Linux企业运维——Redis的安装部署及主从复制、master自动切换,redis、mysql读写分离
目录
- 一、Redis是什么
- 二、redis的安装部署
- 三、redis主从复制
- 四、Sentine主从自动切换
-
- 1.配置sentinel文件
- 2.master自动切换
- 五、redis的集群cluster
-
- 集群原理
- 1.集群构建
-
- 手动构建集群
- 脚本构建集群
- 2.节点主从自动切换
- 3.添加节点和分片
- 六、Redis+Mysql读写分离
- 七、redis如何与mysql保持数据一致
-
- Gearman原理
- 配置gearmand
一、Redis是什么
Redis是现在最受欢迎的NoSQL数据库之一,Redis是一个使用ANSI C编写的开源、包含多种数据结构、支持网络、基于内存、可选持久性的键值对存储数据库,其具备如下特性:
基于内存运行,性能高效
支持分布式,理论上可以无限扩展
key-value存储系统
开源的使用ANSI C语言编写、遵守BSD协议、支持网络、可基于内存亦可持久化的日志型、Key-Value数据库,并提供多种语言的API
相比于其他数据库类型,Redis具备的特点是:
C/S通讯模型
单进程单线程模型
丰富的数据类型
操作具有原子性
持久化
高并发读写
支持lua脚本
二、redis的安装部署
server1配置redis
下载 redis-6.2.4.tar.gz 压缩包,解压安装
lftp 172.25.254.250
cd /pub/docs/redis
get redis-6.2.4.tar.gz
tar zxf redis-6.2.4.tar.gz
cd redis-6.2.4
make #测试安装,根据报错缺少什么安装什么
make的时候如果报错下载需要的依赖性插件后需要删除压缩包重新解压安装,否则会有之前的缓存
make install #安装
cd utils
vim install_server.sh #修改安装脚本,注释调脚本关于systemd的if语句,否则执行此脚本汇报错
./install_server.sh #执行脚本,根据交互界面一直回车即可
vim install_server.sh

