Jsoup解析WSDL文档代码实例
Jsoup解析WSDL文档代码示例
文章说明:本文章目的在于分享本人对wsdl文档的解析结果,希望可以通过本实例帮助大家了解如何解析wsdl中
文章目录
- Jsoup解析WSDL文档代码示例
- 前言
- 一、WSDL文档及其结构
- 二、jsoup介绍
- 三、实例代码展示
- 1.代码思路/结构展示
- 2.项目结构
- 3.代码示例
- 4.所解析的WSDL文档
- 5.解析运行结果
- 总结
前言
1、如果需要解析WSDL文档,首先就得了解WSDL文档本身,还没有的了解的可以去百度搜索了解,这个是解析的根本!2、了解WSDL文档后,就得找解析的工具帮助我们去解析了。此处使用了jsoup-1.11.2.jar;解析工具有很多,例如还有wsdl4j、dom4j等...
注意:工具并不是我们关注的重点,解析的方法和原理才是!
3、本“Jsoup解析WSDL文档实例”会尽量将代码与原理讲明白,此处以获取请求报文为例,让读者更容易看明白~
一、WSDL文档及其结构
WSDL(Web服务描述语言,Web Services Description Language)是为描述Web服务发布的XML格式。
由于本文档重点讲解代码及方法思路,此处请百度~
二、jsoup介绍
jsoup是一款Java的HTML解析器,主要用来对HTML解析。
当然了,也可以解析XML~
具体的用法此处暂不多讲,可以百度搜索、或查看官方API文档可以了解其用法。
三、实例代码展示
1.代码思路/结构展示
(1)方法步骤图解:
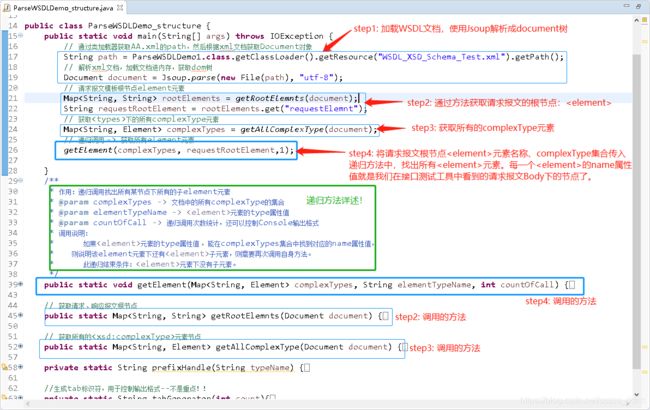
(2)WSDL文档图解(绿色箭头、描述是重点!):

2.项目结构

3.代码示例
代码示例(建议复制到开发工具):
import java.io.File;
import java.io.IOException;
import java.util.HashMap;
import java.util.Iterator;
import java.util.Map;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
/**
* 作用:遍历WSDL的xsd文档中的types元素节点,原理与soap接口测试工具的获取WSDL下不同服务的请求报文类似。
* 说明:
* 1、xsd文档本属于XML,所以此处使用了jsoup解析工具,解析wsdl的xsd
* 2、做types元素节点解析前提:熟悉xsd文档、及wsdl的文档结构
* @author Administrator
*/
public class ParseWSDLDemo1 {
public static void main(String[] args) throws IOException {
// 通过类加载器获取AA.xml的path,然后根据xml文档获取Document对象
String path = ParseWSDLDemo1.class.getClassLoader().getResource("WSDL_XSD_Schema_Test.xml").getPath();
// 解析xml文档,加载文档进内存,获取dom树
Document document = Jsoup.parse(new File(path), "utf-8");
// 打印检查document有没有获取成功
//System.out.println(document);
// 请求报文模板根节点element元素
Map<String, String> rootElements = getRootElemnts(document);
String requestRootElement = rootElements.get("requestElemnt");
/*
* 打印根节点name属性值-> 此处只是说明,而不是重点!!!
