[TOC]
简介
为何修改Java
java8的改变是为了让代码在多核CPU上高效运行。
面向对象编程 vs. 函数式编程
面向对象是对数据进行抽象;
函数式编程是对行为进行抽象
函数式编程的核心:在思考问题时,使用不可变值和函数,函数对一个值进行处理,映射成另一个值
lambda表达式
第一个lambda表达式
匿名内部类是代码即数据的例子。我们传递的参数是代表某种行为的对象。但是这种方式冗长,需要样板代码,而且可读性很差,没有表达出来程序员的意图。我们不想传入对象,只想传入行为。lambda就是传入一段代码块——一个没有名字的函数。
传入行为的时候,参数不用指定类型,编译器根据参数类型进行推断,比如是A类型的对象,那么会找A里面的默认方法,这个方法的参数类型就是lambda表达式的参数类型。也就是说,只有一个方法的接口的匿名内部类对象==一个lambda表达式
如何辨别lambda表达式
lambda的几种形式 :
Runnable noArguments = () -> System.out.println("Hello Wordl");
ActionListener oneArguments = event -> System.out.println("button clicked");
Runnable multiStatement = () -> {
System.out.println("Hello");
System.out.println("World");
};
BinaryOperator add = (x, y) -> x + y;
BinaryOperator addExplict = (Long x, Long y) -> x + y;
lambda表达式的目标类型是函数接口,但具体是哪个函数接口,需要通过上下文推断。即根据lambda被赋值的对象的类型去推断lambda表达式的参数类型。
引用值,而不是变量
匿名内部类引用外部变量的时候,外部变量需要是final。lambda是一样的,但是可以不写final。但是如果改变了变量值也会报错。所以lambda也被称为闭包。因为需要是未赋值的变量与周边环境隔离起来,进而被绑定到一个特定的值。
这里就参考上面的定义,函数是对不可变的值进行处理,然后映射成为另一个值。
函数接口
lambda本身的类型是函数接口:只有一个抽象方法的接口。这来源于java编程以前经常使用的一个技巧,就是使用只有一个方法的接口来表示某特定方法并反复使用。这种用法被改进为lambda表达。但是历史告诉我们,一个显而易见的地方的改进往往能带来更多不能一眼想到的牛逼用法的改进。比如后面的流处理那些。
我理解,函数式编程需要定义一个函数的壳子,然后用的时候有函数的实例。如同类与实例的关系。但是java不允许这种形式的存在。所以折中的处理就是把函数壳子放到接口中。函数的实例放到接口的匿名内部类的实例中。现在lambda改变的是匿名内部类这种丑陋的形式,让它看起来像是一个简洁的函数了。同时需要注意,接口中只能定义一个函数,否则编译器无法得知你想用哪个函数模板。
直接定义函数模板,目前java暂时无法实现。所以必须把函数模板放在接口中,成为函数接口,即java只能定义一个接口(或者类),但是函数接口中的那个函数实质上就是函数模板。
但是函数实例替换匿名类对象这个是可以做到的。注意,如果变量或者参数就是函数接口的匿名类对象,我们可以直接传入lambda表达式。但是如果变量和参数是其他类的匿名类对象呢?如果这个匿名类对象只有一个行为,那么我们可以用lambda表示这个行为,然后在类内部实现一个子类+工厂方法,工厂方法的入参是lambda,返回值是内部子类。工厂方法内调用子类的构造函数,其入参也是lambda。内部子类有lambda的引用,然后重写父类需要的那个行为(那个函数),函数内部使用lambda就行了。这里的lambda一般是supplier。
下面是ThreadLocal的例子:
// ThreadLocal内部实现
public static ThreadLocal withInitial(Supplier supplier) {
return new SuppliedThreadLocal<>(supplier);
}
static final class SuppliedThreadLocal extends ThreadLocal {
private final Supplier supplier;
SuppliedThreadLocal(Supplier supplier) {
this.supplier = Objects.requireNonNull(supplier);
}
@Override
protected T initialValue() {
return supplier.get();
}
}
// 传统方式
private static ThreadLocal name = new ThreadLocal() {
@Override
protected String initialValue() {
return "default";
}
};
// 使用lambda后
private static ThreadLocal name = ThreadLocal.withInitial(() -> "default");
