nginx+spawn-fcgi+demo+fcgi库函数
由于项目中用到了nginx+FastCGI相关内容,所以这段时间学习了一下,顺便记下相关内容。
我是在远程工作机上实验的,有个缺点就是没有root权限,所以有些步骤我就没做了,比如make install(nginx)、添加到服务管理列表等等,仅在make之后二进制所在目录上进行执行,使用上完全没问题。还有个优点就是有些库已经全部安装好了,比如openssl、zlib等等,少了一些步骤。
一.nginx
1.安装过程:
基本按这篇文章的步骤来:《Nginx安装与使用》,仅仅没有make install。
后半部分也简单介绍了nginx的配置,即conf目录下的文件,重点是nginx.conf。
有个地方要提一下,这篇文章讲了fastcgi_params与fastcgi.conf的关系,这个在很多别的文章里都没有提到,甚至在后面配置FastCGI的时候很多文章实际上都配置错了。关系如下:
fastcgi.conf只比fastcgi_params多了一行“fastcgi_param SCRIPT_FILENAME $document_root$fastcgi_script_name;”
原本只有fastcgi_params文件,fastcgi.conf是nginx 0.8.30 (released: 15th of December 2009)才引入的。主要为是解决以下问题(参考:http://www.dwz.cn/x3GIJ):
原本Nginx只有fastcgi_params,后来发现很多人在定义SCRIPT_FILENAME时使用了硬编码的方式。例如,fastcgi_param SCRIPT_FILENAME /var/www/foo$fastcgi_script_name。于是为了规范用法便引入了fastcgi.conf。
不过这样的话就产生一个疑问:为什么一定要引入一个新的配置文件,而不是修改旧的配置文件?这是因为fastcgi_param指令是数组型的,和普通指令相同的是:内层替换外层;和普通指令不同的是:当在同级多次使用的时候,是新增而不是替换。换句话说,如果在同级定义两次SCRIPT_FILENAME,那么它们都会被发送到后端,这可能会导致一些潜在的问题,为了避免此类情况,便引入了一个新的配置文件。
因此不再建议大家使用以下方式(搜了一下,网上大量的文章,并且nginx.conf的默认配置也是使用这种方式):
fastcgi_param SCRIPT_FILENAME $document_root$fastcgi_script_name;
include fastcgi_params;
而使用最新的方式:
include fastcgi.conf;
2.配置
上面推荐的那篇文章简单介绍了一些配置,但远远不够。
这里推荐这篇文章:《Nginx 反向代理、负载均衡、页面缓存、URL重写及读写分离详解》,正如题目所说,讲了nginx方向代理、负载均衡、页面缓存、URl重写、读写分离等功能的配置,很详细,按上面内容step by step走一遍,基本了解相关配置了。
其中有几个步骤要求修改httpd配置文件、并重启httpd,由于我没有root权限所以没法实验。
二、什么是CGI、FastCGI、PHP-CGI、PHP-FPM、Spawn-FCGI
要学习FastCGI,首先要搞清楚这几个术语,我也稍微整理了一些内容,大概搞懂了它们的关系。
推荐自己整理的文章:《【整理】什么是CGI、FastCGI、PHP-CGI、PHP-FPM、Spawn-FCGI?》
然后就是这张图描述Nginx+FastCGI运行过程: 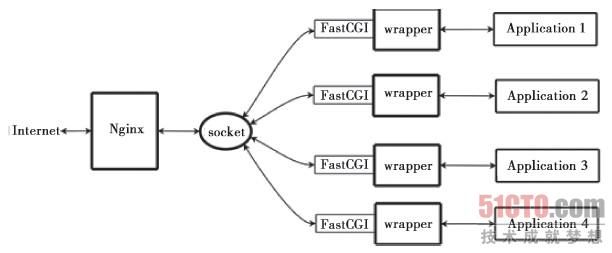
Nginx不支持对外部程序的直接调用或者解析,所有的外部程序(包括PHP)必须通过FastCGI接口来调用。FastCGI接口在Linux下是socket(这个socket可以是文件socket,也可以是ip socket)。为了调用CGI程序,还需要一个FastCGI的wrapper(wrapper可以理解为用于启动另一个程序的程序),这个wrapper绑定在某个固定socket上,如端口或者文件socket。
当Nginx将CGI请求发送给这个socket的时候,通过FastCGI接口,wrapper接收到请求,然后派生出一个新的线程,这个线程调用解释器或者外部程序处理脚本并读取返回数据;接着,wrapper再将返回的数据通过FastCGI接口,沿着固定的socket传递给Nginx;最后,Nginx将返回的数据发送给客户端。这就是Nginx+FastCGI的整个运作过程,如图1所示。
这里我要说下Spawn-FCGI在这种图中的主要功能:打开监听端口,绑定地址,然后fork-exec创建FastCGI进程,退出完成工作。
由于是fork-exec创建子进程,所以子进程能够继承父进程的所有打开句柄,包括监听socket。这样所有子进程都能够在同一个端口上进行监听新连接,谁拿到了谁就处理之。这是Spawn-FCGI最重要的功能。
Spawn-FCGI源码只有600多行,以后有机会可以研究一下。(参考:http://www.it165.net/pro/html/201411/27470.html)
三、spawn-fastcgi的安装
正确步骤是:
1. 解压
2. 如果没有configure,请先执行./autogen.sh,生成configure
3. ./configure
4. make
5. 编译好以后,将可执行文件移动到nginx的二进制所在目录(由于我没有make install,我的nginx二进制在nginx-1.10.1/objs目录下)
但无论下载spawn-fcgi-1.6.4还是spawn-fcgi-1.6.3,执行./autogen.sh时都提示:
configure.ac:4: error: Autoconf version 2.61 or higher is required
configure.ac:4: the top level
autom4te: /usr/bin/m4 failed with exit status: 63
aclocal: autom4te failed with exit status: 63
autoreconf: aclocal failed with exit status: 63
于是下载编译autoconf-2.68,又提示:
checking for GNU M4 that supports accurate traces… configure: error: no acceptable m4 could be found in $PATH.
GNU M4 1.4.6 or later is required; 1.4.16 or newer is recommended.
GNU M4 1.4.15 uses a buggy replacement strstr on some systems.
Glibc 2.9 - 2.12 and GNU M4 1.4.11 - 1.4.15 have another strstr bug.
然后又下载安装m4-1.4.9,make、make install,提示:
/usr/bin/install: cannot create regular file `/usr/local/bin/m4’: Permission denied
make64[2]: * [install-binPROGRAMS] Error 1
也就是说,正常顺序是m4–>autoconf–>spawn-fcgi,由于我没有root权限,无法install m4,导致无法编译spawn-fcgi。
所以这里只是记录下我遇到问题的过程,实际上我并没有解决这个问题。好在我在其他项目工程里找到了spawn_fcgi的二进制,我就假装此步骤已经完成了吧。。。。。
将spawn_fcgi二进制拷贝到nginx二进制所在目录。
四、fcgi库
很多老帖都是发的这个地址:http://www.fastcgi.com/dist/fcgi.tar.gz,实际上现在已经打不开了。
这个地址是可以下载的:ftp://ftp.slackware.com/.2/gentoo/distfiles/fcgi-2.4.0.tar.gz
这个库不是必须的,你可以用其他类似库,也是自己实现。
解压后编译:
./configure
make
在./libfcgi/.libs/目录下生成两个静态库文件:libfcgi.a、libfcgi++.a,后面编译demo的时候需要链接这两个静态库。
然后就是头文件,主要是这几个头文件:fastcgi.h,fcgiapp.h,fcgi_config.h,fcgi_config_x86.h,fcgimisc.h,fcgio.h,fcgios.h,fcgi_stdio.h,最初分布在./和./include目录下,为了后面编译方便,全部放到./include目录下。
五、demo
1. echo_cpp
其实在fcgi库中./examples目录下有好几个例子,我们先快速实现一下,再去细看其中用到的函数。
我用./examples/echo-cpp.cpp为例,编译此源码:
g++ echo-cpp.cpp -I ../include/ -o echo_cpp ../libfcgi/.libs/libfcgi.a ../libfcgi/.libs/libfcgi++.a
生成“echo_cpp”二进制。
将此二进制拷贝到nginx二进制所在目录。
经过上面一系列步骤,nginx、spawn_fcgi、echo_cpp三个二进制是在同一个目录下。
2. 启动spawn_fcgi
启动spawn_fcgi,绑定server IP和端口,注意不要跟nginx的监听端口重合、也不能绑定其他程序已使用的端口,否则会报错,
./spawn_fcgi -f ./echo_cpp -p 19890 -a 12.34.56.78 -F 10
可以用netstat -apn | grep 19890查看端口绑定是否已经成功。
3. 修改nginx.conf
在server节点下增加以下转发规则,即访问的url以.cgi结尾时进行转发:
location ~ \.cgi$ {
fastcgi_pass 12.34.56.78:19890;
fastcgi_index index.cgi;
fastcgi_param SCRIPT_FILENAME fcgi$fastcgi_script_name;
include fastcgi.conf;
}
修改后,nginx重新加载配置文件:
nginx -s reload
4.测试结果
浏览器访问(nginx服务器的ip与port):http://12.34.56.78:8010/xxx.cgi
显示的截图如下(较长,截了一部分): 
六、fcgi库的方法
本节主要参考:《fastcgi中的多线程使用》,有改动。
1. 一个简单的单线程fcgi请求:
#include
\r\n");
printf("Request number %d.", count++);
}
exit(0);
}原理:有一个死循环,一直等待接受请求,有请求过来时,就处理请求,并返回结果,没有并发性。
这里为什么printf输出内容就返回到nginx呢?
因为在fcgi_stdio.h中对printf进行了宏转向,在程序里的printf 不再是标准输出了:
//fcgi_stdio.h
#undef printf
#define printf FCGI_printf除此之外,fcgi_stdio.h中还对很多常见的输入输出函数进行了宏转向,例如stdin,stdout,stderr,fgets,fputs等等。
2. 进入FCGI_Accept(void)
此方法在文件fcgi_stdio.c里
int FCGI_Accept(void)
{
//变量表示是否接收请求。默认为Fasle,不接收请求
if(!acceptCalled) {
//判断是否为cgi,变量为全局静态的,下次还会用。
isCGI = FCGX_IsCGI();
//状态改为接收请求。
acceptCalled = TRUE;
//请求的收尾,将数值清空赋初值。
atexit(&FCGI_Finish);
} else if(isCGI) {
//不是第一次请求,并且是cgi程序。
return(EOF);
}
if(isCGI) {
//cgi的初始赋值操作,不关心。
...
} else {
FCGX_Stream *in, *out, *error;
//char** 字符串数组。
FCGX_ParamArray envp;
//接受请求,这个方法下面介绍
int acceptResult = FCGX_Accept(&in, &out, &error, &envp);
//接收失败,返回<0,这也是为什么在循环上判断是 while(FCGI_Accept() >= 0)
if(acceptResult < 0) {
return acceptResult;
}
//将得到的数据赋值给对应的输出,输入,data。
FCGI_stdin->stdio_stream = NULL;
FCGI_stdin->fcgx_stream = in;
FCGI_stdout->stdio_stream = NULL;
FCGI_stdout->fcgx_stream = out;
FCGI_stderr->stdio_stream = NULL;
FCGI_stderr->fcgx_stream = error;
environ = envp;
}
//结束
return 0;
}通过上面代码可以看出,fcgi库是同时支持CGI和FCGI两种方式的。
返回值:
=0:成功
-1:失败
3. FCGX_Accept (&in, &out, &error, &envp)
等待接收请求的方法,在fcgiapp.c里
static FCGX_Request the_request;
int FCGX_Accept(FCGX_Stream **in,FCGX_Stream **out,FCGX_Stream **err,FCGX_ParamArray *envp)
{
int rc;//定义返回的变量。
//是否初始化过。
if (! libInitialized) {
//FCGX_Init返回0时表示成功
rc = FCGX_Init();
if (rc) {
return rc;
}
}
//接收数据,下面介绍
rc = FCGX_Accept_r(&the_request);
//给对应流和数据赋值。
*in = the_request.in;
*out = the_request.out;
*err = the_request.err;
*envp = the_request.envp;
return rc;
}返回值:
=0:成功
=-1:失败
4. FCGX_Accept_r ()
同在fcgiapp.c里面
/*
*----------------------------------------------------------------------
*
* FCGX_Accept_r --
*
* 从http server 接收一个新的请求
* Results:
* 正确返回0,错误返回-1.
* Side effects:
*
* 通过FCGX_Accept完成请求的接收,创建input,output等流并且各自分配给in
* ,out,err.创建参数数据从FCGX_GetParam中取出,并且给envp。
* 不要保存指针和字符串,他们会在下次请求中的FcGX_Finish中被释放。
*----------------------------------------------------------------------
*/
int FCGX_Accept_r(FCGX_Request *reqDataPtr)
{
if (!libInitialized) {
return -9998;
}
//将当前的reqData完成请求。将内容释放,初始化。
FCGX_Finish_r(reqDataPtr);
//while
for (;;) {
//ipcFd 是双方通讯的管道,在上面的FCGX_Finish_r中被赋值-1。
if (reqDataPtr->ipcFd < 0) {
int fail_on_intr = reqDataPtr->flags & FCGI_FAIL_ACCEPT_ON_INTR;
//接收一次请求,传入socket,没有请求会在这里等待。这里面是重点,可是我看不懂。
reqDataPtr->ipcFd = OS_Accept(reqDataPtr->listen_sock, fail_on_intr, webServerAddressList);
if (reqDataPtr->ipcFd < 0) {
return (errno > 0) ? (0 - errno) : -9999;
}
}
reqDataPtr->isBeginProcessed = FALSE;
reqDataPtr->in = NewReader(reqDataPtr, 8192, 0);
FillBuffProc(reqDataPtr->in);
if(!reqDataPtr->isBeginProcessed) {
goto TryAgain;
}
{
//查看请求类型。
char *roleStr;
switch(reqDataPtr->role) {
case FCGI_RESPONDER:
roleStr = "FCGI_ROLE=RESPONDER";
break;
case FCGI_AUTHORIZER:
roleStr = "FCGI_ROLE=AUTHORIZER";
break;
case FCGI_FILTER:
roleStr = "FCGI_ROLE=FILTER";
break;
default:
goto TryAgain;
}
//创建存储参数QueryString的空间。
reqDataPtr->paramsPtr = NewParams(30);
//将请求类型当做key-value加入参数里。
PutParam(reqDataPtr->paramsPtr, StringCopy(roleStr));
}
//将输入流以制定的方式读取(在哪停止,是否需要跳过请求)
SetReaderType(reqDataPtr->in, FCGI_PARAMS);
//将参数读取写入key=value。
if(ReadParams(reqDataPtr->paramsPtr, reqDataPtr->in) >= 0) {
//跳出循环,否则等下一次请求。
break;
}
//释放这些中间产生的东西。将ipcFd置为-1.
TryAgain:
FCGX_Free(reqDataPtr, 1);
} /* for (;;) */
//将剩下的信息赋值。完成一个请求的开始部分。
SetReaderType(reqDataPtr->in, FCGI_STDIN);
reqDataPtr->out = NewWriter(reqDataPtr, 8192, FCGI_STDOUT);
reqDataPtr->err = NewWriter(reqDataPtr, 512, FCGI_STDERR);
reqDataPtr->nWriters = 2;
reqDataPtr->envp = reqDataPtr->paramsPtr->vec;
return 0;
}注意:很多不同的帖子里有的用FCGX_Accept (void),有的用FCGX_Accept (&in, &out, &error, &envp),有的用FCGX_Accept_r(FCGX_Request *reqDataPtr),感觉很混乱,需要搞清楚他们之间的关系。主要是封装的程度不同,值得一提的是,如果是调用FCGX_Accept_r(FCGX_Request *reqDataPtr),需要先FCGX_Init();,其他两个函数对此内部都已封装。
5. 在接收请求之前执行的FCGX_Finish_r (reqDataPtr)
在fcgiapp.c里
void FCGX_Finish_r(FCGX_Request *reqDataPtr)
{
int close;
if (reqDataPtr == NULL) {
return;
}
close = !reqDataPtr->keepConnection;
if (reqDataPtr->in) {
close |= FCGX_FClose(reqDataPtr->err);
close |= FCGX_FClose(reqDataPtr->out);
close |= FCGX_GetError(reqDataPtr->in);
}
FCGX_Free(reqDataPtr, close);
}基本流程就是这样。
6. 多线程请求的例子
官网多线程的例子,./examples/threaded.c
static int counts[THREAD_COUNT];
static void *doit(void *a)
{
int rc, i, thread_id = (int)a;
pid_t pid = getpid();
FCGX_Request request;
char *server_name;
FCGX_InitRequest(&request, 0, 0);
for (;;)
{
static pthread_mutex_t accept_mutex = PTHREAD_MUTEX_INITIALIZER;
static pthread_mutex_t counts_mutex = PTHREAD_MUTEX_INITIALIZER;
/* Some platforms require accept() serialization, some don't.. */
pthread_mutex_lock(&accept_mutex);
rc = FCGX_Accept_r(&request);
pthread_mutex_unlock(&accept_mutex);
if (rc < 0)
break;
server_name = FCGX_GetParam("SERVER_NAME", request.envp);
FCGX_FPrintF(request.out,
"Content-type: text/html\r\n"
"\r\n"
"FastCGI Hello! (multi-threaded C, fcgiapp library) "
"FastCGI Hello! (multi-threaded C, fcgiapp library)
"
"Thread %d, Process %ld"
"Request counts for %d threads running on host %s"
,
thread_id, pid, THREAD_COUNT, server_name ? server_name : "?");
sleep(2);
pthread_mutex_lock(&counts_mutex);
++counts[thread_id];
for (i = 0; i < THREAD_COUNT; i++)
FCGX_FPrintF(request.out, "%5d " , counts[i]);
pthread_mutex_unlock(&counts_mutex);
FCGX_Finish_r(&request);
}
return NULL;
}
int main(void)
{
int i;
pthread_t id[THREAD_COUNT];
FCGX_Init();
for (i = 1; i < THREAD_COUNT; i++)
pthread_create(&id[i], NULL, doit, (void*)i);
doit(0);
return 0;
}这种多线程模式是main函数起多个线程,每个线程都独立接受请求(需要加锁)。
还有一种是main函数起一个accpet线程接受请求,多个do_session线程处理请求,这种模式需要一个任务队列的支持。
#include <fcgi_stdio.h>
#include <stdlib.h>
#include <pthread.h>
#include <string>
void* do_accept(void *arg);
void* do_session(void *arg);
int main()
{
pthread_t pthread_id;
//接收请求的单独线程
pthread_create(&pthread_id, NULL, do_accept, NULL);
int iThreadNum = 10;
for (int index = 0; index != iThreadNum; ++ index)
{
pthread_t pthread_id;
//多个处理请求的线程
pthread_create(&pthread_id, NULL, do_session, NULL);
}
pthread_join();
return 0;
}
void* do_accept(void *arg)
{
FCGX_Request *request = NULL;
while (1)
{
int rc = FCGX_Accept_r(request);
if (rc < 0)
{
continue;
}
httpRequest.put(request); //httpRequest 是一个生产者消费者模型,此处是放入任务
}
}
void* do_session(void *arg)
{
while(1)
{
FCGX_Request *request = NULL;
while (!request)
{
request = httpRequest.get(); //此处是取出任务,应需要线程安全,此次从简
}
string strRequestMethod;
string strGetData;
string strPostData;
int iPostDataLength;
if (FCGX_GetParam("QUERY_STRING", request->envp))
{
strGetData = FCGX_GetParam("QUERY_STRING", request->envp);
}
if (FCGX_GetParam("REQUEST_METHOD", request->envp))
{
iPostDataLength = ::atoi(FCGX_GetParam("CONTENT_LENGTH", _pRequest->envp));
char* data = (char*)malloc(iPostDataLength + 1);
::memset(data, 0, iPostDataLength + 1);
FCGX_GetStr(data, iPostDataLength, _pRequest->in);
strPostData = data;
free(data);
}
FCGX_PutS("Content-type: text/html\r\n\r\n", _pRequest->out);
FCGX_PutS(strPostData.c_str(), _pRequest->out);
}
}