Graph Convolutional Tracking
文章目录
- ==摘要==
- ==Introduction==
- ==Related work==
- ==GCT==
- **GCN**
- `Target Appearance Modeling via ST-GCN`
- `Target Feature Adaption via CT-GCN`
- The Proposed Tracking Algorithm
- 网络结构
- 离线训练
- Tracking Inference
- 实验结果
- 总结
这是张天柱老师团队在2019CVPR(Oral)发表的一篇基于图卷积做的跟踪文章
链接: 文章详情.
摘要
近年来,基于 siamese 网络的跟踪获得良好的性能。然而现存在的 大多数siamese 网络没有在不同的上下文情景下充分利用时空目标外观模型(do not take full advantage of spatial-temporal target appearance modeling under different contextual situations)。事实上,时空信息可以提供不同的特征来增强目标的表示,并且上下文信息对于目标定位的在线调整很重要。为了充分利用历史目标样本的时空结构,并从上下文获益,在这个工作中,我们提出了一个新的图卷积跟踪(GCT)高性能视觉跟踪方法。具体来说,GCT将两种类型的GCN网络合并到用于目标外观建模的siamese框架中。这里,我们采用一个时空的GCN(spatial-temporal GCN)来建模历史目标样本的结构表示。此外,一个上下文GCN(context GCN)被设计,为利用当前帧的上下文来学习目标定位的自适应特征。在4个有挑战的benchmarks广泛的结果表明我们的GCT方法相对于最先进的跟踪器表现良好,同时速度为50fps。
感觉这个时空信息很吸引人,对于一个视频的跟踪,很少有文章去考虑以前帧的信息。 它保存的历史帧仅仅是模板帧的,模板帧来自于 一个物体的视频片段在最近的100帧中收集了T+1帧的训练样本,使用前T帧作为模板图像,最后一帧作为搜索图像。并使用间隔为7来更新模板图像。用imageNet数据集离线训练。T=10,GCT 的score和原来siamfc的score都使用,只不过加了权重。
Introduction
visual tracking-----target object is localized in a changing video sequence automatically
challenges-------occlusion,background cluter,illumination variation,scale variation,motion blur,fast motion,deformation
siamFC 当目标物体有严重的外观改变时遇到了很大的困难。
改进的方法: attention learning
dynamic updating
structured modeling
transformation learning
3D spatial-temporal graph
two-fold learning
triplet loss optimizatioin
region proposal network
adversarial learning
deep reinforcement learning
distractor-aware module
structured modeling
缺点:没有充分利用在不同的上下文情景下的时空目标外观模型
这篇文章提出了一个基于siamese框架的端到端的GCT方法,联合考虑了历史帧的时空目标外观结构和当前搜索图像的上下文信息。为了使得跟踪高效,所有的学习过程都离线训练。
贡献:1.采用了一个端到端的图卷积跟踪框架
2.在siamese 网络中设计了ST-and CT-GCN
3.在五个视觉跟踪基准上进行了广泛的实验
Related work
Tracking by Siamese Network:SINT 、 SiamFC、 DSiam
Structured Target Appearance Modeling.:解决不同的挑战
FlowTrack、part-based methods、spectral
tracking methonds
Graph Neural Networks for Computer Vision:spatial manner
spectral manner
GCN
GCT

![]()
Spatial-Temporal GCN (ST-GCN) ψ1
ConText GCN (CT-GCN) ψ2.
ST-feature:
![]()
logistic function:

![]()
GCN
![]()
graph signal X
filter W
![]()
![]()
Target Appearance Modeling via ST-GCN
首先模板分支以历史样本图片作为输入,经过一个shared ConvNet(modified AlexNet 在ImageNet上预训练)产生对应的Examplar EmbeddingZ(t-T,t-1),D1xMz,分别表示特征的维度和parts数目,为了方便我们考虑特征mapZ的每个D1x1x1小格作为目标part。
we construct an undirected ST-graph G1 = (V1, E1) on an exemplar embedding sequence with Mz parts (nodes) and T frames featuring both intra-exemplar and inter-exemplar relationships.
顶点:V1 = {vij |i = t-1, …, t-T, j = 1, …, Mz},总共MzT个顶点
边:(1)每帧中样本内连接,采用全连接图来描述空间的表示,因为在不同的外观改变下所有的目标parts可能有交互作用。
(2)我们把连续帧中相同位置的parts连起来作为时间边
然后送到ST-GCN ,对图中的每个顶点生成特征向量Zi(i=t-1->t-T),为了减少接下来层的计算压力,我们沿着时间维度聚合了特征并产生了紧凑的特征ST-featureV1(D2xMz):
![]()
Target Feature Adaption via CT-GCN
以当前搜索帧图像 xt 作为输入,那个shared ConvNet 网络产生Instance Embedding Xt(D1x Mx)为了得到搜索图像的全局信息,我们利用一个卷积层(D2filter,3x3,stride1)和一个最大池化层(Mx)来生成全局特征xt(D1x1),将当前的全局特征xt 作为当前上下文信息,然后使用deconvolution layer来得到较大的特征Xˆ t,它与ST-feature V1具有同样的大小,then:
![]()
Vx 被认为是具有目标物体的时空特征和当前帧的上下文信息。为了实现鲁棒性特征自适应的图学习,我们使用Vx生成一个自适应图,其邻接矩阵A2定义如下:
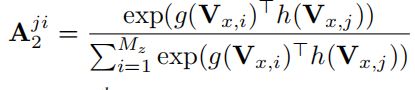
g(·) and h(·) are two 1 × 1 convolutional layers with D1 filters.
有了邻接矩阵,就可以构图,然后以V1作为输入,生成自适应的特征V2,V2 和 Xt做相关得到相应的分数。
The Proposed Tracking Algorithm
网络结构
shared ConvNet: modified AlexNet , 在ImageNet上预训练,前三层卷积层的权重固定,仅仅微调最后两层,并且增加了一个3x3 卷积层来减少输出的维度D1=256。
Mz=6x6 Mx=22x22 2层ST-GCN 2层CT-GCN
离线训练
ImageNet Large Scale Visual Recognition Challenge(ILSVRC2015) 4500videos
我们在一个物体的视频片段在最近的100帧中收集了T+1帧的训练样本,使用前T帧作为模板图像,最后一帧作为搜索图像。(T=10)
ADAM optimizer 学习率为0.005 权重衰减5e -5 训练50 epochs batchsize 24
Tracking Inference
在跟踪过程中,我们使用间隔为7来更新模板图像。具体来说,每隔7帧,第一张模板图片就被移除,新的加入。
使用了shared ConvNet的cov5特征得到了另一分数 Rs,最后的分数用系数 r=0.7来平衡:
![]()
使用来cosine window,three scales。
实验结果
OTB
OPE(one-pass evaluation),两个指标success plot and precision plot
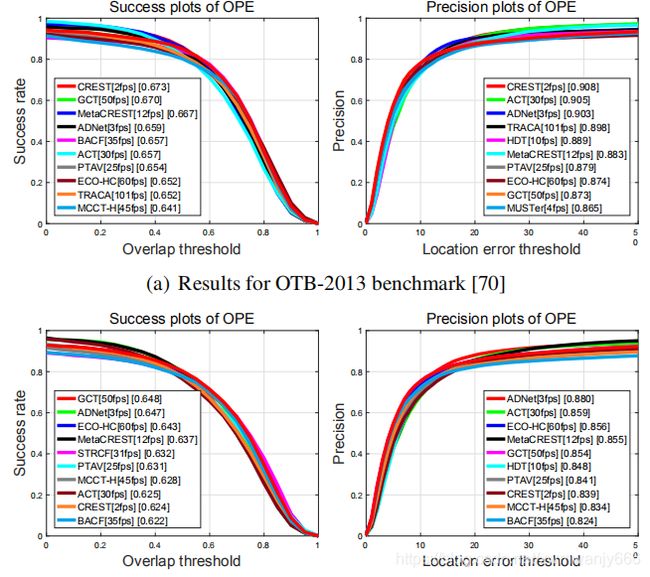
Note that the DP score of our method is not very significant, which may because of the low resolution of the response map (17×17) and its interpolation process in target localization.
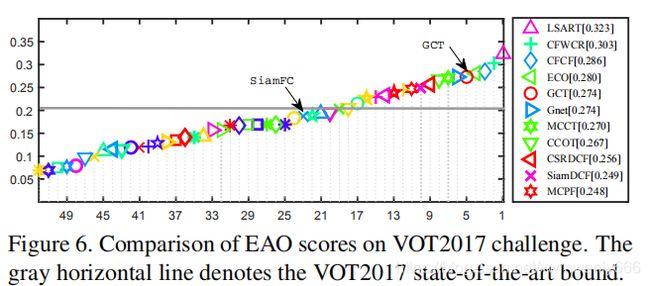
VOT
Expected Average Overlap(EAO)
总结
In the future, we intend to explore other types of graph neural networks for visual tracking, such as graph embedding and graph attention model.
代码没有公布出来,只知道大体想法和思路,但是具体实现还是不清楚。