前言:
MySQL Cluster 是一个基于 NDB Cluster 存储引擎的完整的分布式数据库系统。不仅仅具有高可用性,而且可以自动切分数据,冗余数据等高级功能。和 Oracle Real Cluster Application 不太一样的是,MySQL Cluster 是一个 Share Nothing 的架构,各个 MySQL Server 之间并不共享任何数据,高度可扩展以及高度可用方面的突出表现是其最大的特色。虽然目前还只是 MySQL 家族中的一个新兴产品,但是已经有不少企业正在积极的尝试使用了。本章我们将通过对 MySQL Cluster 的了解来寻找其在可扩展设计方面的优势。
16.1 MySQL Cluster介绍
简单的说,MySQL Cluster实际上是在无共享存储设备的情况下实现的一种完全分布式数据库系统,其主要通过NDB Cluster(简称NDB)存储引擎来实现。MySQL Cluster 刚刚诞生的时候可以说是一个可以对数据进行持久化的内存数据库,所有数据和索引都必须装载在内存中才能够正常运行,但是最新的 MySQL Cluster 版本已经可以做到仅仅将所有索引装载在内存中即可,实际的数据可以不用全部装载到内存中。
一个MySQL Cluster的环境主要由以下三部分组成:
a) SQL层的SQL服务器节点(后面简称为SQL节点),也就是我们常说的MySQL Server。
主要负责实现一个数据库在存储层之上的所有事情,比如连接管理,Query 优化和响应,Cache 管理等等,只有存储层的工作交给了 NDB 数据节点去处理了。也就是说,在纯粹的MySQL Cluster环境中的SQL节点,可以被认为是一个不需要提供任何存储引擎的 MySQL服务器,因为他的存储引擎有Cluster环境中的 NDB 节点来担任。所以,SQL层各MySQL服务器的启动与普通的 MySQL Server 启动也有一定的区别,必须要添加ndbcluster参数选项才行。我们可以添加在my.cnf配置文件中,也可以通过启动命令行来指定。
b) Storage 层的 NDB 数据节点,也就是上面说的 NDB Cluster。
最初的 NDB 是一个内存式存储引擎,当然也会将数据持久化到存储设备上。但是最新的 NDB Cluster 存储引擎已经改进了这一点,可以选择数据是全部加载到内存中还是仅仅加载索引数据。NDB 节点主要是实现底层数据存储功能,来保存Cluster的数据。每一个Cluster节点保存完整数据的一个fragment,也就是一个数据分片(或者一份完整的数据,视节点数目和配置而定),所以只要配置得当,MySQL Cluster在存储层不会出现单点的问题。一般来说,NDB 节点被组织成一个一个的NDB Group,一个NDB Group实际上就是一组存有完全相同的物理数据的NDB节点群。
上面提到了NDB各个节点对数据的组织,可能每个节点都存有全部的数据也可能只保存一部分数据,主要是受节点数目和参数来控制的。首先在MySQL Cluster主配置文件(在管理节点上面,一般为config.ini)中,有一个非常重要的参数叫NoOfReplicas,这个参数指定了每一份数据被冗余存储在不同节点上面的份数,该参数一般至少应该被设置成2,也只需要设置成2就可以了。因为正常来说,两个互为冗余的节点同时出现故障的概率还是非常小的,当然如果机器和内存足够多的话,也可以继续增大来更进一步减小出现故障的概率。此外,一个节点上面是保存所有的数据还是一部分数据还受到存储节点数目的限制。NDB存储引擎首先保证NoOfReplicas参数配置的要求来使用存储节点,对数据进行冗余,然后再根据节点数目将数据分段来继续使用多余的NDB节点。分段的数目为节点总数除以NoOfReplicas所得。
c) 负责管理各个节点的Manage节点主机:
管理节点负责整个Cluster集群中各个节点的管理工作,包括集群的配置,启动关闭各节点,对各个节点进行常规维护,以及实施数据的备份恢复等。管理节点会获取整个Cluster环境中各节点的状态和错误信息,并且将各Cluster集群中各个节点的信息反馈给整个集群中其他的所有节点。由于管理节点上保存了整个Cluster环境的配置,同时担任了集群中各节点的基本沟通工作,所以他必须是最先被启动的节点。
下面是一幅 MySQL Cluster 的基本架构图(出自 MySQL 官方文档手册):
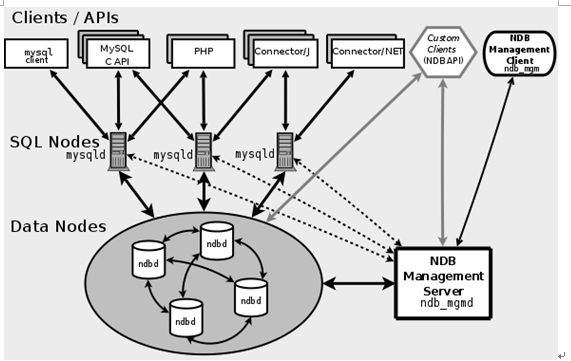
通过图中我们可以更清晰的了解整个 MySQL Cluster 环境各个节点以及客户端应用之间的关系。
由于 MySQL Cluster 目前的成熟使用并不是太多,实现也较普通的 MySQL 略复杂,所以本章将首先从如何搭建一个 MySQL Cluster 环境开始来介绍他。
16.2 MySQL Cluster环境搭建
搭建MySQL Cluster首先需要至少一个管理节点主机来实现管理功能,一个SQL节点主机来实现MySQL server功能和两个ndb节点主机实现NDB Cluster的功能。在后面的介绍中,我采用双SQL节点来搭建测试环境,具体信息如下:
1、硬件准备
a) MySQL节点1 192.168.0.1
b) MySQL节点2 192.168.0.2
c) ndb节点1 192.168.0.3
d) ndb节点2 192.168.0.4
e) 管理节点 192.168.0.5
2、软件安装
首先在上面5个节点的主机上尽量确保环境基本一致,然后从MySQL官方下载相应的软件包并分发到两台SQL节点和两台NDB节点上,以备后面的安装时候的使用。
