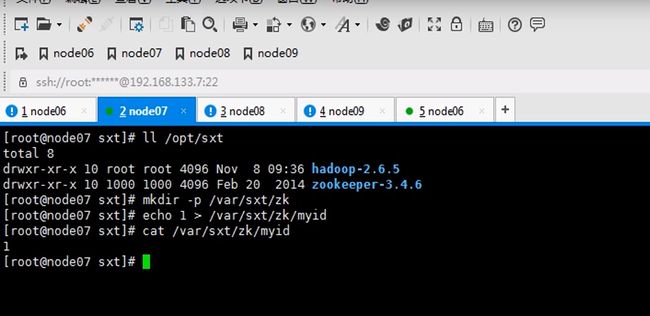
所以要mkdir一下,存储信息
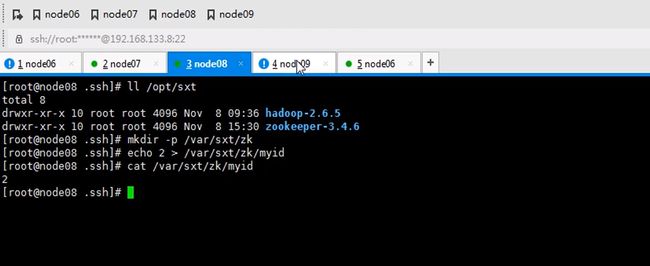
七八九都要执行一遍,因为启动时要读取这个文件id也不要写错,123
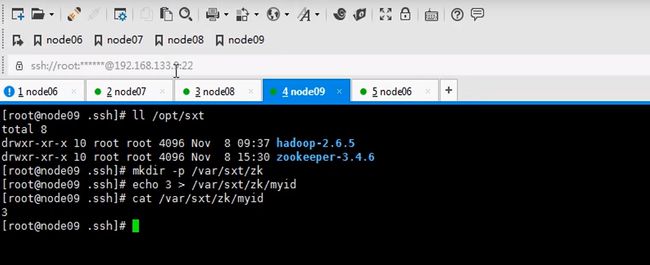
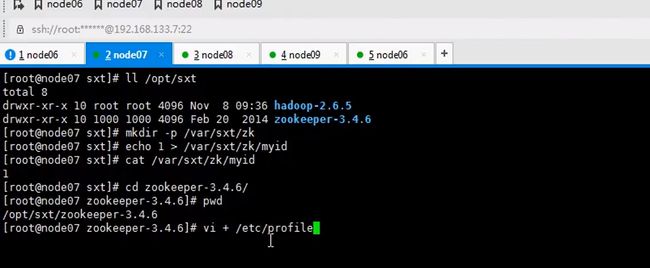
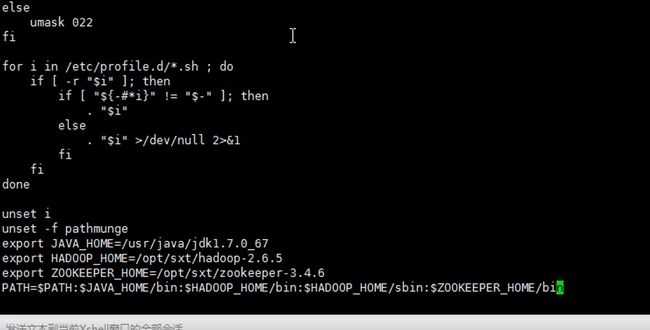
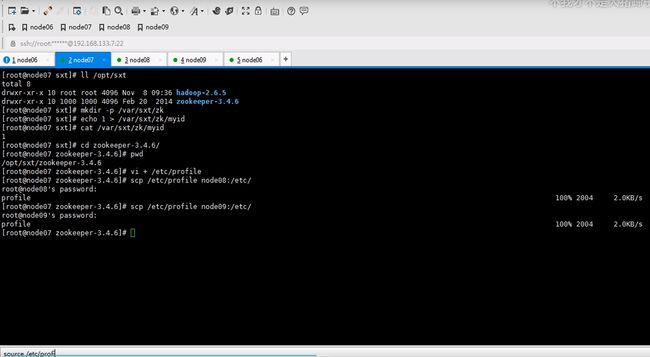
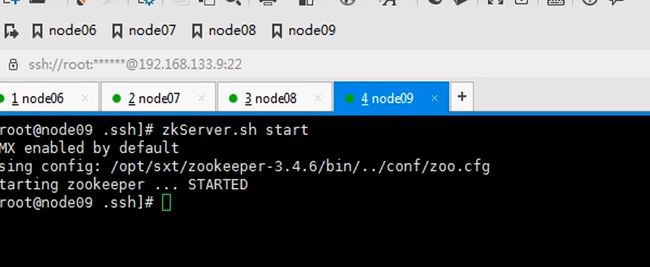
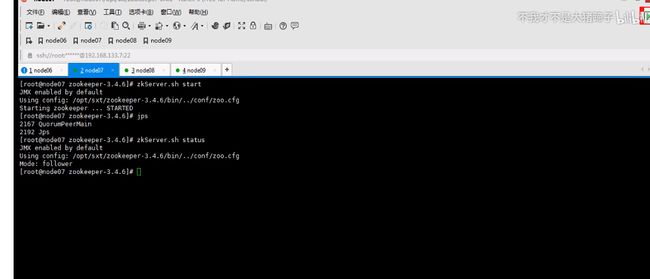
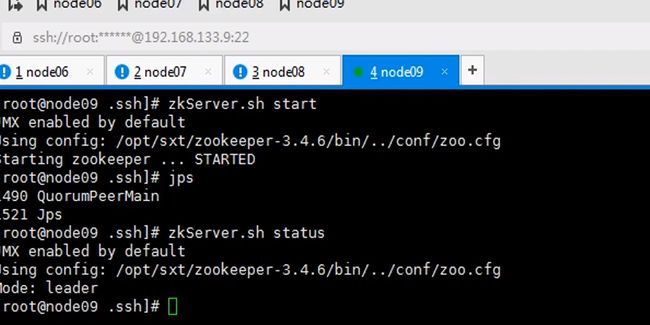
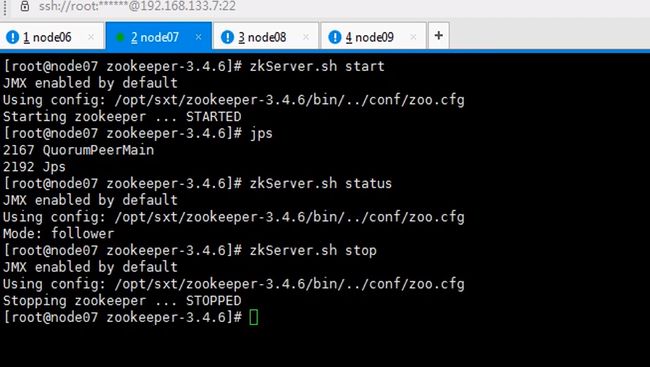
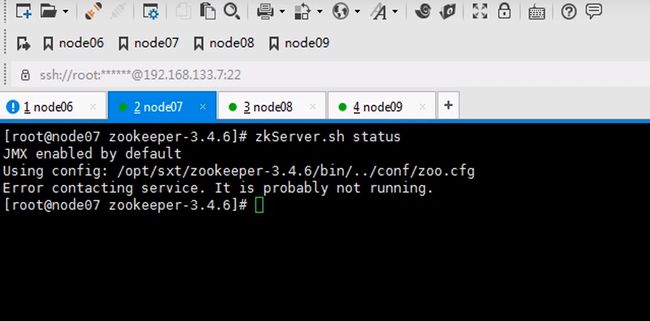
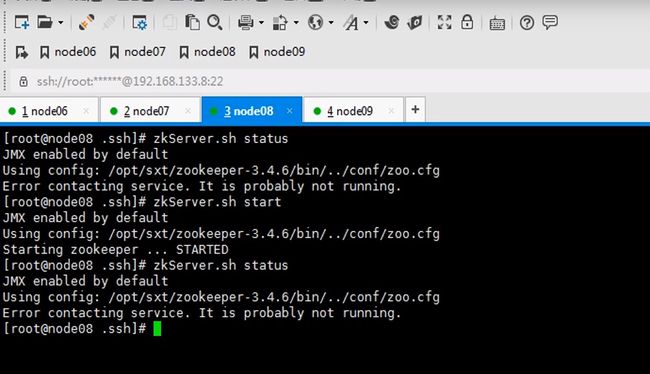
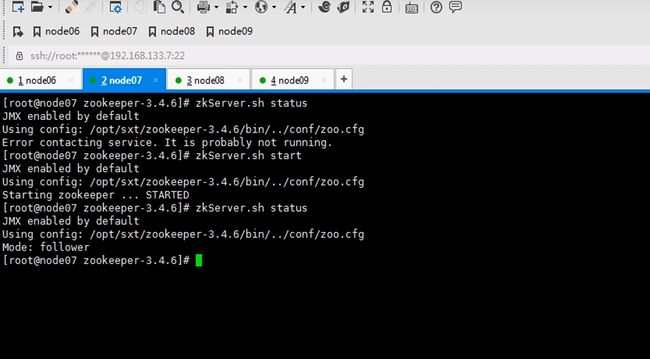
