深度强化学习实战-Tensorflow实现DDPG
前言
这是开栏以来的第一篇文章,都说万事开头难,希望开了这个头之后,专栏里能越来越多关于深度强化学习算法代码实现的文章。
正文开始之前,先自我介绍一下,本人刚刚踏入研三,是通信与信息系统专业的学生,实验室是做卫星导航的。但由于自己对深度学习感兴趣,打算读这方向的PhD,所以自学了深度学习,强化学习,目前主要关注自动驾驶领域的研究。因为都是自己在自学,没有人指导期间也遇到了很多困难,相信很多人也和我一样在自己琢磨的时候遇到很多难题,所以希望能通过这个专栏和大家一起学习交流,共同进步。
Github代码 https://github.com/lightaime/TensorAgent
正文
这次是讲解DeepMind发布在ICLR 2016的文章CONTINUOUS CONTROL WITH DEEP REINFORCEMENT LEARNING,时间稍微有点久远,但因为算法经典,还是值得去实现。
环境
这次实验环境是Openai Gym的 Pendulum-v0,state是3维连续的表示杆的位置方向信息,action是1维的连续动作,大小是-2.0到2.0,表示对杆施加的力和方向。目标是让杆保持直立,所以reward在杆保持直立不动的时候最大。笔者所用的环境为:
- tensorflow (1.2.1)
- gym (0.9.2)
请先安装tensorflow和gym,tensorflow和gym的安装就不赘述了,下面是网络收敛后的结果。
代码详解
先贴一张DeepMind文章中的伪代码,分析一下实现它,我们需要实现哪些东西:

网络结构(model)
首先,我们需要实现一个critic network和一个actor network,然后再实现一个target critic network和target actor network,并且对应初始化为相同的weights。下面来看看这部分代码怎么实现:
critic network & target critic network
def __create_critic_network(self):
h1 = tf.layers.dense(self.input_state,
units=self.h1_dim,
activation=self.activation,
kernel_initializer=self.kernel_initializer_1,
kernel_regularizer=self.kernel_regularizer,
name="hidden_1")
h2 = tf.layers.dense(self.input_action,
units=self.h2_dim,
activation=self.activation,
kernel_initializer=self.kernel_initializer_2,
kernel_regularizer=self.kernel_regularizer,
name="hidden_2")
h_concat = tf.concat([h1, h2], 1, name="h_concat")
h3 = tf.layers.dense(h_concat,
units=self.h3_dim,
activation=self.activation,
kernel_initializer=self.kernel_initializer_3,
kernel_regularizer=self.kernel_regularizer,
name="hidden_3")
q_output = tf.layers.dense(h3,
units=1,
activation = None,
kernel_initializer=self.kernel_initializer_4,
kernel_regularizer=self.kernel_regularizer,
name="q_output")
return q_output
上面是critic network的实现,critic network 是一个用神经网络去近似的一个函数,输入是s-state,a-action,输出是Q函数,网络参数是 ,在这里我的实现和原文类似,state经过一个全连接层得到隐藏层特征h1,action经过另外一个全连接层得到隐藏层特征h2,然后特征串联在一起得到h_concat,之后h_concat再经过一层全连接层得到h3,最后h3经过一个没有激活函数的全连接层得到q_output。这就简单得实现了一个critic network。
def __create_target_network(self):
# get source variales and initialize
source_vars = tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES, scope=self.source_var_scope)
self.sess.run(tf.variables_initializer(source_vars))
# create target network and initialize it by source network
q_output = self.__create_critic_network()
target_vars = tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES, scope=self.target_var_scope)
target_init_op_list = [target_vars[i].assign(source_vars[i]) for i in range(len(source_vars))]
self.sess.run(target_init_op_list)
return q_output
上面是target critic network的实现,target critic network 网络结构和critic network一样,也参数初始化为一样的权重,思路是先把critic network的权重取出来初始化,再调用一遍self.__create_critic_network()创建target network,最后把critic network初始化的权重赋值给target critic network。
这样我们就得到了critic network和critic target network。
actor network & actor target network
actor network 和 actor target network 的实现和critic几乎一样,区别在于网络结构和激活函数。
def __create_actor_network(self):
h1 = tf.layers.dense(self.input_state,
units=self.h1_dim,
activation=self.activation,
kernel_initializer=self.kernel_initializer_1,
kernel_regularizer=self.kernel_regularizer,
name="hidden_1")
h2 = tf.layers.dense(h1,
units=self.h2_dim,
activation=self.activation,
kernel_initializer=self.kernel_initializer_2,
kernel_regularizer=self.kernel_regularizer,
name="hidden_2")
action_output = tf.layers.dense(h2,
units=self.action_dim,
activation=tf.nn.tanh,
# activation=tf.nn.tanh,
kernel_initializer=self.kernel_initializer_3,
kernel_regularizer=self.kernel_regularizer,
use_bias=False,
name="action_outputs")
return action_output
def __create_target_network(self):
# get source variales and initialize
source_vars = tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES, scope=self.source_var_scope)
self.sess.run(tf.variables_initializer(source_vars))
# create target network and initialize it by source network
action_output = self.__create_actor_network()
target_vars = tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES, scope=self.target_var_scope)
target_init_op_list = [target_vars[i].assign(source_vars[i]) for i in range(len(source_vars))]
self.sess.run(target_init_op_list)
return action_output
这里用了3层全连接层,最后激活函数是tanh,把输出限定在-1到1之间。这样大体的网络结构就实现完了。
Replay Buffer & Random Process(Mechanism)
接下来,伪代码提到replay buffer和random process,这部分代码比较简单也很短,主要参考了openai 的rllab的实现,大家可以直接看看源码。
网络更新和损失函数(Model)
用梯度下降更新网络,先需要定义我们的loss函数。
critic nework更新
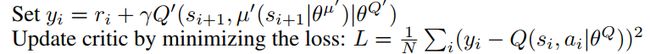
def __create_loss(self):
self.loss = tf.losses.mean_squared_error(self.y, self.q_output)
def __create_train_op(self):
self.train_q_op = self.optimizer.minimize(self.loss)
train_op_vars = tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES, scope= self.scope + "/" + self.train_op_scope) # to do: remove prefix
train_op_vars.extend(tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES, scope=self.train_op_scope))
self.sess.run(tf.variables_initializer(train_op_vars))
这里critic只是很简单的是一个L2 loss。不过由于transition是s, a, r, s'。要得到y需要一步处理,下面是预处理transition的代码。
def get_transition_batch(self):
batch = self.replay_buffer.get_batch()
transpose_batch = list(zip(*batch))
s_batch = np.vstack(transpose_batch[0])
a_batch = np.vstack(transpose_batch[1])
r_batch = np.vstack(transpose_batch[2])
next_s_batch = np.vstack(transpose_batch[3])
done_batch = np.vstack(transpose_batch[4])
return s_batch, a_batch, r_batch, next_s_batch, done_batch
def preprocess_batch(self, s_batch, a_batch, r_batch, next_s_batch, done_batch):
target_actor_net_pred_action = self.model.actor.predict_action_target_net(next_s_batch)
target_critic_net_pred_q = self.model.critic.predict_q_target_net(next_s_batch, target_actor_net_pred_action)
y_batch = r_batch + self.discout_factor * target_critic_net_pred_q * (1 - done_batch)
return s_batch, a_batch, y_batch
def train_model(self):
s_batch, a_batch, r_batch, next_s_batch, done_batch = self.get_transition_batch()
self.model.update(*self.preprocess_batch(s_batch, a_batch, r_batch, next_s_batch, done_batch))
训练模型是,从Replay buffer里取出一个mini-batch,在经过预处理就可以更新我们的网络了,是不是很简单。y经过下面这行代码处理得到。
y_batch = r_batch + self.discout_factor * target_critic_net_pred_q * (1 - done_batch)
actor nework更新

actor network的更新也很简单,我们需要求的梯度如上图,首先我们需要critic network 对动作a的导数,其中a是由actor network根据状态s估计出来的。代码如下:
action_batch_for_grad = self.actor.predict_action_source_net(state_batch, sess)
action_grad_batch = self.critic.get_action_grads(state_batch, action_batch_for_grad, sess)
def __create_get_action_grad_op(self):
self.get_action_grad_op = tf.gradients(self.q_output, self.input_action)
先根据actor network估计出action,在用critic network的输出q对估计出来的action求导。
然后我们把得到的这部分梯度,和actor network的输出对actor network的权重求导的梯度,相乘就能得到最后的梯度,代码如下:
def __create_loss(self):
source_vars = tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES, scope=self.source_var_scope)
self.policy_gradient = tf.gradients(self.action_output, source_vars, -self.actions_grad)
self.grads_and_vars = zip(self.policy_gradient, source_vars)
def __create_train_op(self):
self.train_policy_op = self.optimizer.apply_gradients(self.grads_and_vars, global_step=tf.contrib.framework.get_global_step())
train_op_vars = tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES, scope= self.scope + "/" + self.train_op_scope) # to do: remove prefix
train_op_vars.extend(tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES, scope=self.train_op_scope))
self.sess.run(tf.variables_initializer(train_op_vars))
也就是说我们需要求的policy gradient主要由下面这一行代码求得,由于我们需要梯度下降去更新网络,所以需要加个负号:
self.policy_gradient = tf.gradients(self.action_output, source_vars, -self.actions_grad)
之后就是更新我们的target network,target network采用soft update的方式去稳定网络的变化,算法如下:
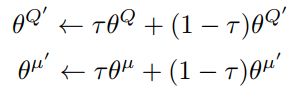
def __create_update_target_net_op(self):
source_vars = tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES, scope=self.source_var_scope)
target_vars = tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES, scope=self.target_var_scope)
update_target_net_op_list = [target_vars[i].assign(self.tau*source_vars[i] + (1-self.tau)*target_vars[i]) for i in range(len(source_vars))]
self.update_target_net_op = tf.group(*update_target_net_op_list)
就这样我们的整体网络更新需要的东西都实现了,下面是整体网络更新的代码:
def update(self, state_batch, action_batch, y_batch, sess=None):
sess = sess or self.sess
self.critic.update_source_critic_net(state_batch, action_batch, y_batch, sess)
action_batch_for_grad = self.actor.predict_action_source_net(state_batch, sess)
action_grad_batch = self.critic.get_action_grads(state_batch, action_batch_for_grad, sess)
self.actor.update_source_actor_net(state_batch, action_grad_batch, sess)
self.critic.update_target_critic_net(sess)
self.actor.update_target_actor_net(sess)
全部代码
总体的细节都介绍完了,希望大家有所收获,下面贴出全部代码,大家也可以直接访问我的Github:
https://github.com/lightaime/TensorAgent
model/ddpg_model.py
import tensorflow as tf
from ddpg_actor import DDPG_Actor
from ddpg_critic import DDPG_Critic
class Model(object):
def __init__(self,
state_dim,
action_dim,
optimizer=None,
actor_learning_rate=1e-4,
critic_learning_rate=1e-3,
tau = 0.001,
sess=None):
self.state_dim = state_dim
self.action_dim = action_dim
self.actor_learning_rate = actor_learning_rate
self.critic_learning_rate = critic_learning_rate
self.tau = tau
tf.reset_default_graph()
self.sess = sess or tf.Session()
self.global_step = tf.Variable(0, name="global_step", trainable=False)
global_step_vars = tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES, scope="global_step")
self.sess.run(tf.variables_initializer(global_step_vars))
self.actor_scope = "actor_net"
with tf.name_scope(self.actor_scope):
self.actor = DDPG_Actor(self.state_dim,
self.action_dim,
learning_rate=self.actor_learning_rate,
tau=self.tau,
scope=self.actor_scope,
sess=self.sess)
self.critic_scope = "critic_net"
with tf.name_scope(self.critic_scope):
self.critic = DDPG_Critic(self.state_dim,
self.action_dim,
learning_rate=self.critic_learning_rate,
tau=self.tau,
scope=self.critic_scope,
sess=self.sess)
def update(self, state_batch, action_batch, y_batch, sess=None):
sess = sess or self.sess
self.critic.update_source_critic_net(state_batch, action_batch, y_batch, sess)
action_batch_for_grad = self.actor.predict_action_source_net(state_batch, sess)
action_grad_batch = self.critic.get_action_grads(state_batch, action_batch_for_grad, sess)
self.actor.update_source_actor_net(state_batch, action_grad_batch, sess)
self.critic.update_target_critic_net(sess)
self.actor.update_target_actor_net(sess)
def predict_action(self, observation, sess=None):
sess = sess or self.sess
return self.actor.predict_action_source_net(observation, sess)
model/ddpg_actor.py
import tensorflow as tf
from math import sqrt
class DDPG_Actor(object):
def __init__(self, state_dim, action_dim, optimizer=None, learning_rate=0.001, tau=0.001, scope="", sess=None):
