强化学习(1)马尔科夫决策过程(MDP)
强化学习
开始强化学习之前先来了解强化学习、深度学习、深度强化学习、监督学习、无监督学习、机器学习和人工智能之间的关系。如下图:

强化学习是机器学习的一个重要分支,它试图解决决策优化的问题。所谓决策优化,是指面对特定状态(Stata,S),采取什么行动方案(Action,A),才能使收益最大(Reward,R)。
强化学习的基本原理
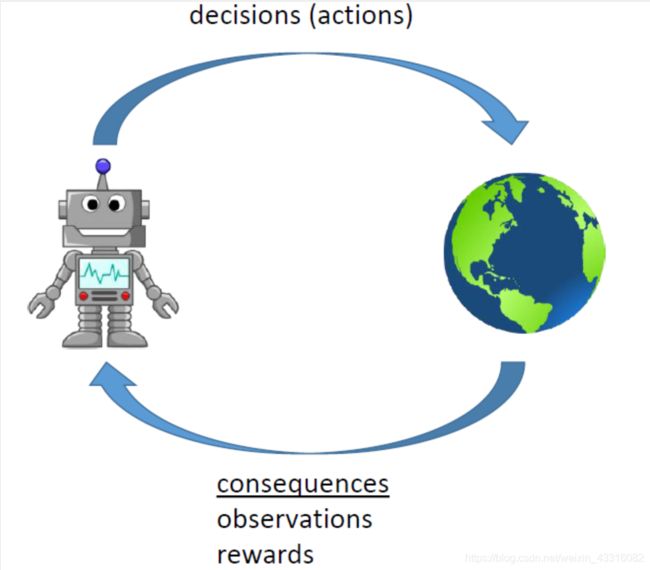
智能体在执行某项任务时,首先通过动作A与周围环境进行交互,在动作A和环境的作用下,智能体会产生新的状态,同时环境会给出一个立即回报。如此循环下去,智能体与环境进行不断地交互从而产生很多数据。强化学习算法利用产生的数据修改自身的动作策略,再与环境交互,产生新的数据,并利用新的数据进一步改善自身的行为,经过数次迭代学习后,智能体能最终地学到完成相应任务的最优动作(最优策略)。
最简单的强化学习的数学模型,是马尔科夫决策过程(Markov Decision Process),简称MDP。文章主要讲如何利用马尔科夫决策过程对强化学习建模。
先介绍一些相关概念:
马尔科夫性
马尔科夫性是指系统的下一个状态 s t + 1 s_{t+1} st+1仅与当前状态 s t s_t st有关,而与以前的状态无关。
定义:状态 s t s_t st 是马尔科夫的,当且仅当 P [ s t + 1 ∣ s t ] = P [ s t + 1 ∣ s 1 , ⋯ , s t ] P\left[s_{t+1}|s_t\right]=P\left[s_{t+1}|s_1,\cdots ,s_t\right] P[st+1∣st]=P[st+1∣s1,⋯,st]。
定义中可以看到,当前状态 s t s_t st 其实是蕴含了所有相关的历史信息 s 1 , ⋯ , s t s_1,\cdots ,s_t s1,⋯,st,一旦当前状态已知,历史信息将会被抛弃。
马尔科夫过程
马尔科夫过程的定义:马尔科夫过程是一个二元组 ( S , P ) \left(S,P\right) (S,P),且满足: S S S是有限状态集合, P P P是状态转移概率。状态转移概率矩阵为:
P = [ P 11 ⋯ P 1 n ⋮ ⋮ ⋮ P n 1 ⋯ P n n ] P=\left[\begin{matrix} P_{11}& \cdots& P_{1n}\\ \vdots& \vdots& \vdots\\ P_{n1}& \cdots& P_{nn}\\ \end{matrix}\right] P=⎣⎢⎡P11⋮Pn1⋯⋮⋯P1n⋮Pnn⎦⎥⎤。
马尔科夫决策过程
马尔科夫决策过程由元组 ( S , A , P , R , γ ) \left(S,A,P,R,\gamma\right) (S,A,P,R,γ)描述,其中:
S S S为有限的状态集
A A A 为有限的动作集
P P P 为状态转移概率
R R R为回报函数
γ \gamma γ 为折扣因子,用来计算累积回报。
注意,跟马尔科夫过程不同的是,马尔科夫决策过程的状态转移概率是包含动作的即: P s s ′ a = P [ S t + 1 = s ′ ∣ S t = s , A t = a ] P_{ss'}^{a}=P\left[S_{t+1}=s'|S_t=s,A_t=a\right] Pss′a=P[St+1=s′∣St=s,At=a]
强化学习的目标是给定一个马尔科夫决策过程,寻找最优策略。所谓策略是指状态到动作的映射,策略常用符号 π \pi π 表示,它是指给定状态 s s s 时,动作集上的一个分布,即
π ( a ∣ s ) = p [ A t = a ∣ S t = s ] \pi\left(a|s\right)=p\left[A_t=a|S_t=s\right] π(a∣s)=p[At=a∣St=s]
公式的含义是:策略 π \pi π在每个状态 s s s 指定一个动作概率。如果给出的策略 π \pi π是确定性的,那么策略 π \pi π在每个状态 s s s指定一个确定的动作。
当给定一个策略 π \pi π时,我们就可以计算累积回报。首先定义累积回报:
G t = R t + 1 + γ R t + 2 + ⋯ = ∑ k = 0 ∞ γ k R t + k + 1 G_t=R_{t+1}+\gamma R_{t+2}+\cdots =\sum_{k=0}^{\infty}{\gamma^kR_{t+k+1}} Gt=Rt+1+γRt+2+⋯=∑k=0∞γkRt+k+1
当给定策略 π \pi π时,假设从状态 s 1 s_1 s1 出发,状态序列可能为:
s 1 → s 2 → s 3 → s 4 → s 5 ; s 1 → s 2 → s 3 → s 5 . . . . . . s_1\rightarrow s_2\rightarrow s_3\rightarrow s_4\rightarrow s_5 ;\\ s_1\rightarrow s_2\rightarrow s_3\rightarrow s_5 \\ ...... s1→s2→s3→s4→s5;s1→s2→s3→s5......
即当给定策略 π \pi π时,会有多个状态序列,累计回报 G 1 G_1 G1有多个可能值 。
为了评价状态 s 1 s_1 s1的价值,我们需要定义一个确定量来描述状态 s 1 s_1 s1的价值,很自然的想法是利用累积回报来衡量状态 s 1 s_1 s1 的价值。然而,累积回报 G 1 G_1 G1 是个随机变量,不是一个确定值,因此无法进行描述。但其期望是个确定值,可以作为状态值函数的定义。
状态值函数与状态-行为值函数
当智能体采用策略 π \pi π时,累积回报服从一个分布,累积回报在状态 s s s处的期望值定义为状态-值函数:
υ π ( s ) = E π [ ∑ k = 0 ∞ γ k R t + k + 1 ∣ S t = s ] \upsilon_{\pi}\left(s\right)=E_{\pi}\left[\sum_{k=0}^{\infty}{\gamma^kR_{t+k+1}|S_t=s}\right] υπ(s)=Eπ[∑k=0∞γkRt+k+1∣St=s]
相应地,状态-行为值函数:
q π ( s , a ) = E π [ ∑ k = 0 ∞ γ k R t + k + 1 ∣ S t = s , A t = a ] q_{\pi}\left(s,a\right)=E_{\pi}\left[\sum_{k=0}^{\infty}{\gamma^kR_{t+k+1}|S_t=s,A_t=a}\right] qπ(s,a)=Eπ[∑k=0∞γkRt+k+1∣St=s,At=a]
状态值函数与状态-行为值函数的贝尔曼方程
在这里我们直接给出贝尔曼方程,具体数学推导见文末。
v π ( s ) = E π ( R t + 1 + γ v π ( S t + 1 ) ∣ S t = s ) v_{\pi}(s)=\mathbb{E}_{\pi}\left(R_{t+1}+\gamma v_{\pi}\left(S_{t+1}\right) | S_{t}=s\right) vπ(s)=Eπ(Rt+1+γvπ(St+1)∣St=s) (1.1)
q π ( s , a ) = E π ( R t + 1 + γ q π ( S t + 1 , A t + 1 ) ∣ S t = s , A t = a ) q_{\pi}(s, a)=\mathbb{E}_{\pi}\left(R_{t+1}+\gamma q_{\pi}\left(S_{t+1}, A_{t+1}\right) | S_{t}=s, A_{t}=a\right) qπ(s,a)=Eπ(Rt+1+γqπ(St+1,At+1)∣St=s,At=a)
状态值函数与状态-行为值函数的递推关系

图B计算公式为
υ π ( s ) = ∑ a ∈ A π ( a ∣ s ) q π ( s , a ) ( 1.2 ) \upsilon_{\pi}\left(s\right)=\sum_{a\in A}{\pi\left(a|s\right)q_{\pi}\left(s,a\right)}\left(1.2\right) υπ(s)=∑a∈Aπ(a∣s)qπ(s,a)(1.2)
也就是说,状态值函数是所有状态-行为值函数基于策略 π π π的期望。通俗说就是某状态下所有状态-行为值乘以该动作出现的概率,最后求和,就得到了对应的状态价值。
图C计算状态-行为值函数为:
q π ( s , a ) = R s a + γ ∑ s ′ P s s ′ a υ π ( s ′ ) ( 1.3 ) q_{\pi}\left(s,a\right)=R_{s}^{a}+\gamma\sum_{s'}{P_{ss'}^{a}}\upsilon_{\pi}\left(s'\right)\left(1.3\right) qπ(s,a)=Rsa+γ∑s′Pss′aυπ(s′)(1.3)
将(1.3)式带入到(1.2)式可以得到状态值函数:
υ π ( s ) = ∑ a ∈ A π ( a ∣ s ) ( R s a + γ ∑ s ′ ∈ S P s s ′ a υ π ( s ′ ) ) \upsilon_{\pi}\left(s\right)=\sum_{a\in A}{\pi\left(a|s\right)\left(R_{s}^{a}+\gamma\sum_{s'\in S}{P_{ss'}^{a}\upsilon_{\pi}\left(s'\right)}\right)} υπ(s)=∑a∈Aπ(a∣s)(Rsa+γ∑s′∈SPss′aυπ(s′)) (1.4)
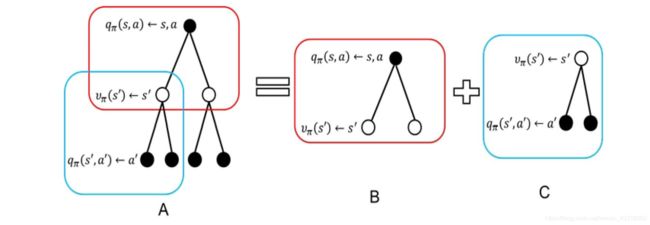
在C中
υ π ( s ′ ) = ∑ a ′ ∈ A π ( a ′ ∣ s ′ ) q π ( s ′ , a ′ ) ( 1.5 ) \upsilon_{\pi}\left(s'\right)=\sum_{a'\in A}{\pi\left(a'|s'\right)q_{\pi}\left(s',a'\right)}\left(1.5\right) υπ(s′)=∑a′∈Aπ(a′∣s′)qπ(s′,a′)(1.5)
将(1.5)带入到(1.3)中,得到行为状态-行为值函数:
q π ( s , a ) = R s a + γ ∑ s ′ ∈ S P s s ′ a ∑ a ′ ∈ A π ( a ′ ∣ s ′ ) q π ( s ′ , a ′ ) q_{\pi}\left(s,a\right)=R_{s}^{a}+\gamma\sum_{s'\in S}{P_{ss'}^{a}\sum_{a'\in A}{\pi\left(a'|s'\right)q_{\pi}\left(s',a'\right)}} qπ(s,a)=Rsa+γ∑s′∈SPss′a∑a′∈Aπ(a′∣s′)qπ(s′,a′) (1.6)
最优价值函数
计算状态值函数的目的是为了构建学习算法从数据中得到最优策略。每个策略对应着一个状态值函数,最优策略自然对应着最优状态值函数。
定义:最优状态值函数 υ ∗ ( s ) \upsilon^*\left(s\right) υ∗(s),为在所有策略中值最大的值函数即:
υ ∗ ( s ) = max π υ π ( s ) \upsilon^*\left(s\right)=\max_{\pi}\upsilon_{\pi}\left(s\right) υ∗(s)=maxπυπ(s)
最优状态-行为值函数 q ∗ ( s , a ) q^*\left(s,a\right) q∗(s,a)为在所有策略中最大的状态-行为值函数,即:
q ∗ ( s , a ) = max π q π ( s , a ) q^*\left(s,a\right)=\max_{\pi}q_{\pi}\left(s,a\right) q∗(s,a)=maxπqπ(s,a)
我们由(1.4)式和(1.6)式分别得到最优状态值函数和最优状态-行动值函数的贝尔曼最优方程:
υ ∗ ( s ) = max a R s a + γ ∑ s ′ ∈ S P s s ′ a υ ∗ ( s ′ ) \upsilon^*\left(s\right)=\max_aR_{s}^{a}+\gamma\sum_{s'\in S}{P_{ss'}^{a}\upsilon^*\left(s'\right)} υ∗(s)=maxaRsa+γ∑s′∈SPss′aυ∗(s′)
q ∗ ( s , a ) = R s a + γ ∑ s ′ ∈ S P s s ′ a max a ′ q ∗ ( s ′ , a ′ ) q^*\left(s,a\right)=R_{s}^{a}+\gamma\sum_{s'\in S}{P_{ss'}^{a}\max_{a'}q^*\left(s',a'\right)} q∗(s,a)=Rsa+γ∑s′∈SPss′amaxa′q∗(s′,a′)
若已知最优状态-动作值函数,最优策略可通过直接最大化 q ∗ ( s , a ) q^*\left(s,a\right) q∗(s,a) 来决定。
π ∗ ( a ∣ s ) = { 1 if a = arg max a ∈ A q ∗ ( s , a ) 0 else \pi_{*}(a | s)=\left\{\begin{array}{ll}{1} & {\text { if } a=\arg \max _{a \in A} q_{*}(s, a)} \\ {0} & {\text { else }}\end{array}\right. π∗(a∣s)={10 if a=argmaxa∈Aq∗(s,a) else
数学推导
(1.1)
υ ( s ) = E [ G t ∣ S t = s ] = E [ R t + 1 + γ R t + 2 + ⋯ ∣ S t = s ] = E [ R t + 1 + γ ( R t + 2 + γ R t + 3 + ⋯ ) ∣ S t = s ] = E [ R t + 1 + γ G t + 1 ∣ S t = s ] = E [ R t + 1 + γ υ ( S t + 1 ) ∣ S t = s ] \upsilon\left(s\right)=E\left[G_t|S_t=s\right] \\ =E\left[R_{t+1}+\gamma R_{t+2}+\cdots |S_t=s\right] \\ =E\left[R_{t+1}+\gamma\left(R_{t+2}+\gamma R_{t+3}+\cdots\right)|S_t=s\right] \\ =E\left[R_{t+1}+\gamma G_{t+1}|S_t=s\right] \\ =E\left[R_{t+1}+\gamma\upsilon\left(S_{t+1}\right)|S_t=s\right] υ(s)=E[Gt∣St=s]=E[Rt+1+γRt+2+⋯∣St=s]=E[Rt+1+γ(Rt+2+γRt+3+⋯)∣St=s]=E[Rt+1+γGt+1∣St=s]=E[Rt+1+γυ(St+1)∣St=s]
参考文献
[1]https://zhuanlan.zhihu.com/p/25498081
[2]https://www.cnblogs.com/pinard/p/9426283.html