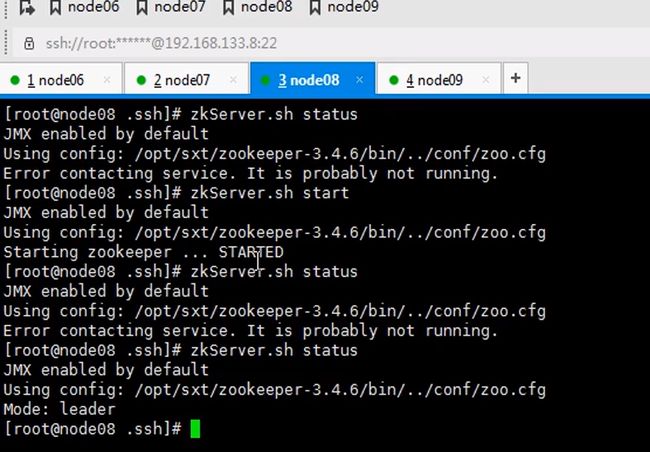
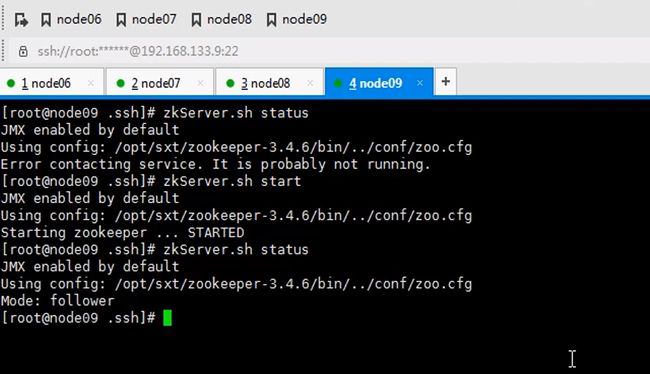


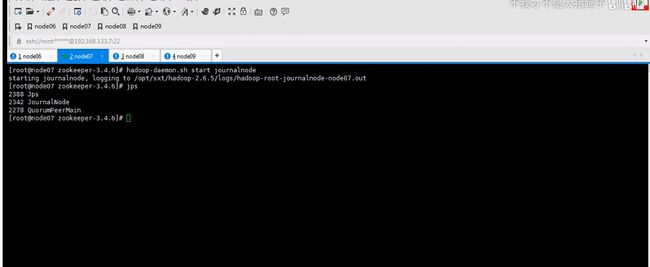
让六七八都跑journalnode
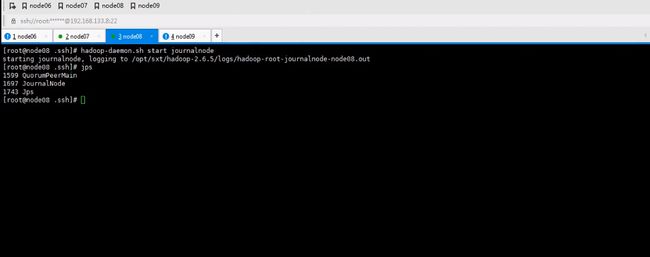
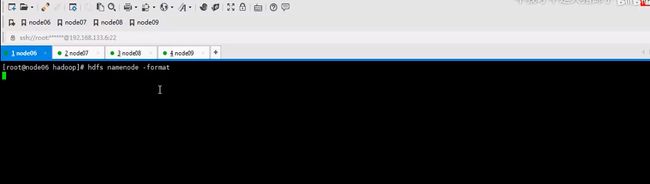
格式化生成集群地址和clusterid,如果其他执行了。id不一致构不成集群
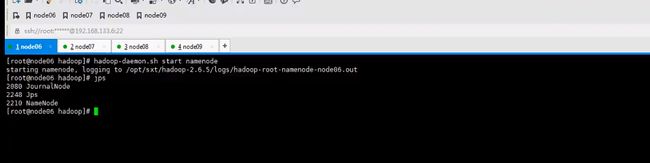
启动namenode
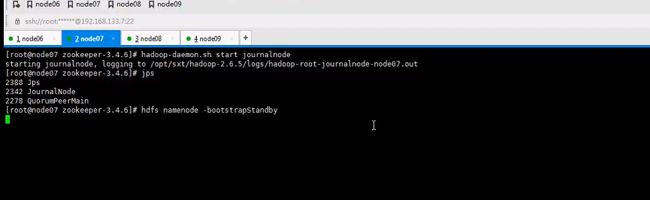
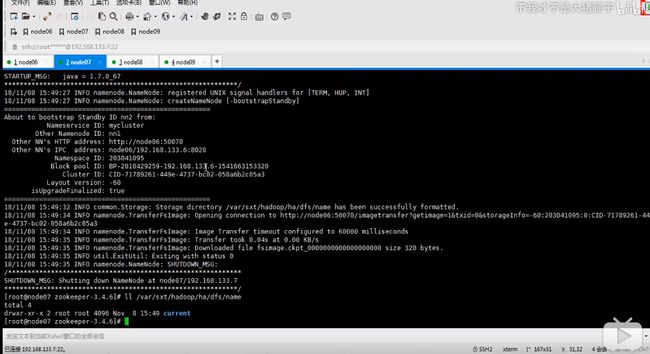
-bootstrapstandby把namenode原数据同步
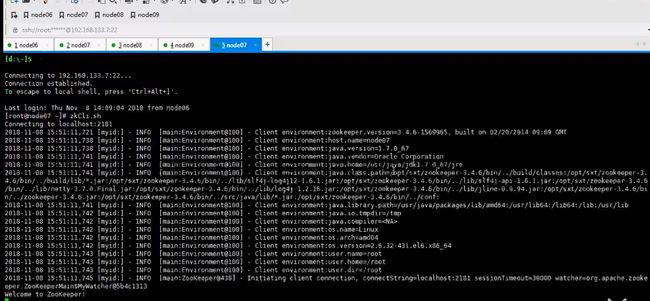
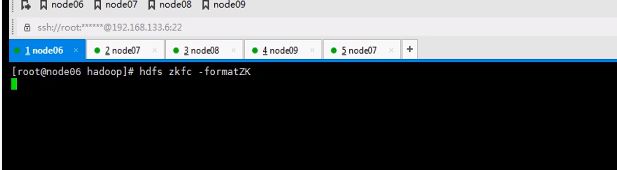
并不是初始化zok,而是hdfs在zookeeper上执行
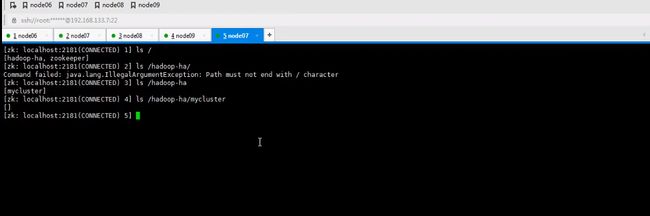