* 注意:"
System.out.println(" + requestRootElement + ">");
// 获取下的所有complexType元素
Map<String, Element> complexTypes = getAllComplexType(document);
// 递归调用 -> 获取所有element元素
getElement(complexTypes, requestRootElement,1);
System.out.println(" + requestRootElement + ">");
}
/**
* 作用:递归调用找出所有某节点下所有的子element元素
* @param complexTypes -> 文档中的所有complexType的集合
* @param elementTypeName -> 元素的type属性值
* @param countOfCall -> 递归调用次数统计,还可以控制Console输出格式
* 调用说明:
* 如果元素的type属性值 ,能在complexTypes集合中找到对应的name属性值,
* 则说明该element元素下还有子元素,则需要再次调用自身方法。
* 此递归结束条件:元素下没有子元素。
*/
public static void getElement(Map<String, Element> complexTypes, String elementTypeName, int countOfCall) {
//System.out.println("调用次数 - " + countOfCall);
if (complexTypes.containsKey(elementTypeName)) {
// 获取指定名称的complexType节点
Element complexType = complexTypes.get(elementTypeName);
//获取指定complexType节点的element元素
Elements elements = complexType.getElementsByTag("xsd:element");
Iterator<Element> ie = elements.iterator();
while (ie.hasNext()) {
Element element = ie.next();
String eleTypeName = prefixHandle(element.attr("type"));
String nodeName = element.attr("name");
/*
* containsKey作用:
* 检查element元素的type属性值是否有complexType元素,
* 如果有则说明该element元素下还嵌套其他子元素
*/
boolean containsKey = complexTypes.containsKey(eleTypeName);
//此判断只是控制Console输出格式
if(containsKey){
System.out.println(tabGenerator(countOfCall) + " + nodeName + ">");
}else{
System.out.print(tabGenerator(countOfCall) + " + nodeName + ">");
}
/*
* 递归调用判断:如果元素还有复杂元素(complexType),则再次调用本分方法
*/
if (containsKey) {
countOfCall += 1;
getElement(complexTypes, eleTypeName, countOfCall);
}
//此判断只是控制Console输出格式
if (!containsKey) {
System.out.print("?"); //如果没有子节点的element元素,就加上'问号'
System.out.println(" + nodeName + ">");
}else{
System.out.println(tabGenerator(countOfCall - 1) + " + nodeName + ">");
}
}
} else {
System.out.println("节点异常(不同寻常...),请检查wsdl地址或使用soap测试工具检查!");
}
}
// 获取请求、响应报文根节点
public static Map<String, String> getRootElemnts(Document document) {
// 使用Map保存根节点元素的name及其属性值
Map<String, String> rootElement = new HashMap<>();
// 通过元素标签名获取types元素,返回的是Elements集合(Elements可直接当作集合使用)
Elements e = document.getElementsByTag("wsdl:types");
// 一般情况,wsdl下只有一个types元素节点
Element typesNode = e.get(0);
// 一般情况,type下只有一个schema元素子节点
Element schema = typesNode.child(0);
// 把schema下的所有complexType获取出来,保存至Elements集合(Elements可直接当作集合使用)
// schemaChilds中有7个子元素:其中包括5个complexType、2个element(2个element就是要拿的element节点)
Elements schemaChilds = schema.children();
// System.out.println(schemaChilds.size());
Iterator<Element> iter = schemaChilds.iterator();//集合遍历
String requestElemnt = "";
String responseElemnt = "";
while (iter.hasNext()) {
Element child = iter.next();
//通过nodeName()方法获取元素节点name属性值
if (child.nodeName().contains("element")) { // 通过element关键字来判断child元素是否element元素
// 请求报文根节点
if (child.attr("type").contains("Request") || child.attr("type").contains("request")) {
requestElemnt = prefixHandle(child.attr("type"));// 前缀处理
}
// 响应报文根节点
if (child.attr("type").contains("Response") || child.attr("type").contains("response")) {
responseElemnt = prefixHandle(child.attr("type"));// 前缀处理
}
}
}
rootElement.put("requestElemnt", requestElemnt);
rootElement.put("responseElemnt", responseElemnt);
return rootElement;
}
// 获取所有的元素节点
public static Map<String, Element> getAllComplexType(Document document) {
// complexType用于保存:complexType元素的name属性值及对应的complexType元素
Map<String, Element> complexType = new HashMap<>();
//通过complexType的标签名获取所有的complexType元素
Elements complexEle = document.getElementsByTag("xsd:complexType");
Iterator<Element> it = complexEle.iterator();
while (it.hasNext()) {
Element complexNode = it.next();
complexType.put(complexNode.attr("name"), complexNode);
}
return complexType;
}
/*
* 处理元素中type属性的前缀
* 例如: 4.所解析的WSDL文档
说明:将其复制到项目的resources文件夹下,若无该文件夹,则创建一个新的。然后命名为:WSDL_XSD_Schema_Test.xml
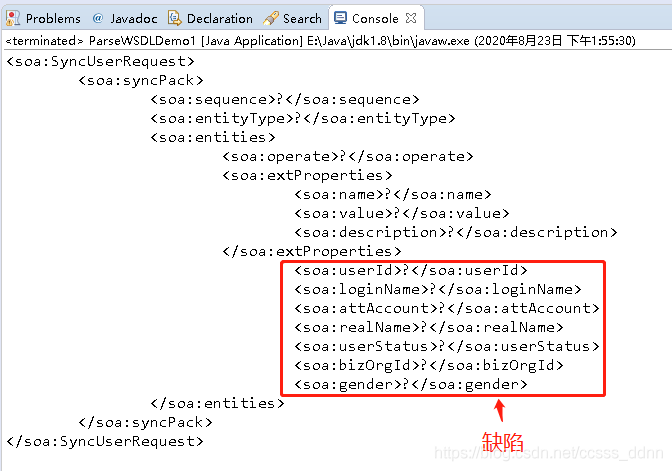
5.解析运行结果
如下图所示:请求报文解析成功;运行结果还有个小缺陷,不过不影响主体功能。