我的测试环境OS(RedHat Linux)如下(非必须):
root@mysql1:/usr/local>uname -a
Linux oratest1 2.6.9-42.ELsmp #1 SMP Wed Jul 12 23:27:17 EDT 2006 i686 i686 i386 GNU/Linux
a) 安装MySQL节点:
在MySQL节点上面需要安装支持cluster的MySQL Server,可以通过自编译源代码安装也可以选择MySQL官方提供的编译好的tar包或者rpm安装包,我是通过源代码自行编译的,实际上完全可以通过MySQL官方提供的经过优化编译的二进制tar包,只是我自己习惯了而已,我的编译设置参数如下:
root@mysql1>./configure \
--prefix=/usr/local/MySQL \
--without-debug \
--without-bench \
--enable-thread-safe-client \
--enable-assembler \
--with-charset=utf8 \
--with-extra-charsets=complex \
--with-client-ldflags=-all-static \
--with-MySQLd-ldflags=-all-static \
--with-ndbcluster \
--with-server-suffix=-max \
--datadir=/data/mysqldata \
--with-unix-socket-path=/usr/local/MySQL/sock/mysql.sock
...
root@mysql1>make
...
root@mysql1>make install
...
然后是配置设置配置文件/etc/my.cnf,由于是测试环境,所以我仅仅设置了ndbcluster所需要的最基本的两个配置项,其他所有的配置均用默认配置(后面会有较为详细的配置说明),如下:
root@mysql1>vi /etc/my.cnf
[client]
socket = /usr/local/mysql/sock/mysql.sock #由于编译时候特殊指定了,所以设置在这里,方便以后登入的时候使用
[MySQLd]
socket = /usr/local/mysql/sock/mysql.sock
ndbcluster
[MySQL_cluster]
ndb-connectstring = 192.168.0.5
继续完成后面的MySQL安装过程:
root@mysql1>cd /usr/local/mysql
root@mysql1>bin/mysql_install_db --user=mysql --socket=/usr/local/mysql/sock/mysql.sock
Installing MySQL system tables...
OK
Filling help tables...
OK
To start MySQLd at boot time you have to copy
support-files/MySQL.server to the right place for your system
PLEASE REMEMBER TO SET A PASSWORD FOR THE MySQL root USER !
To do so, start the server, then issue the following commands:
/usr/local/mysql/bin/MySQLadmin -u root password 'new-password'
/usr/local/mysql/bin/MySQLadmin -u root -h ointest_stb password 'new-password'
Alternatively you can run:
/usr/local/mysql/bin/MySQL_secure_installation
which will also give you the option of removing the test
databases and anonymous user created by default. This is
strongly recommended for production servers.
See the manual for more instructions.
You can start the MySQL daemon with:
cd /usr/local/MySQL ; /usr/local/mysql/bin/MySQLd_safe &
You can test the MySQL daemon with MySQL-test-run.pl
cd MySQL-test ; perl MySQL-test-run.pl
Please report any problems with the /usr/local/mysql/bin/MySQLbug script!
The latest information about MySQL is available on the web at
http://www.mysql.com
Support MySQL by buying support/licenses at http://shop.mysql.com
root@mysql1>chown -R root .
root@mysql1>chgrp -R mysql .
