k8s(一)简介及部署
kubernetes简介
●在Docker 作为高级容器引擎快速发展的同时,在Google内部,容器技术已经应用了很多年,Borg系统运行管理着成千上万的容器应用。
●Kubernetes项目来源于Borg, 可以说是集结了Borg设计思想的精华,并且吸收了Borg系统中的经验和教训。
●Kubernetes对计算资源进行了更高层次的抽象,通过将容器进行细致的组合,将最终的应用服务交给用户。
●Kubernetes的好处: .
●隐藏资源管理和错误处理,驴仅需要关注应用的开发。
●服务高可用、可靠。
●可将负载运行在由成千上万的机器联合而成的集群中。
设计架构

Kubernetes主要由以下几个核心组件组成:
etcd:保存了整个集群的状态
piserver:提供了资源操作的唯一-入口, 并提供认证、授权、访问控制、API注册和发现等机制
controller manager:负责维护集群的状态,比如故障检测、自动扩展、滚动更新等
scheduler:负责资源的调度,按照预定的调度策略将Pod调度到相应的机器上
kubelet: 负责维护容器的生命周期, 同时也负责Volume (CVI)和网络(CNI)的管理
Container runtime:负责镜像管理以及Pod和容器的真正运行(CRI)
kube-proxy: 负责为Service提供cluster内部的服务发现和负载均衡,
除了核心组件,还有一些推荐的Add-ons:
kube-dns: 负责为整个集群提供DNS服务
Ingress Controller:为服务提供外网入口
Heapster: 提供资源监控
Dashboard:提供GUI
Federation:提供跨可用区的集群
Fluentd-elasticsearch:提供集群日志采集、存储与查询
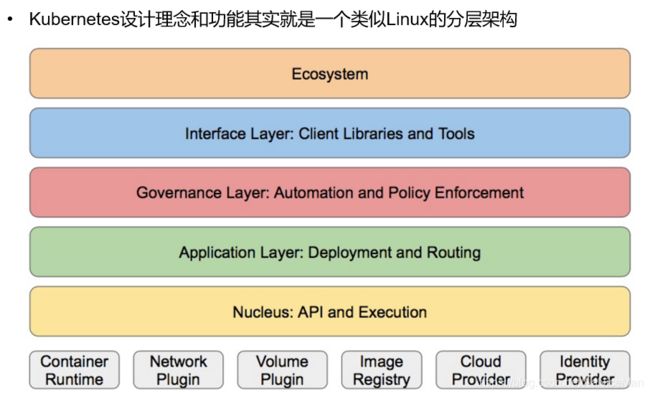
●核心层: Kubernetes最核心的功能, 对外提供API构建高层的应用,对内提供插件式应用执行环境
●应用层:部署(无状态应用、有状态应用、批处理任务、集群应用等)和路由(服务发现、DNS解析等)
●管理层:系统度量(如基础设施、容器和网络的度量),自动化(如自动扩展、动态Provision等)以及策略管理(RBAC、 Quota、 PSP、NetworkPolicy等 )
●接口层: kubectl命令行工具、 客户端SDK以及集群联邦,
●生态系统:在接口层之上的庞大容器集群管理调度的生态系统,可以划分为两个范畴
1 Kubernetes外部:日志、监控、配置管理、CI、 CD、Workflow、 FaaS、 OTS应用、ChatOps等
2 Kubernetes内部: CRI、 CNI、 CVI、 镜像仓库、Cloud Provider、集群自身的配置和管理等
Kubernetes的一些重要概念
cluster:cluster是 计算、存储和网络资源的集合,k8s利用这些资源运行各种基于容器的应用。
master:master是cluster的大脑,他的主要职责是调度,即决定将应用放在那里运行。master运行linux操作系统,可以是物理机或者虚拟机。为了实现高可用,可以运行多个master。
node:node的职责是运行容器应用。node由master管理,node负责监控并汇报容器的状态,同时根据master的要求管理容器的生命周期。node运行在linux的操作系统上,可以是物理机或者是虚拟机。
pod:pod是k8s的最小工作单元。每个pod包含一个或者多个容器。pod中的容器会作为一个整体被master调度到一个node上运行。
controller:k8s通常不会直接创建pod,而是通过controller来管理pod的。controller中定义了pod的部署特性,比如有几个剧本,在什么样的node上运行等。为了满足不同的业务场景,k8s提供了多种controller,包括deployment、replicaset、daemonset、statefulset、job等。
deployment:是最常用的controller。deployment可以管理pod的多个副本,并确保pod按照期望的状态运行。
replicaset实现了pod的多副本管理。使用deployment时会自动创建replicaset,也就是说deployment是通过replicaset来管理pod的多个副本的,我们通常不需要直接使用replicaset。
daemonset:用于每个node最多只运行一个pod副本的场景。正如其名称所示的,daemonset通常用于运行daemon。
statefuleset:能够保证pod的每个副本在整个生命周期中名称是不变的,而其他controller不提供这个功能。当某个pod发生故障需要删除并重新启动时,pod的名称会发生变化,同时statefulset会保证副本按照固定的顺序启动、更新或者删除。
job:用于运行结束就删除的应用,而其他controller中的pod通常是长期持续运行的。
service:
deployment可以部署多个副本,每个pod 都有自己的IP,外界如何访问这些副本那?
答案是service
k8s的 service定义了外界访问一组特定pod的方式。service有自己的IP和端口,service为pod提供了负载均衡。
k8s运行容器pod与访问容器这两项任务分别由controller和service执行。
namespace:可以将一个物理的cluster逻辑上划分成多个虚拟cluster,每个cluster就是一个namespace。不同的namespace里的资源是完全隔离的。
k8s的部署
(1)实验环境
| server1(172.25.254.10) | harbor仓库 |
|---|---|
| server2(172.25.254.20) | master |
| server3(172.25.254.30) | node1 |
| server4(172.25.254.40) | node2 |
关闭上述主机的防火墙,selinx,设置每台主机可以上网
要求集群主机时间同步
每台主机做好解析和免密
每台主机最好加上网关能上网
所有节点都需要安装docker 每个节点都需要使docker开机自启
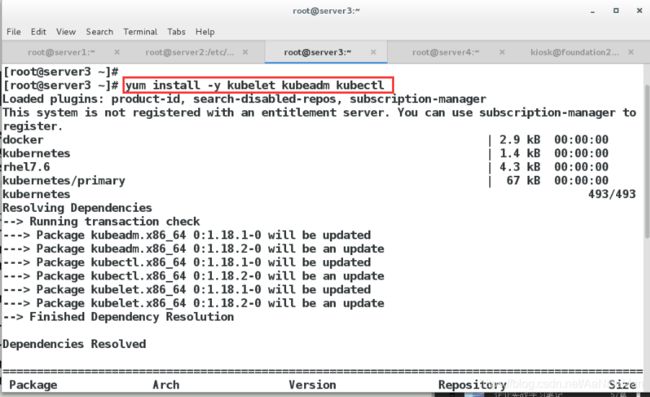
安装 kubelet、kubeadm 和 kubectl
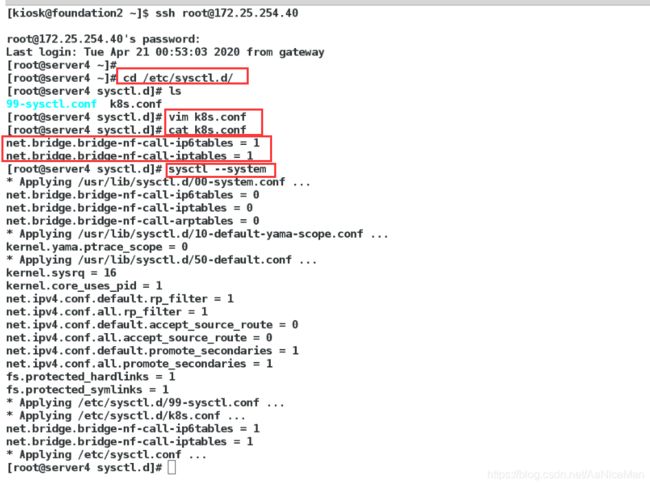
(2)server4节点是新开的虚拟机,要保证打开内置的桥功能,这个是借助于iptables来实现的
server123都开过了
cat < /etc/sysctl.d/k8s.conf
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
EOF
sysctl --system
(3)配置k8s的yum文件
每台主机都要配置
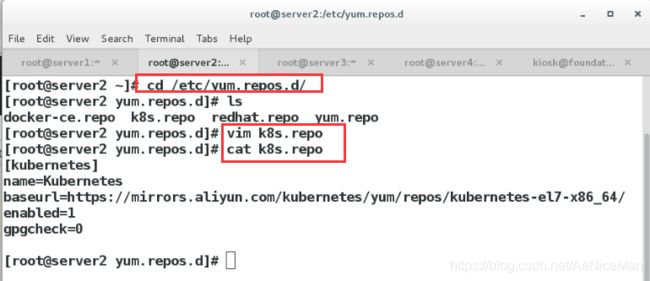
把yum源文件传给server3和server4

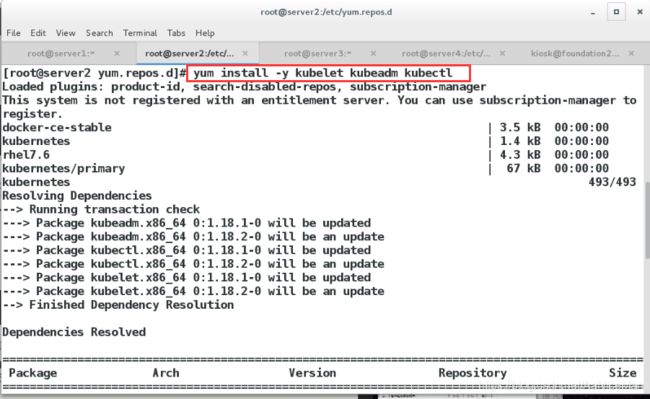
(4)安装 kubelet、kubeadm 和 kubectl(所有节点执行)
kubelet 运行在 Cluster 所有节点上,负责启动 Pod 和容器。
kubeadm 用于初始化 Cluster。
kubectl 是 Kubernetes 命令行工具。通过 kubectl 可以部署和管理应用,查看各种资源,创建、删除和更新各种组件。

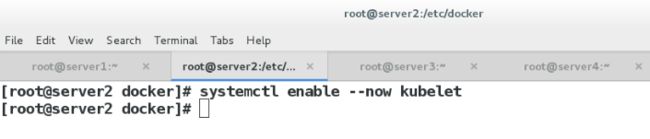
(5)启动kubelet
此时,还不能启动kubelet,因为此时配置还不能,现在仅仅可以设置开机自启动
每个主机执行:systemctl enable --now kubelet


用 kubeadm 创建 Cluster
(1)删除docker machine添加的认证文件
由于之前server2 和server3 是由docker machine添加的主机因此需要将认证文件删除
[root@server2 ~]# cd /etc/systemd/system/docker.service.d/
[root@server2 docker.service.d]# ls
10-machine.conf
[root@server2 docker.service.d]# rm -f 10-machine.conf
[root@server3 ~]# cd /etc/systemd/system/docker.service.d/
[root@server3 docker.service.d]# rm -f 10-machine.conf
若没有该文件跳过此步。
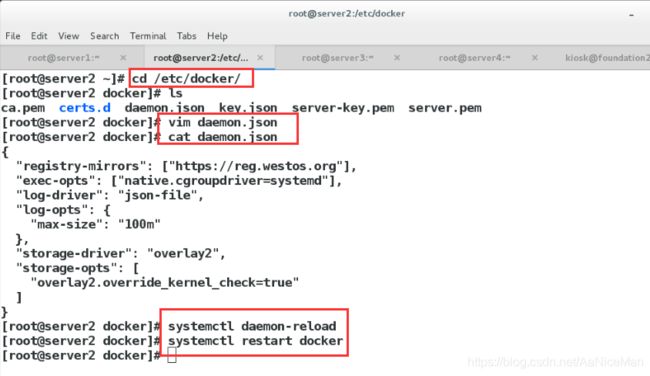
(2)将docker的cgroup驱动更改为systemd
每个节点都需要设置
[root@server2 ~]# vim /etc/docker/daemon.json
[root@server2 ~]# cat /etc/docker/daemon.json
{
"registry-mirrors": ["https://reg.westos.org"], #私有仓库
"exec-opts": ["native.cgroupdriver=systemd"],
"log-driver": "json-file",
"log-opts": {
"max-size": "100m"
},
"storage-driver": "overlay2",
"storage-opts": [
"overlay2.override_kernel_check=true"
]
}
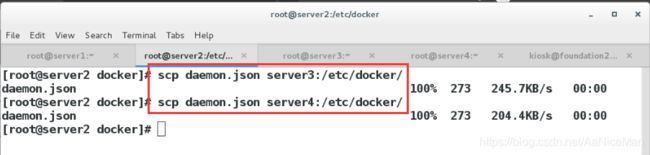
给server34发一份并重启


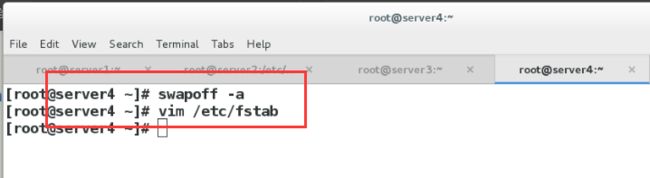
(3)需要禁止各个节点启用swap,如果启用了swap,那么kubelet就无法启动
[root@server1 ~]# swapoff -a
之后更改/etc/fstab文件将swap那一行注释掉即可实现永久关闭


server34一样

(4)拉取镜像初始化
kubeadm config print init-defaults//查看默认配置信息
默认从k8s.gcr.io.上下载组件镜像,需要才可以,所以需要修改镜像仓库:
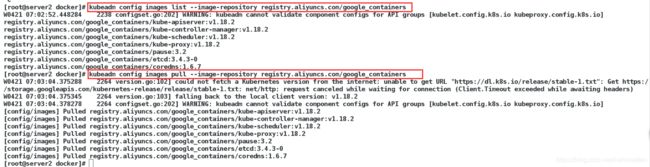
kubeadm config images list -image-repository registry.aliyuncs.com/googl_ containers /列出所需镜像
kubeadm config images pull -image-repository registry.aliyuncs.com/googl_ containers //拉取镜像
kubeadm init -pod-network- cidr=10.244.0.0/16 -image-repository registry.aliyuncs.com/google_containers /初始化集群
--pod-network-cidr= 10.244.0.0/16 //使用flannel网络组件时必须添加
●--kubernetes-version /指定k8s安装版本
初始化
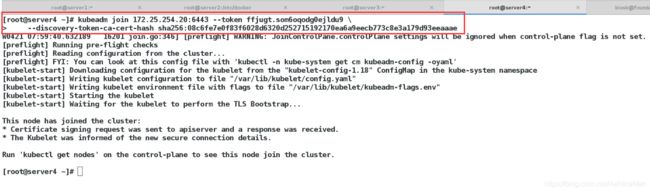
[root@server1 ~]# kubeadm init --image-repository registry.aliyuncs.com/google_containers --kubernetes-version v1.18.2 --pod-network-cidr=10.244.0.0/16
![]()

初始化成功
成功后注意最后一个命令,这个join命令可以用来添加节点
如果初始化失败,请使用如下代码清除后重新初始化# kubeadm reset
(5)添加节点

配置kubectl
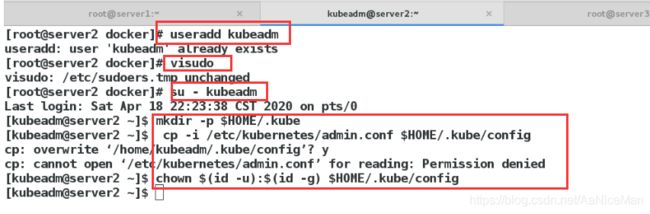
kubectl 是管理 Kubernetes Cluster 的命令行工具,前面我们已经在所有的节点安装了 kubectl。Master 初始化完成后需要做一些配置工作,然后 kubectl 就能使用了。
[root@server1 ~]# mkdir -p $HOME/.kube
[root@server1 ~]# cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
[root@server1 ~]# chown $(id -u):$(id -g) $HOME/.kube/config
为了使用更便捷,启用 kubectl 命令的自动补全功能。
[root@server1 ~]# echo "source <(kubectl completion bash)" >> ~/.bashrc

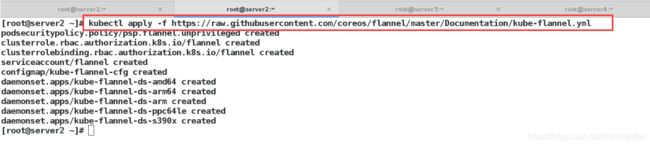
安装pod网络
要让 Kubernetes Cluster 能够工作,必须安装 Pod 网络,否则 Pod 之间无法通信。
每个节点启动kubelet
systemctl restart kubelet
之前镜像下载完成,看到node的状态是ready了



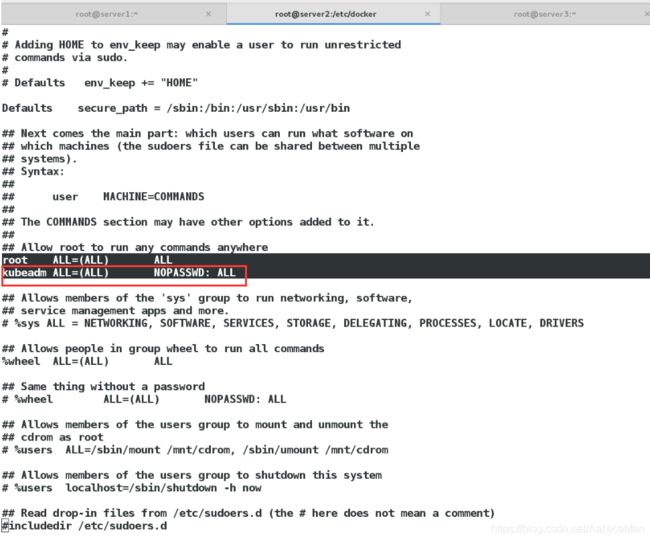
·master节点创建普通用户管理集群,如果需要让普通用户可以运行 kubectl,运行如下命令,这也是 kubeadm init 输出的一部分
学习仿照如下:





