1. 以用户为基础(User-based)的协同过滤
基于用户的协同过滤算法是通过用户的历史行为数据发现用户对商品或内容的喜欢(如商品购买,收藏,内容评论或分享),并对这些喜好进行度量和打分。根据不同用户对相同商品或内容的态度和偏好程度计算用户之间的关系。在有相同喜好的用户间进行商品推荐。简单的说就是如果A,B两个用户都购买了x,y,z三本图书,并且给出了5星的好评。那么A和B就属于同一类用户。可以将A看过的图书w也推荐给用户B。

1.1 寻找偏好相似的用户
我们模拟了5个用户对两件商品的评分,来说明如何通过用户对不同商品的态度和偏好寻找相似的用户。在示例中,5个用户分别对两件商品进行了评分。这里的分值可能表示真实的购买,也可以是用户对商品不同行为的量化指标。例如,浏览商品的次数,向朋友推荐商品,收藏,分享,或评论等等。这些行为都可以表示用户对商品的态度和偏好程度。
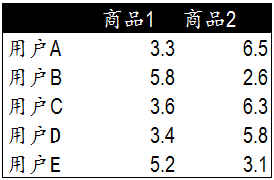
从表格中很难直观发现5个用户间的联系,我们将5个用户对两件商品的评分用散点图表示出来后,用户间的关系就很容易发现了。在散点图中,Y轴是商品1的评分,X轴是商品2的评分,通过用户的分布情况可以发现,A,C,D三个用户距离较近。用户A(3.3 6.5)和用户C(3.6 6.3),用户D(3.4 5.8)对两件商品的评分较为接近。而用户E和用户B则形成了另一个群体。
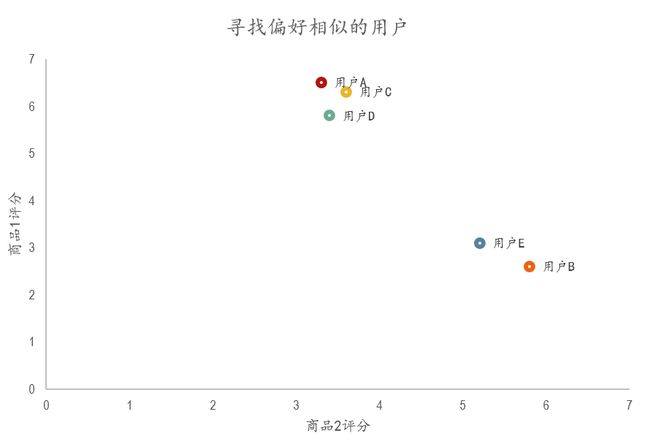
散点图虽然直观,但无法投入实际的应用,也不能准确的度量用户间的关系。因此我们需要通过数字对用户的关系进行准确的度量,并依据这些关系完成商品的推荐。
1.2 相似度计算
1.2.1 欧几里德距离评价
欧几里德距离评价是一个较为简单的用户关系评价方法。原理是通过计算两个用户在散点图中的距离来判断不同的用户是否有相同的偏好。以下是欧几里德距离评价的计算公式。
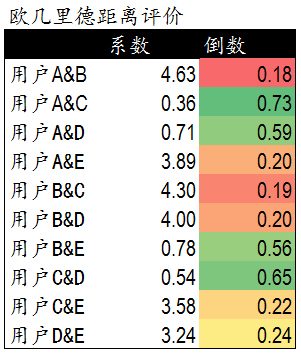
通过公式我们获得了5个用户相互间的欧几里德系数,也就是用户间的距离。系数越小表示两个用户间的距离越近,偏好也越是接近。为了相似性与数值呈正相关,我们对求得的系数取倒数,使用户间的距离约接近,数值越大。在下面的表格中,可以发现,用户A&C用户A&D和用户C&D距离较近。同时用户B&E的距离也较为接近。与我们前面在散点图中看到的情况一致。
1.2.2 皮尔逊相关度评价
皮尔逊相关度评价是另一种计算用户间关系的方法。他比欧几里德距离评价的计算要复杂一些,但对于评分数据不规范时皮尔逊相关度评价能够给出更好的结果。以下是一个多用户对多个商品进行评分的示例。这个示例比之前的两个商品的情况要复杂一些,但也更接近真实的情况。我们通过皮尔逊相关度评价对用户进行分组,并推荐商品。

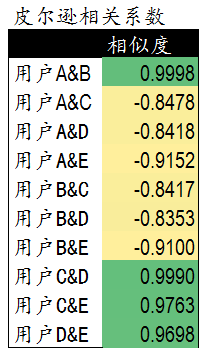
通过计算5个用户对5件商品的评分我们获得了用户间的相似度数据。这里可以看到用户A&B,C&D,C&E和D&E之间相似度较高。下一步,我们可以依照相似度对用户进行商品推荐。
1.3 为用户推荐商品
当我们需要对用户C推荐商品时,首先我们检查之前的相似度列表,发现用户C和用户D和E的相似度较高。换句话说这三个用户是一个群体,拥有相同的偏好。因此,我们可以对用户C推荐D和E的商品。但这里有一个问题。我们不能直接推荐前面商品1-商品5的商品。因为这这些商品用户C以及浏览或者购买过了。不能重复推荐。因此我们要推荐用户C还没有浏览或购买过的商品。

1.4 算法优缺点
1.4.1 算法缺点
1. 数据稀疏性。一个大型的电子商务推荐系统一般有非常多的物品,用户可能买的其中不到1%的物品,不同用户之间买的物品重叠性较低,导致算法无法找到一个用户的邻居,即偏好相似的用户。
2. 算法扩展性。最近邻居算法的计算量随着用户和物品数量的增加而增加,不适合数据量大的情况使用。
1.5 python实现基于user的协同过滤算法:
import numpy as np
from math import sqrt
class Recommender:
# data: 数据集,这里指users_rating
# k: 表示得出最相近的k的近邻
# sim_func: 表示使用计算相似度
# n: 表示推荐的item的个数
def __init__(self, data, k = 3, sim_func='pearson', n=12):
# 数据初始化
self.k = k
self.n = n
self.sim_func = sim_func
if self.sim_func == 'pearson':
self.fn = self.pearson_sim
if type(data).__name__ == 'dict':
self.data = data
#pearson相似度
def pearson_sim(self, rating1, rating2):
sum_x = 0
sum_y = 0
sum_xy = 0
sum_x2 = 0
sum_y2 = 0
n = 0
for key in rating1:
if key in rating2:
n += 1
x = rating1[key]
y = rating2[key]
sum_x += x
sum_y += y
sum_xy += x * y
sum_x2 += pow(x, 2)
sum_y2 += pow(y, 2)
if n == 0:
return 0
dinominator = sqrt(n * sum_x2 - pow(sum_x, 2)) * sqrt(n * sum_y2 - pow(sum_y, 2))
if dinominator == 0:
return 0
else:
return (n * sum_xy - sum_x * sum_y) / dinominator
#对用户相似度排序
def user_sim_sort(self, user_id):
distances = []
for instance in self.data:
if instance != user_id:
dis = self.fn(self.data[user_id], self.data[instance])
distances.append((instance, dis))
distances.sort(key=lambda items: items[1], reverse=True)
return distances
# recommand主体函数
def recommand(self, user_id):
# 定义一个字典,用来存储推荐的电影和分数
recommendations = {}
# 计算出user与其它所有用户的相似度,返回一个list
user_sim = self.user_sim_sort(user_id)
# 计算最近的k个近邻的总距离
total_dis = 0.0
for i in range(self.k):
total_dis += user_sim[i][1]
if total_dis == 0.0:
total_dis = 1.0
# 将与user最相近的k个人中user没有看过的书推荐给user,并且这里又做了一个分数的计算排名
for i in range(self.k):
# 第i个人的id
neighbor_id = user_sim[i][0]
# 第i个人与user的相似度转换到[0, 1]之间
weight = user_sim[i][1] / total_dis
# 第i个用户看过的书和相应的打分
neighbor_ratings = self.data[neighbor_id]
user_rating = self.data[user_id]
for item_id in neighbor_ratings:
if item_id not in user_rating:
if item_id not in recommendations:
recommendations[item_id] = neighbor_ratings[item_id] * weight
else:
recommendations[item_id] = recommendations[item_id] + neighbor_ratings[item_id] * weight
recommendations = list(recommendations.items())
# 做了一个排序
recommendations.sort(key=lambda items: items[1], reverse=True)
return recommendations[:self.n], user_sim
if __name__ == "__main__":
# 获取数据
users_rating = dict()
data_path = "./ratings.csv"
with open(data_path, 'r') as file:
for line in file:
items = line.strip().split(',')
if items[0] not in users_rating:
users_rating[items[0]] = dict()
users_rating[items[0]][items[1]] = dict()
users_rating[items[0]][items[1]] = float(items[2])
user_id = '1'
recomm = Recommender(users_rating)
recommendations, user_sim = recomm.recommand(user_id)
print("movie id list:", recommendations)
print("near list:", user_sim[:15])
数据集链接:https://pan.baidu.com/s/14VwSvGHsNTqHeeuyG5Og1Q 密码:1e97
2 基于物品的协同过滤算法(item-based collaborative filtering)
基于物品的协同过滤算法与基于用户的协同过滤算法很像,将商品和用户互换。通过计算不同用户对不同物品的评分获得物品间的关系。基于物品间的关系对用户进行相似物品的推荐。这里的评分代表用户对商品的态度和偏好。简单来说就是如果用户A同时购买了商品1和商品2,那么说明商品1和商品2的相关度较高。当用户B也购买了商品1时,可以推断他也有购买商品2的需求。

2.1 寻找相似的物品
表格中是两个用户对5件商品的评分。在这个表格中我们用户和商品的位置进行了互换,通过两个用户的评分来获得5件商品之间的相似度情况。单从表格中我们依然很难发现其中的联系,因此我们选择通过散点图进行展示。

在散点图中,X轴和Y轴分别是两个用户的评分。5件商品按照所获的评分值分布在散点图中。我们可以发现,商品1,3,4在用户A和B中有着近似的评分,说明这三件商品的相关度较高。而商品5和2则在另一个群体中。

2.2 相似度评价
2.2.1 欧几里德距离评价
在基于物品的协同过滤算法中,我们依然可以使用欧几里德距离评价来计算不同商品间的距离和关系。以下是计算公式。
通过欧几里德系数可以发现,商品间的距离和关系与前面散点图中的表现一致,商品1,3,4距离较近关系密切。商品2和商品5距离较近。

2.2.2 皮尔逊相关度评价
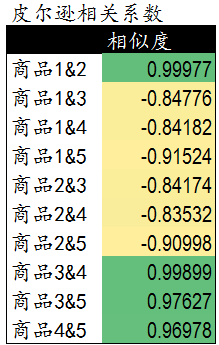
我们选择使用皮尔逊相关度评价来计算多用户与多商品的关系计算。下面是5个用户对5件商品的评分表。我们通过这些评分计算出商品间的相关度。

通过计算可以发现,商品1&2,商品3&4,商品3&5和商品4&5相似度较高。下一步我们可以依据这些商品间的相关度对用户进行商品推荐。
2.3 为用户提供基于相似物品的推荐
这里我们遇到了和基于用户进行商品推荐相同的问题,当需要对用户C基于商品3推荐商品时,需要一张新的商品与已有商品间的相似度列表。在前面的相似度计算中,商品3与商品4和商品5相似度较高,因此我们计算并获得了商品4,5与其他商品的相似度列表。

以下是通过计算获得的新商品与已有商品间的相似度数据。
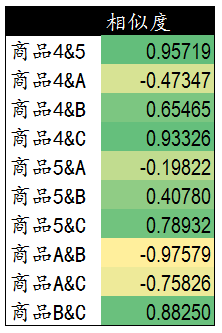
加权排序推荐,这里是用户C已经购买过的商品4,5与新商品A,B,C直接的相似程度。我们将用户C对商品4,5的评分作为权重。对商品A,B,C进行加权排序。用户C评分较高并且与之相似度较高的商品被优先推荐。

2.4 python实现基于item的协同过滤
from math import sqrt
class ItemBasedCF:
def __init__(self, train_file):
self.train_file = train_file
self.read_data()
# 读取文件,并生成用户-物品的评分表和测试集
def read_data(self):
self.train = dict()
for line in open(self.train_file):
user_id, item_id, score = line.strip().split(',')
self.train.setdefault(user_id, {})
self.train[user_id][item_id] = int(float(score))
# 建立物品-物品的共现矩阵
def item_sim(self):
C = dict() #物品-物品的共现矩阵
N = dict() #物品被多少个不同用户购买
for user, items in self.train.items():
for i in items.keys():
N.setdefault(i, 0)
N[i] += 1
C.setdefault(i, {})
for j in items.keys():
if i == j :
continue
if j not in C[i].keys():
C[i].setdefault(j, 0)
C[i][j] += 1
#计算相似度矩阵
self.W = dict()
for i,related_items in C.items():
self.W.setdefault(i,{})
for j,cij in related_items.items():
# 余弦相似度
self.W[i][j] = cij / (sqrt(N[i] * N[j]))
return self.W
#给用户user推荐,前K个相关用户
def recommend(self,user,K=3,N=10):
rank = dict()
action_item = self.train[user] #用户user产生过行为的item和评分
for item,score in action_item.items():
for j,wj in sorted(self.W[item].items(),key=lambda x:x[1],reverse=True)[0:K]:
if j in action_item.keys():
continue
if j not in rank.keys():
rank.setdefault(j,0)
rank[j] += score * wj
return dict(sorted(rank.items(),key=lambda x:x[1],reverse=True)[0:N])
if __name__ == "__main__":
CF = ItemBasedCF('./ratings.csv')
CF.item_sim()
recomm_dic = CF.recommend('1')
for k,v in recomm_dic.iteritems():
print(k,"\t",v)
4. 协同过滤优缺点
4.1 优点
以用户的角度来推荐的协同过滤系统有下列优点:
能够过滤机器难以自动内容分析的信息,如艺术品,音乐等。
共享其他人的经验,避免了内容分析的不完全或不精确,并且能够基于一些复杂的,难以表述的概念(如信息质量、个人品味)进行过滤。
有推荐新信息的能力。可以发现内容上完全不相似的信息,用户对推荐信息的内容事先是预料不到的。可以发现用户潜在的但自己尚未发现的兴趣偏好。
推荐个性化、自动化程度高。能够有效的利用其他相似用户的反馈信息。加快个性化学习的速度。
4.2 缺点
虽然协同过滤作为一推荐机制有其相当的应用,但协同过滤仍有许多的问题需要解决。整体而言,最典型的问题有
新用户问题(New User Problem) 系统开始时推荐质量较差
新项目问题(New Item Problem) 质量取决于历史数据集
稀疏性问题(Sparsity)
系统延伸性问题(Scalability)。
Reference:
1.《推荐系统》基于用户和Item的协同过滤算法的分析与实现(Python)