self.scope = scope
self.sess = sess
self.state_dim = state_dim
self.action_dim = action_dim
self.learning_rate = learning_rate
self.l2_reg = 0.01
self.optimizer = optimizer or tf.train.AdamOptimizer(self.learning_rate)
self.tau = tau
self.h1_dim = 400
self.h2_dim = 300
# self.h3_dim = 200
self.activation = tf.nn.relu
self.kernel_initializer = tf.contrib.layers.variance_scaling_initializer()
# fan-out uniform initializer which is different from original paper
self.kernel_initializer_1 = tf.random_uniform_initializer(minval=-1/sqrt(self.h1_dim), maxval=1/sqrt(self.h1_dim))
self.kernel_initializer_2 = tf.random_uniform_initializer(minval=-1/sqrt(self.h2_dim), maxval=1/sqrt(self.h2_dim))
self.kernel_initializer_3 = tf.random_uniform_initializer(minval=-3e-3, maxval=3e-3)
self.kernel_regularizer = tf.contrib.layers.l2_regularizer(self.l2_reg)
with tf.name_scope("actor_input"):
self.input_state = tf.placeholder(tf.float32, shape=[None, self.state_dim], name="states")
with tf.name_scope("actor_label"):
self.actions_grad = tf.placeholder(tf.float32, shape=[None, self.action_dim], name="actions_grad")
self.source_var_scope = "actor_net"
with tf.variable_scope(self.source_var_scope):
self.action_output = self.__create_actor_network()
self.target_var_scope = "actor_target_net"
with tf.variable_scope(self.target_var_scope):
self.target_net_actions_output = self.__create_target_network()
with tf.name_scope("compute_policy_gradients"):
self.__create_loss()
self.train_op_scope = "actor_train_op"
with tf.variable_scope(self.train_op_scope):
self.__create_train_op()
with tf.name_scope("actor_target_update_train_op"):
self.__create_update_target_net_op()
self.__create_get_layer_weight_op_source()
self.__create_get_layer_weight_op_target()
def __create_actor_network(self):
h1 = tf.layers.dense(self.input_state,
units=self.h1_dim,
activation=self.activation,
kernel_initializer=self.kernel_initializer_1,
# kernel_initializer=self.kernel_initializer,
kernel_regularizer=self.kernel_regularizer,
name="hidden_1")
h2 = tf.layers.dense(h1,
units=self.h2_dim,
activation=self.activation,
kernel_initializer=self.kernel_initializer_2,
# kernel_initializer=self.kernel_initializer,
kernel_regularizer=self.kernel_regularizer,
name="hidden_2")
# h3 = tf.layers.dense(h2,
# units=self.h3_dim,
# activation=self.activation,
# kernel_initializer=self.kernel_initializer,
# kernel_regularizer=self.kernel_regularizer,
# name="hidden_3")
action_output = tf.layers.dense(h2,
units=self.action_dim,
activation=tf.nn.tanh,
# activation=tf.nn.tanh,
kernel_initializer=self.kernel_initializer_3,
# kernel_initializer=self.kernel_initializer,
kernel_regularizer=self.kernel_regularizer,
use_bias=False,
name="action_outputs")
return action_output
def __create_target_network(self):
# get source variales and initialize
source_vars = tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES, scope=self.source_var_scope)
self.sess.run(tf.variables_initializer(source_vars))
# create target network and initialize it by source network
action_output = self.__create_actor_network()
target_vars = tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES, scope=self.target_var_scope)
target_init_op_list = [target_vars[i].assign(source_vars[i]) for i in range(len(source_vars))]
self.sess.run(target_init_op_list)
return action_output
def __create_loss(self):
source_vars = tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES, scope=self.source_var_scope)
self.policy_gradient = tf.gradients(self.action_output, source_vars, -self.actions_grad)