root@mysql1>chown -R mysql.mysql /usr/local/mysql/etc
root@mysql1>chown -R mysql.mysql /usr/local/mysql/sock
root@mysql1>chown -R mysql.mysql /usr/local/mysql/log
root@mysql1>:/usr/local/mysql# ls -l
total 40
drwxr-xr-x 2 root MySQL 4096 May 4 14:47 bin
drwxr-xr-x 2 MySQL MySQL 4096 May 4 14:20 etc
drwxr-xr-x 3 root MySQL 4096 May 4 14:46 include
drwxr-xr-x 2 root MySQL 4096 May 4 14:46 info
drwxr-xr-x 3 root MySQL 4096 May 4 14:46 lib
drwxr-xr-x 2 root MySQL 4096 May 4 14:47 libexec
drwxr-xr-x 2 MySQL MySQL 4096 May 4 14:20 log
drwxr-xr-x 4 root MySQL 4096 May 4 14:47 man
drwxr-xr-x 9 root MySQL 4096 May 4 14:47 MySQL-test
drwxr-xr-x 2 MySQL MySQL 4096 May 5 22:16 sock
root@mysql1>:/usr/local/mysql#
b) 安装ndb节点:
如果希望尽可能的各环境保持一致,建议在NDB节点也和SQL节点一样安装整个带有NDB Cluster存储引擎的MySQL Server。由于安装细节和上面的SQL节点完全一样,所以这里就不再累述。
另外,如果只是为了保证能够完整的MySQL Cluster这个环境,则在NDB节点上完全可以仅安装NDB存储引擎(mysql ndb storage engine)即可。安装NDB存储引擎好像目前是找不到源码来自行编译安装的,只能通过MySQL AB官方提供的rpm包来安装。安装过程非常简单,和其他的rpm软件包安装没有任何区别。
c) 管理节点:
管理节点所需要的安装更简单,实际上只需要ndb_mgm和ndb_mgmd两个程序即可,这两个可执行程序可以在上面的MySQL节点的MySQL安装目录中的bin目录下面找到。将这两个程序copy到管理节点上面合适的位置(自行考虑,我一般会放在/usr/local/mysql/bin下面),并在path制定的目录中建立两个同名的soft link在到这两个程序上面,就可以了。
以上即是MySQL Cluster环境的软件安装过程,看上去并不复杂是吧,希望大家的安装过程也能够一切顺利,当然如果遇到了什错误也不用担心,MySQL官方手册中也提供了非常详细的安装过程说明。
3、基本配置
在上面所有节点的软件安装完成之后,就是MySQL Cluster环境的配置工作了。如果不考虑其他一些优化和个性化的配置需求,MySQL Cluster的基本配置是比较简单的。这里暂时先仅仅完成一个简单的测试环境的配置,详细的配置说明请看后面的MySQL Cluster配置介绍的章节。
对于MySQL节点和ndb节点在上面的安装过程中已经完成了,仅需要设置[MySQL_cluster]参数组的ndb-connectstring参数即可完成最基本的配置。
管理节点的配置稍微复杂一点,因为他需要配置出Cluster环境中每一个节点的基本信息。配置文件并不需要一个特别固定的位置和名称,都由用户自行设定,只需要在启动过程中指定配置文件即可。在我们的测试环境中配置为建名称为/var/lib/MySQL-cluster/config.ini,内容如下:
[root@mysqlMgm ~]# cat /var/lib/mysql-cluster/config.ini
[NDBD DEFAULT]
NoOfReplicas=2
DataMemory=64M
IndexMemory=16M
[TCP DEFAULT]
portnumber=2202
#管理节点
[NDB_MGMD]
id=1
hostname=192.168.0.5
datadir=/var/lib/mysql-cluster
#第一个ndbd节点:
[NDBD]
id=2
hostname=192.168.0.3
datadir=/data/mysqldata
#第二个ndbd节点:
[NDBD]
id=3
hostname=192.168.0.4
datadir=/drbddata/mysqldata
# SQL node options:
[MySQLD]
id=4
hostname=192.168.0.1
[MySQLD]
id=5
hostname=10.0.65.203
[root@mysqlMgm ~]#
1) SQL节点的配置:
MySQL节点的配置和普通的MySQL Server的配置区别主要是需要在my.cnf文件中增加[mysql_cluster]这个配置选项组,并至少指定ndb-connectstring=192.168.0.5,也就是制定管理节点的ip地址或者hostname。另外,如果希望能在启动MySQLd的时候不用手动指定ndbcluster参数,则在[mysqld]参数选项组中增加ndbcluster项参数。除了这两项之外,其他的所有参数都可以可以使用默认值。
2) NDB存储节点的配置:
NDB存储节点的配置就更简单的了,仅仅需[mysql_cluster]中的ndb-connectstring = 192.168.0.5 参数,其他所有的都可以不再配置了。
4、环境测试
在MySQL Cluster环境搭建完成后,首先肯定要对新搭建的环境进行一些基本的功能和异常测试,以确认搭建的环境是否已经可以正常提供服务。
1) 首先检测ndb引擎是否已经正常工作
通过任意客户端连接任意选定的一个SQL节点,测试各种基本的ddl,dml操作,然后再通过客户端连接上Cluster环境中另外的SQL节点校验所作的草食是否在其他节点同样可见了。下面是测试create table 后再插入一条数据的示例:
在节点4上面:
mysql>use test;
