Python实现新版正方教务系统爬虫
目录~
- 引入
- 需要什么软件?
- 模拟登陆
- 代码实现(登陆)
- 模拟获取成绩
- 代码实现(获取成绩)
- 解析成绩
- 测试(完成图)
- 作者的话
引入
就在我刚刚写完旧版正方系统爬虫的时候(旧版正方系统爬虫代码)
学校就出了新版的正方教务系统

估计是装空调的钱有的多
那就开始讲解叭~

需要什么软件?
- 基本的
- Python! (我最喜欢3.x的版本啦)
- 一个你喜欢的IDE! (顺手的IDE事半功倍哦)
- 库
- requests(爬虫基本都大家都明白的吧~)
- BeautifulSoup(解析结构化数据很好用啦)
- re(正则化表达式html还算好用吧)
- time(这是网址中神秘代码的来源哦)
- datetime(这个可以不加啦 我做了和数据库的链接方便记录时间)
- subprocess(委屈 是不经意间没有办法捡来的解决办法)
- sys(防止报错意外停止啦)
- 扩展的
- Fiddler 4!(模拟爬虫是真滴好用)
模拟登陆
-
首先我们启动Fiddler 然后正常访问一下教务系统

发现了这两条事件
第78条事件就是访问主页面啦
但是第80条事件返回了一个json格式的数据 不知道干嘛的 先保存下来吧 -
输入账号密码
![]()
在Fiddler中出现了一条post数据

点一下WebForms看看带了什么数据进去
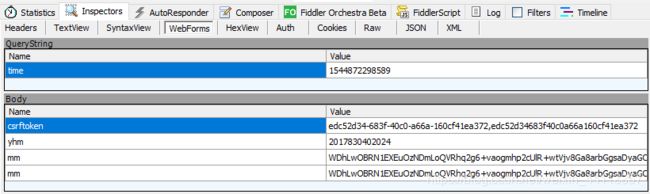
| Body | Value |
|---|---|
| time | time库里的time~ |
| csrftioken | 不知道什么东西 怎么没出现过 |
| yhm | 用户名是明文唉 大家心知肚明就好了 |
| mm | 这个就是输入的密码了 一看就经过了加密 |
什么??加密过了??那是怎么加密的呢
在主页面经过审查元素发现了js的文件

啊~在login.js里面 找到了这些代码
$.getJSON(_path+"/xtgl/login_getPublicKey.html?time="+new Date().getTime(),function(data){
modulus = data["modulus"];
exponent = data["exponent"];
});
------我是分割符------
var rsaKey = new RSAKey();
rsaKey.setPublic(b64tohex(modulus), b64tohex(exponent));
var enPassword = hex2b64(rsaKey.encrypt($("#mm").val()));
$("#mm").val(enPassword);
$("#hidMm").val(enPassword);
大概翻译一下就是
获取了publishkey之后使用publishkey对明文的密码做RSA算法加密再使用BASE64填充

升级了系统不就是不用验证码了吗 为什么做爬虫更累了呢

- 总结一下
- 保存PublishKey
- 对密码进行加密
- 获取csrftoken
- 登陆!
代码实现(登陆)
首先准备一个session(会话)
session = requests.Session()
time_now = int(time.time())
session.headers.update({
'Accept': 'text/html, */*; q=0.01',
'Accept-Encoding': 'gzip, deflate',
'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:58.0) Gecko/20100101 Firefox/58.0',
'X-Requested-With': 'XMLHttpRequest',
'Connection': 'keep-alive',
'Content-Length': '0',
'Content-Type': 'application/x-www-form-urlencoded',
'Host': 'qjxyjw.hznu.edu.cn',
'Referer': 'http://qjxyjw.hznu.edu.cn/jwglxt/xtgl/index_initMenu.html?jsdm=&_t=' + str(time_now),
'Upgrade-Insecure-Requests': '1'
})
至于这个头是怎么来的 详情Fiddler
# 准备publickey
url = 'http://qjxyjw.hznu.edu.cn/jwglxt/xtgl/login_getPublicKey.html?time=' + str(time_now)
r = session.get(url)
publickey = r.json()
提一下这个csrftoken 找来找去最后在访问主页面的时候找到了
# 准备csrftoken
url = 'http://qjxyjw.hznu.edu.cn/jwglxt/xtgl/login_slogin.html?language=zh_CN&_t=' + str(time_now)
r = session.get(url)
r.encoding = r.apparent_encoding
soup = BeautifulSoup(r.text, 'html.parser')
csrftoken = soup.find('input', attrs={'id': 'csrftoken'}).attrs['value']
说一下这个加密 虽然github上面有大佬从js里面移植过来的rsa算法 但是我无论如何都用不来
只好用别人的java程序 在python里面使用txt对密码传输(虽然很low但是是无奈之举了)