self.grads_and_vars = zip(self.policy_gradient, source_vars)
def __create_train_op(self):
self.train_policy_op = self.optimizer.apply_gradients(self.grads_and_vars, global_step=tf.contrib.framework.get_global_step())
train_op_vars = tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES, scope= self.scope + "/" + self.train_op_scope) # to do: remove prefix
train_op_vars.extend(tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES, scope=self.train_op_scope))
self.sess.run(tf.variables_initializer(train_op_vars))
def __create_update_target_net_op(self):
source_vars = tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES, scope=self.source_var_scope)
target_vars = tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES, scope=self.target_var_scope)
update_target_net_op_list = [target_vars[i].assign(self.tau*source_vars[i] + (1-self.tau)*target_vars[i]) for i in range(len(source_vars))]
# source_net_dict = {var.name[len(self.source_var_scope):]: var for var in source_vars}
# target_net_dict = {var.name[len(self.target_var_scope):]: var for var in target_vars}
# keys = source_net_dict.keys()
# update_target_net_op_list = [target_net_dict[key].assign((1-self.tau)*target_net_dict[key]+self.tau*source_net_dict[key]) \
# for key in keys]
# for s_v, t_v in zip(source_vars, target_vars):
# update_target_net_op_list.append(t_v.assign(self.tau*s_v - (1-self.tau)*t_v))
self.update_target_net_op = tf.group(*update_target_net_op_list)
def predict_action_source_net(self, feed_state, sess=None):
sess = sess or self.sess
return sess.run(self.action_output, {self.input_state: feed_state})
def predict_action_target_net(self, feed_state, sess=None):
sess = sess or self.sess
return sess.run(self.target_net_actions_output, {self.input_state: feed_state})
def update_source_actor_net(self, feed_state, actions_grad, sess=None):
sess = sess or self.sess
batch_size = len(actions_grad)
return sess.run([self. train_policy_op],
{self.input_state: feed_state,
self.actions_grad: actions_grad/batch_size})
def update_target_actor_net(self, sess=None):
sess = sess or self.sess
return sess.run(self.update_target_net_op)
model/ddpg_critic.py
import tensorflow as tf
from math import sqrt
class DDPG_Critic(object):
def __init__(self, state_dim, action_dim, optimizer=None, learning_rate=0.001, tau=0.001, scope="", sess=None):
self.scope = scope
self.sess = sess
self.state_dim = state_dim
self.action_dim = action_dim
self.learning_rate = learning_rate
self.l2_reg = 0.01
self.optimizer = optimizer or tf.train.AdamOptimizer(self.learning_rate)
self.tau = tau
self.h1_dim = 400
self.h2_dim = 100
self.h3_dim = 300
self.activation = tf.nn.relu
self.kernel_initializer = tf.contrib.layers.variance_scaling_initializer()
# fan-out uniform initializer which is different from original paper
self.kernel_initializer_1 = tf.random_uniform_initializer(minval=-1/sqrt(self.h1_dim), maxval=1/sqrt(self.h1_dim))
self.kernel_initializer_2 = tf.random_uniform_initializer(minval=-1/sqrt(self.h2_dim), maxval=1/sqrt(self.h2_dim))
self.kernel_initializer_3 = tf.random_uniform_initializer(minval=-1/sqrt(self.h3_dim), maxval=1/sqrt(self.h3_dim))
self.kernel_initializer_4 = tf.random_uniform_initializer(minval=-3e-3, maxval=3e-3)
self.kernel_regularizer = tf.contrib.layers.l2_regularizer(self.l2_reg)
with tf.name_scope("critic_input"):
self.input_state = tf.placeholder(tf.float32, shape=[None, self.state_dim], name="states")
self.input_action = tf.placeholder(tf.float32, shape=[None, self.action_dim], name="actions")
with tf.name_scope("critic_label"):
self.y = tf.placeholder(tf.float32, shape=[None, 1], name="y")