mysql>create table t1 ( a int) engine=ndb;
Query ok, 0 rows affected (0.00 sec)
mysql>insert into t1 values(100);
Query ok, 1 rows affected (0.00 sec)
然后在节点5上面:
mysql>use test;
mysql>select * from t1;
+-----+
| id |
+-----+
| 100 |
+-----+
1 row in set (0.00 sec)
可见,在节点4上面所插入的数据,已经在节点5上面了,说明ndb引擎工作正常的。其他的测试与此类似,大家可以自行测试。
如果在测试中发现在某两个节点之间出现不一致现象,那么可以肯定的是,Cluster环境的配置有问题。在管理节点上面通过“ndb_mgm -e SHOW”命令查看各节点状态是否正常,是否都已经连接到了管理节点上面。并检查不正常节点的my.cnf配置文件,是否已经配置好了以ndbcluster方式启动MySQLd,是否有正确配置[mysql_cluster]这个参数组的最基本的ndb-connectstring参数。然后检查管理节点上面的config文件,里面是否有正确配置好各所有节点的配置,尤其是不正常的SQL节点的配置。
2) 检测冗余环境的单点故障问题
a、模拟NDB节点Crash
由于是模拟Crash,所以我们通过在节点2上面kill掉ndb进程,然后再分别通过两个SQL节点去访问t1表,查看是否可以正常访问,数据是否一样。
在节点4上面:
mysql> use test;
mysql> select * from t1;
+-----+
| id |
+-----+
| 100 |
+-----+
1 row in set (0.00 sec)
mysql> insert into t1 values(200);
Query ok, 1 rows affected (0.00 sec)
在节点5上面:
mysql>use test;
mysql>select * from t1;
+-----+
| id |
+-----+
| 100 |
| 200 |
+-----+
2 row in set (0.00 sec)
mysql> delete from t1 where id = 100;
Query ok, 1 rows affected (0.00 sec)
再回到节点4上面:
mysql> select * from t1;
+-----+
| id |
+-----+
| 200 |
+-----+
1 row in set (0.00 sec)
可以看到,不仅t1仍然可以正常访问,数据也没有任何丢失,且仍然可以正常插入,删除数据。可见,在有一个NDB节点Crash之后,真个MySQL Cluster环境仍然可以正常提供服务。当然,如果两个NDB节点都Crash之后,MySQL Cluster环境就无法正常提供服务了,大家也可以自行测试一下。
b、模拟SQL节点Crash
同样和测试NDB节点Crash一样,kill掉一个SQL节点(比如节点4)的mysqld进程,然后通过节点5进行访问:
在节点5上面:
mysql> use test;
mysql> select * from t1;
+-----+
| id |
+-----+
| 200 |
+-----+
1 row in set (0.00 sec)
mysql> insert into t1 values(300);
Query ok, 1 rows affected (0.00 sec)
mysql> select * from t1;
+-----+
| id |
+-----+
| 200 |
| 300 |
+-----+
2 row in set (0.00 sec)
可以看到,当节点4 Crash之后,节点5仍然能够提供正常的服务。当然,如果在应用环境中,应用环境需要至少支持当一个SQL节点出现问题的时候能够自行切换到剩下的正常的SQL节点来访问。
c、管理节点的单点
一般情况来说,管理节点是最容易控制的,实施也非常简单,只需要将配置文件和两个可执行程序(ndb_mgmd和ndb_mgm)存放在多台机器上面即可,所以一般来说不需要太多考虑单点故障。
16.3 MySQL Cluster配置详细介绍(config.ini)
在MySQL Cluster环境的配置文件config.ini里面,每一类节点都有两个(或以上)的相应配置项组,每一类节点的配置项都主要由两部分组成,一部分是同类所有节点相同的配置项组,在[NDB_MGM DEFAULT]、[NDBD DEFAULT]和[MySQLD DEFAULT]这三个配置组里面,而且每一个配置组只出现一次;而另外一部分则是针对每一个节点独有配置内容的配置项组[NDB_MGM]、[NDBD]和[MySQLD],由于这三类配置组中配置的每一个节点独有的个性化配置,所以每一个配置组都可能会出现多次(每一个节点一次)。下面是每一类节点的各种配置说明:
1、管理节点相关配置
在整个MySQL Cluster环境中,管理节点相关的配置为[NDBD_MGM DEFAULT]和[NDB_MGMD]相关的两组:
1) [NDB_MGMD DEFAULT]中各管理节点的共用配置项:
PortNumber:配置管理节点的服务端程序(ndb_mgmd)监听客户端(ndb_mgm)连接请求和发送的指令,从文档上可以查找到,默认端口是1186端口。一般来说这一项不需要更改,当然如果是为了在同一台主机上面启动多个管理节点的话,肯定需要将两个管理节点启动不同的监听端口;
LogDestination:配置管理节点上面的cluster日志处理方式。
a) 可以写入文件如:LogDestination=FILE:filename=my-cluster.log,maxsize=500000,maxfiles=4;
b) 也可以通过标准输出来打印出来如:LogDestination=CONSOLE;
c) 还可以计入syslog里面如:LogDestination=SYSLOG:facility=syslog;
d) 甚至多种方式共存:LogDestination=CONSOLE;SYSLOG:facility=syslog;FILE:filename=/var/log/cluster-log
