强化学习 之 Policy Gradient
参考
1、关于Policy Gradient的理解(对于PG的理解比较完整和全面)
2、【强化学习】Policy Gradient算法详解(详细的推导过程)
3、Policy Gradient算法推导(包含详细的计算过程)
4、策略梯度 Policy Gradient(除推导外,还有其他一些计算知识,包含Actor Critic部分)
5.PARL源码走读——使用策略梯度算法求解迷宫寻宝问题(提及连续的分布输出)
简介
强化学习是一个通过奖惩来学习正确行为的机制。
其中,Q learning、Sarsa、Deep Q Network等通过学习奖惩值, 根据自己认为的高价值选行为;
Policy Gradients则不通过分析奖励值,直接输出行为,即接受环境信息 (observation)后,他要输出不是 action 的 value,而是具体的那一个 action,这样 policy gradient 就跳过了 value 这个阶段。
对比起以值为基础的方法,Policy Gradients 直接输出动作的最大好处是 能在一个连续区间内挑选动作,而基于值的, 比如 Q-learning, 它如果在无穷多的动作中计算价值, 从而选择行为, 这它可吃不消。
反向传递与更新参数
Policy Gradient中,反向传递的目的是 让这次被选中的行为更有可能在下次发生 而在提升该行为下次被选中概率的过程中,由奖惩 reward 来控制变化幅度的大小
举个例子
观测的信息通过神经网络分析, 选出了左边的行为,我们直接进行反向传递,使之下次被选的可能性增加。但是奖惩信息却告诉我们,这次的行为是不好的,那我们的动作可能性增加的幅度 随之被减低(即可能性增加的小一些)。
又比如这次的观测信息让神经网络选择了右边的行为,右边的行为随之想要进行反向传递,使右边的行为下次被多选一点。这时奖惩信息也来了,告诉我们这是好行为,那我们就在这次反向传递的时候加大力度(即可能性增加的多一些)。
这样就能靠奖励来左右我们的神经网络反向传递。
算法思想
此处介绍的是 一种基于 整条回合数据 的更新, 也叫 REINFORCE 方法,是policy gradients的基础算法,描述如下:
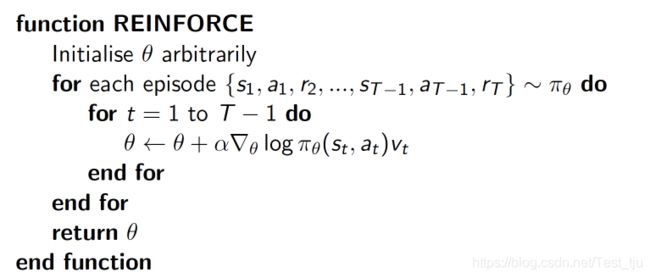
核心思想:
delta( log(Policy(s,a)) * V ) 表示在 状态 s 对所选动作 a 的吃惊度,
所以如果 Policy(s,a)的概率越小,则反向的 log(Policy(s,a)) (即 - log P) 反而越大。
如果在 Policy(s,a) 很小的情况下拿到了一个 大的 R,也就是 大的 V,则:
-delta( log(Policy(s,a)) * V ) 就更大,表示更吃惊
(吃惊可以理解为:我选了一个不常选的动作,却发现原来它能得到了一个好的 reward,那我就得对我这次的参数进行一个大幅修改)
原理分析
此部分参考了第三篇文章。




神经网络分析
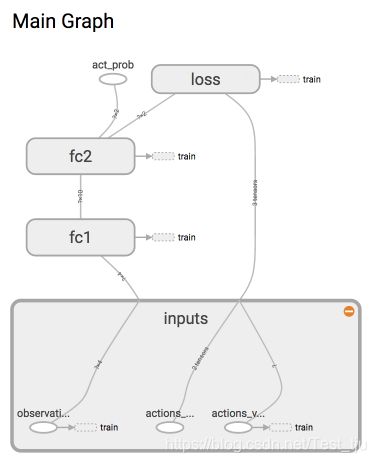
这是强化学习,所以神经网络中并没有我们熟知的监督学习中的 y label。取而代之的是我们选的 action。网络结构如下:
1. 参数初始化
def __init__(
self,
n_actions,
n_features,
learning_rate=0.01,
reward_decay=0.95,
output_graph=False,
):
self.n_actions = n_actions
self.n_features = n_features
self.lr = learning_rate
self.gamma = reward_decay
self.ep_obs, self.ep_as, self.ep_rs = [], [], [] # 存储回合信息
self._build_net() # 建立神经网络
self.sess = tf.Session()
if output_graph:
tf.summary.FileWriter("logs/", self.sess.graph)
self.sess.run(tf.global_variables_initializer())
2. 各层网络
def _build_net(self):
with tf.name_scope('inputs'):
# 接收 observation,即state
self.tf_obs = tf.placeholder(tf.float32, [None, self.n_features], name="observations")
# 接收 我们在这个回合中选过的 actions
self.tf_acts = tf.placeholder(tf.int32, [None, ], name="actions_num")
# 接收 每个 state-action 所对应的 value (通过 reward 计算)
self.tf_vt = tf.placeholder(tf.float32, [None, ], name="actions_value")
# fc1 全连接层1
layer = tf.layers.dense(
inputs=self.tf_obs,
units=10, # 输出个数
activation=tf.nn.tanh, # 激活函数
kernel_initializer=tf.random_normal_initializer(mean=0, stddev=0.3),
bias_initializer=tf.constant_initializer(0.1),
name='fc1'
)
# fc2 全连接层2
all_act = tf.layers.dense(
inputs=layer,
units=self.n_actions, # 输出个数
activation=None, # 之后再加 Softmax
kernel_initializer=tf.random_normal_initializer(mean=0, stddev=0.3),