self.source_var_scope = "critic_net"
with tf.variable_scope(self.source_var_scope):
self.q_output = self.__create_critic_network()
self.target_var_scope = "critic_target_net"
with tf.variable_scope(self.target_var_scope):
self.target_net_q_output = self.__create_target_network()
with tf.name_scope("compute_critic_loss"):
self.__create_loss()
self.train_op_scope = "critic_train_op"
with tf.variable_scope(self.train_op_scope):
self.__create_train_op()
with tf.name_scope("critic_target_update_train_op"):
self.__create_update_target_net_op()
with tf.name_scope("get_action_grad_op"):
self.__create_get_action_grad_op()
self.__create_get_layer_weight_op_source()
self.__create_get_layer_weight_op_target()
def __create_critic_network(self):
h1 = tf.layers.dense(self.input_state,
units=self.h1_dim,
activation=self.activation,
kernel_initializer=self.kernel_initializer_1,
# kernel_initializer=self.kernel_initializer,
kernel_regularizer=self.kernel_regularizer,
name="hidden_1")
# h1_with_action = tf.concat([h1, self.input_action], 1, name="hidden_1_with_action")
h2 = tf.layers.dense(self.input_action,
units=self.h2_dim,
activation=self.activation,
kernel_initializer=self.kernel_initializer_2,
# kernel_initializer=self.kernel_initializer,
kernel_regularizer=self.kernel_regularizer,
name="hidden_2")
h_concat = tf.concat([h1, h2], 1, name="h_concat")
h3 = tf.layers.dense(h_concat,
units=self.h3_dim,
activation=self.activation,
kernel_initializer=self.kernel_initializer_3,
# kernel_initializer=self.kernel_initializer,
kernel_regularizer=self.kernel_regularizer,
name="hidden_3")
# h2_with_action = tf.concat([h2, self.input_action], 1, name="hidden_3_with_action")
q_output = tf.layers.dense(h3,
units=1,
# activation=tf.nn.sigmoid,
activation = None,
kernel_initializer=self.kernel_initializer_4,
# kernel_initializer=self.kernel_initializer,
kernel_regularizer=self.kernel_regularizer,
name="q_output")
return q_output
def __create_target_network(self):
# get source variales and initialize
source_vars = tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES, scope=self.source_var_scope)
self.sess.run(tf.variables_initializer(source_vars))
# create target network and initialize it by source network
q_output = self.__create_critic_network()
target_vars = tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES, scope=self.target_var_scope)
target_init_op_list = [target_vars[i].assign(source_vars[i]) for i in range(len(source_vars))]
self.sess.run(target_init_op_list)
return q_output
def __create_loss(self):
self.loss = tf.losses.mean_squared_error(self.y, self.q_output)
def __create_train_op(self):
self.train_q_op = self.optimizer.minimize(self.loss)
train_op_vars = tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES, scope= self.scope + "/" + self.train_op_scope) # to do: remove prefix
train_op_vars.extend(tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES, scope=self.train_op_scope))
self.sess.run(tf.variables_initializer(train_op_vars))
def __create_update_target_net_op(self):
source_vars = tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES, scope=self.source_var_scope)
target_vars = tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES, scope=self.target_var_scope)
update_target_net_op_list = [target_vars[i].assign(self.tau*source_vars[i] + (1-self.tau)*target_vars[i]) for i in range(len(source_vars))]