Datadir:设置用于管理节点存放文件输出的位置。如process文件(.pid),cluster log文件(当LogDestination有FILE处理方式存在时候)。
ArbitrationRank:配置各节点在处理某些事件出现分歧的时候的级别。有0,1,2三个值可以选择。
a) 0代表本节点完全听其他节点的,不参与决策
b) 1代表本节点有最高优先权,“一切由我来决策”
c) 2代表本节点参与决策,但是优先权较1低,但是比0高
ArbitrationRank参数不仅仅管理节点有,MySQL节点也有。而且一般来说,所有的管理节点一般都应该设置成1,所有SQL节点都设置成2。
2) [NDB_MGMD]是每个管理节点配置一组,所需配置项如下(下面的参数只能设置在[NDB_MGMD]参数组中):
Id:为节点指定一个唯一的ID号,要求在整个Cluster环境中唯一;
Hostname:配置该节点的IP地址或者主机名,如果是主机名,则该主机名必须要在配置文件所在的节点的/etc/hosts文件中存在,而且绑定的IP是准确的。
上面[NDB_MGMD DEFAULT]里面的所有参数项,都可以设置在下面的[NDB_MGMD]参数组里面,但是Id和Hostname两个参数只能设置在[NDB_MGMD]里面,而不能设置在[NDB_MGMD DEFAULT]里面,因为这两个参数项针对每一个节点都是不相同的内容。
2、NDB节点相关配置
NDB节点和管理节点一样,既有各个节点共用的配置信息组[NDBD DEFAULT],也有每一个节点个性化配置的[NDBD]配置组(实际上SQL节点也是如此)。
1) [NDBD DEFAULT]中的配置项:
NoOfReplicas:定义在Cluster环境中相同数据的分数,通俗一点来说就是每一份数据存放NoOfReplicas份。如果希望能够冗余,那么至少设置为2(一般情况来说此参数值设置为2就够了),最大只能设置为4。另外,NoOfReplicas值得大小,实际上也就是node group大小的定义。NoOfReplicas参数没有系统默认值,所以必须设定,而且只能设置在[NDBD DEFAULT]中,因为此数值在整个Cluster集群中一个node group中所有的NDBD节点都需要一样。另外NoOfReplicas的数目对整个Cluster环境中NDB节点数量有较大的影响,因为NDB节点总数量是NoOfReplicas * 2 * node_group_num;
DataDir:指定本地的pid文件,trace文件,日志文件以及错误日志子等存放的路径,无系统默认地址,所以必须设定;
DataMemory:设定用于存放数据和主键索引的内存段的大小。这个大小限制了能存放的数据的大小,因为ndb存储引擎需属于内存数据库引擎,需要将所有的数据(包括索引)都load到内存中。这个参数并不是一定需要设定的,但是默认值非常小(80M),只也就是说如果使用默认值,将只能存放很小的数据。参数设置需要带上单位,如512M,2G等。另外,DataMemory里面还会存放UNDO相关的信息,所以,事务的大小和事务并发量也决定了DataMemory的使用量,建议尽量使用小事务;
IndexMemory:设定用于存放索引(非主键)数据的内存段大小。和DataMemory类似,这个参数值的大小同样也会限制该节点能存放的数据的大小,因为索引的大小是随着数据量增长而增长的。参数设置也如DataMemory一样需要单位。IndexMemory默认大小为18M;
实际上,一个NDB节点能存放的数据量是会受到DataMemory和IndexMemory两个参数设置的约束,两者任何一个达到限制数量后,都无法再增加能存储的数据量。如果继续存入数据系统会报错“table is full”。
FileSystemPath:指定redo日志,undo日志,数据文件以及meta数据等的存放位置,默认位置为DataDir的设置,并且在ndbd初始化的时候,参数所设定的文件夹必须存在。在第一次启动的时候,ndbd进程会在所设定的文件夹下建立一个子文件夹叫ndb_id_fs,这里的id为节点的ID值,如节点id为3则文件夹名称为ndb_3_fs。当然,这个参数也不一定非得设置在[NDBD DEFAULT]参数组里面让所有节点的设置都一样(不过建议这样设置),还可以设置在[NDBD]参数组下为每一个节点单独设置自己的FileSystemPath值;
BackupDataDir:设置备份目录路径,默认为FileSystemPath/BACKUP。
接下来的几个参数也是非常重要的,主要都是与并行事务数和其他一些并行限制有关的参数设置。
MaxNoOfConcurrentTransactions:设置在一个节点上面的最大并行事务数目,默认为4096,一般情况下来说是足够了的。这个参数值所有节点必须设置一样,所以一般都是设置在[NDBD DEFAULT]参数组下面;
MaxNoOfConcurrentOperations:设置同时能够被更新(或者锁定)的记录数量。一般来说可以设置为在整个集群中相同时间内可能被更新(或者锁定)的总记录数,除以NDB节点数,所得到的值。比如,在集群中有两个NDB节点,而希望能够处理同时更新(或锁定)100000条记录,那么此参数应该被设置为:100000 / 4 = 25000。此外,这里的记录数量并不是指单纯的表里面的记录数,而是指事物里面的操作记录。当使用到唯一索引的时候,表的数据和索引两者都要算在里面,也就是说,如果是通过一个唯一索引来作为过滤条件更新某一条记录,那么这里算是两条操作记录。而且即使是锁定也会产生操作记录,比如通过唯一索引来查找一条记录,就会产生如下两条操作记录:通过读取唯一索引中的某个记录数据会产生锁定,产生一条操作记录,然后读取基表里面的数据,这里也会产生读锁,也会产生一条操作记录。MaxNoOfConcurrentOperations参数的默认值为32768。当我们额度系统运行过程中,如果出现此参数不够的时候,就会报出“Out of operation records in transaction coordinator”这样的错误信息;
MaxNoOfLocalOperations:此参数默认是MaxNoOfConcurrentOperations * 1.1 的大小,也就是说,每个节点一般可以处理超过平均值的10%的操作记录数量。但是一般来说,MySQL建议单独设置此参数而不要使用默认值,并且将此参数设置得更较大一些;