url = r"C:\Users\Administrator\Desktop\new_jiaowu"
f = open(url + r"\code.txt", "w")
f.write(studentid + '\n')
f.write(studentpwd + '\n')
f.write(publickey['modulus'] + '\n')
f.write(publickey['exponent'] + '\n')
f.close()
try:
subprocess.Popen('code.exe', shell=False, close_fds=True)
except:
print("启动加密程序错误")
sys.exit()
time.sleep(1)
with open(url + r"\encode.txt", 'r') as f:
list1 = f.readlines()
for i in range(0, len(list1)):
list1[i] = list1[i].rstrip('\n')
id = list1[0]
rsacode = list1[1]
f.close()
if id != studentid:
print("RSA加密错误...等待调试")
sys.exit()
对应的java代码在笔记本里 给个空位=。=
等待更新
嘿嘿嘿东西都准备好了 尝试登陆吧
try:
url = 'http://qjxyjw.hznu.edu.cn/jwglxt/xtgl/login_slogin.html'
data = {
'csrftoken': csrftoken,
'mm': rsacode,
'mm': rsacode,
'yhm': studentid
}
result = session.post(url, data=data)
return result.text
except Exception as e:
print(e)
如果密码输入错误的话会有提示框 这里使用in就可以简单的实现判断了
if '用户名或密码不正确' in result.text:
return "用户名或密码不正确"
最后 封装一下 就实现了主页面登陆的按钮啦
贴个代码
def login(studentid, studentpwd, session):
time_now = int(time.time())
# 准备publickey
url = 'http://qjxyjw.hznu.edu.cn/jwglxt/xtgl/login_getPublicKey.html?time=' + str(time_now)
r = session.get(url)
publickey = r.json()
# 准备csrftoken
url = 'http://qjxyjw.hznu.edu.cn/jwglxt/xtgl/login_slogin.html?language=zh_CN&_t=' + str(time_now)
r = session.get(url)
r.encoding = r.apparent_encoding
soup = BeautifulSoup(r.text, 'html.parser')
csrftoken = soup.find('input', attrs={'id': 'csrftoken'}).attrs['value']
# 加密密码
url = r"C:\Users\Administrator\Desktop\new_jiaowu"
f = open(url + r"\code.txt", "w")
f.write(studentid + '\n')
f.write(studentpwd + '\n')
f.write(publickey['modulus'] + '\n')
f.write(publickey['exponent'] + '\n')
f.close()
try:
subprocess.Popen('code.exe', shell=False, close_fds=True)
except:
print("启动加密程序错误")
sys.exit()
time.sleep(1)
with open(url + r"\encode.txt", 'r') as f:
list1 = f.readlines()
for i in range(0, len(list1)):
list1[i] = list1[i].rstrip('\n')
id = list1[0]
rsacode = list1[1]
f.close()
if id != studentid:
print("RSA加密错误...等待调试")
sys.exit()
# 单击登录按钮
try:
url = 'http://qjxyjw.hznu.edu.cn/jwglxt/xtgl/login_slogin.html'
data = {
'csrftoken': csrftoken,
'mm': rsacode,
'mm': rsacode,
'yhm': studentid
}
result = session.post(url, data=data)
return result.text
except Exception as e:
print(e)
模拟获取成绩
老样子 我们先模拟登陆使用Fiddler看看是怎么一个过程
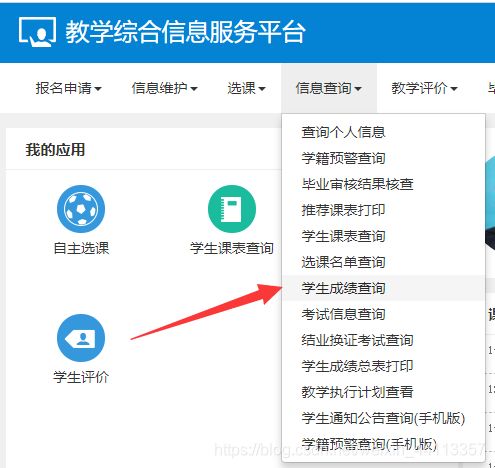
这里可以一次性查询所有成绩有一点点方便
![]()
铛铛 在Fiddler中发现了如下数据

| Body | Value |
|---|---|
| xnm | 学年名 |
| xqm | 学期名 |
| _search | 固定false |
| nd | 这个和之前的time一样的啦 都是time库里面的time函数整数化一下就好了 |
| query* | 固定的 照抄照抄 |
| time | 固定0(总觉得这个的存在是正方有点问题) |
还是提一下这里学期名 发现第一学期发送的是3 第二学期发送的是12

代码实现(获取成绩)
def score_page(session, year, term):
url = 'http://qjxyjw.hznu.edu.cn/jwglxt/cjcx/cjcx_cxDgXscj.html?doType=query&gnmkdm=N305005'
# 定义所有学期 3为第一学期 12为第二学期
if term == "1":
term = "3"
elif term == "2":
term = "12"
try:
data = {'_search': 'false',
'nd': int(time.time()),
'queryModel.currentPage': '1',
'queryModel.showCount': '15',
'queryModel.sortName': '',
'queryModel.sortOrder': 'asc',
'time': '0',
'xnm': year,
'xqm': term
}
result = session.post(url, data=data)
result = result.json()
return result
except:
return '[Error]获取该学期成绩失败'
解析成绩
既然成绩我们都获取到啦 还很方便给的是json数据 so 你懂了吗
stu_name = result['items'][0]['xm']
sch_stu = result['items'][0]['xslb']
institute = result['items'][0]['jgmc']
stu_class = result['items'][0]['bj']
print('姓名:{}\t学历:{}\t\t学院:{}\t班级:{}'.format(stu_name, sch_stu, institute, stu_class))
# dt = datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S")
plt = '{0:{4}<15}\t{1:{4}<6}\t{2:{4}<6}\t{3:{4}<4}'
for i in result['items']:
print(plt.format(i['kcmc'], i['bfzcj'], i['jd'], i['jsxm'], chr(12288)))
# sql.insert_score(studentid, year, term, i['kcmc'], i['bfzcj'], i['jd'], i['jsxm'], dt)
因为后面我做好了和sql数据库的写入 作为演示 我都注释掉啦
测试(完成图)
嗝。。因为加密密码的环境问题 之后用笔记本再贴进来啦 给个空位=。=
(我是图片)
作者的话
为了这个程序真的是心力憔悴(写博客的格式更累)
但是还是结束啦~

希望能帮助到学习爬虫的各位~