Caffe学习笔记1:linux下建立自己的数据库训练和测试caffe中已有网络
本文是基于薛开宇 《学习笔记3:基于自己的数据训练和测试“caffeNet”》基础上,从头到尾把实验跑了一遍~对该文中不清楚的地方做了更正和说明。
主要工作如下:
1、下载图片建立数据库
2、将图片转化为256*256的lmdb格式
3、计算图像均值
4、定义网络修改部分参数
1、下载图片建立数据库
在caffe-master/data 下新建一个属于自己的数据库命名为babyjia,并在该文件夹下创建 train 和 val 文件夹用于存放训练集和验证集的图片:
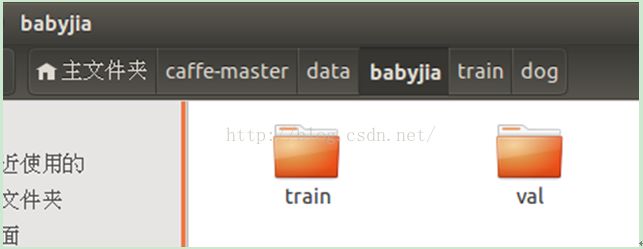
我一共选取了100张训练集图片和20张验证集图片,分类如下:
训练集:猫 50 张图片 狗 50 张图片
验证集:猫 10 张图片 狗 10 张图片
由于训练集的图片较多,我在 train 文件夹下又增加了 dog 和 cat 文件夹
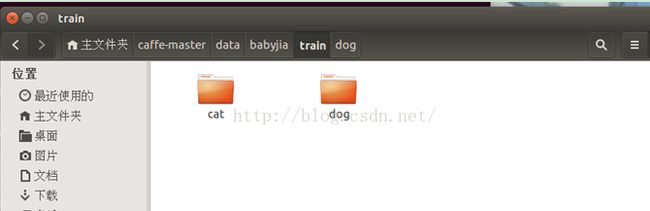
下图为训练集中狗类别的示例:

find -name *.jpeg |cut -d '/' -f 3-4>train.txt
find -name *.jpeg |cut -d '/' -f 3-4>val.txt最终保证在 train.txt、val.txt 中存储的是分别是 train 文件夹和 val 文件夹中的图片的相对路径。
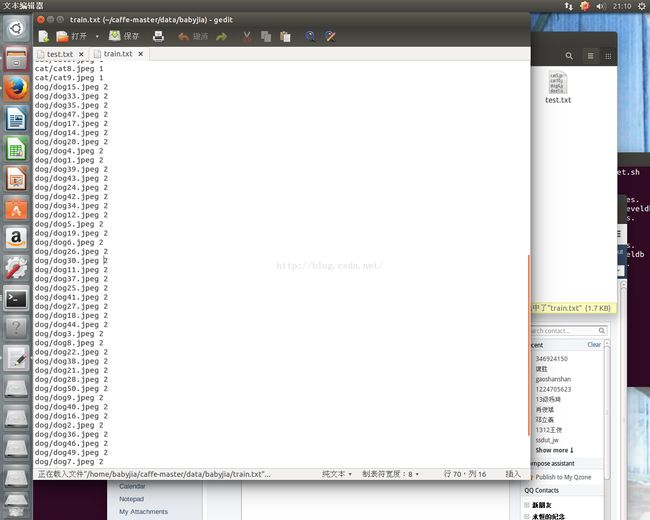
train.txt 中的内容:

val.txt 中的内容:

然后把给两个文件夹中的图片手动存储上标签,0~999均可 ,这里我们用1代指cat ,2代指dog
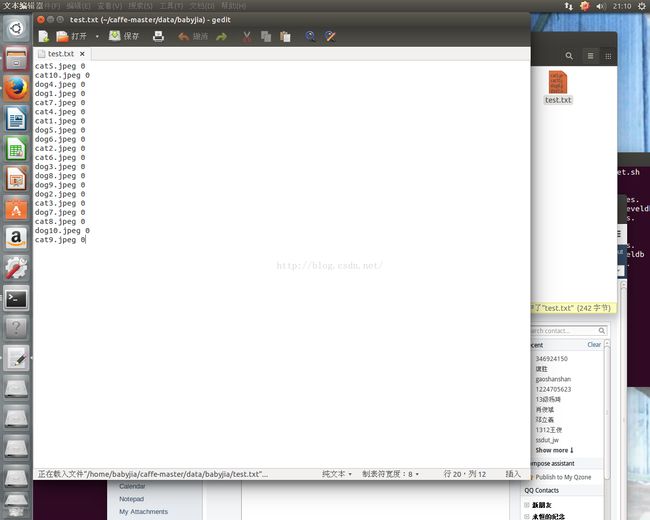
同时我们建立 test.txt 文件,令其内容和 val.txt 一样,但是所有标签均为0;
最后我们会在 caffe-master/data/babyjia 文件夹下得到 test.txt train.txt 内容分别如下(val没有列出来):
2、将图片转化为256*256的lmdb格式
在 caffe-master 下又创建了一个 babyjia 文件夹(上次是在 caffe-master/data 下创建的)这里将 caffe-master/examples/imagenet
下的 create_imagenet.sh 拷贝到刚刚创建的 babyjia 文件下,做相应路径的修改:
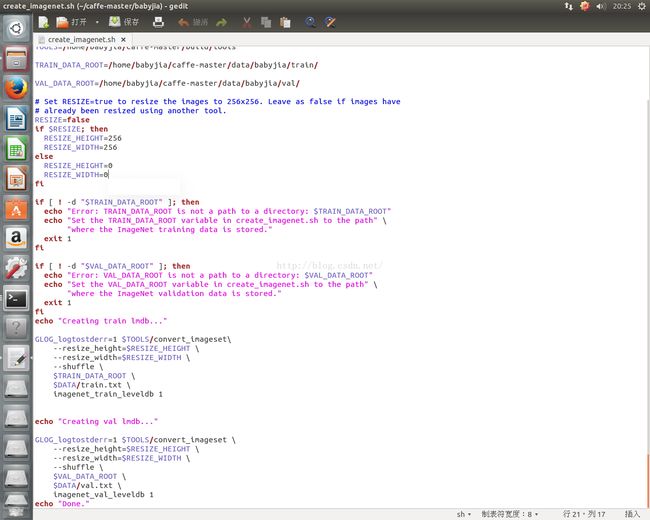
需要修改的地方如下:
DATA=/home/babyjia/caffe-master/data/babyjia
TOOLS=/home/babyjia/caffe-master/build/tools
TRAIN_DATA_ROOT=/home/babyjia/caffe-master/data/babyjia/train/
VAL_DATA_ROOT=/home/babyjia/caffe-master/data/babyjia/val/
.....
RESIZE=false
...
GLOG_logtostderr=1 $TOOLS/convert_imageset\
--resize_height=$RESIZE_HEIGHT \
--resize_width=$RESIZE_WIDTH \
--shuffle \
$TRAIN_DATA_ROOT \
$DATA/train.txt \
imagenet_train_leveldb 1
echo "Creating val lmdb..."
GLOG_logtostderr=1 $TOOLS/convert_imageset \
--resize_height=$RESIZE_HEIGHT \
--resize_width=$RESIZE_WIDTH \
--shuffle \
$VAL_DATA_ROOT \
$DATA/val.txt \
imagenet_val_leveldb 1在执行下面的语句后:
./create_imagenet.sh终端会显示处理了100个训练集的图片和20个验证集的图片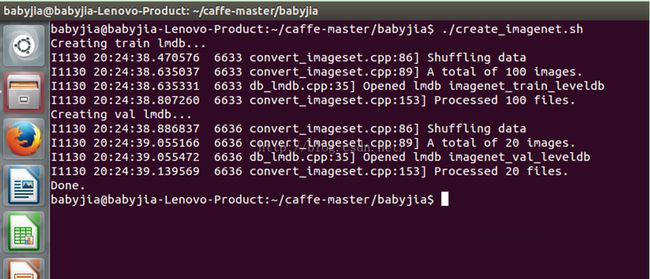
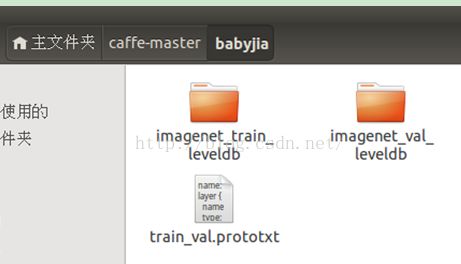
3、计算图像均值
把caffe-master/examples/imagenet 文件夹下的make_imagenet_mean.sh文件拷贝到caffe-master/babyjia文件下
并做相应的修改