以下的三个参数主要是在一个事务中执行一条query的时候临时用到存储(或者内存)的情况下所使用到的,所使用的存储信息会在事务结束(commit或者rollback)的时候释放资源;
MaxNoOfConcurrentIndexOperations:这个参数和MaxNoOfConcurrentOperations参数比较类似,只不过所针对的是Index的record而已。其默认值为8192,对伊一般的系统来说都已经足够了,只有在事务并发非常非常大的系统上才有需要增加这个参数的设置。当然,此参数越大,系统运行时候为此而消耗的内存也会越大;
MaxNoOfFiredTriggers:触发唯一索引(hash index)操作的最大的操作数,这个操作数是影响索引的操作条目数,而不是操作的次数。系统默认值为4000,一般系统来说够用了。当然,如果系统并发事务非常高,而且涉及到索引的操作也非常多,自然也就需要提高这个参数值的设置了;
TransactionBufferMemory:这个buffer值得设置主要是指定用于跟踪索引操作而使用的。主要是用来存储索引操作中涉及到的索引key值和column的实际信息。这个参数的值一般来说也很少需要调整,因为实际系统中需要的这部分buffer量非常小,虽然默认值只是1M,但是对于一般应用也已经足够了;
下面要介绍到的参数主要是在系统处理中做table scan或者range scan的时候使用的一些buffer的相关设置,设置的恰当可以既节省内存又达到足够的性能要求。
MaxNoOfConcurrentScans:这个参数主要控制在Cluster环境中并发的table scan和range scan的总数量平均分配到每一个节点后的平均值。一般来说,每一个scan都是通过并行的扫描所有的partition来完成的,每一个partition的扫描都会在该partition所在的节点上面使用一个scan record。所以,这个参数值得大小应该是“scan record”数目 * 节点数目。参数默认大小为256,最大只能设置为500;
MaxNoOfLocalScans:和上面的这个参数相对应,只不过设置的是在本节点上面的并发table scan和range scan数量。如果在系统中有大量的并发而且一般都不使用并行的话,需要注意此参数的设置。默认为MaxNoOfConcurrentScans * node数目;
BatchSizePerLocalScan:该参用于计算在Localscan(并发)过程中被锁住的记录数,文档上说明默认为64;
LongMessageBuffer:这个参数定义的是消息传递时候的buffer大小,而这里的消息传递主要是内部信息传递以及节点与节点之间的信息传递。这个参数一般很少需要调整,默认大小为1MB大小;
下面介绍一下与log相关的参数配置说明,包括log level。这里的log level有多种,从0到15,也就是共16种。如果设定为0,则表示不记录任何log。如果设置为最高level,也就是15,则表示所有的信息都会通过标准输出来记录log。由于这里的所有信息实际上都会传递到管理节点的cluster log中,所以,一般来说,除了启动时候的log级别需要设置为1之外,其他所有的log level都只需要设置为0就可以了。
NoOfFragmentLogFiles:这个参数实际上和Oracle的redo log的group一样的。其实就是ndb的redo log group数目,这些redo log用于存放ndb引擎所做的所有需要变更数据的事情,以及各种checkpoint信息等。默认值为8;
MaxNoOfSavedMessages:这个参数设定了可以保留的trace文件(在节点crash的时候参数)的最大个数,文档上面说此参数默认值为25。
LogLevelStartup:设定启动ndb节点时候需要记录的信息的级别(不同级别所记录的信息的详细程度不一样),默认级别为1;
LogLevelShutdown:设定关闭ndb节点时候记录日志的信息的级别,默认为0;
LogLevelStatistic:这个参数是针对于统计相关的日志的,就像更新数量,插入数量,buffer使用情况,主键数量等等统计信息。默认日志级别为0;
LogLevelCheckpoint:checkpoint日志记录级别(包括local和global的),默认为0;
LogLevelNodeRestart:ndb节点重启过程日志级别,默认为0;
LogLevelConnection:各节点之间连接相关日志记录的级别,默认0;
LogLevelError:在整个Cluster中错误或者警告信息的日志记录级别,默认0;
LogLevelInfo:普通信息的日志记录级别,默认为0。
这里再介绍几个用来作为log记录时候需要用到的Buffer相关参数,这些参数对于性能都有一定的影响。当然,如果节点运行在无盘模式下的话,则影响不大。
UndoIndexBuffer:undo index buffer主要是用于存储主键hash索引在变更之后产生的undo信息的缓冲区。默认值为2M大小,最小可以设置为1M,对于大多数应用来说,2M的默认值是够的。当然,在更新非常频繁的应用里面,适当的调大此参数值对性能还是有一定帮助的。如果此参数太小,会报出677错误:Index UNDO buffers overloaded;
UndoDataBuffer:和undo index buffer类似,undo data buffer主要是在数据发生变更的时候所需要的undo信息的缓冲区。默认大小为16M,最小同样为1M。当这个参数值太小的时候,系统会报出如下的错误:Data UNDO buffers overloaded,错误号为891;
RedoBuffer:Redo buffer是用redo log信息的缓冲区,默认大小为8M,最小为1M。如果此buffer太小,会报1221错误:REDO log buffers overloaded。
此外,NDB节点还有一些和metadata以及内部控制相关的参数,但大部分参数都基本上不需要任何调整,所以就不做进一步介绍。如果有兴趣希望详细了解,可以根据MySQL官方的相关参考手册,手册上面都有较为详细的介绍。
3、SQL节点相关配置说明
1) 和其他节点一样,先介绍一些适用于所有节点的[MySQLD DEFAULT]参数