# source_net_dict = {var.name[len(self.source_var_scope):]: var for var in source_vars}
# target_net_dict = {var.name[len(self.target_var_scope):]: var for var in target_vars}
# keys = source_net_dict.keys()
# update_target_net_op_list = [target_net_dict[key].assign((1-self.tau)*target_net_dict[key]+self.tau*source_net_dict[key]) \
# for key in keys]
# for s_v, t_v in zip(source_vars, target_vars):
# update_target_net_op_list.append(t_v.assign(self.tau*s_v - (1-self.tau)*t_v))
self.update_target_net_op = tf.group(*update_target_net_op_list)
def __create_get_action_grad_op(self):
self.get_action_grad_op = tf.gradients(self.q_output, self.input_action)
def predict_q_source_net(self, feed_state, feed_action, sess=None):
sess = sess or self.sess
return sess.run(self.q_output, {self.input_state: feed_state,
self.input_action: feed_action})
def predict_q_target_net(self, feed_state, feed_action, sess=None):
sess = sess or self.sess
return sess.run(self.target_net_q_output, {self.input_state: feed_state,
self.input_action: feed_action})
def update_source_critic_net(self, feed_state, feed_action, feed_y, sess=None):
sess = sess or self.sess
return sess.run([self.train_q_op],
{self.input_state: feed_state,
self.input_action: feed_action,
self.y: feed_y})
def update_target_critic_net(self, sess=None):
sess = sess or self.sess
return sess.run(self.update_target_net_op)
def get_action_grads(self, feed_state, feed_action, sess=None):
sess = sess or self.sess
return (sess.run(self.get_action_grad_op, {self.input_state: feed_state,
self.input_action: feed_action}))[0]
agent/ddpg.py
import numpy as np
class Agent(object):
def __init__(self, model, replay_buffer, exploration_noise, discout_factor, verbose=False):
self.model = model
self.replay_buffer = replay_buffer
self.exploration_noise = exploration_noise
self.discout_factor = discout_factor
self.verbose = verbose
def predict_action(self, observation):
return self.model.predict_action(observation)
def select_action(self, observation, p=None):
pred_action = self.predict_action(observation)
noise = self.exploration_noise.return_noise()
if p is not None:
return pred_action * p + noise * (1 - p)
else:
return pred_action + noise
def store_transition(self, transition):
self.replay_buffer.store_transition(transition)
def init_process(self):
self.exploration_noise.init_process()
def get_transition_batch(self):
batch = self.replay_buffer.get_batch()
transpose_batch = list(zip(*batch))
s_batch = np.vstack(transpose_batch[0])
a_batch = np.vstack(transpose_batch[1])
r_batch = np.vstack(transpose_batch[2])
next_s_batch = np.vstack(transpose_batch[3])
done_batch = np.vstack(transpose_batch[4])
return s_batch, a_batch, r_batch, next_s_batch, done_batch
def preprocess_batch(self, s_batch, a_batch, r_batch, next_s_batch, done_batch):
target_actor_net_pred_action = self.model.actor.predict_action_target_net(next_s_batch)
target_critic_net_pred_q = self.model.critic.predict_q_target_net(next_s_batch, target_actor_net_pred_action)
y_batch = r_batch + self.discout_factor * target_critic_net_pred_q * (1 - done_batch)
return s_batch, a_batch, y_batch
def train_model(self):
s_batch, a_batch, r_batch, next_s_batch, done_batch = self.get_transition_batch()
self.model.update(*self.preprocess_batch(s_batch, a_batch, r_batch, next_s_batch, done_batch))
mechanism/ou_process.py
'''
refer to openai
https://github.com/rll/rllab/blob/master/rllab/exploration_strategies/ou_strategy.py
'''
import numpy as np
class OU_Process(object):
def __init__(self, action_dim, theta=0.15, mu=0, sigma=0.2):
self.action_dim = action_dim
self.theta = theta
self.mu = mu
self.sigma = sigma
self.current_x = None
self.init_process()
def init_process(self):
self.current_x = np.ones(self.action_dim) * self.mu
def update_process(self):
dx = self.theta * (self.mu - self.current_x) + self.sigma * np.random.randn(self.action_dim)
self.current_x = self.current_x + dx
def return_noise(self):
self.update_process()
return self.current_x
if __name__ == "__main__":
ou = OU_Process(3, theta=0.15, mu=0, sigma=0.2)
states = []
for i in range(10000):
states.append(ou.return_noise()[0])
import matplotlib.pyplot as plt
plt.plot(states)
plt.show()
mechanism/replay_buffer.py
from collections import deque
import random
class Replay_Buffer(object):
def __init__(self, buffer_size=10e6, batch_size=1):
self.buffer_size = buffer_size
self.batch_size = batch_size
self.memory = deque(maxlen=buffer_size)
def __call__(self):
return self.memory
def store_transition(self, transition):
self.memory.append(transition)
def store_transitions(self, transitions):
self.memory.extend(transitions)
def get_batch(self, batch_size=None):
b_s = batch_size or self.batch_size
cur_men_size = len(self.memory)
if cur_men_size < b_s:
return random.sample(self.memory, cur_men_size)
else:
return random.sample(self.memory, b_s)
def memory_state(self):
return {"buffer_size": self.buffer_size,
"current_size": len(self.memory),
"full": len(self.memory)==self.buffer_size}
def empty_transition(self):
self.memory.clear()
run_ddpg.py
from model.ddpg_model import Model
from gym import wrappers
from agent.ddpg import Agent
from mechanism.replay_buffer import Replay_Buffer
from mechanism.ou_process import OU_Process
import gym
import numpy as np
ENV_NAME = 'Pendulum-v0'
EPISODES = 100000
MAX_EXPLORE_EPS = 100
TEST_EPS = 1
BATCH_SIZE = 64
BUFFER_SIZE = 1e6
WARM_UP_MEN = 5 * BATCH_SIZE
DISCOUNT_FACTOR = 0.99
ACTOR_LEARNING_RATE = 1e-4
CRITIC_LEARNING_RATE = 1e-3
TAU = 0.001
def main():
env = gym.make(ENV_NAME)
env = wrappers.Monitor(env, ENV_NAME+"experiment-1", force=True)
state_dim = env.observation_space.shape[0]
action_dim = env.action_space.shape[0]
model = Model(state_dim,
action_dim,
actor_learning_rate=ACTOR_LEARNING_RATE,
critic_learning_rate=CRITIC_LEARNING_RATE,
tau=TAU)
replay_buffer = Replay_Buffer(buffer_size=BUFFER_SIZE ,batch_size=BATCH_SIZE)
exploration_noise = OU_Process(action_dim)
agent = Agent(model, replay_buffer, exploration_noise, discout_factor=DISCOUNT_FACTOR)
action_mean = 0
i = 0
for episode in range(EPISODES):
state = env.reset()
agent.init_process()
# Training:
for step in range(env.spec.timestep_limit):
# env.render()
state = np.reshape(state, (1, -1))
if episode < MAX_EXPLORE_EPS:
p = episode / MAX_EXPLORE_EPS
action = np.clip(agent.select_action(state, p), -1.0, 1.0)
else:
action = agent.predict_action(state)
action_ = action * 2
next_state, reward, done, _ = env.step(action_)
next_state = np.reshape(next_state, (1, -1))
agent.store_transition([state, action, reward, next_state, done])
if agent.replay_buffer.memory_state()["current_size"] > WARM_UP_MEN:
agent.train_model()
else:
i += 1
action_mean = action_mean + (action - action_mean) / i
print("running action mean: {}".format(action_mean))
state = next_state
if done:
break
# Testing:
if episode % 2 == 0 and episode > 10:
total_reward = 0
for i in range(TEST_EPS):
state = env.reset()
for j in range(env.spec.timestep_limit):
# env.render()
state = np.reshape(state, (1, 3))
action = agent.predict_action(state)
action_ = action * 2
state, reward, done, _ = env.step(action_)
total_reward += reward
if done:
break
avg_reward = total_reward/TEST_EPS
print("episode: {}, Evaluation Average Reward: {}".format(episode, avg_reward))
if __name__ == '__main__':
main()
感谢
在代码debug过程中,看了github一些其他的优秀实现,也希望大家能看看他们的代码,从中学习。下面是他们Repo的截图。