本人是hadoop入门级小白, 一边学习Hadoop权威指南英文版, 一边翻译相关内容, 希望达到加深理解的效果, 发
布博客上, 希望能和大家一起分享和交流。
1. MapReduce job提交
提交过程比较简单,submit() on a Job object, 通过waitForCompletion()等待job结束。waitForCompletion不断轮询当前job运行的进度。
2.MapReduce job运行流程
运行过程有5个关键部分参与:客户端,Yarn ResourceManager,Yarn NodeManager,MRAppMaster,HDFS,下面分别介绍。
客户端:
提交job任务
Yarn ResourceManager:
coordinates the allocation of compute resourceson the cluster.
整个集群只有一个
负责集群计算资源的分配与调度
处理客户端作业提交请求
启动/监控ApplicationMaster
监控NodeManager
(容错性)存在单点故障,基于ZooKeeper实现HA
Yarn NodeManager:
launch and monitor the compute containers onmachines in the cluster。
整个集群有多个,负责单节点资源管理和使用(更细一点说,是负责启动、监控和管理该计算节点上Container,防止Application Master使用多于它申请到的计算资源)
单个节点上的资源管理和任务管理(因为NodeManager负责启动和监控管理Container,而ApplicationMaster和任务在Container中运行,因此Node Manager负责对它们使用的计算资源进行管理)
处理来自ResourceManager的命令
处理来自ApplicationMaster的命令
(容错性)NodeManager失败后,RM将失败任务告诉对应的AM,AM决定如何处理失败的任务
MRAppMaster:管理完成job而创建的task
每个应用有一个,负责应用程序整个生命周期的管理
分布式计算数据的切分
为应用程序向Resource Manager申请计算资源(以Container为单位,一个应用程序通常为申请跟任务数相同个数的Container),并将Container分配给任务(实际上任务是在Container中执行的)
任务监控与容错
(容错性)失败后,由Resource Manager负责重启,Application Manager需处理内部任务的容错问题,ApplicationManager运行过程中会保存已经运行完成的Task,重启后无需重新运行
HDFS:分布式文件系统
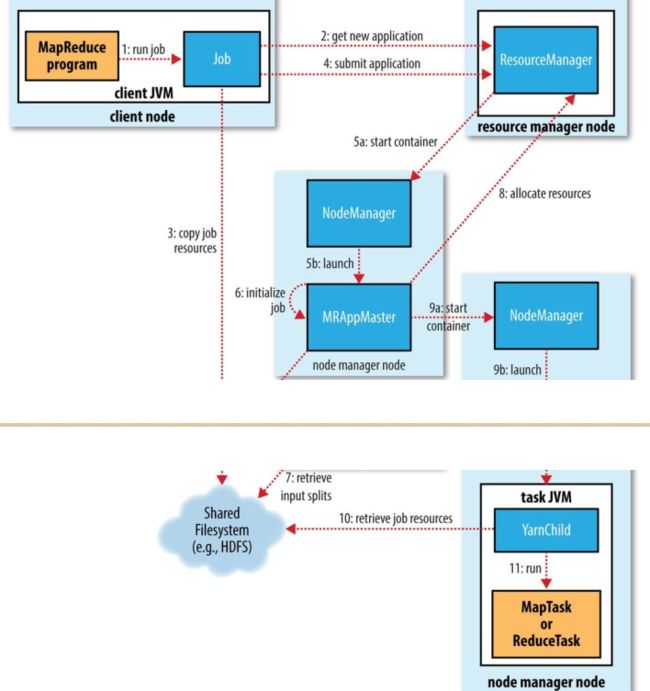
2.1提交job
submit创建一个JobSubmitter实例,提交任务由该实例来完成。
step1:resource manager创建一个application id---mapreduce job ID。
step2: 检查job的输出, 比如输出目录是否已经存在, 存在就上报一个错误。
step3: 为job计算input splits,这些input splits就是作为Mapper的输入。
step4: 复制运行job需要的资源到HDFS。包括job jar, 配置文件, the computed input splits
step5: 提交job通过submitApplication调用。
2.2 Job Initialization
当resource manager收到来自submitApplication的请求, 就会把请求发给YARN scheduler,scheduler会分配container,resource manager也会启动job的application master主线程。application master主线程是由node manager管理。
application master相当于一个main class为MRAppMaster的java应用。
a) 该应用会创建很多个bookkeeping对象, 来跟踪job运行的进度。application master会接收来自task的进度和完成报告。
b)application master会接收input splits
c) 为每个input split创建一个map task对象, 而且会创建相应数目的reduce task对象(reduce task由 mapreduce.job.reduces属性决定)。
d)决策tasks push到哪些node上去运行。
e) 创建输出目录和job task 运作过程中需要的临时输出空间。
application master会向资源管理器为所有map和reduce任务请求containers.
请求的内容:
map task的优先级会高于reduce, 直到5%的map task 完成之后,才能为reduce task请求.
reduce task能在集群的任何node上运行, 但map task有数据局部性限制。map task任务按与input split在同一个node, 同一个柜子上, 同一个机房的不同柜子上的优先顺序分配。
包括cpu,内存等数据。
2.3 Task 执行
当resource manager's scheduler为task分配好一个container资源, application master就会联系node manager启动该container,开始执行Map任务或者Reduce任务,然后YarnChild为main class的java应用就会执行task,因此任务是在称为YarnChild进程中运行,不同于Map Reduce 1,Yarn上每个任务都会启动一个新的JVM进程。YarnChild在执行task之前, 会在分布式cache上找到该task需要的资源:jar file, 配置文件等。
2.4 Progress and Status Updates
Task有很多的事件计数器, 有些计数器是内置framewok中, 也有些事用户自定义的。
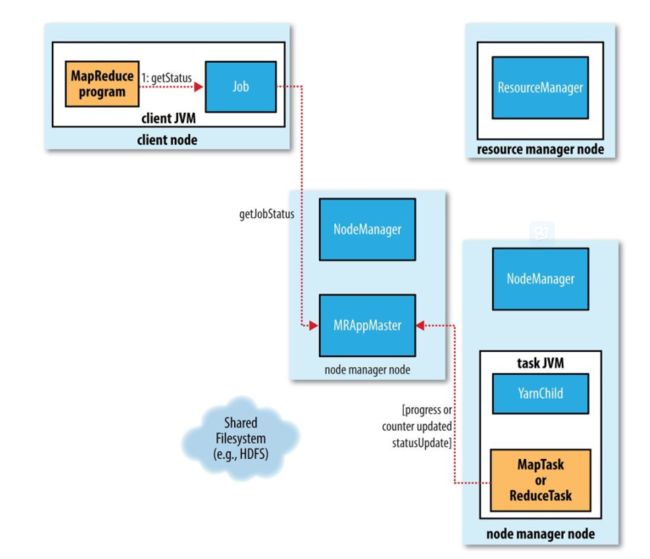
2.5 Job Completion
application master接收到job最后一个 task完成的通知,就修改job状态为successful.
当job轮询状态时, 得到successful状态结果, 就return waitForcompletion()函数。
当job完成后,application master和task container会清理working状态, 中间结果被清理, OutputCommitter scommitJob()会被调用。