我们需要的是ThreadLocal的子类,返回的SuppliedThreadLocal实例的确是它的子类。
我们需要子类实现initialValue方法,SuppliedThreadLocal实例的确实现了,只不过它的行为使用lambda表达的。
到这里,我们可以看到,我们可以用lambda的函数模板去调用可能出现的函数实例。和原来java代码中使用了抽象方法,运行的时候实际使用的是子类方法一样。实际运行的时候传入的是什么lambda(子类方法),函数模板(抽象方法)实际运行的就是什么。
这样我们可以把函数模板放在其他函数的函数体中,这样感觉lambda能发挥作用的空间就更大了。
- supplier是0进1出,方法是get
- consumer是1进0出,方法是accept
- function是1进1出,方法是apply
- predicate是1进1判断,方法是test
- BiConsumer是2进0出,方法是accept
- BiFunction是2进1出,方法是apply
- Bipredictate是2进1判断,方法也是test
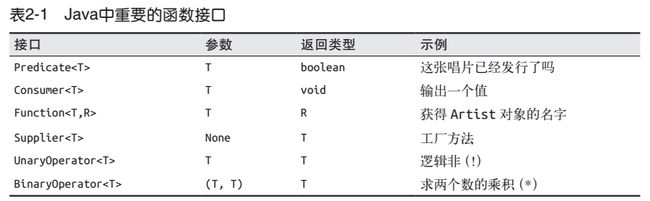
2.5 类型推断
java7中的菱形操作符就是类型推断的一种。主要是有赋值给变量和赋值给函数参数两种,根据变量或者参数的类型,都可以推断。
3 流
对核心类库的改进主要包括集合类的API和新引入的流(Stream)。流能让程序员得以站在更高的抽象层次上对集合进行操作。
stream类的每个方法都对应集合上的一种操作。它是用函数式编程方式在集合类上进行复杂操作的工具。
3.1 从外部迭代到内部迭代
对集合最常见的操作就是迭代,但是样板代码多。另外,如果集合元素很多,想并行提高效率也很麻烦。最后,代码表意性不强。
for循环是封装iterator的语法糖,是外部迭代。

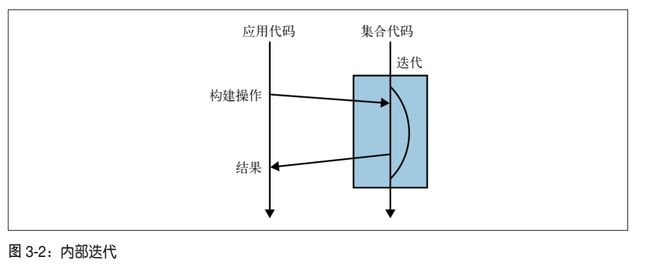
3.2 实现机制
一串惰性求值方法+最后的一个及早求值方法,类似于建造者模式。区分方式:
- 惰性求值方法:返回值是stream
- 及早求值方法:返回值是另一个值或者为空
这样在对需要什么样的操作和结果有更多的了解,可以更有效率地进行计算。
3.3 常用操作
了解一下comparator中的comparing方法。
Track shortestTrack = tracks.stream()
// 方式1,最传统的匿名对象
.min(new Comparator方式3本质思路就是把方式2的模板代码也省掉,我来替你写两个对象比较,加if和else的部分,因为这部分操作也是不变的,你只要给我比较对象就行了。
然后给的方式不是直接给,因为很多时候都是要有取对象的行为的。所以通过Function函数接口给。那么lambda的返回值就是比较对象了。这个对象需要是可比较的,就是实现中的U,需要已经实现了Comparable接口。基础数据类型都是实现了的。
然后在实现内部,jdk帮我们写了方式2的表达式,因为没有赋值给本地变量,直接return的,所以要强制类型转换一下。这里有个点,强制类型转换也可以是一个类加多个接口的。
总结:comparing方法接收一个函数,返回另一个函数。
重构建议
所有的返回List和Set的函数都可以换成返回Stream,它很好的封装了内部实现的数据接口,仅仅暴露一个Stream接口,用户实际使用不会影响内部的List或者set。
3.4 重构遗留代码
每次修改都要单测。
如果函数的参数或者返回值,有任何一个是函数,那么这个函数就被称为高阶函数。
3.7 正确使用lambda表达式
明确要达成什么转化,而不是说明如何转化,这样代码简介,缺陷少,表意清晰。而且没有副作用。只通过函数返回值就能充分理解函数的全部作用。
没有副作用的函数不会改变程序或者外界的状态。打印就算是副作用。
鼓励用户使用lambda表达式获取值而不是变量。这样用户就更容易写出没有副作用的代码。
4 类库
java8引入默认方法和接口的静态方法。
4.2 基本类型
java中没有List
stream对用得最多的3中基本类型做了区分。有对应的stream。如果可能,尽量用对基本类型做过特除处理的方法。


例子:
IntSummaryStatistics trackLengthStats
= album.getTracks()
.mapToInt(track -> track.getLength())
.summaryStatistics();
System.out.printf("Max: %d, Min: %d, Ave: %f, Sum: %d",
trackLengthStats.getMax(),
trackLengthStats.getMin(),
trackLengthStats.getAverage(),
trackLengthStats.getSum());
4.3 重载
选择更具体的,比如下面选择参数是IntegerBiFunction的,因为通过继承,IntegerBiFunction更具体。如果没有继承就无法区分,就编译报错。
overloadedMethod((x, y) -> x + y);
// BEGIN most_specific_bifunction
private interface IntegerBiFunction extends BinaryOperator {
}