ArbitrationRank:这个参数在介绍管理节点的参数时候已经介绍过了,用于设定节点级别(主要是在多个节点在处理相关操作时候出现分歧时候设定裁定者)的。一般来说,所有的SQL节点都应该设定为2;
ArbitrationDelay:默认为0,裁定者在开始裁定之前需要被delay多久,单位为毫秒。一般不需要更改默认值。
BatchByteSize:在做全表扫描或者索引范围扫描的时候,每一次fatch的数据量,默认为32KB;
BatchSize:类似BatchByteSize参数,只不过BatchSize所设定的是每一次fetch的record数量,而不是物理总量,默认为64,最大为992(暂时还不知道这个值是基于什么理论而设定的)。在实际运行query的过程中,fetch的量受到BatchByteSize和BatchSize两个参数的共同制约,二者取最小值;
MaxScanBatchSize:在Cluster环境中,进行并行处理的情况下,所有节点的BatchSize总和的最大值。默认值为256KB,最大值为16MB。
2) 每个节点独有的[MySQLD]参数组,仅有id和hostname参数需要配置,在之前各类节点均有介绍了,这里就不再累述。
16.4 MySQL Cluster基本管理与维护
MySQL Cluster的管理和普通的MySQL Server管理区别较大,基本上大部分管理工作都是在管理节点上面完成,仅有少数管理内容需要在其他节点实施。
1、各节点启动与关闭
要想Cluster环境能够正常工作,只好要启动一个NDB节点和一个SQL节点,另外为了完成管理,也至少要启动一个管理节点。各类节点的启动顺序也有要求,首先是管理节点,然后是NDB节点,最后才是SQL节点。
1) 按顺序启动各节点:
a、 启动管理节点:
[root@localhost MySQL-cluster]# ndb_mgmd -f /var/lib/MySQL-cluster/config.ini
这里执行的ndb_mgmd命令实际上就是MySQL Cluster管理服务器,可以通过-f config_file_name或者--config=config_filename来指定MySQL Cluster集群的参数文件。如果想了解更多关于ndb_mgmd的参数信息,可以通过运行ndb_mgmd --help来获取更详细的信息。
b、 启动用于存储数据的ndb节点
要启动存储节点,必须在每一台ndb节点主机上面都执行ndbd程序,如果是第一次启动,则需要添加--initial参数,以便进行ndb节点的初始化工作。但是,在以后的启动过程中,是不能添加该参数的,否则ndbd程序会清除在之前建立的所有用于恢复的数据文件和日志文件。启动命令如下
root@ndb1:/root>ndbd --initial
c、 启动SQL节点
SQL节点的启动和普通MySQL Server的启动没有太多明显的差别,不过有一个前提就是需要在MySQL Server的配置文件my.cnf设置好[MySQL_cluster]配置组中的ndb-connectstring参数和[MySQLd]配置组中的ndbcluster参数。
root@mysql1:/root>MySQLd_safe --user=MySQL &
2) 节点状态检查:
在各节点都启动完成后,回到管理节点,可以通过ndb_mgm来查看各节点状态:
[root@localhost MySQL-cluster]# ndb_mgm -e SHOW
Connected to Management Server at: localhost:1186
Cluster Configuration
---------------------
[ndbd(NDB)] 2 node(s)
id=2 @192.168.0.3 (Version: 5.0.51, Nodegroup: 0, Master)
id=3 @192.168.0.4 (Version: 5.0.51, Nodegroup: 0)
[ndb_mgmd(MGM)] 1 node(s)
id=1 @192.168.0.5 (Version: 5.0.51)
[MySQLd(API)] 2 node(s)
id=4 @192.168.0.1 (Version: 5.0.51)
id=5 @10.0.65.203 (Version: 5.0.51)
这里显示出整个集群有5个几点,其中各节点信息如下:
a) 2个NDBD节点:
[ndbd(NDB)] 2 node(s)
id=2 @192.168.0.3 (Version: 5.0.51, Nodegroup: 0, Master)
id=3 @192.168.0.4 (Version: 5.0.51, Nodegroup: 0)
b) 两个SQL节点:
[MySQLd(API)] 2 node(s)
id=4 @192.168.0.1 (Version: 5.0.51)
id=5 @10.0.65.203 (Version: 5.0.51)
c) 1个管理节点:
[ndb_mgmd(MGM)] 1 node(s)
id=1 @192.168.0.5 (Version: 5.0.51)
3) 节点的关闭操作:
在MySQL Cluster环境中,NDB节点和管理节点的关闭都可以在管理节点的管理程序中完成,但是SQL节点却没办法。所以,在关闭整个MySQL Cluster环境或者关闭某个SQL节点的时候,首先必须到SQL节点主机上来关闭SQL节点程序。关闭方法和MySQL Server的关闭一样,就不累述。而NDB节点和管理节点则都可以在管理节点通过管理程序来完成:
ndb_mgm> shutdown
Connected to Management Server at: localhost:1186
Node 3: Cluster shutdown initiated
Node 2: Cluster shutdown initiated
Node 2: Node shutdown completed.
Node 3: Node shutdown completed.
2 NDB Cluster node(s) have shutdown.
Disconnecting to allow management server to shutdown.