脚本执行成功界面,安装成功
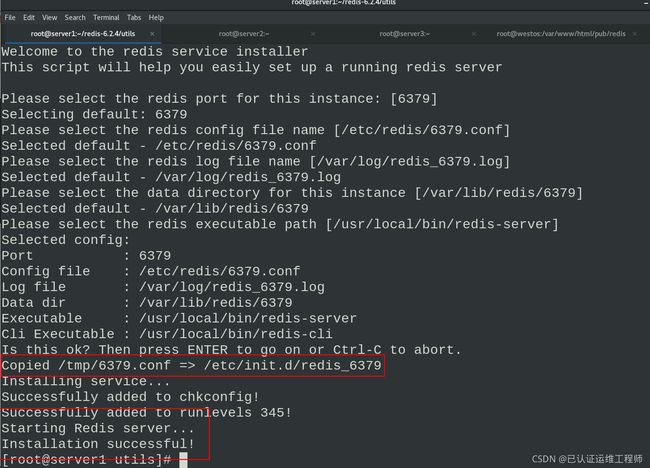
安装成功,可以通过绝对路径启动服务
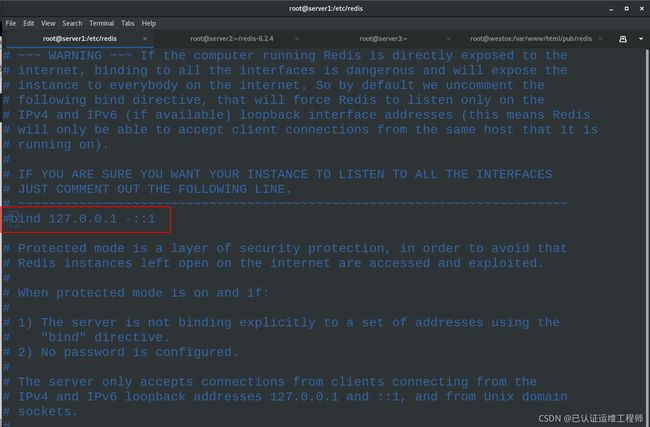
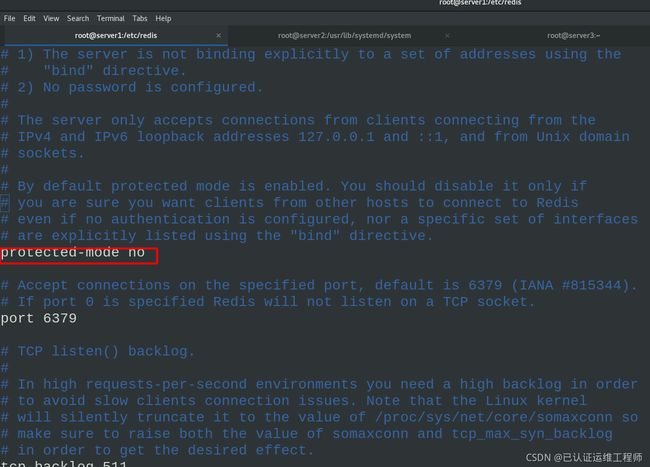
vim /etc/redis/6379.conf #编辑配置文件,注释回环接口,关闭保护模式
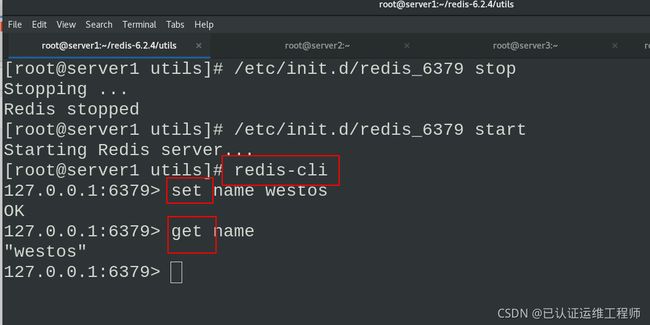
/etc/init.d/redis_6379 stop #停止
/etc/init.d/redis_6379 start #启动数据库
redis-cli #进入redis数据库
set name westos #建立数据
get name #得到数据
/etc/redis/6379.conf
启动进入redis数据库
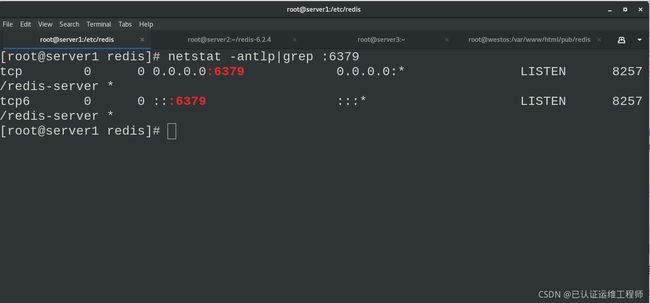
查看开放端口
netstat -antlp|grep :6379
server2配置redis
下载编译安装
scp -r redis-6.2.4.tar.gz server2: #server1直接将解压好的mulu 传输给server2
因为redis是c语言开发的,所以需要下载gcc进行安装编译
yum install -y gcc #下载gcc
yum install -y systemd-devel
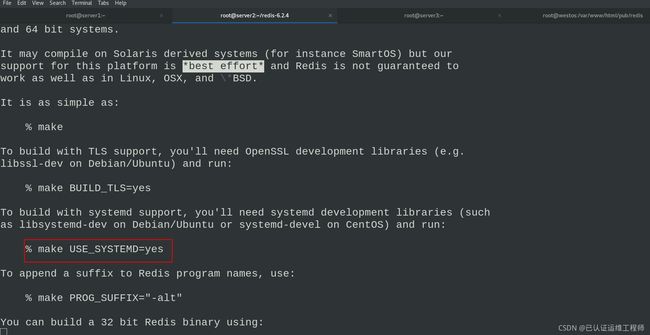
vim README.md #查看使用手册,可以发现如果服务需要用刀systemd,make时需要添加参数USE_SYSTEMD=yes
make USE_SYSTEMD=yes #redis使用systemd守护进程
make install #安装
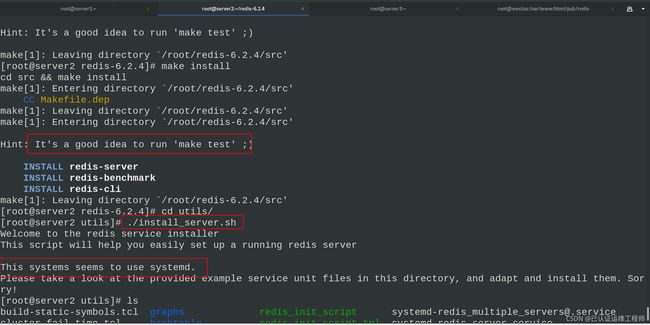
./install_server.sh
vim /etc/redis/6379.conf
README.md
安装完成——如下图!!
编辑相关配置文件
cd redis-6.2.4/
cd utils
cp systemd-redis_server.service /usr/lib/systemd/system/redis.service
cd /usr/lib/systemd/system
vim redis.service
\\\
[Service]
ExecStart=/usr/local/bin/redis-server /etc/redis/redis.conf
Type=forking
\\\
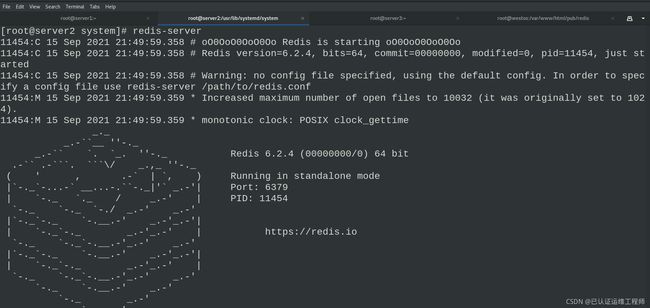
redis-server #查看redis数据库信息
cd /root/redis-6.2.4
mkdir /etc/redis
cp redis.conf /etc/redis/
vim /etc/redis/redis.conf #编辑主配置文件
\\\
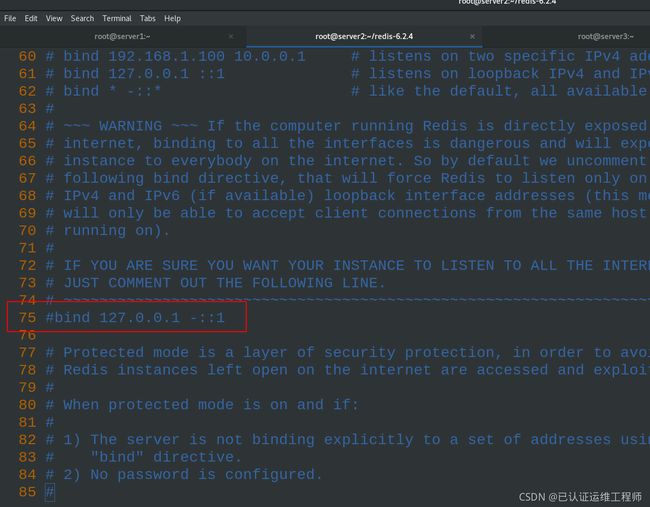
75 #bind 127.0.0.1 -::1 #注释本机连接,即允许其他株距连接redis
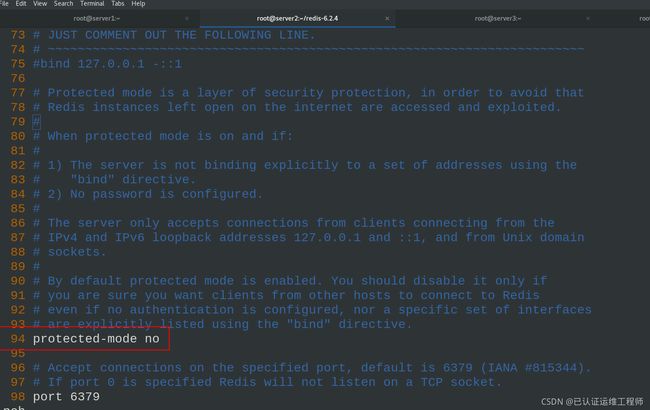
94 protected-mode no #yes改为no,关闭保护模式
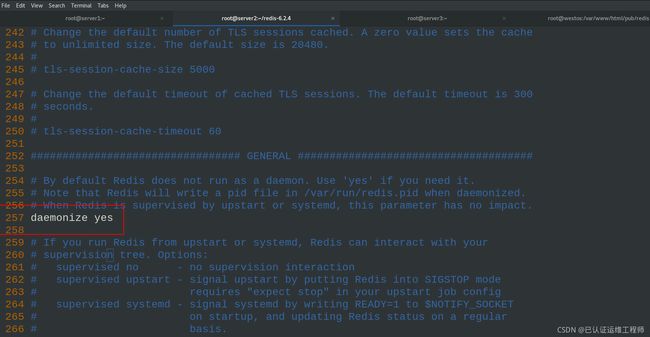
257 daemonize yes #no改为yes,以守护进程的方式运行
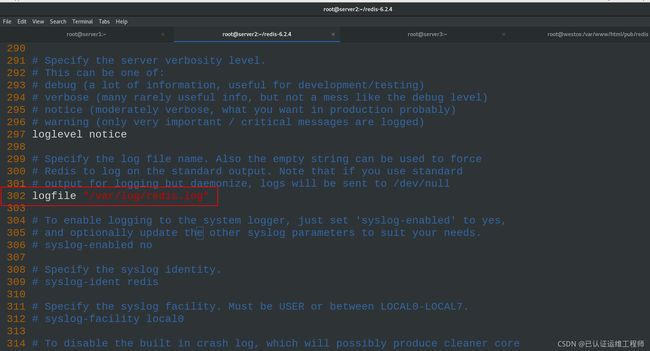
302 logfile "/var/log/redis.log" #logfile日志文件存放路径
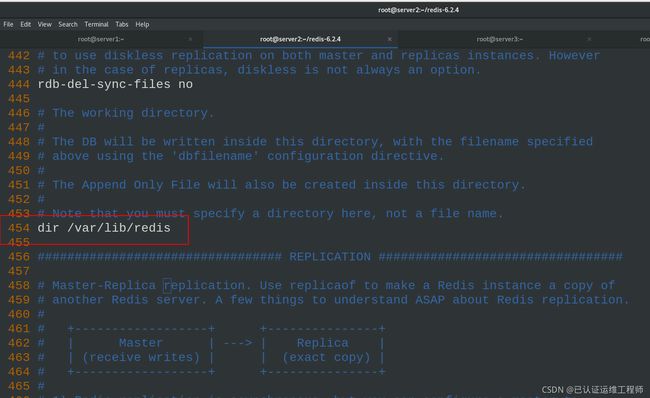
454 dir /var/lib/redis #文件路径
\\\
mkdir /var/lib/redis #建立配置文件所编辑的相应路径下的目录
systemctl daemon-reload #重载
systemctl start redis.service #systemctl开启服务
修改service文件,除了ExecStart和Type=forking这两行,其他都注释