private void overloadedMethod(BinaryOperator lambda) {
System.out.print("BinaryOperator");
}
private void overloadedMethod(IntegerBiFunction lambda) {
System.out.print("IntegerBinaryOperator");
}
4.4 @FunctionalInterface
用作函数接口的接口都应该添加,如果不是就不加,比如Closeable和Comparable接口,虽然是带有一个方法的接口。加了这个注释,javac会检查是否符合。
4.5678 二进制接口的兼容性 & 默认方法
为了向前兼容,自己项目中实现了Collection接口的类也需要增加Stream方法。否则编译不通过。避免的方式就是使用默认方法。
Collection接口中有默认方法,那就允许子类不实现它。比如Iterable接口新增默认方法:forEach。
默认方法的继承,用到时候再看看
4.9 接口的静态方法
就是用作工具方法,和这个接口紧密相关的。比如stream.of方法。
4.10 Optional
之前看过,没啥用
5 高级集合类和收集器
5.1 方法引用



除了上面说的,还有构造函数
(name, nationality) -> new Artist(name, nationality)
Artist::new
String[]::new
5.2 元素顺序
看集合本身是否有序。大多数流操作都是在有序集合上效率高。如果希望有序,用forEachOrdered方法。少数操作在无序上快,用unordered方法消除顺序。
5.3 使用收集器
如下的功能都是用Collectors里面的方法实现的,返回的都是不同功能的收集器(collector)
5.3.1 转换成其他集合
具体的集合实现类不需要你指定。如果希望指定,用toCollection
stream.collection(toCollection(TreeSet::new))
5.3.2 转换成值
maxBy和minBy。averagingInt
public Optional biggestGroup(Stream artists) {
Function getCount = artist -> artist.getMembers().count();
return artists.collect(maxBy(comparing(getCount)));// comparing是静态导入的
}
5.3.3 数据分块
用true和false分解成两个集合。partitioningBy。
public Map> bandsAndSoloRef(Stream artists) {
return artists.collect(partitioningBy(Artist::isSolo));
}
5.3.4 数据分组
用任意数值对数据分组。groupingBy。类似数据库中的group by操作。
// 专辑按照艺术家分组
public Map> albumsByArtist(Stream albums) {
return albums.collect(groupingBy(album -> album.getMainMusician()));
}
5.3.5 字符串
最后输出一个特定格式的字符串。joining。格式化艺术家姓名。
String result =
artists.stream()
.map(Artist::getName)
.collect(Collectors.joining(", ", "[", "]"));
5.3.6 组合收集器
有些需求用一个收集器不能满足,可以用多个,但是要有技巧。介绍两种方式。
一是
// 每个艺术家的专辑数,参考5.3.4
public Map numberOfAlbums(Stream albums) {
return albums.collect(groupingBy(album -> album.getMainMusician(),
counting()));
二是,这里用mapping告诉groupingBy将它的值作为映射,生成最终结果。
// 每个艺术家的专辑名称
public Map> nameOfAlbums(Stream albums) {
return albums.collect(groupingBy(Album::getMainMusician,
mapping(Album::getName, toList())));
两个例子都用到了第二个收集器,用于手机最终结果的一个子集。它们是下游收集器。
5.3.7 重构和定制收集器
如果项目需要,可以重构和定制收集器。
细节用到再看看
5.3.8 对收集器的归一化处理
没看懂
5.4 一些细节
首先,构建map时,尝试取值,如果没有,创建新值并返回。
java8中map新方法,computeIfAbsent
// 旧的方法
public Artist getArtist(String name) {
Artist artist = artistCache.get(name);
if (artist == null) {
artist = readArtistFromDB(name);
artistCache.put(name, artist);
}
return artist;
}
// 新方法
public Artist getArtist(String name) {
return artistCache.computeIfAbsent(name, this::readArtistFromDB);
}
还有putIfAbsent,compute。
第二,迭代map
// 旧方法
Map countOfAlbums = new HashMap<>();
for (Map.Entry> entry : albumsByArtist.entrySet()) {
Artist artist = entry.getKey();
List albums = entry.getValue();
countOfAlbums.put(artist, albums.size());
}
// 新方法
Map countOfAlbums = new HashMap<>();
albumsByArtist.forEach((artist, albums) -> {
countOfAlbums.put(artist, albums.size());
});
6 数据并行化
并发(concurrency)和并行(parallellism)的区分。本章讨论数据并行化,一种特殊形式的并行化。把数据分成块,为每块数据分配单独的处理单元。
另一种是任务并行化,它是线程不同,工作各异。比如servlet服务器。
并行化可以利用现代CPU架构,因为方向就是多核,而不是高主频。
6.3 并行化操作
- Steam对象用parrallel方法
- 集合调用parrallelStream方法
并发并行化一定快。一个重要因素就是数据量。
6.4 模拟系统
模特卡洛模拟法模拟掷骰子
6.5 限制
- reduce方法初始值必须是组合函数的恒等值。比如求和的初始值是0
- 组合操作必须符合结合律。就是说组合操作的顺序不重要。
- 避免持有锁,流框架会自己处理同步,程序员不需要自己加。
6.6 性能
影响因素
- 数据大小
数据够大才有意义。
- 源数据的结构
- 装箱
基本类型比装箱类型快
- 核心数量
- 单元处理开销
花在流中每个元素身上的时间越长,并行操作带来的性能提升越明显。
在底层,并行流还是用的fork/join框架。fork递归式地分解问题,然后每段并行执行,最终由join合并结果,返回最后的值。
能重复将数据结构对半分解的难易程度,决定了分解操作的快慢。能对半分解同时意味着待分解的值能够被等量地分解。
根据性能,核心类库的数据结构分3组:
- 性能好
ArrayList、数组或者IntStream.range,支持随机读取,能轻易被分解。
- 性能一般
HashSet、TreeSet,不易被公平分解,但大多数时候分解是可能的。
- 性能差
LinkedList,Stream.iterate、BufferedReader.lines,难于分解,可能需要O(N)
求和,LinkedList可能比ArrayList慢10倍。
分解后的操作可能是有状态的和无状态的。无状态操作包括map、filter、flatMap,有状态的包括sorted、distinct和limit。尽量避开有状态的。
6.7 并行化数组操作
针对数组的,脱离流框架的操作。都在Arrays中。以下是新增的并行化操作。都是修改原来的数组,不会产生新数组。

parallelSetAll初始化数组
// BEGIN simpleMovingAverage
public static double[] simpleMovingAverage(double[] values, int n) {
double[] sums = Arrays.copyOf(values, values.length); // <1>
Arrays.parallelPrefix(sums, Double::sum); // <2>
int start = n - 1;
return IntStream.range(start, sums.length) // <3>
.mapToDouble(i -> {
double prefix = i == start ? 0 : sums[i - n];
return (sums[i] - prefix) / n; // <4>
})
.toArray(); // <5>
}
// END simpleMovingAverage
// BEGIN parallelInitialize
public static double[] parallelInitialize(int size) {
double[] values = new double[size];
Arrays.parallelSetAll(values, i -> i);
return values;
}
// END parallelInitialize
parallelPrefix擅长对时间序列数据做累加,会更新一个数组,将每个元素替换为当前元素和其前驱元素的和(和是一个BinaryOperator,未必一定是加和)。
7 测试、调试和重构
7.1 重构的候选项
- 进进出出、摇摇晃晃
日志isDebugEnabled的例子。如果代码中不断检查和操作某个对象,只是为了最后给它设定一个值,那么这段代码就本该属于你所操作的对象。