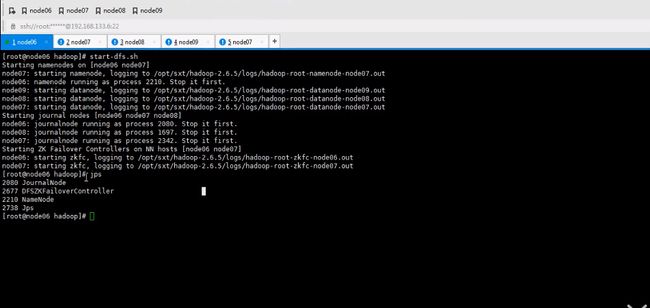
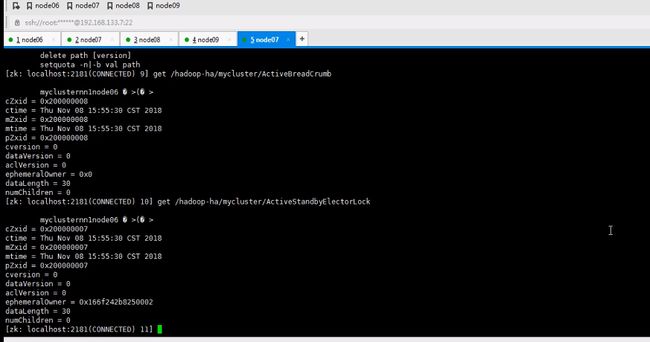

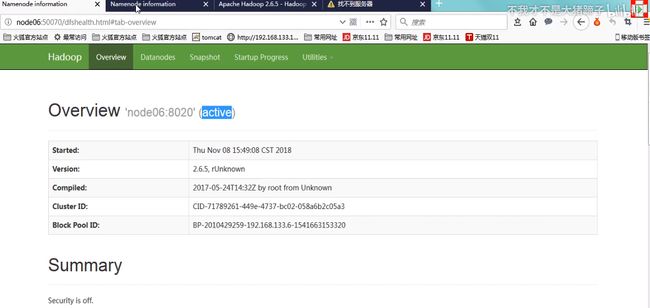
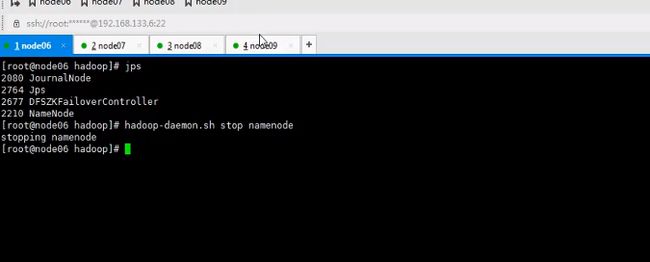
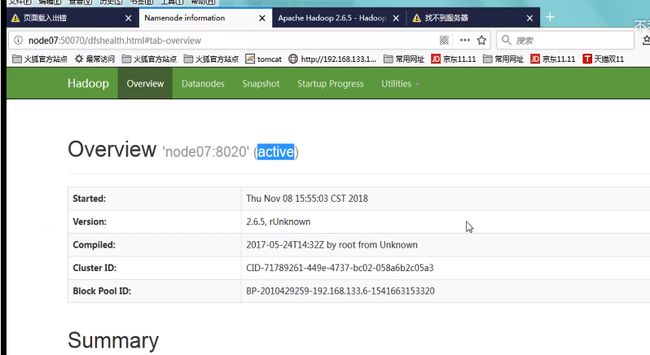
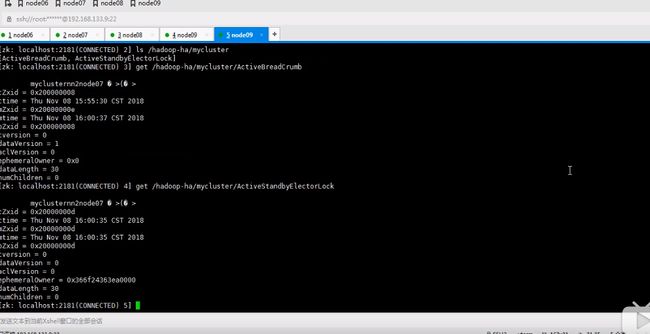
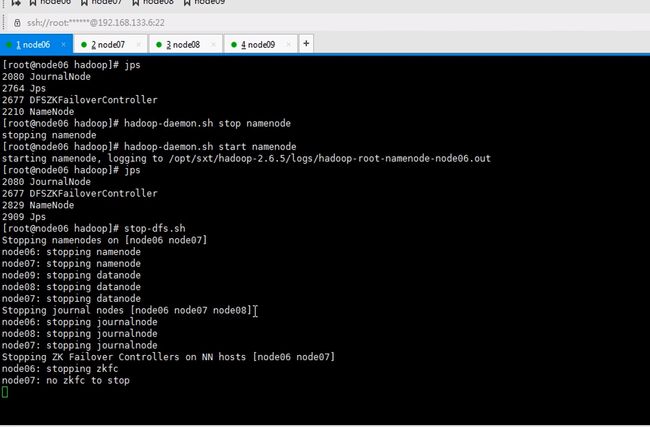
这是千万不要使用formate命令了