redis-server #查看redis数据库信息
vim /etc/redis/redis.conf #编辑主配置文件
server3配置redis
server3的redis配置和server1相同
scp -r redis-6.2.4 server3: #在server1将解压国的redis目录拷贝过来即可
由于目录已经make安装测试过的,所以这里可以直接安装make install(也可以传输压缩包到server2,然后按照server1的流程安装即可)
因为redis是c语言开发的,所以需要下载gcc进行安装编译
yum install -y gcc #下载gcc
cd redis-6.2.4/
make install
cd utils/
./install_server.sh
/etc/init.d/redis_6379 start #开启redis
vim /etc/redis/6379.conf
\\\
#bind 127.0.0.1 -::1
protected-mode no
\\\
三、redis主从复制
设置redis一主两从,server1为master,server2、server3为slave
分别在/etc/redis/redis.conf中编辑加入master信息即可
在server2中
vim /etc/redis/redis.conf
在最后一行添加master信息
slaveof 172.25.7.1 6379 (当前主机为172.25.7.1,从机端口为6379)
在server3中
vim /etc/redis/6379.conf
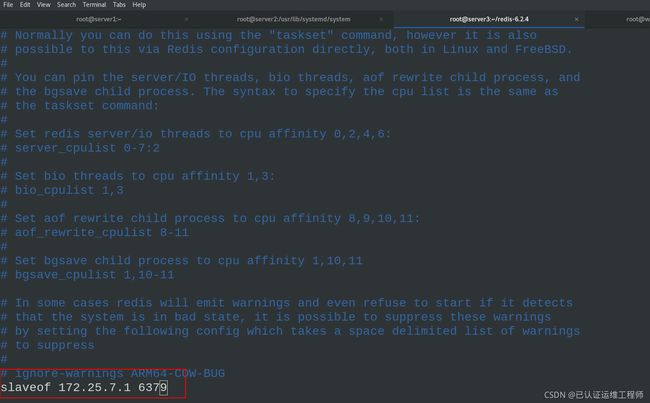
此时,主从配置完毕
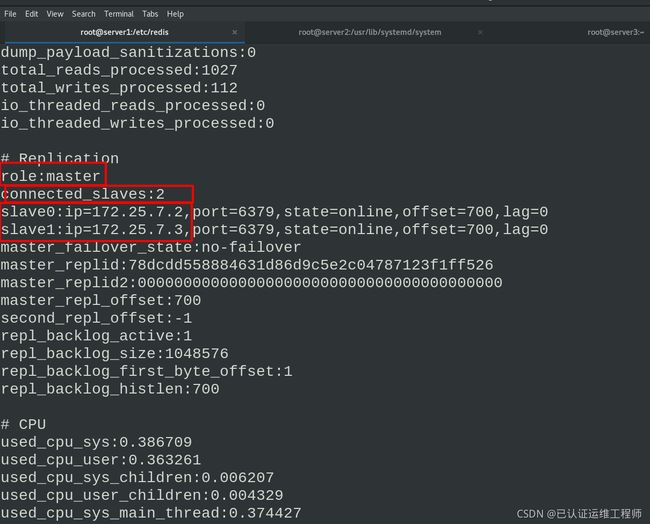
在server1中,进入redis
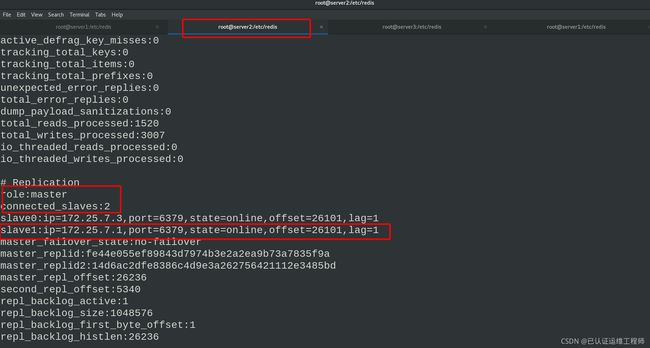
info 查看master状态信息
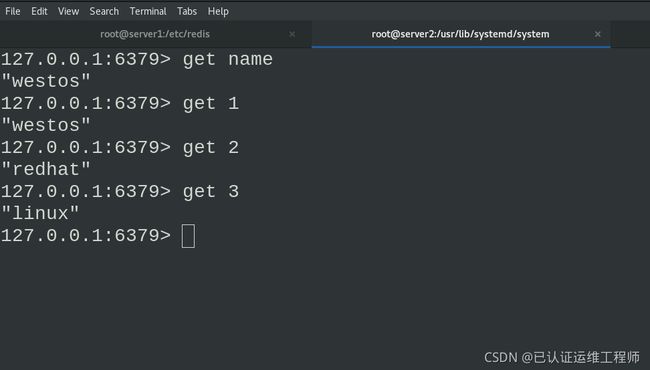
set name #插入数据
get name #查看
此时在主库中插入数据,从库中可以get查到
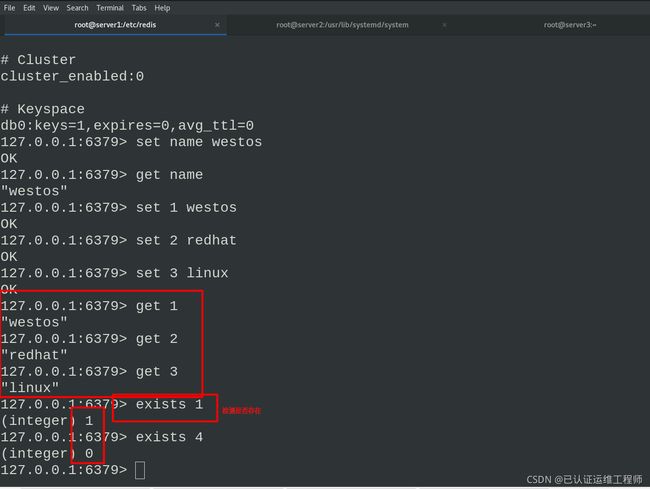
在从库中可以get到信息
四、Sentine主从自动切换
使用哨兵模式,自动监视Master节点,当前挂掉后,自动将Slaver节点变为Master节点
Sentinel(哨兵)是用于监控redis集群中Master状态的工具,是Redis 的高可用性解决方案,sentinel哨兵模式已经被集成在redis2.4之后的版本中。sentinel是redis高可用的解决方案,sentinel系统可以监视一个或者多个redis master服务,以及这些master服务的所有从服务;当某个master服务下线时,自动将该master下的某个从服务升级为master服务替代已下线的master服务继续处理请求。
sentinel可以让redis实现主从复制,当一个集群中的master失效之后,sentinel可以选举出一个新的master用于自动接替master的工作,集群中的其他redis服务器自动指向新的master同步数据。一般建议sentinel采取奇数台,防止某一台sentinel无法连接到master导致误切换。
原理:
一主两从的情况下,当master与两个slave或因网络关系断掉的情况下,客户端并不知道master失联,会持续写入数据,但此时slave端已经不能复制数据。
如果需要解决此问题,则需要两个slave同时认定不能连接master,或者,超过设定时间不能连接,则此时master端会拒绝客户端继续写入,那么重新接入变成slave时就不会造成数据丢失。
故障转移
选取领头的sentinel,然后对故障进行转移
在下线服务器的从服务器中挑选一个作为新的主服务器
已下线的服务器下的其他从服务器复制新的主服务器
已下线的主服务器再上线的时候会作为新服务器的从服务器0.
1.配置sentinel文件
在server1主机中,配置sentinel,并复制到server2和server3中
cd redis-6.2.4/
cp sentinel.conf /etc/redis/
cd /etc/redis/
vim sentinel.conf
///
sentinel monitor mymaster 172.25.7.1 6379 2 ##master为server1,2表示需要两票通过,这台主机就被认定宕掉
sentinel down-after-milliseconds mymaster 10000 ##连接超时为10s
///
scp sentinel.conf server2:/etc/redis/
scp sentinel.conf server3:/etc/redis/
redis-sentinel /etc/redis/sentinel.conf ##可以看到两个slave端
更改文件sentinel.conf

sentinel文件配置完毕!!!
2.master自动切换
在server1即master打开哨兵中监控到信息,将监控程序打入后台
redis-sentinel /etc/redis/sentinel.conf &
此时server2、server3是slave
也开启哨兵模式
redis-sentinel /etc/redis/sentinel.conf &
打开一个新的shell面板,连接server1
在server1中关闭redis
在另一个server1的shell面板查看变化,会显示已关闭及server2、server3的竞选master的过程
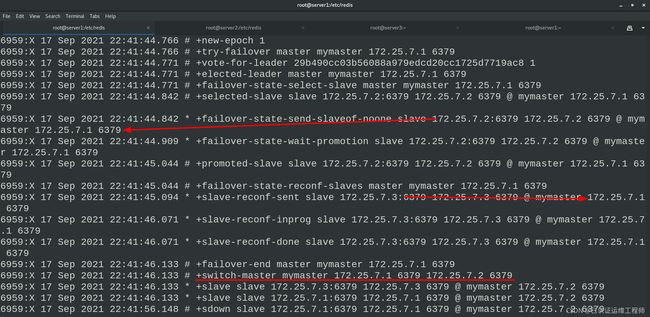
master变成了server2

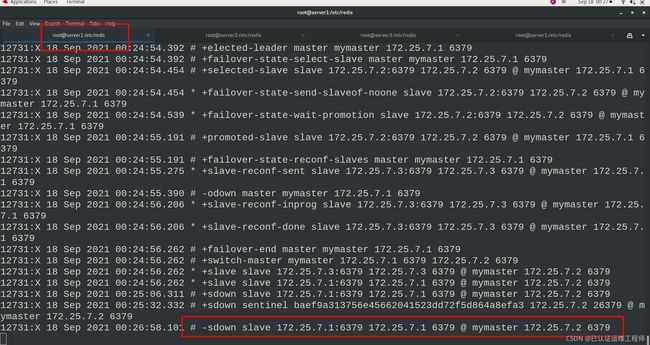
现在server1是关闭的,开启server1的redis后,server1会自动切换为slave,并清空之前的所有数据
五、redis的集群cluster
集群原理
1.所有的redis节点彼此互联(PING-PONG机制),内部使用二进制协议优化传输速度和带宽。
2.节点的fail是通过集群中超过半数的节点检测失效时才生效。
3.客户端与redis节点直连,不需要中间proxy层.客户端不需要连接集群所有节点,连接集群中任何一个可用节点即可。
4.redis-cluster把所有的物理节点映射到[0-16383]slot上,cluster 负责维护node<->slot<->value
Redis集群中内置了 16384 个哈希槽,当需要在 Redis 集群中放置一个 key-value 时,redis 先对key 使用 crc16 算法算出一个结果,然后把结果对 16384 求余数,这样每个 key 都会对应一个编号在 0-16383 之间的哈希槽,redis 会根据节点数量大致均等的将哈希槽映射到不同的节点
1.集群构建
手动构建集群
此时server1主机为master,重启redis,开启AOF模式,建立medis目录,及集群7001~7006目录,分别配置目录下配置文件,启动服务
在server1中
/etc/init.d/redis_6379 restart
vim /etc/redis/6379.conf
\\\
appendonly yes ##开启AOF模式
\\\
cd /usr/local
mkdir redis #创建目录
cd redis/
mkdir 700{1..6} #创建六个节点的目录
cd 7001
vim redis.conf #编辑配置文件
///
port 7001
cluster-enabled yes ##开启集群
cluster-config-file nodes.conf ##集群配置文件
cluster-node-timeout 5000 ##节点超时
appendonly yes ##开启AOF模式
daemonize yes ##用守护线程的方式启动
///
redis-server redis.conf ##启动服务
ps ax ##redis-server *:7001 [cluster]
cp redis.conf ../7002/ ##复制配置文件到7002-7006
cp redis.conf ../7003/
cp redis.conf ../7004/
cp redis.conf ../7005/
cp redis.conf ../7006/
再分别进入各节点目录中修改配置文件中——port 7001
例如:
cd 7002/
vim redis.conf
///
port 7002
cluster-enabled yes
cluster-config-file nodes.conf
cluster-node-timeout 5000
appendonly yes
daemonize yes
///
redis-server redis.conf #启动服务
在 /etc/redis/6379.conf 文件中开启AOF模式

创建redis目录后,在各节点目录中编辑配置文件 redis.conf (7001目录中的文件)

最终可以使用ps查看,此时所有节点的服务都已经启动
ps ax ##查看进程

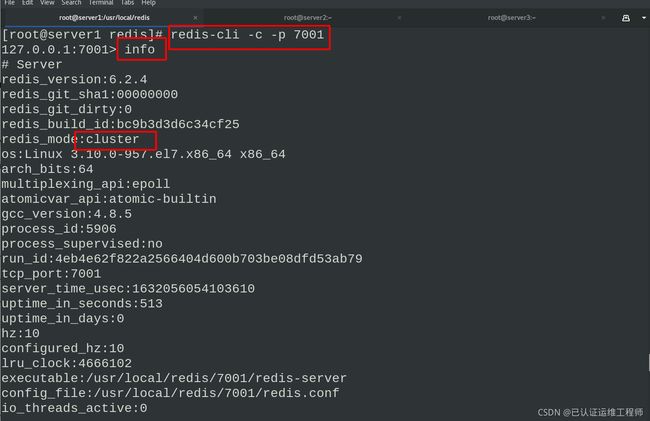
使用redis-cli来进行集群的交互,客户端连接任意一个节点,使用-c表示以集群的方式登录,-p指定端口。info查看,当前为master,没有slave端。
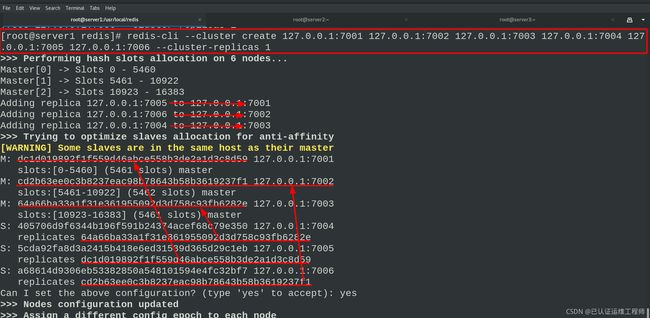
创建集群主从节点,–cluster-replicas 参数为数字,1表示每个主节点需要1个从节点。然后检查集群,查看集群信息。
redis-cli --cluster create 127.0.0.1:7001 127.0.0.1:7002 127.0.0.1:7003 127.0.0.1:7004 127.0.0.1:7005 127.0.0.1:7006 --cluster-replicas 1 #创建集群
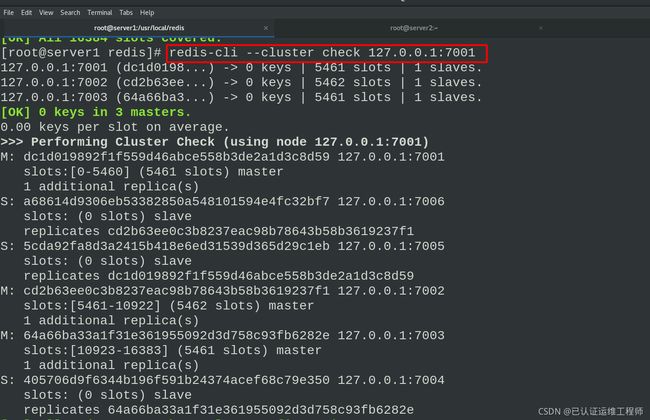
redis-cli --cluster check 127.0.0.1:7001 ##检查集群
redis-cli --cluster info 127.0.0.1:7001 ##集群信息查看
创建六个节点,1、2、3为master,一主一从
检查集群,看到是一主一从
集群信息查看

脚本构建集群
cd
cd redis-6.2.4/
cd utils/create-cluster/
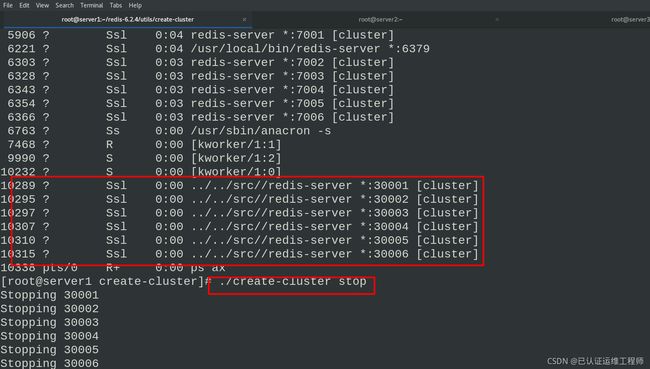
./create-cluster start ##开启实例Starting 30001~30006
ps ax
./create-cluster stop ##停止所有实例,使用手动构建的集群来做接下来的实验
ps ax #查看

2.节点主从自动切换
之前查看节点信息我们直到节点主从信息
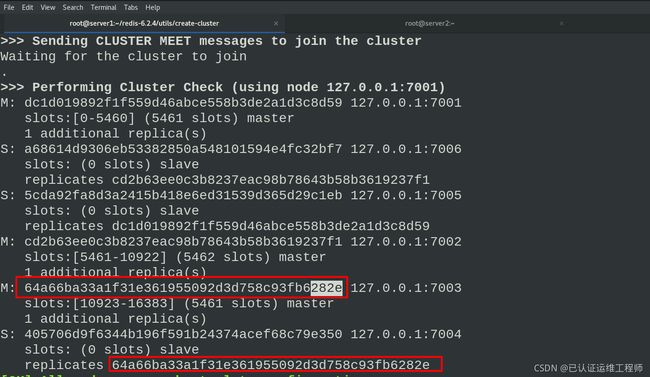
如图,7004是7003的从节点,当连接7003端口,并关掉当前节点,7004会自动切换为主节点,此时没有从节点。开启server2,此时为从节点,检查集群,可以看到7004有一个从节点为7003。
redis-cli -c -p 7003
> SHUTDOWN
ps ax ##7003消失
redis-cli --cluster check 127.0.0.1:7001 ##7004 0 slaves
cd ..
cd 7003
redis-server redis.conf ##再次启动服务
ps ax ##redis-server *:7003 [cluster]
redis-cli --cluster check 127.0.0.1:7001 ##7004 1 slaves为7003
关闭7003

ps ax查看发现7003消失
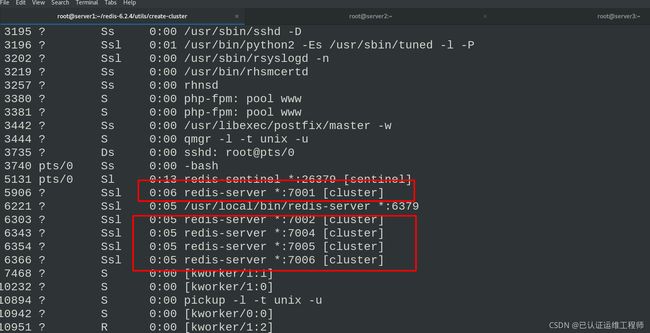
redis-cli --cluster check 127.0.0.1:7001
检查所有节点信息发现7004成为了master,且没有从节点

重新开启7003,再次查看节点信息发现7003已经成为7004的从节点,即自动切换主从节点
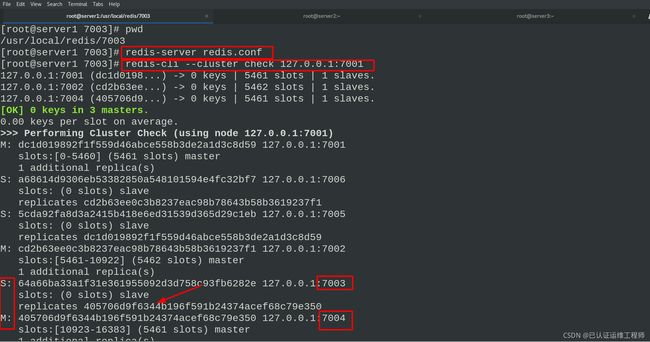
3.添加节点和分片
创建7007、7008两个节点的目录及配置文件
mkdir 700{7,8}
cd 7007
cp ../7001/redis.conf .
vim redis.conf
///
port 7007
cluster-enabled yes
cluster-config-file nodes.conf
cluster-node-timeout 5000
appendonly yes
daemonize yes
///
redis-server redis.conf
7008相同
ps ax

查看两个节点的进程
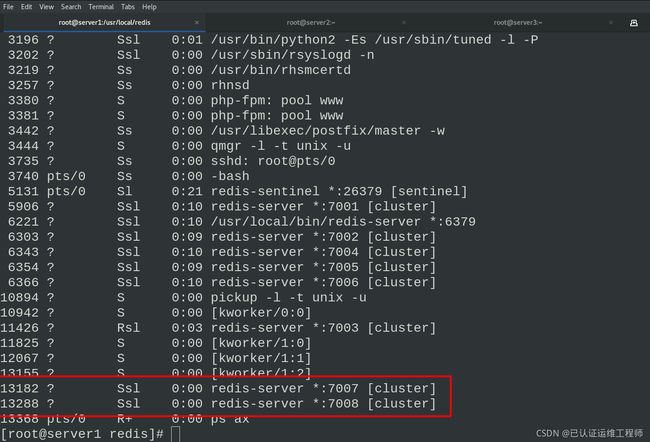
将7007节点加入集群中,但是并没有分配slot,所以这个节点并没有真正的开始分担集群工作,所以要进行分片。重新分片基本上意味着将哈希槽从一组节点移动到另一组节点,并且像群集创建一样。
redis-cli --cluster add-node 127.0.0.1:7007 127.0.0.1:7001 #将7007节点加入了集群中
redis-cli --cluster check 127.0.0.1:7001 #7007 0 slaves slots: (0 slots) master
将节点加入了集群中,但是并没有分配slot,所以这个节点并没有真正的开始分担集群工作

检查集群信息,7007节点为master
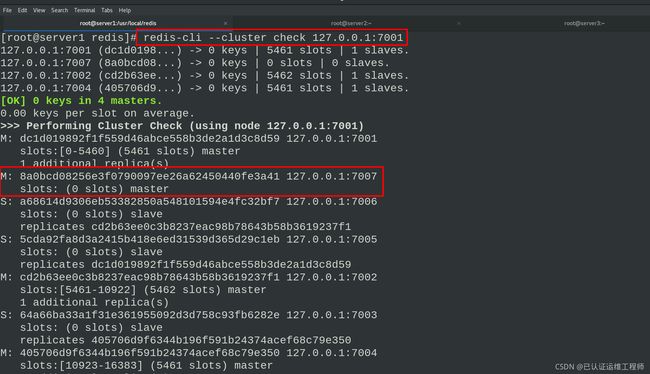
分配slot
redis-cli --cluster reshard 127.0.0.1:7001 #重新分片
分片操作
How many slots do you want to move (from 1 to 16384)? 1000 #移动的插槽数量
What is the receiving node ##7007节点的ID(接收节点的ID)
Source node #1: all #从哪些节点获取这些密钥,输入all则从所有其他主节点获取这些哈希槽
Do you want to proceed with the proposed reshard plan (yes/no)? yes #确定是否要继续重新分片,输入yes
redis-cli --cluster check 127.0.0.1:7001 #检查集群信息
再次检查集群信息
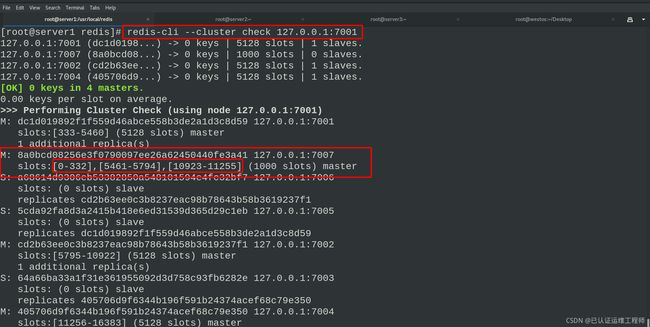
此时7007节点有1000哈希槽,没有从节点,于是把7008 节点加入到7001 节点的集群中,并且当做8a0bcd08256e3f0790097ee26a62450440fe3a41的从节点。如果不指定 --cluster-master-id 会随机分配到任意一个主节点。
redis-cli --cluster check 127.0.0.1:7001
redis-cli --cluster add-node 127.0.0.1:7008 127.0.0.1:7001 --cluster-slave --cluster-master-id 8a0bcd08256e3f0790097ee26a62450440fe3a41 #把7008 节点加入到7001 节点的集群中,并且当做node_id为 7007的从节点id。
如果不指定主节点ID --cluster-master-id 会随机分配到任意一个主节点
redis-cli --cluster check 127.0.0.1:7001 #检查集群
redis-cli --cluster info 127.0.0.1:7001 #查看集群信息
将7008加入集群中
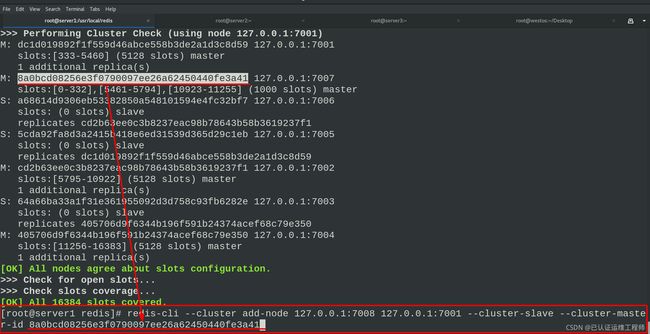
检查集群
redis-cli --cluster check 127.0.0.1:7001
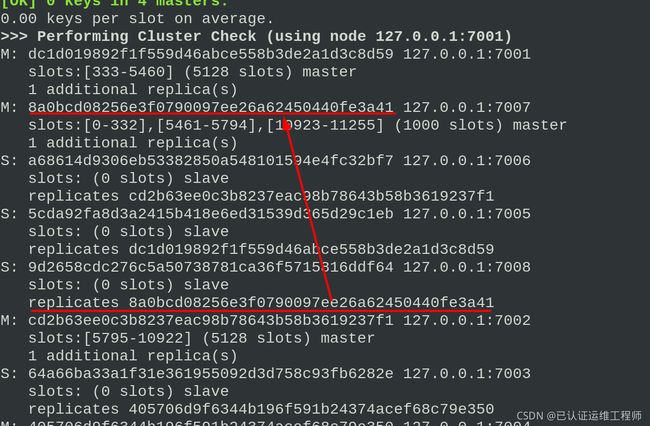
显示集群信息,此时7007有一个从节点
redis-cli --cluster info 127.0.0.1:7001
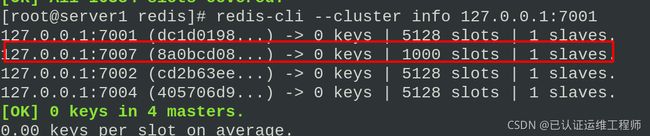
六、Redis+Mysql读写分离
Redis作mysql的缓存服务器
实际的生产环境当中,客户端对数据库的读操作都是直接找redis拿数据的
如果redis缓存里面没有数据,那么就会去找mysql拿数据,并且给redis中缓存一份
redis中的数据有两种情况不能使用:数据过期了或者mysql中的数据更新了 用户读的时候访问redis,用户写的时候访问mysql
实际上读的需求量是很大的,redis刚好是把数据缓存在内存当中,响应速度也快 也可以降低我们后台mysql数据库的压力一般对于高并发的系统来说,搭建一个健壮的缓存系统是不可避免的。
单机的reids的QPS可能只能上万,如果有再高并发的场景,单机是不能搞定的,就会有它的系统瓶颈。
一般来说缓存是用来支撑高并发读,这时候我们可能就会想到读写分离; 读写分离是用来处理读的并发量大,而写的并发量小的场景。
数据访问流程:client -> app -> redis -> mysql -> redis -> client
客户端用app访问,按照顺序会先在redis缓存里找数据,缓存中如果没有才去mysql读,读完保存一份在redis里,然后返回客户端,下次再读时直接到缓存中读取速度就会有很大的提升
在server1主机中(nginx+php)
接着上一个实验,我们需要杀死所有的redis进程,方便起见我们需要安装进程管理工具,便于使用killall命令,关掉之前redis所有进程
yum install -y psmisc ##便于使用killall命令
killall redis-server
ps ax ##没有redis且nginx和php正常
拓展:
Psmisc软件包包含三个帮助管理/proc目录的程序
fuser 显示使用指定文件或者文件系统的进程的PID。
killall 杀死某个名字的进程,它向运行指定命令的所有进程发出信号。
pstree 树型显示当前运行的进程。
killall用于杀死指定名字的进程(kill processes by
name)。我们可以使用kill命令杀死指定进程PID的进程,如果要找到我们需要杀死的进程,我们还需要在之前使用ps等命令再配合grep来查找进程,而killall把这两个过程合二为一
格式:killall 【command-name】 fuser
安装软件包php、gearmand、libevent-devel、libgearman相关软件包
本地主机获取软件包
lftp 172.25.254.250
cd /pub/docs/redis
mirror rhel7/
exit
cd rhel7/
yum install -y *.rpm #全部安装
systemctl daemon-reload
systemctl start php-fpm #开启php
rhel7目录下软件包

修改测试页test.php内容,修改主从ip
mv test.php /usr/local/nginx/html/
vim test.php
///
3 $redis->connect('172.25.7.2',6379)
10 $connect = mysql_connect('172.25.7.3','redis','westos');
///
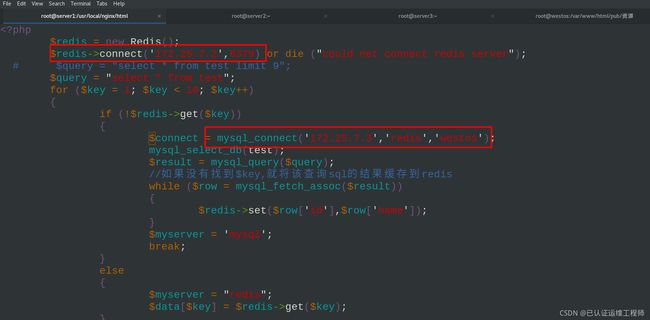
测试页test.php源码
$redis = new Redis();
$redis->connect('127.0.0.1',6379) or die ("could net connect redis server");
# $query = "select * from test limit 9";
$query = "select * from test";
for ($key = 1; $key < 10; $key++)
{
if (!$redis->get($key))
{
$connect = mysql_connect('127.0.0.1','redis','westos');
mysql_select_db(test);
$result = mysql_query($query);
//如果没有找到$key,就将该查询sql的结果缓存到redis
while ($row = mysql_fetch_assoc($result))
{
$redis->set($row['id'],$row['name']);
}
$myserver = 'mysql';
break;
}
else
{
$myserver = "redis";
$data[$key] = $redis->get($key);
}
}
echo $myserver;
echo "
";
for ($key = 1; $key < 10; $key++)
{
echo "number is $key";
echo "
";
echo "name is $data[$key]";
echo "
";
}
?>
在server2主机中(redis)
开启redis,info查看信息,当前为server1的从机。修改配置文件/etc/redis/redis.conf,删除关于主从的设定,重启redis。info查看server2此时为master主机
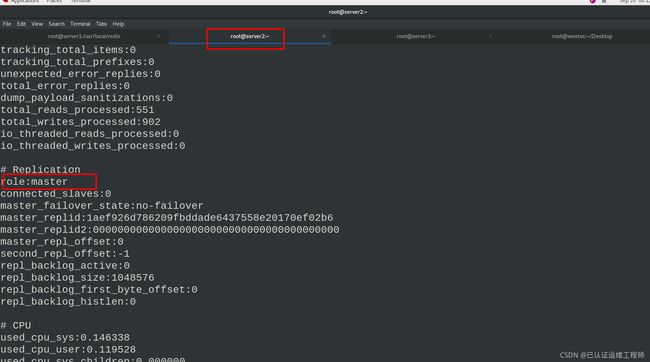
在server3主机中(mariadb数据库)
在server3主机,停掉rdis,并且取消开机自启。删除redis环境变量并且生效
/etc/init.d/redis_6379 stop
chkconfig redis_6379 off ##取消开机自启
vim .bash_profile
///
PATH=$PATH:$HOME/bin
///
source .bash_profile
安装mariadb 还原mysql的配置文件,删除mysql所有数据文件,开启mariadb
yum install -y mariadb-server.x86_64
vim /etc/my.cnf
///
[mysqld]
datadir=/var/lib/mysql
socket=/var/lib/mysql/mysql.sock
[mysqld_safe]
log-error=/var/lib/mysql/mysqld.log
pid-file=/var/lib/mysql/mysqld.pid
///
systemctl start mariadb

进入数据库,可以看到test库,将本地文件test.sql文件导入,是test库的内容。进入数据库,可以看到导入的数据,并授权redis用户
lftp 172.25.254.250
> cd pub/docs/redis/
> get test.sql
mysql
> show databases; ##test
mysql < test.sql #将test库内容导入
mysql
> use test
> show tables;
> select * from test; ##test1~test9
> grant all on test.* to redis@'%' identified by 'westos'; #授权
导入数据前

导入test.sql数据后查看数据库

导入数据之后重新启动数据库
systemctl restart mariadb.service
test.sql源码
use test;
CREATE TABLE `test` (`id` int(7) NOT NULL AUTO_INCREMENT, `name` char(8) DEFAULT NULL, PRIMARY KEY (`id`)) ENGINE=InnoDB DEFAULT CHARSET=utf8;
INSERT INTO `test` VALUES (1,'test1'),(2,'test2'),(3,'test3'),(4,'test4'),(5,'test5'),(6,'test6'),(7,'test7'),(8,'test8'),(9,'test9');
#DELIMITER $$
#CREATE TRIGGER datatoredis AFTER UPDATE ON test FOR EACH ROW BEGIN
# SET @RECV=gman_do_background('syncToRedis', json_object(NEW.id as `id`, NEW.name as `name`));
# END$$
#DELIMITER ;
在浏览器访问172.25.7.1/test.php
数据在数据库,拿到数据之后还会在redis缓存一份
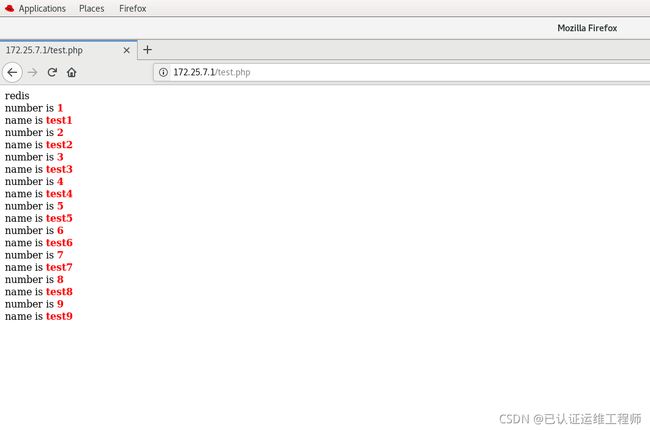
在读写分离之前,浏览器还是会到redis的缓存中拿数据,当redis中数据被删除才会在mysql中更新
所以我们可以在server2的redis中更改数据浏览器会同步更改,但是数据库中更改并没有同步到redis中
如图:
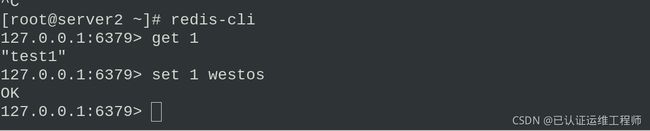
在浏览器验证数据已同步

下面实现Mysql更新自动触发redis进行修改,这样才能实现真正的读写分离 。
目前我们实现了简单的读写分离
客户端读的时候去找redis缓存;客户端写的时候去找mysql
但是存在一个问题:当mysql数据库中的数据有所变化的时候,redis缓存并不能实时同步
接下来我将实现一旦mysql有所变化,立即触发redis更新所缓存的数据
七、redis如何与mysql保持数据一致
接下来我们要解决mysql数据更改之后redis没有同步的问题
我们需要直到什么是Gearman
Gearman原理
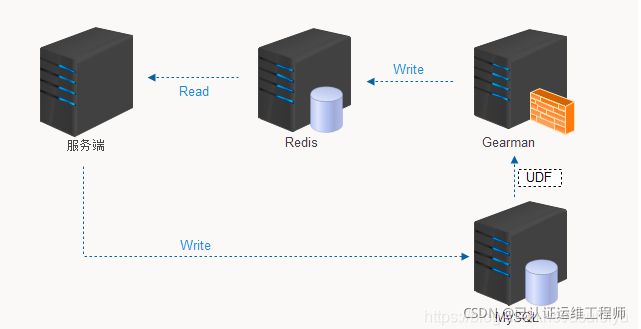
Gearmand是一个用来把工作委派给其它机器、分布式的调用更适合做某项工作的机器、并发的做某项工作在多个调用间做负载均衡、或用来调用其它语言的函数的系统。
一个Gearman驱动的应用程序由三部分组成:一个客户端,一个工作者和一个作业服务器。客户端负责创建要运行的作业并将其发送到作业服务器。作业服务器将找到可以运行作业并转发作业的合适工作人员。工作人员执行客户端请求的工作,并通过作业服务器向客户端发送响应。Gearman提供您的应用程序调用的客户端和工作者API来与Gearman作业服务器(也称为gearmand)交谈,因此您不需要处理网络或作业的映射。在内部,gearman客户端和工作者API使用TCP套接字与作业服务器进行通信。
client:请求的发起者,工作任务的需求方(可以是C、PHP、Java、Perl、Mysql udf等等)
Job Server:请求的调度者,负责将client的请求转发给相应的worker(gearmand服务进程创建)
worker:请求的处理者(可以是C、PHP、Java、Perl等等)
配置gearmand
在servre3中
安装数据库的开发包,通过 lib_mysqludf_json UDF 库函数将关系数据映射为 JSON 格式,拷贝 lib_mysqludf_json.so 模块。进入数据库,查看mysql 的模块目录,注册 UDF 函数,查看函数
server3(mariadb)
lftp 172.25.254.250
cd /pub/docs/redis/
get lib_mysqludf_json-master.zip
exit
yum install -y unzip
unzip lib_mysqludf_json-master.zip
cd lib_mysqludf_json-master/
yum install -y gcc
gcc $(mysql_config --cflags) -shared -fPIC -o lib_mysqludf_json.so lib_mysqludf_json.c
cp lib_mysqludf_json.so /usr/lib64/mysql/plugin/
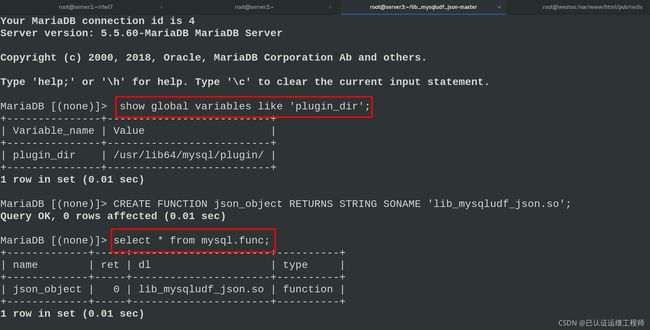
进入mysql查看
mysql
mysql> show global variables like 'plugin_dir';

注册UDF函数
mysql> CREATE FUNCTION json_object RETURNS STRING SONAME 'lib_mysqludf_json.so';
mysql> select * from mysql.func;
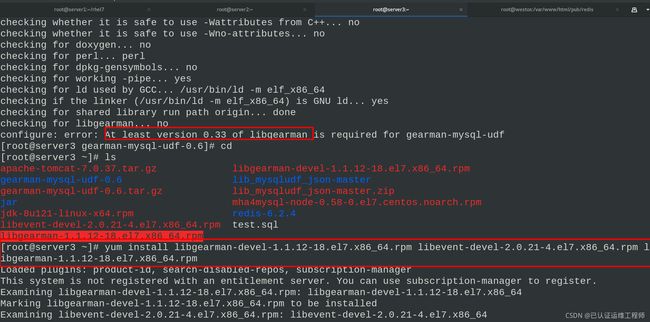
下载解压gearman,并解决依赖性进行编译
tar zxf gearman-mysql-udf-0.6.tar.gz
cd gearman-mysql-udf-0.6/
./configure --libdir=/usr/lib64/mysql/plugin/
yum install -y libgearman* libevent*
#libevent-devel-2.0.21-4.el7.x86_64.rpm
#libgearman-1.1.12-18.el7.x86_64.rpm
#libgearman-devel-1.1.12-18.el7.x86_64.rpm
./configure --libdir=/usr/lib64/mysql/plugin/ #再次检测
make #编译
make install #安装
注册UDF函数,并查看
mysql
mysql> CREATE FUNCTION gman_do_background RETURNS STRING SONAME 'libgearman_mysql_udf.so';
mysql> CREATE FUNCTION gman_servers_set RETURNS STRING SONAME 'libgearman_mysql_udf.so';
mysql> select * from mysql.func;
安装软件包
注册函数

指定gearman的服务信息
MariaDB [(none)]> select gman_servers_set('172.25.7.1:4730');

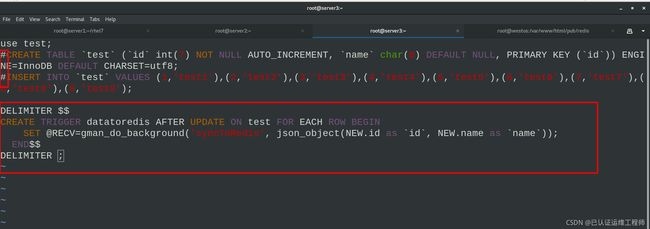
编辑mysql触发器,重新导入数据库
vim test.sql ##编写 mysql 触发器
///
use test;
#CREATE TABLE `test` (`id` int(7) NOT NULL AUTO_INCREMENT, `name` char(8) DEFAULT NULL, PRIMARY KEY (`id`)) ENGINE=InnoDB DEFAULT CHARSET=utf8;
#INSERT INTO `test` VALUES (1,'test1'),(2,'test2'),(3,'test3'),(4,'test4'),(5,'test5'),(6,'test6'),(7,'test7'),(8,'test8'),(9,'test9');
DELIMITER $$
CREATE TRIGGER datatoredis AFTER UPDATE ON test FOR EACH ROW BEGIN
SET @RECV=gman_do_background('syncToRedis', json_object(NEW.id as `id`, NEW.name as `name`));
END$$
DELIMITER ;
///
mysql -pwestos < test.sql
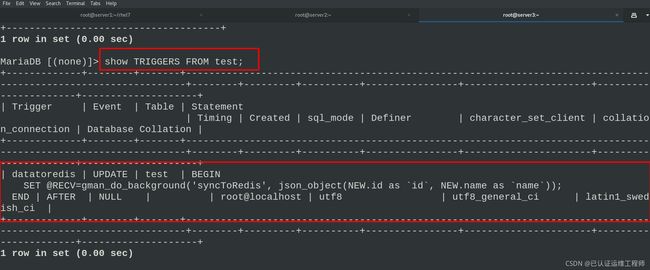
mysql -pwestos
> SHOW TRIGGERS FROM test; ##查看触发器
触发器信息
在server1中
启动服务及worker任务
systemctl start gearmand ##启动gearman服务
php -m | grep gearman #查看服务
php -m | grep redis
netstat -antlp #查看4370端口是否开启
cd /root/rhel7/ #切换环境到worker.php目录中
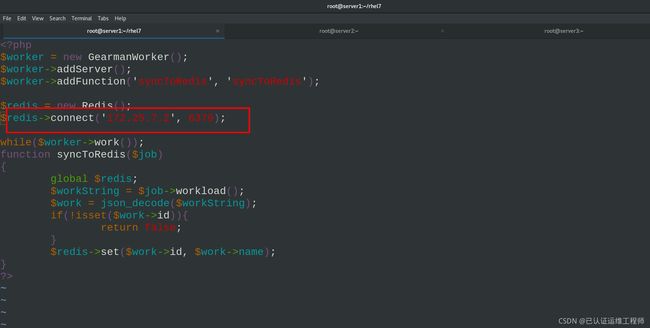
vim worker.php #编写 gearman 的 worker 端
///
7 $redis->connect('172.25.7.2', 6379);
18 $redis->set($work->id, $work->name); ##(未做更改)这条语句就是将 id 作 KEY 和name 作 VALUE 分开存储,需要和前面写的 php 测试代码的存取一致。
///
nohup php worker.php & #运行worker.php并打入后台
ps ax #查看是否开启 worker.php
worker.php


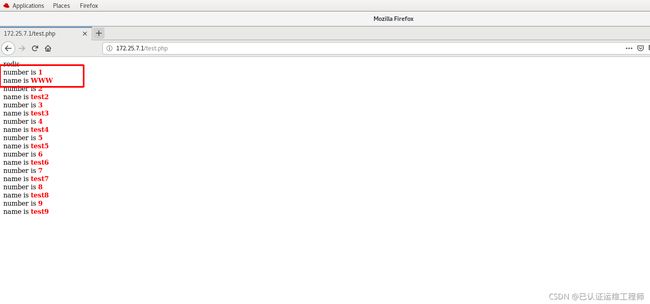
server1中的服务启动完毕,到mariadb中更改数据,server2中redis检查是否同步,浏览器查看
MariaDB [test]> update test set name='WWW' where id =1;

server2中检查,redis与mysql同步成功!

浏览器信息已变更
注意!!!
如果redis和mysql数据出现了不同步的问题,我们需要检查以下几点:
1.Mysql的udf函数注册和触发器
2.是否指向正确的Gearmand 4730主机
3.Gearmand服务正常启动
4.worker正常启动