2、基本管理维护
前面运行的命令ndb_mgm如果不带任何参数,实际上是进入MySQL Cluster的命令行管理界面。在命令行管理界面里面可以做大量的维护工作,如下:
[root@localhost MySQL-cluster]# ndb_mgm
-- NDB Cluster -- Management Client --
ndb_mgm>
然后同样执行show命令:
ndb_mgm>show
Connected to Management Server at: localhost:1186
Cluster Configuration
---------------------
[ndbd(NDB)] 2 node(s)
id=2 (not connected, accepting connect from 192.168.0.3)
id=3 @192.168.0.4 (Version: 5.0.51, Nodegroup: 0, Master)
[ndb_mgmd(MGM)] 1 node(s)
id=1 @192.168.0.5 (Version: 5.0.51)
[MySQLd(API)] 2 node(s)
id=4 @192.168.0.1 (Version: 5.0.51)
id=5 @10.0.65.203 (Version: 5.0.51)
我们可以看到结果和上面的完全一样。可以通过在ndb控制界面下执行help命令查看可以查看很多基本的维护管理命令:
ndb_mgm> help
---------------------------------------------------------------------------
NDB Cluster -- Management Client -- Help
---------------------------------------------------------------------------
HELP Print help text
HELP COMMAND Print detailed help for COMMAND(e.g. SHOW)
SHOW Print information about cluster
START BACKUP [NOWAIT | WAIT STARTED | WAIT COMPLETED]
Start backup (default WAIT COMPLETED)
ABORT BACKUP
SHUTDOWN Shutdown all processes in cluster
CLUSTERLOG ON [
CLUSTERLOG OFF [
CLUSTERLOG TOGGLE [
CLUSTERLOG INFO Print cluster log information
ENTER SINGLE USER MODE
EXIT SINGLE USER MODE Exit single user mode
PURGE STALE SESSIONS Reset reserved nodeid's in the mgmt server
CONNECT [
QUIT Quit management client
For detailed help on COMMAND, use HELP COMMAND.
也可以通过执行help后面跟命令名称而获取各种命令的操作说明帮助信息:
ndb_mgm> help start
---------------------------------------------------------------------------
NDB Cluster -- Management Client -- Help for START command
---------------------------------------------------------------------------
START Start data node (started with -n)
Only starts data nodes that have not
yet joined the cluster. These are nodes
launched or restarted with the -n(--nostart)
option.
It does not launch the ndbd process on a remote
machine.
ndb_mgm> help shutdown
---------------------------------------------------------------------------
NDB Cluster -- Management Client -- Help for SHUTDOWN command
---------------------------------------------------------------------------
SHUTDOWN Shutdown the cluster
SHUTDOWN Shutdown the data nodes and management nodes.
MySQL Servers and NDBAPI nodes are currently not
shut down by issuing this command.
ndb_mgm> help PURGE STALE SESSIONS
---------------------------------------------------------------------------
NDB Cluster -- Management Client -- Help for PURGE STALE SESSIONS command
---------------------------------------------------------------------------
PURGE STALE SESSIONS Reset reserved nodeid's in the mgmt server
PURGE STALE SESSIONS
Running this statement forces all reserved
node IDs to be checked; any that are not
being used by nodes acutally connected to
the cluster are then freed.
This command is not normally needed, but may be
required in some situations where failed nodes
cannot rejoin the cluster due to failing to
allocate a node id.
通过上面的几个帮助命令所获取的信息得知,我们可以通过在管理节点上面通过执行restart,stop,shutdown等基本的命令来重启某个节点,关闭某个节点,还可以同时一次性关闭所有节点。
此外,还可以通过执行备份相关的命令在管理节点对整个Cluster环境进行备份,以及通过日志相关命令实施对日志的相关管理。
16.5 基本优化思路
MySQL Cluster 虽然是一个分布式的数据库系统,但是在大部分地方的优化思路和方法还是和普通的 MySQL Server 一样。和常规 MySQL Server 在优化方面的区别主要提现在各节点之间的协作配置以及网络环境相关的优化。
由于 MySQL Cluster 是一个分布式的环境,而且所有访问都是需要经过超过一个节点(至少有一个 SQL 节点和一个 NDB 节点)才能完成,所以各个节点之间的协作配合就显得尤为重要。
首先,由于各个节点之间存在大量的数据通讯,所以节点之间的内部互联网络带宽一定要保证足够使用。为了适应不同的网络环境和性能需求,MySQL Cluster 支持了多种内部网络互联的协议和方式。最为常用的自然是通过 TCP/IP 来进行互联。此外还可以有 SCI Socket 方式来进行互联,还支持 Myrinet,Infiniband,VIA 接口等等。
其次,SQL 节点和 NDB 节点的主机性能配比应该合适,而不应该出现某一类节点过早出现瓶颈的时候,另外一类节点却还处于非常空闲的状态。如果在我们遇到的环境中出现这样的情况,那么我们就该重新评估两类节点的硬件设备配比了。否则,有一类节点的硬件资源就相当处于浪费状态了。
最后,就是 SQL 节点 和 NDB 节点两者软件配置方面的优化了。对于 SQL 节点的配置,和普通的 MySQL 区别不是太大。各类参数的配置原则也和普通 MySQL 基本相同。NDB Cluster 存储引擎的主要配置参数在前面的配置介绍中也基本都进行了性能相关的说明,这里就不再累述了。
16.6 小结
MySQL Cluster 的核心在于 NDB Cluster 存储引擎,他不仅对数据进行了水平切分,还对数据进行了跨节点冗余。既解决了数据库的扩展问题,同时也在很大程度上提高了数据库整体可用性。
虽然目前 MySQL Cluster 的应用还不如普通的 MySQL Server 应用那么广泛,但是我想随着他的不断成熟和改善,将会被越来越广泛的使用。这种 Share Nothing 的 Cluster 架构也很可能会成为未来的趋势,就让我们共同期待越来越成熟稳定高效的 MySQL Cluster吧。