bias_initializer=tf.constant_initializer(0.1),
name='fc2'
)
3. 误差、训练
softmax函数:把一些输入映射为0-1之间的实数,并且归一化保证和为1,因此多分类的概率之和也刚好为1,计算过程大致如下图:
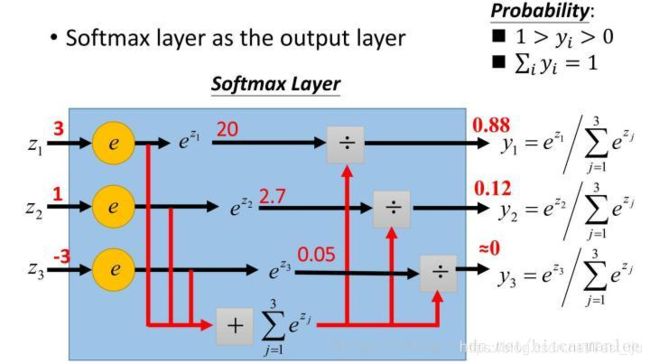
详细参考:小白都能看懂的softmax详解
# 把输出的每一个 action 的值,转换成概率 probability
self.all_act_prob = tf.nn.softmax(all_act, name='act_prob')
with tf.name_scope('loss'):
# 最大化总体reward(log_p * R) 就是在最小化 -(log_p * R), 而 tf 的功能里只有最小化 loss
# 所以,计算所选 action 的概率 -log 值
# all_act是神经网络判断后做出的行动,shape为[batch_size,num_classes]
# self.tf_acts是实际采取的行动,shape是长度等于batch_size的一维向量
# neg_log_prob = tf.nn.sparse_softmax_cross_entropy_with_logits(logits=all_act, labels=self.tf_acts)
# 下面的方式是一样的:
# 对采取的action使用独热码的形式存储,便于乘法运算
neg_log_prob = tf.reduce_sum(-tf.log(self.all_act_prob)*tf.one_hot(self.tf_acts, self.n_actions), axis=1)
# (vt = 本reward + 衰减的未来reward),引导参数的梯度下降
loss = tf.reduce_mean(neg_log_prob * self.tf_vt)
with tf.name_scope('train'):
self.train_op = tf.train.AdamOptimizer(self.lr).minimize(loss)
计算loss的部分对应,“所以如果 Policy(s,a)的概率越小,则反向的 log(Policy(s,a)) (即 - log P) 反而越大”,其中,neg_log_prob 即为 反向的 log(Policy(s,a)) 。
也可以将 neg_log_prob 理解成 cross-entropy 的分类误差,计算方法:

其中 y’i 为label中的第i个值,yi 为经softmax归一化输出的vector中的对应分量。由此可以看出,当分类越准确时,yi 所对应的分量就会越接近于1,从而 H 的值也就会越小。
cross-entropy详细参考:tf.nn.sparse_softmax_cross_entropy_with_logits 解析
4. 关于v
每步t的v由reward计算得到,即v[t]新 = v[t]旧 * γ + reward[t]
def _discount_and_norm_rewards(self):
# 实现对未来 reward 的衰减
# np.zeros_like(array): 生成一个和给定数组araay相同shape的全0数组
discounted_ep_rs = np.zeros_like(self.ep_rs)
running_add = 0
# 计算vt
for t in reversed(range(0, len(self.ep_rs))):
running_add = running_add * self.gamma + self.ep_rs[t]
discounted_ep_rs[t] = running_add
# 标准化回合的 reward
discounted_ep_rs -= np.mean(discounted_ep_rs)
discounted_ep_rs /= np.std(discounted_ep_rs)
return discounted_ep_rs
5. 在学习过程中传入vt的值
def learn(self):
# 衰减, 并标准化这回合的 reward
discounted_ep_rs_norm = self._discount_and_norm_rewards()
# train on episode
self.sess.run(self.train_op, feed_dict={
self.tf_obs: np.vstack(self.ep_obs), # shape=[None, n_obs]
self.tf_acts: np.array(self.ep_as), # shape=[None, ]
# 传入vt
self.tf_vt: discounted_ep_rs_norm, # shape=[None, ]
})
self.ep_obs, self.ep_as, self.ep_rs = [], [], [] # 学习完当前回合后,清空回合 data
return discounted_ep_rs_norm
6. 随机选择行为action
def choose_action(self, observation):
# 所有 action 的概率
prob_weights = self.sess.run(self.all_act_prob, feed_dict={self.tf_obs: observation[np.newaxis, :]})
# 根据概率来选 action
action = np.random.choice(range(prob_weights.shape[1]), p=prob_weights.ravel())
return action
7. 存储回合中每一步的记忆
def store_transition(self, s, a, r):
self.ep_obs.append(s)
self.ep_as.append(a)
self.ep_rs.append(r)