其中
$TOOLS/compute_image_mean.bin//路径imagenet_train_leveldb//要求取平均值的leveldb文件的路径$DATA/imagenet_mean.binaryproto //要生成的binaryproto文件的路径./make_imagenet_mean.sh
4、定义网络修改部分参数
“两个prototxt文件和一个sh文件”
从caffe-master/models/bvlc_reference_caffenet文件夹下拷贝 train_val.prototxt 和solver.prototxt到caffe-master/babyjia文件夹下
从caffe-master/examples/imagenet 文件夹下拷贝 train_caffenet.sh 到caffe-master/babyjia文件夹下
对train_val.prototxt 作如下修改:
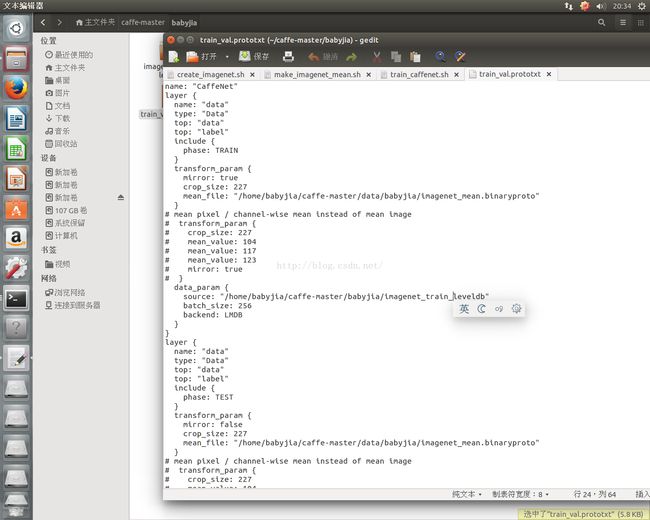
transform_param {
mirror: true
crop_size: 227
mean_file: "/home/babyjia/caffe-master/data/babyjia/imagenet_mean.binaryproto"
}
data_param {
source: "/home/babyjia/caffe-master/babyjia/imagenet_train_leveldb"
batch_size: 256
backend: LMDB
}
transform_param {
mirror: false
crop_size: 227
mean_file: "/home/babyjia/caffe-master/data/babyjia/imagenet_mean.binaryproto"
}data_param {
source: "/home/babyjia/caffe-master/babyjia/imagenet_val_leveldb"
batch_size: 50
backend: LMDB
}solver.prototxt 作如下修改:
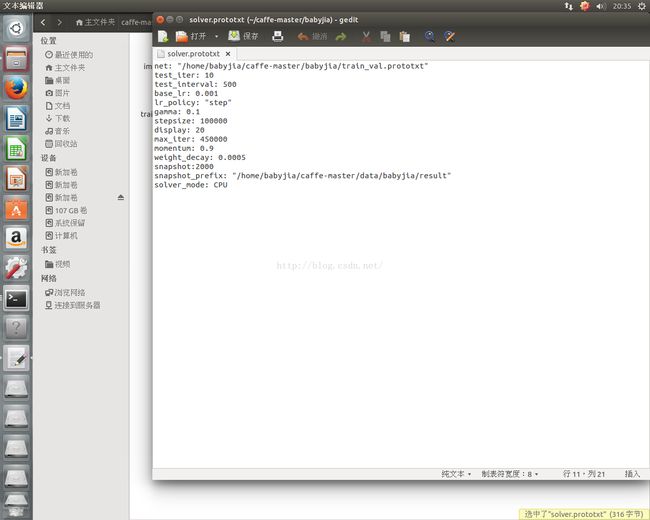
test_iter: 1000 是指测试的批次,我们就 10 张照片,设置 10 就可以了。
test_interval: 1000 是指每 1000 次迭代测试一次,我们改成 500 次测试一次。
base_lr: 0.01 是基础学习率,因为数据量小, 0.01 就会下降太快了,因此改成 0.001
lr_policy: "step"学习率变化
gamma: 0.1 学习率变化的比率
stepsize: 100000 每 100000 次迭代减少学习率
display: 20 每 20 层显示一次
max_iter: 450000 最大迭代次数,
momentum: 0.9 学习的参数,不用变
weight_decay: 0.0005 学习的参数,不用变
snapshot: 10000 每迭代 10000 次显示状态,这里改为 2000 次
solver_mode: CPU 末尾加一行,代表用 CPU 进行train_caffenet.sh 作如下修改:

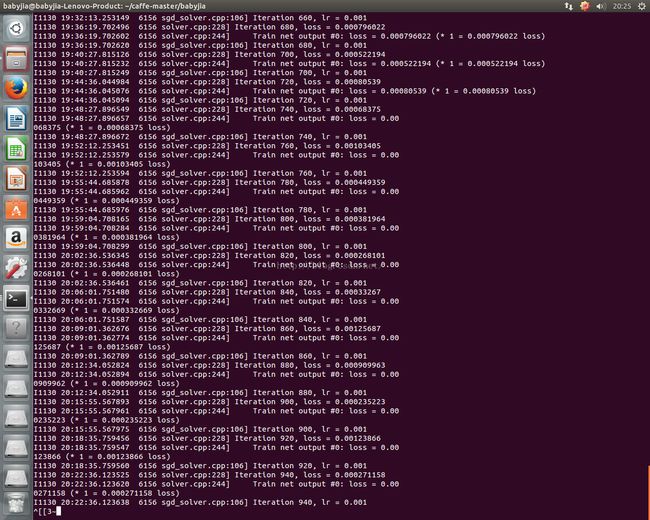
最后运行结果如下 :
参考资料: