python3爬虫系列03之requests库:根据关键词自动爬取下载百度图片
python3爬虫系列03之requests库:根据关键词自动爬取下载百度图片
1.前言
在上一篇文章urllib使用:根据关键词自动爬取下载百度图片 当中,我们已经分析过了百度图片的搜索URL的变化,发现关键词就在搜索结果页的网址中。
我们只需要把网址中的关键词换掉,就是得到新的关键词的结果页网址。
上一篇文章我们采用了python的基础模块【urllib库】来做爬虫,正所谓长江后浪推前浪,Reuqests库把urllib库拍在沙滩上了,现在都不推荐使用它了,比它更好的网页下载器是requests库 。
requests基于urllib上进行了很多功能的封装,号称最好用的HTTP请求库。
所以今天开始requests库的学习,开始新的爬虫。
2.requests库介绍
一、安装requests库
因为它不是 python 的内置库,所以使用前需要安装一下。
直接使用 pip 安装:
pip install requests
二、请求方式
requests支持所有的HTTP请求,以最常用的get方法为例。
一行代码 Get 请求:
import requests
url = 'https://www.baidu.com'
response = requests.get(url)
- 只要把要访问的网址当作参数传递给requests.get方法,就可以获得所请求的网页。
- 请求成功后会返回一个Response对象,这个对象包含了服务器对请求的响应和对响应的一些操作。
一行代码 Post 请求:
response = requests.post('https://httpbin.org/post', data = {'key':'value'})
其它乱七八糟的 Http 请求暂时不说。
三、响应的操作
获取服务器响应内容,最常用 text属性和content属性。
补充一下:
使用response .encoding可看网页编码格式。
- response .text()
通过text属性可以查看响应【文本内容】:
#注:这里的response是前面代码块中的response,
print(response.text)
【text属性通常是网页的源代码】,也就是在浏览器里查看源码后看到的代码。如果请求的是一个js文件的话,text就是js文件的内容。总之,text属性是响应内容的文本形式。
- response.content()
当返回的响应是二进制的内容时(比如图片或视频),text属性通常不能正常使用,这时可以使用content属性来保存字节响应内容。
下面的代码请求了一张图片并保存到当前目录下:
img_url = 'https://www.cnblogs.com/skins/CodingLife/images/title-yellow.png'
r = requests.get(url)
with open('img.png', 'wb+') as f:
f.write(r.content)
- response.status_code()
status_code属性:获取响应码
status_code属性是响应的状态码,它表示了请求的状态,200表示请求成功,301和302表示请求重定向,具体描述请看下方表格。
图示:

注意:,很多情况下收到5**状态码并不是服务器发生了错误,而是服务器拒绝了请求,出现这种情况一般是因为服务器有反爬措施。
想了解更多关于http状态码的问题:状态码大全
其他:
- response.json()
获取 Json 响应内容。 - response.cookies[‘cookie_name’]
获取 cookie 信息 - requests.get(‘https://xx.com/’, timeout=10)
设置超时 - response .encoding()
网页编码格式.
除了牛逼
还能说什么呢??
设置请求头、如何发送带参数的请求、get请求和post请求的区别?
对于一般的网站来说请求头可以说是反爬的核心手段了,所以对于每个学习爬虫的人都有必要了解一下请求头。
1.get请求:
get提交内容:
url
params
headers
一段真实的请求头如下:
GET /sugrec?prod=pc_his&from=pc_web&json=1&sid=1460_21117_29568_29700_29220_28704&hisdata=&req=2&csor=0&cb=jQuery110205236274301352801_1572627552648&_=1572627552649 HTTP/1.1
Host: www.baidu.com
Connection: keep-alive
Accept: text/javascript, application/javascript, application/ecmascript, application/x-ecmascript, */*; q=0.01
X-Requested-With: XMLHttpRequest
User-Agent: Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36
Referer: https://www.baidu.com/
Accept-Encoding: gzip, deflate, br
Accept-Language: zh-CN,zh;q=0.9
Cookie: BAIDUID=0B5706DD2582Cxxx......
对于所有的请求头来说它们的第一行的格式都是相同的:
GET /sugrec?prod=pc_his&from=pc_web&json=1&sid=1460_21117_29568_29700_29220_28704&hisdata=&req=2&csor=0&cb=jQuery110205236274301352801_1572627552648&_=1572627552649 HTTP/1.1
请求方式 请求的网址 使用的HTTP协议版本
第二行到最后一行是请求头字段,其中需要了解的是Host、User-Agent、Referer和Cookie。
-
Host字段表示请求网站的主域名,也就是请求的网址中的www.jianshu.com部分,Referer表示请求发起页面的地址,一般的反爬机制就是通过识别Host和Rederer字段来进行反爬。
-
User-Agent是浏览器标识头,requests默认不设置这个字段,而且大部分的请求库或者爬虫框架这个字段都是很有特点的(这里的有特点指的是和浏览器的差别很大),许多的网站根据这个字段来对爬虫做初步的判断。
-
也有少量的网站是通过 IP来鉴别爬虫的,同一个 IP访问频率过快就会遭到封禁,这时还想继续爬就得用代理。
-
不过一般的服务器还是通过headers来区别爬虫与人的,所以我们只要伪造一个headers就能以假乱真,这样我们又可爬了。
伪造headers?
有一个简单粗暴的方法就是直接用chrome的开发者模式把网站的请求头复制下来,不过对付一般的网站我们只需要user-agent就行(有些甚至不需要 headers)。
伪造好 headers后,headers传递给 get方法的 headers参数就可以用伪造的 headers来访问网站了
#简单粗暴的方法
headers = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
'Accept-Encoding': 'gzip, deflate',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Cache-Control': 'max-age=0',
'Content-Type': 'application/x-www-form-urlencoded',
'Host': 'www.baidu.com',
'Proxy-Connection': 'keep-alive',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.117 Safari/537.36',
}
#一般的方法
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.117 Safari/537.36',
}
r = requests.get(url, headers=headers)
2.post请求
post提交内容:
url
params
headers
data
如果碰到要登录或者需要提交表单的网页就束手无策了,遇到这种情况 post 方法就排上用场了。
post 方法的使用和 get 方法一样,也可以传入 headers 参数。
唯一不同的就是 post 方法用 data 来接收要提交的表单数据,data 要求是字典格式 data 的键对应 html 中表单的 name,
举例如下:
<html>
<head>
<title>注册title>
<meta charset="utf-8">
head>
<body>
<form action="#" method="post">
<div class="row">
<span class="col s4">username:span><input type="text" name="username">
div>
<div class="row">
<span class="col s4">password:span><input type="password" name="password">
div>
<div class="row">
<button class="col s4 center" type="submit">提交button>
div>
form>
body>
html>
对应的请求代码:
#这个网页可以返回 post方法提交的表单数据
url = 'http://203.195.204.124/post'
#构造 data 字典 username 、password 分别和上方网页中的 username 和 password 对应
data = {
'username': 'geebos',
'password': '123456',
}
r = requests.post(url, data=data)
#也可以传入 headers 参数
r = requests.post(url, data=data, headers=headers)
print(r.text)
'''返回的内容(r.text):{"username": "geebos", "password": "123456"}''
当然,真正的 post 请求比这个例子要复杂一些,至少密码是经过加密再进行传输的。
还有请求方式一共分为六种,其中最常用的是GET和POST请求,对于爬虫来说了解了这两种请求也就足够了。
3.实战环节
了解完这些,我们开始实战爬虫。
基于上一篇的代码和分析,我们直接在原代码上修改,在网页下载器的地方,将原来的urllib改为requests库即可。
源代码:
#!/usr/bin/python3
import re
import requests
def dowmloadPic(html,keyword):
pic_url = re.findall('"objURL":"(.*?)",',html,re.S) #re.S将字符串作为整体,在整体中进行匹配。
i = 0
print ('找到关键词:'+keyword+'的图片,现在开始下载图片...')
for each in pic_url:
print ('正在下载第'+str(i+1)+'张图片,图片地址:'+str(each))
try:
pic= requests.get(each, timeout=10) # 10秒超时控制
except requests.exceptions.ConnectionError:
print ('【错误】当前图片无法下载')
continue
string = 'pic/02/'+keyword+'_'+str(i) + '.jpg'
fp = open(string,'wb')
fp.write(pic.content) # 二进制数据用content
fp.close()
i += 1
if __name__ == '__main__':
word = input("关键词: ")
url = 'http://image.baidu.com/search/flip?tn=baiduimage&ie=utf-8&word='+word+'&ct=201326592&v=flip'
result = requests.get(url)
dowmloadPic(result.text,word) # 源码存在text里面
open函数:
这里的 open( filename, mode ) 是 python的内置函数,用于打开一个文件,接受两个参数 filename和 mode,返回 一个 file对象。
以wb, ab, wb+, ab+, rb+模式打开的 file对象的 write方法能接收二进制数据作为参数,所以我们可以通过 write方法将二进制数据写入到 file对象对应的文件中去。
其中 filename是要打开的文件的名称,mode是打开文件的方式,mode的取值有如下几种:

效果:
这里我输入了“猫”,如下图。结果针对让人振奋,自动下载了很多张关于猫的图。
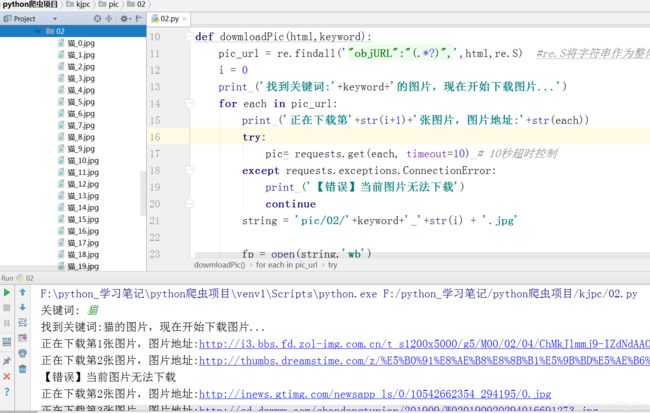
图示:
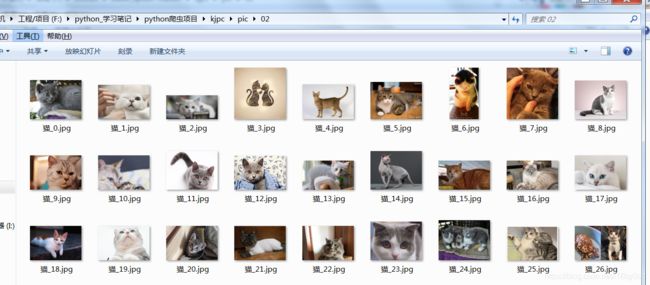
这样就完成了基于requests实现:根据关键词自动爬取下载百度图片。
为什么选取都是同一个网站来爬虫?是为了让大家更好的对比同一对应可以采用不同的方式,而不是对象不同采用不同的方式。
下一篇以爬虫简单架构的方式来修改代码,继续爬虫。
参考地址: https://www.jianshu.com/p/60f7b65026fe