- 孤独的覆盖
使用继承,目的只是为了覆盖一个方法。例子就是ThreadLocal。
- 同样的东西写两遍
// 改进前
public long countRunningTime() {
long count = 0;
for (Album album : albums) {
for (Track track : album.getTrackList()) {
count += track.getLength();
}
}
return count;
}
public long countMusicians() {
long count = 0;
for (Album album : albums) {
count += album.getMusicianList().size();
}
return count;
}
public long countTracks() {
long count = 0;
for (Album album : albums) {
count += album.getTrackList().size();
}
return count;
}
// END body
// 改进后
public long countFeature(ToLongFunction function) {
return albums.stream()
.mapToLong(function)
.sum();
}
public long countTracks() {
return countFeature(album -> album.getTracks().count());
}
public long countRunningTime() {
return countFeature(album -> album.getTracks()
.mapToLong(track -> track.getLength())
.sum());
}
public long countMusicians() {
return countFeature(album -> album.getMusicians().count());
}
7.2 lambda表达式的单测
lambda没有名字,无法直接在测试代码中调用。
任何一个lambda表达式都能被改写为普通方法,然后使用方法引用直接引用。
7.3 测试替身
使用Mockito框架
7.4567 流的调试
循环由框架处理,断点没法打,不好调试。用peak。它能查看每个值,同时能继续操作流。还能在其中打断点。
Set nationalities
= album.getMusicians()
.filter(artist -> artist.getName().startsWith("The"))
.map(artist -> artist.getNationality())
.peek(nation -> System.out.println("Found nationality: " + nation))
.collect(Collectors.toSet());
8 设计和架构的原则
8.1 lambda与设计模式
1和2的主要的思想就是如果设计模式中有接口符合函数接口的形式,我们就都可以用lambda表达式替换,甚至直接用方法引用。
8.1.1 命令者模式
8.1.2 策略模式
8.1.3 观察者模式
8.1.4 模板方法
8. lambda与DSL
用不到先不看
8. lambda与SOLID原则
S.O.L.I.D是面向对象设计和编程(OOD&OOP)中几个重要编码原则(Programming Priciple)的首字母缩写。
| SRP | [The Single Responsibility Principle ] | 单一责任原则 |
|---|---|---|
| OCP | [The Open Closed Principle] | 开放封闭原则 |
| LSP | [The Liskov Substitution Principle] | 里氏替换原则 |
| ISP | [The Interface Segregation Principle] | 接口分离原则 |
| DIP | [The Dependency Inversion Principle] | 依赖倒置原则 |
单一责任原则:
当需要修改某个类的时候原因有且只有一个(THERE SHOULD NEVER BE MORE THAN ONE REASON FOR A CLASS TO CHANGE)。换句话说就是让一个类只做一种类型责任,当这个类需要承当其他类型的责任的时候,就需要分解这个类。
开放封闭原则
软件实体应该是可扩展,而不可修改的。也就是说,对扩展是开放的,而对修改是封闭的。这个原则是诸多面向对象编程原则中最抽象、最难理解的一个。
里氏替换原则
当一个子类的实例应该能够替换任何其超类的实例时,它们之间才具有is-A关系
接口分离原则
不能强迫用户去依赖那些他们不使用的接口。换句话说,使用多个专门的接口比使用单一的总接口总要好。
依赖倒置原则
- 高层模块不应该依赖于低层模块,二者都应该依赖于抽象
- 抽象不应该依赖于细节,细节应该依赖于抽象
这几条原则是非常基础而且重要的面向对象设计原则。正是由于这些原则的基础性,理解、融汇贯通这些原则需要不少的经验和知识的积累。上述的图片很好的注释了这几条原则。